




目录
矩阵运算库blas, cblas, openblas, atlas, lapack, mk
多线程问题
Faiss是由Facebook主导开源的一个“向量搜索(召回)算法”库。简单的说:Faiss能在一大堆库存的向量中找出与指定向量最相似的几向量。
从理论上看,作为一个明显的CPU计算型的应用,更多的core意味着更大的计算吞吐能力。性能只会越来越好才是。可现实是当通过taskset命令分配更多的core给faiss(在本文中亦特指一个以faiss为基础的ivf proxy benchmark工具)只会带来更长响应时间以及更大的响应时间偏差(variation)。
更多core带来更长响应时间以及更大的响应时间偏差
一开始,我首先检查了CPU利用率,发现即便是性能最差的情况,CPU都是满载,这就非常不合情理了。本以为可能性最大(也是最容易解决)的一条路被堵死了,只能认栽,从调黑盒性能变成了调白盒性能。
代码是根据faiss自带的tutorial/cpp/3-IVFPQ.cpp改进而来。测试的流程大致上可以划分为3个阶段:建库(train)、校验(sanity check)、搜索。把每一个环节的耗时统计出来,发现校验过程并不需要太多时间,可以直接排除掉。而剩余的两个阶段都存在“核心越多,性能越差”的奇怪表现。而考虑到具体线上的正常使用模式:建库的过程是一次性的。意味着对建库的修复过程没有这么紧要,那就直接去到搜索阶段的优化。
基于break down。搜索阶段又分两个部分,一个是quantizer,一个是search_preassigned。这么说把,search_preassigned又是耗时大头。对这个函数经过1000次测试之后发现了一个问题:导致单个core和多个core之间性能差异的并非是大多数情况,是少数outlier(离群,囧)导致的平均数增加。outlier的出现频率和偏离程度与核心数呈正比关系。
outlier的出现频率和偏离成都与核心数呈正比关系
这种状况就算是诡异了,从分部特征来看,这应该跟线程的计算有关。将nprobe值和batch设置强置为1,从算法上保证search_preassigned只能用单核单线程。本来希望满满的,结果还是照旧。并且奇怪的是即便已经确信只有单线程在执行,系统中照样还是在多个核心上满负载。
search_preassigned函数单线程模式
看来白盒不是我的风格了,切换回黑盒方法,直接用perf top命令查看系统调用栈。发现在多核、单线程的模式下占比最高的居然是libgomp,而真正的benchmark(6-IVFPQ)只占了很少的CPU资源。
这就是核心的问题了:
- Faiss的多核心是通过openMP实现的。
- 默认OMP_NUM_THREADS等于所有可用的CPU数,即OpenMP默认将会在启动与核心数相同的线程数作为线程池。注: Faiss内部实现使用了大量的OpenMP来提高计算效率,其默认的向量检索也是batch,如果应用场景是单条向量查询,建议把环境变量OMP_NUM_THREADS设为1,避免使用OpenMP带来的多余性能开销,这样可以将单条查询的latency减少至原本的20%;
- 默认情况下,openmp假定所有的调用都是计算密集型的。为了减少线程启动/唤醒过程需要上下文开销,系统必须时刻保证每一个线程都是alive状态。换句话说,要让线程活着,OpenMP会让线程池的每个线程做大量的无意义计算占据时间片而不是wait挂起。
- quantizer 的过程中系统启动了omp线程池,理论上在修改后的search_preassigned开始后,线程池已经没有任何意义。但在放任不管的情况下,系统的每个核心的CPU使用率都会被空白计算占据,理论上100%。主线程结束之前线程池不会自己销毁。
- 这个时候如果位于主线程上的search_preassigned函数需要执行,那就不得不与OMP线程池抢占CPU time。这就是核心越多性能越差的原因。而放大这个影响的原因是我们的测试程序经过了变态级别的优化之后导致OMP的线程维护开销远远大于任务的CPU开销(微秒级响应,少于0.1个最小上下文)。这个测试事实上成为了某种程度“系统调度时延”测量。这个结果恰恰反应了预期。
6. Faiss外部依赖只有一个矩阵计算框架,这个框架可以用OpenBlas也可以用Intel的MKL,使用MKL编译的话性能会比OpenBlas稳定提升30%,在发布Faiss的时候MKL还是商用License,所以官方并没有直接使用,但是现在MKL已经免费了,所以建议使用MKL;
剩下的就是解这个问题了,那只要在合适的时候让线程池销毁所有线程就迎刃而解了。OpenMP的实现是基于编译器的,并没有详细的代码可以参考。找了文档,发现没有办法可以直接实现我的目的,只有两个对应的环境变量可以缓解:
- GOMP_SPINCOUNT=<int n> omp线程经过了n个spin lock之后便被挂起。自然,n值越小就越早的挂起线程。
- OMP_WAIT_POLICY=PASSIVE 通过使用wait方法挂起 omp线程。对应的ACTIVE 意味着线程池中的线程始终处于活动状态——消耗大量的CPU。
我这里就用了后者,展示下优化结果,同样的坐标系之下,效果还是很感人的。再次perf top,omp线程已经不再出现在头部了,收工领赏!咋着也够敲几杯咖啡喝的吧?
