







我们先看一下一个搜索引擎的大体设计图 :
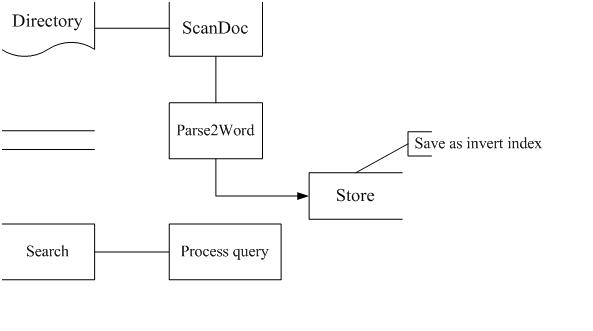 这里面我们看到了输入部分 , 索引部分 , 存储部分 , 还有搜索部分 , 简单的说拥有这些部件你的产品就可以叫做一个索引引擎了 ,MS 使用的桌面搜索服务 (Index service) 也是这几部分组成的 , 那么我们接下来一步一步分析这几部分 :
这里面我们看到了输入部分 , 索引部分 , 存储部分 , 还有搜索部分 , 简单的说拥有这些部件你的产品就可以叫做一个索引引擎了 ,MS 使用的桌面搜索服务 (Index service) 也是这几部分组成的 , 那么我们接下来一步一步分析这几部分 :
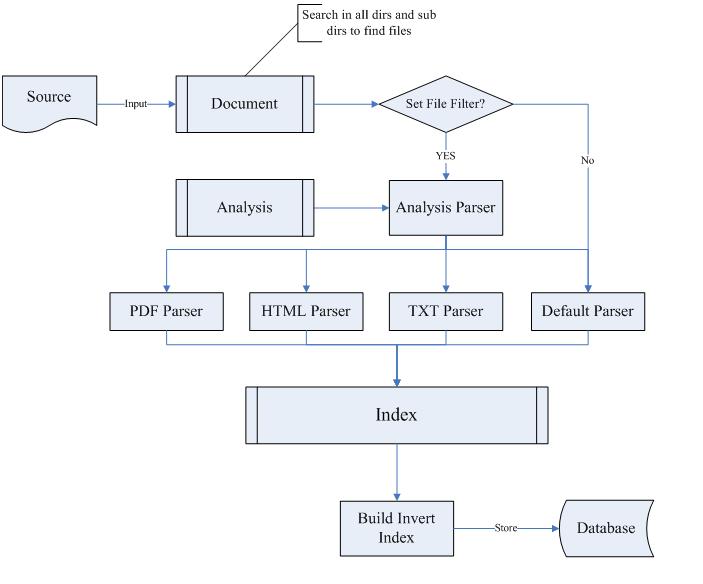
1. Source 作为输入部分 , 为一个指定的文件目录 , 先要具备全目录扫描 , 这时要看我们是否设定了文件 Filter, 很多时候我们只需要把 PDF,HTML 等有用的文件去做索引 , 索引设定 Filter 还是可以提供更好的性能和准确度 , 这里我们创建一个 Document 模块负责文件目录的管理 , 该模块要具备文件系统扫描 , 文件类型过虑 , 还要能将扫描得到的有用文件路径存储到内存中为以后打开这些文件做索引做准备 , 这里我使用了一个 vector 做的文件路径存储 .
2. Analysis 模块负责对文件内容进行解析 , 不同的文件调用不同的解析器 , 这里的文件就是由上面的 vector 提供的 , 这里设计一定要为将来其他用户使用拓展文件类型提供接口 , 否则你的设计就太不 Flexible, 可以考虑诸如 Façade 的设计模式开发 . 我在这里抽象了一个虚基类 :
class CFileParserBase
{
public:
CFileParserBase(void);
~CFileParserBase(void);
virtual int parseWord(IN char * read_buf, CString FileName) = 0;
virtual char * getContent(CString FileName) = 0;
};
其它类需要去重载文件解析和文件内容获取两个基本函数 .
3. 将解析的关键字建立反向索引 , 这里我使用的是数据库 , 因为好的 Database 会在你查询时提供优化 , 速度也就会更快一些 , 性能对于搜索引擎来说是最重要的 . 这一部分的实现我下篇文章详细说 :















 2571
2571

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









