







背景知识
Flex 和 Bison 是两个在编译前期最常实验的工具,分别是用来做 lexical analyse 和 semantic analyse 的,这两个工具的使用基本不需要很深的编译知识,只需要掌握正则表达式的书写(lexical analyse阶段使用)和上下文无关文法(semantic analyse 阶段使用),就可以完成这两个阶段的分析了。
Flex大体介绍
Flex 主要是用在词法分析阶段,不需要我们去手写分析器,只需要制定好相应的正则表达式规则,他可以自动对输入文件进行词法分析。
Flex 主要在 Linux 系统下工作,安装方式也很简单。
sudo apt-get install flex
或者
sudo yum install flex
安装好 flex 之后,我们创建一个 .l 后缀的文件,这个文件里面主要由三部分组成,定义了词法分析的规则,整个文件的结构如下。
definitions
%%
rules
%%
user subroutines
在编写好文件后,可以以下使用命令 进行编译
flex file.l
编译之后,我们会得到一个名为 file.yy.c 的文件,这个文件代码中,我们只需要使用里面的 yylex() 函数,这个函数可以读入文件中的一个词法单元,然后进行规则匹配,即词法分析。
我们可以在外部定义一个自己的 main() 进行调用,可也以在第三部分 {user subroutines} 中书写 main() 函数进行调用。便于文件的组织,这里我们使用外部文件的方式定义一个新的主函数。
主要的代码框架如下
extern File* yyin;
int main(int argc, char ** args) {
if (argc > 1) {
if( ! (yyin = fopen(argv[1], "r"))) {
perror(argv[1]);
return 1;
}
}
while(yylex()!= 0);
return 0;
}
这个 yyin 可以理解成输入文件的文件指针,用来读取文件,在 file.yy.c 中定义。
然后我们进行整体的编译
gcc main.c file.yy.c -lfl -o scanner
-lfl 参数是指定一个库函数,对于 MacOS 用户,可以使用 -ll 参数进行代替。
这里有个坑,有可能提示错误:/usr/bin/ld: cannot find -lfl
解决方法:需要再安装以下包:
sudo yum install flex-devel
这样之后,对某个文件进行词法分析就可以直接运行 ./scanner test.cmm 了。
Flex 规则部分
我们需要注意的是对 Flex 中的规则的编写,整个 FLex 文件分别由三个部分,第一个部分通常定义一些之后常用的正则表达式,可以简化书写,定义格式为:
name definition
defintion 是一个具体的正则表达式,而 name 是其别名,比如,如果想定义一个识别任意数字的正则表达式,可以这样定义
digit [0-9]
这个 digit 就是这个正则表达式的别名,和这个正则表达式的效果一样,会和任意一个数字进行匹配。
第二部分是规则部分,即针对每一个特定的语法单元,我们对其有什么样的操作。定义格式为
pattern {action}
这个pattern 和我们上面的一样,都是正则表达式,而对应的 action 则指定了如果遇到了这个 pattern 之后,我们的应对方法。这个 pattern 我们可以重新定义,也可以直接使用在第一部分定义好的对应的 name,如果使用 name,则格式为 {name}。针对一些没有匹配任何规则的词法元素,我们可以使用 . 这个 pattern 指定对应的动作。
第三部分是用户自定义的代码部分,而这部分定义的方法,函数,都应该在第一部分中进行声明,声明格式为
%{
%}
这样,声明后的变量,函数和自定义的代码片段都会在 file.yy.c 中生成,方便我们调用。
完成了这三个部分后,我们就可以生成一个简单的语法分析器了。下面给出一个使用 flex 进行单词统计的完整文件。
%{
int chars = 0;
int words = 0;
int lines = 0;
%}
letter [a-zA-Z]
%%
{letter}+ {words ++; chars += yyleng; }
\n {chars++; lines ++;}
. {chars++;}
%%
int main(int argc, char** argv) {
if (argc > 1) {
if (!(yyin = fopen(argv[1], "r"))) {
perror(argv[1]);
return 1;
}
}
yylex();
printf("lines are %d words are %d chars are %d\n", lines, words, chars);
return 0;
}
这里的 yyleng 是 flex 内置提供的变量,记录当前单词的长度。
这样,整个词法分析的过程就结束了,我们可以输入对应的词法流,在语法分析阶段进行下一步的分析。而语法分析所用的工具,就是 bison。
其他
正则表达式:
Flex 有几个正则表达式和传统的正则表达式规则还是有点区别:
[a-z]{}[jv] 表示 a-z 里面再排除 j 和 v
/ 尾部上下文, 0/1 表示匹配 01 中的 0 , / 后面的只用于尾部模式匹配, 匹配出来的是斜线前面的内容, 但斜线后面的内容并不会消耗掉, 会继续给余下的规则匹配
语法:
%option noyywrap 是用于关闭 yywrap 这个鸡肋的函数, yywrap 主要用于调整 yyin 的值来读取新文件的内容
yyrestart(f) 放在 yylex 之前, 告诉 flex 读取文件 f 的内容
示例
单词统计程序
wc.l 源代码:
%{
int chars = 0;
int words = 0;
int lines = 0;
%}
%%
[^ \t\n\r\f\v]+ { words++; chars += strlen(yytext); }
\n { chars++; lines++; }
\t { return 0;}
. { chars++; }
%%
int main(int argc, char **argv) {
yylex();
printf("%8d%8d%8d\n", lines, words, chars);
}
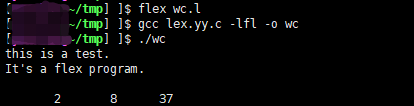
源码备注:
%{ … %} 是直接拷贝到 C 文件开头
%% … %% 是模式匹配的代码区域, 左边是正则表达式, 右边是匹配的 C 代码
yytext 代表匹配正则表达式的字符串
flex 的匹配默认是从最长匹配开始, 如果有多个匹配的正则表达式, 从最早的那个开始匹配, 所以上面的模式匹配, 首先是按照单词 -> 行尾符 -> 剩余字符串的顺序进行匹配的, 不会产生重复统计的问题
yylex 是调用 flex 的词法分析函数 yylex 进行计算
Linux 系统上用 -lfl 选项编译, Mac 的编译选项是 -ll
英美式英语转换
convert.l 源代码:
%%
"colour" { printf("color"); }
"flavour" { printf("flavor"); }
"clever" { printf("smart"); }
"conservative" { printf("libreal"); }
. { printf("%s", yytext); }
%%
int main(int argc, char **argv) {
yylex();
}
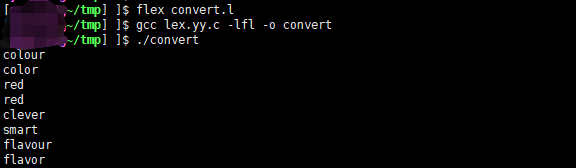
源码备注:
匹配英式单词后, 转换称模式后的美式英语
最后的点表示不转换单词
参考资料:
1.https://www.cnblogs.com/wAther/p/10662978.html
2.https://www.jianshu.com/p/bad193f67a09

















 1306
1306

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