OpenMP 环境变量
OpenMP
规范定义了四个用于控制 OpenMP 程序执行的环境变量。下表对它们进行了概括。有关详细信息,请参阅 openmp.org 中的 OpenMP API 版本 3.0 规范。
表 2–1 OpenMP 环境变量
| 环境变量 | 功能 |
| OMP_SCHEDULE | 为指定了 RUNTIME 调度类型的 DO、PARALLEL DO、for、parallel for 指令/pragma 设置调度类型。 如果未定义,则使用缺省值 STATIC。值为 "type[,chunk]" 示例: setenv OMP_SCHEDULE 'GUIDED,4' |
| OMP_NUM_THREADS | 设置在执行并行区域期间所要使用的线程数。 使用 NUM_THREADS 子句或调用 OMP_SET_NUM_THREADS() 可以覆盖此值。 如果未设置,则使用缺省值 1。value 是一个正整数。 示例: setenv OMP_NUM_THREADS 16 |
| OMP_DYNAMIC | 启用或禁用可用于执行并行区域的线程数的动态调整。 如果未设置,则使用缺省值 TRUE。值 为 TRUE 或 FALSE。 示例: setenv OMP_DYNAMIC FALSE |
| OMP_NESTED | 启用或禁用嵌套并行操作。 值 为 TRUE 或 FALSE。 缺省值为 FALSE。 示例: setenv OMP_NESTED FALSE |
| OMP_STACKSIZE | 为 OpenMP 创建的线程设置栈大小。 可以将大小指定为以千字节为单位的正整数,或者带有后缀 B、K、M 或 G,分别表示字节、千字节、兆字节或千兆字节。 示例:setenv OMP_STACKSIZE 10M |
| OMP_WAIT_POLICY | 设置有关等待线程的所需策略 ACTIVE 或 PASSIVE。 ACTIVE 线程在等待时会占用处理器时间。PASSIVE 线程不会占用处理器时间,并且可能会放弃处理器或进入休眠状态。 |
| OMP_MAX_ACTIVE_LEVELS | 将嵌套活动并行区域的最大级别数设置为非负整数值。 |
| OMP_THREAD_LIMIT | 将要在整个 OpenMP 程序中使用的线程数设置为正整数。 |
其他多重处理环境变量也会影响 OpenMP 程序的执行,但它们不是 OpenMP 规范的一部分。下表对它们进行了概括。
表 2–2 多重处理环境变量
| 环境变量 | 功能 |
| PARALLEL | 为与传统程序兼容,设置 PARALLEL 环境变量的效果与设置 OMP_NUM_THREADS 的效果相同。然而,如果同时设置 PARALLEL 和 OMP_NUM_THREADS,则必须将它们设置为相同的值。 |
| SUNW_MP_WARN | 控制 OpenMP 运行时库发出的警告消息。如果设置为 TRUE,运行时库会给 stderr 发出警告消息;如果设置为 FALSE,则禁用警告消息。缺省值为 FALSE。 OpenMP 运行时库能够检查很多常见的 OpenMP 违规行为,如错误的嵌套和死锁。运行时检查会增加程序执行的开销。请参见第 3 章。 如果 SUNW_MP_WARN 设置为 TRUE,则运行时库会向 stderr 发出警告消息。如果程序注册一个回调函数以接受警告消息,则运行时库也将发出警告消息。程序可通过调用以下函数来注册用户回调函数: 回调函数的地址将作为参数传递给 sunw_mp_register_warn()。如果成功注册了回调函数,该函数将返回 0,如果注册失败则返回 1。 如果程序已注册了回调函数,libmtsk 将调用该注册的函数,将一个指针传递给包含错误消息的本地化字符串。从回调函数返回后,指向的内存将不再有效。 示例: setenv SUNW_MP_WARN TRUE |
