










Advanced MapReduce Features
Overview of Localization
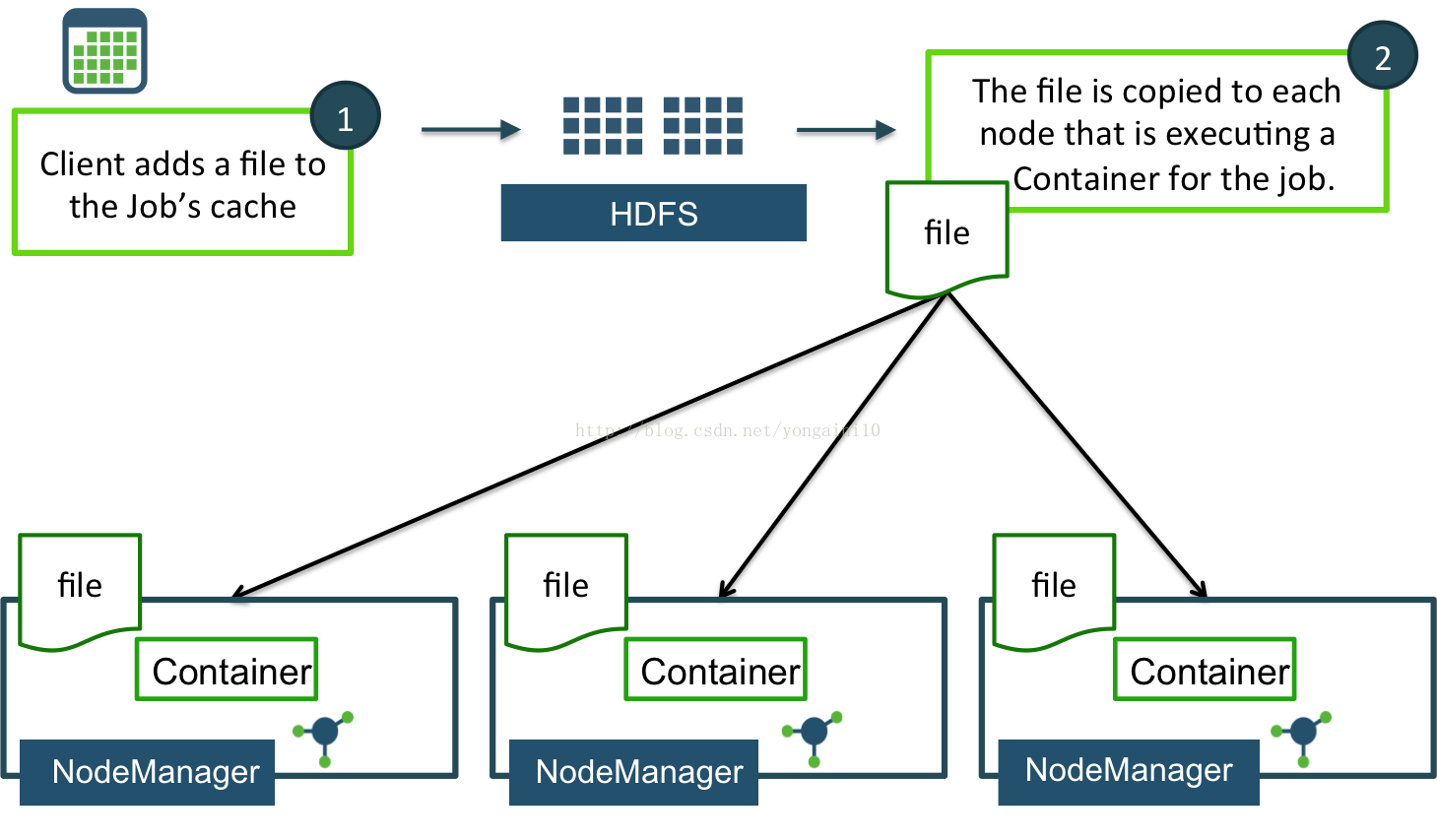
Localization is the process of copying or downloading remote resources onto the local file-system.
It is copied to the local machine so the resource can be accessed locally.Localization is implemented using LocalResources.
A LocalResource represents a file or library required torun a container.
The NodeManager is responsible for localizing the resource prior to launching thecontainer.
Typical examples of LocalResources include:
--Libraries required for starting the container such as a jar file--Configuration files required to configure the container once started (remote service URLs or application default configs, for example)
--A static dictionary file
Therefore if an external system has to update the remote resource it should be done via versioning. YARN will fail containers that depend on modified remote resources to prevent inconsistencies.
Each LocalResource can be of one of the following types:
FILE -- A regular file, either textual or binary.
ARCHIVE -- An archive, which is automatically unarchived by the NodeManager. As of now,NodeManager recognizes jars, tars, tar.gz files and .zip files.
PATTERN -- A hybrid of ARCHIVE and FILE types.
Distributing Files as a LocalResource
addCacheFile -- Adds a single file
addCacheArchive -- Adds a single archive
setCacheFiles -- Replaces the current files with the provided files
setCacheArchives -- Replaces the current archives with the provided archives
addFileToClassPath -- Adds a file to the cache and also to the CLASSPATH
addArchiveToClassPath -- Adds an archive to the cache and also to the CLASSPATH
•job.addCacheFile(new URI("myfiles/afile.txt"));
• job.addCacheArchive(new URI("helper.zip"));
Retrieving a LocalResource File
Use the getLocalCacheFiles method in the JobContext class for retrieving LocalResource files.
The method returns an array of Path references:A Mapper or Reducer only needs to invoke these methods once, so the files are typically retrieved in the setup method of the Mapper or Reducer.
•public class PayrollReducer extends Reducer<CustomerKey,
• Customer, Text, DoubleWritable> {
• private DataInputStream in;
• protected void setup(Context context)
• throws IOException, InterruptedException {
• Configuration conf = context.getConfiguration();
• Path [] files = context.getLocalCacheFiles();
• for(Path file : files) {
• if(file.getName().equals("zipcodes.txt")) {
• FileSystem fs = FileSystem.getLocal(conf);
• InputStream is = fs.open(file);
• in = new DataInputStream(is);
• }
• }
• }
• @Override
• protected void cleanup(Context context)
• throws IOException, InterruptedException {
• in.close();
• }
• //remainder of class definition...
• }
Performing Joins in MapReduce
From a high-level, there are essentially two options:
Map-side join -- The join is performed by the Mapper.
Shuffle(or reduce-side) join -- The join is performed by the Reducer.
The best option depends onthe size of the data and how it is stored in HDFS.
Three common scenarios for performing Big Data joins.
Scenario #1: Map-side Replicated Join

