







Hadoop 自从2.7.1 之后开始支持 Docker Container Executor, 这就为我们运行mapreduce 任何提供了一个新的可能,也就是说我们可以把mapreduce 任务的JVM 运行在docker里。利用docker提供的资源隔离技术可以减少并行运行task之间的的干扰。本文主要介绍了把任务运行在docker内,其他相关文章也有讨论把docker配资成单一的节点,该情况不在本文讨论的范围之内。
一. Docker Container vs. YARN Container
首先,docker是一个开源的应用容器引擎,它主要利用namespace实现作用域的隔离,利用cgroup实现资源的 隔离。利用docker可以实现应用的开发,测试以及部署完全没有依赖。当然这些概念化的语句读者可以再wiki或者百度百科上找到,这里就不多说了。其实YARN也就是我们说的hadoop v2.0 也有自已的一套容器机制。有别于hadoop v 1.0 仅仅用slot来区分map 的资源和reduce 资源。 YARN引入了容器的概念,就我自己的感觉来说,起码有以下几个好处:
1. 资源复用,提高集群的利用率(map释放的资源可以被reduce利用)
2. 对资源有了更高纬度的抽象,目前为止支持cpu和memory的抽象,可以想象,随着机器学习应用的流行,将来还可能支持io,gpu,network等
3. YARN能更好的支持除了mapreduce以外的其他应用,例如spark, mpi等
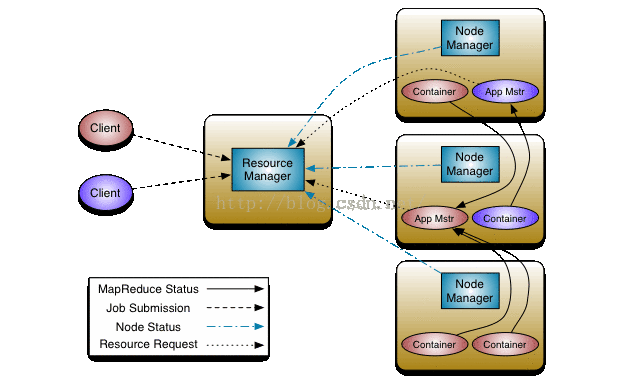
如图所示,在一个Application Maser(AppMaster)为它的task请求到资源以后,YARN会以container的形式把封装好的资源发送给这个task。通俗来说,一个container也就是若干cpu和若干memory的抽象集合。之后Node Manager 再在相应的节点上把这个container运行起来,这个过程很复杂,主要包括从HDFS得到运行程序的jar包、配置文件,从Distributed cache里得到相应的文件,以及本地的配置文件等。但是,问题在于,YARN的container仅仅是一个概念上的container,在YARN的container总并没有实现任何资源隔离,所以我们经常看到的情况是,明明配置了2GB 1core的一个container, top 一下发现这个container上运行的JVM内存消耗超过4GB,CPU利用率超过300%。当然其实YARN的开发组并没有忽视这个问题,他们一直在下一盘很大的棋。于是在hadoop-2.7.1发布之后,DockerContainerExecutor横空出世。
关于Docker的安装,本文不展开细讲,网上能找到大量的资料,ubuntu 上步骤如下:
$ apt-get update
$ apt-get install apt-transport-https ca-certificates编辑/etc/apt/sources.list.d/docker.list,如果没有的话就创建一个。添加以下条目:
On Ubuntu Precise 12.04 (LTS)
deb https://apt.dockerproject.org/repo ubuntu-precise mainOn Ubuntu Trusty 14.04 (LTS)
deb https://apt.dockerproject.org/repo ubuntu-trusty mainUbuntu Wily 15.10
deb https://apt.dockerproject.org/repo ubuntu-wily main$ apt-get update
$ apt-get purge lxc-docker
$ apt-cache policy docker-engine
$ docker images ## list docker images on your host  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3542
3542

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