| SUNW_MP_THR_IDLE | 控制 OpenMP 程序中空闲线程的状态,这些空闲线程正在某个屏障处等待或者正在等待要处理的新并行区域。可以将该值设置为下列某个值:SPIN、SLEEP、SLEEP(times)、SLEEP(timems)、SLEEP(timemc),其中 time 是一个整数,指定时间量,s、ms 和 mc 指定时间单位(分别为秒、毫秒和微秒)。 SPIN 指定空闲线程在屏障处等待时或等待要处理的新并行区域时应旋转。不带时间参数的 SLEEP 指定空闲线程应立即休眠。带时间参数的 SLEEP 指定线程进入休眠状态前应旋转等待的时间量。 缺省情况下,空闲线程经过一段时间的旋转等待后将进入休眠状态。SLEEP、SLEEP(0)、SLEEP(0s)、SLEEP(0ms) 和 SLEEP(0mc) 都是等效的。 请注意,如果同时设置 SUNW_MP_THR_IDLE 和 OMP_WAIT_POLICY,它们的值必须一致。 示例: |
| SUNW_MP_PROCBIND | 此环境变量可在 Solaris 和 Linux 系统上工作。SUNW_MP_PROCBIND 环境变量可用于将 OpenMP 程序的线程绑定到正在运行的系统上的虚拟处理器。虽然可以通过处理器绑定来增强性能,但是如果将多个线程绑定到同一虚拟处理器,则会导致性能下降。有关详细信息,请参见2.3 处理器绑定。 |
| SUNW_MP_MAX_POOL_THREADS | 指定线程池的最大大小。线程池只包含 OpenMP 运行时库创建的非用户线程。它不包含主线程或由用户程序显式创建的任何线程。如果将此环境变量设置为零,则线程池为空,并且将由一个线程执行所有并行区域。如果未指定,则使用缺省值 1023。有关详细信息,请参见4.2 控制嵌套并行操作。 请注意,SUNW_MP_MAX_POOL_THREADS 指定用于整个程序的非用户 OpenMP 线程的最大数量,而 OMP_THREAD_LIMIT 指定用于整个程序的用户和非用户 OpenMP 线程的最大数量。如果同时设置 SUNW_MP_MAX_POOL_THREADS 和 OMP_THREAD_LIMIT,则它们的值必须一致,以便将 OMP_THREAD_LIMIT 设置为比 SUNW_MP_MAX_POOL_THREADS 的值大一。 |
| SUNW_MP_MAX_NESTED_LEVELS | 指定活动嵌套并行区域的最大深度。活动嵌套深度大于此环境变量值的任何并行区域将只由一个线程来执行。如果并行区域是 OpenMP 并行区域(其 IF 子句的值为 false),则不会将该区域视为活动区域。如果未指定,则使用缺省值 4。有关详细信息,请参见4.2 控制嵌套并行操作。 请注意,如果同时设置 SUNW_MP_MAX_NESTED_LEVELS 和 OMP_MAX_ACTIVE_LEVELS,则必须将它们设置为相同的值。 |
| STACKSIZE | 设置每个线程的栈大小。值以千字节为单位。缺省线程栈大小在 32 位 SPARC V8 和 x86 平台上为 4 Mb,在 64 位 SPARC V9 和 x86 平台上为 8 Mb。 示例: setenv STACKSIZE 8192 将线程栈大小设置为 8 Mb STACKSIZE 环境变量还接受带有 B(字节)、K(千字节)、M(兆字节)或 G(千兆字节)后缀的数值。缺省单位为千字节。 请注意,如果同时设置 STACKSIZE 和 OMP_STACKSIZE,则必须将它们设置为相同的值。 |