If one of the datasets is small enough to fit in memory, then it is possible to perform a map-side join, also referred to as a replicated join.The smaller dataset is stored in a file and distributed to all Mappers, using aLocalResource.
Here is how a map-side join is typically implemented:
1.Add the smaller dataset as a LocalResource.2.In the setup method of each Mapper, retrieve the smaller dataset and load it into memory (use a HashMap , TreeMap or similar data structure).
3.As records from the larger dataset come into the map method, use the smaller dataset as a filter to check for a matching record.
4.If a match occurs, piece together the desired data from the two datasets and output it from the Mapper.
Scenario #2: Bucket Join
In this scenario, the size of the datasetsis not the issue. Instead, the data needs to be partitioned in a very specific manner:
1.Each dataset needs to have the exact same number of partitions (i.e. the same number of input splits).2.Both datasets need to be sorted by the join key.
3.All records that need to be joined must reside on the same partition (so that the same Mapper processes both inputs).
The join occurs before the data gets to the map method, and all the developer must do is specify if it is aninner join or an outer join.
The compose method of CompositeInputFormat is used to configure the join statement,which is then set as a configuration property.
For example, the following code defines an inner join on two datasets that reside in inputDir1 and inputDir2:
- conf.setInputFormat(CompositeInputFormat.class);
- String joinStmt = CompositeInputFormat.compose("inner",
- TextInputFormat.class,
- inputDir1,
- inputDir2);
- conf.set(CompositeInputFormat.JOIN_EXPR, joinStmt);
Scenario#3: Reduce-side Join

A reduce-side join is not efficient,because a potentially large number of records get shuffled and sorted, only tobe ignored after the join. But it is a general way to accomplish a join withoutany type of requirements on the datasets.
Role of the Mapper
The Mapper plays a key role in a reduce-side join, because the Mapper must output data in such away that records needing to be joined get sent to the same Reducer.
Here is how a reduce-side join is typically implemented:
1.The Mapper tags each record with the record’s source,so that the Reducer knows which dataset the record belongs to.
2.The output key of each record is the join key, so thatthe records from the two datasets that need to be joined get sent to the same Reducer.
3.A secondary sort occurs on the data in such a way that the fields from one dataset appear before the fields of the other dataset in the Reducer. More specifically, the fields of the left dataset appear first inthe values parameter of the reduce method.
An easy way to ensure this is to give the records the same key and let the shuffle/sort phase automatically send these records to the same Reducer.
In the reduce method, since the values are also sorted, the first object in values will represent the left-hand data in the join,and all subsequent objects in values (if any) will represent the right-hand data in the join.
Bloom Filters

The result has no false negatives, but possibly a false positive (<c,9>)
A Bloom filter is a small dataset that is used for checking membership in a larger set.
Records may pass through a Bloom filter that should not, but records will never be filtered out if they should not be.
Internally, a Bloom filter is nothing more than an array of bits that are initially all set to 0. When a new BloomFilter instance is instantiated, three values are specified:
1.The size of the bit array: a nice feature of a Bloom filter is that its size is fixed.
2.The number of hash functions to consider: when an object is added to a Bloom filter, internally it gets hashed n number of times,which generates n indexes, which results in those n bits in the Bloomfilter getting switched to 1.
3.The type of hashing function to use.
• BloomFilter filter = new BloomFilter(50000, 15, Hash.JENKINS_HASH);
This Bloom filter will be of size 50,000 bits, and objects put in the filter will get hashed 15 times using the Jenkins hash function.
The MapReduce API contains two classes that implement hashing: JenkinsHash and MurmurHash.
One usage of Bloom filters in MapReduce is to improve the performance of joins on large datasets. Instead of processing every record on both sides of the join,you build a Bloom filter from those records and reduce the number of records that need to go through the shuffle/sort phase.
The result is a reduce-side join with false positives, meaning some records will be sent to the reducer that should not have appeared in the join.















 1677
1677











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