| SUNW_MP_GUIDED_WEIGHT | 设置加权因子,该因子用于确定 在使用 GUIDED 调度的循环中为线程分配的块的大小。该值应该是正浮点数,并且应用于程序中所有使用 GUIDED 调度的循环。如果未设置,则采用缺省值 2.0。 |
| int sunw_mp_register_warn (void (*func)(void *)); |
| setenv SUNW_MP_THR_IDLE SPIN setenv SUNW_MP_THR_IDLE SLEEP setenv SUNW_MP_THR_IDLE SLEEP(2s) setenv SUNW_MP_THR_IDLE SLEEP(20ms) setenv SUNW_MP_THR_IDLE SLEEP(150mc) |
矩阵运算库blas, cblas, openblas, atlas, lapack, mk
基本数学库/API
BLAS
简介:基本线性代数子程序,Basic Linear Algebra Subprograms,是一个API标淮,用以规范发布基础线性代数操作的数值库(如矢量或矩阵乘法)。Netlib用Fortran实现了BLAS的这些API接口,得到的库也叫做BLAS。Netlib只是一般性地实现了基本功能,并没有对运算做过多的优化。在高性能计算领域,BLAS被广泛使用。为提高性能,各软硬件厂商则针对其产品对BLAS接口实现进行高度最佳化。
参考链接:
LAPACK
简介:线性代数库,也是Netlib用fortran语言编写的,其底层是BLAS。LAPACK提供了丰富的工具函式,可用于诸如解多元线性方程式、线性系统方程组的最小平方解、计算特徵向量、用于计算矩阵QR分解的Householder转换、以及奇异值分解等问题。该库的运行效率比BLAS库高。从某个角度讲,LAPACK也可以称作是一组科学计算(矩阵运算)的接口规范。Netlib实现了这一组规范的功能,得到的这个库叫做LAPACK库。
参考链接
ScaLAPACK
简介:ScaLAPACK(Scalable LAPACK 简称)是一个并行计算软件包,适用于分布式存储的 MIMD (multiple instruction, multiple data)并行计算机。它是采用消息传递机制实现处理器/进程间通信,因此使用起来和编写传统的 MPI 程序比较类似。ScaLAPACK 主要针对密集和带状线性代数系统,提供若干线性代数求解功能,如各种矩阵运算,矩阵分解,线性方程组求解,最小二乘问题,本征值问题,奇异值问题等,具有高效、可移植、可伸缩、高可靠性等优点,利用它的求解库可以开发出基于线性代数运算的并行应用程序。
参考链接
高级数学库
MKL
简介:英特尔MKL基于英特尔® C++和Fortran编译器构建而成,并使用OpenMP*实现了线程化。该函数库的算法能够平均分配数据和任务,充分利用多个核心和处理器。支持Linux/Win。
底层:
- BLAS:所有矩阵间运算(三级)均面向密集和稀疏 BLAS 实现了线程化。 许多矢量间运算(一级)和矩阵与矢量的运算(二级)均面向英特尔® 64 架构上 64 位程序中的密集型矩阵实现了线程化。 对于稀疏矩阵,除三角形稀疏矩阵解算器外的所有二级运算均实现了线程化。
- LAPACK:部分计算例程针对以下某类型的问题实现了线程化:线性方程解算器、正交因子分解、单值分解和对称特征值问题。 LAPACK 也调用 BLAS,因此即使是非线程化函数也可能并行运行。
- ScaLAPACK:面向集群的 LAPACK 分布式内存并行版本。
- PARDISO:该并行直接稀疏矩阵解算器的三个阶段均实现了线程化:重新排序(可选)、因子分解和解算(如果采用多个右侧项)。
- DFTs:离散傅立叶变换
- VML:矢量数学库
- VSL:矢量统计学库
参考资料:
Armadillo
简介:使用模板元编程技术,与Matlab相似,易于使用的C++矩阵库,提供高效的 LAPACK, BLAS和ATLAS封装包,包含了 Intel MKL, AMD ACM和 OpenBLAS等诸多高性能版本。
底层:
- BLAS/LAPACK:支持OpenBLAS、ACML、MKL
参考链接:
Eigen
简介:Eigen是可以用来进行线性代数、矩阵、向量操作等运算的C++库,它里面包含了很多算法。它支持多平台。Eigen采用源码的方式提供给用户使用,在使用时只需要包含Eigen的头文件即可进行使用。之所以采用这种方式,是因为Eigen采用模板方式实现,由于模板函数不支持分离编译,所以只能提供源码而不是动态库的方式供用户使用。
底层:
- BLAS/LAPACK:支持所有基于F77的BLAS或LAPACK库作为底层(EIGEN_USE_BLAS、EIGEN_USE_LAPACKE)
- MKL:支持MKL作为底层(EIGEN_USE_MKL_ALL)
- CUDA:支持在CUDA kernels里使用CUDA
- OpenMP:多线程优化
参考链接
- http://eigen.tuxfamily.org/index.php?title=Main_Page
- http://eigen.tuxfamily.org/dox/TopicUsingBlasLapack.html
- http://eigen.tuxfamily.org/dox/TopicUsingIntelMKL.html
线性代数库
关系
- 狭义的BLAS/LAPACK可理解为用于线性代数运算库的API
- Netlib实现了Fortran/C版的BLAS/LAPACK、CBLAS/CLAPACK
- 开源社区及商业公司针对API实现了BLAS(ATLAS、OpenBLAS)和LAPACK(MKL、ACML、CUBLAS)的针对性优化
- Eigen、Armadillo除自身实现线性代数运算库外还支持上述各种BLAS/LAPACK为基础的底层以加速运算
对比
- 备选:MKL、OpenBLAS、Eigen、Armadillo
- 接口易用程度:Eigen > Armadillo > MKL/OpenBLAS
- 速度:MKL≈OpenBLAS > Eigen(with MKL) > Eigen > Armadillo
其中:
- OpenBLAS没有单核版本,强行指定OMP_NUM_THREADS=1性能损失大,不考虑
- MKL直接使用学习成本较高,但是性能最强
- Armadillo效率和接口易用性不如Eigen
- Eigen的原生BLAS/LAPACK实现速度不如MKL、OpenBLAS,但是使用MKL做后台性能和MKL原生几乎一样,所以可以视情况决定是否使用MK
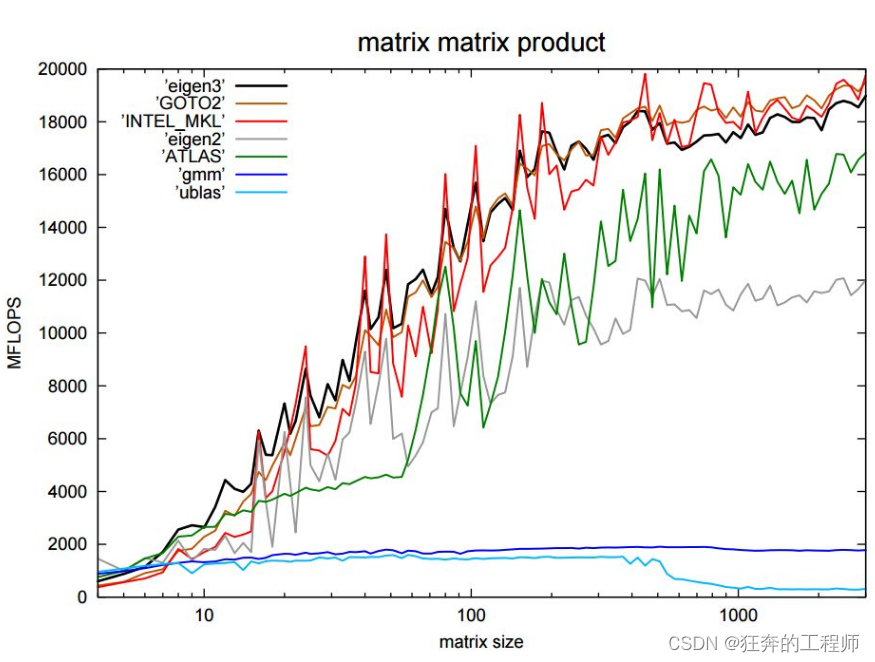
已经很好的给出了 BLAS 与 这些库的关系。我在这里补充一些几个矩阵库性能之间的对比。
Eigen官方对比,这份对比包括了常见的矩阵库包括:Eigen3, Eigen2, Intel MKL, ACML, GOTO BLAS, ATLAS等。注意:这份对比各个库均单线程运行。
注: MFLOPS(Million Floating-point Operations per Second,每秒百万个浮点操作),衡量计算机系统的技术指标,不能反映整体情况,只能反映浮点运算情况MFLOPS_百度百科()。

















 1530
1530

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









