







- 介绍
一般的类和方法,只能使用具体的类型:要么是基本类型,要么是自定义的类。如果要编写可以应用于多种类型的代码,这种刻板的限制对代码的束缚就会很大。
1.1 Java泛化机制
在考虑代码重用的时候, 自然的想法是, 希望写一份逻辑可以用于不同的场景, 比如写一份算法逻辑可以使用于各种类型, 这就是泛化的需求。Java针对这样的泛化需求有以下三种泛化机制。
(1)类多态
对于面向对象语言而言, 首先想到的泛化方法, 肯定是多态,尤其对于Java这样的单根继承体系, 多态应该可以解决大部分问题,凡是需要说明类型的地方都使用基类,能具备更好的灵活性。但这样做的问题是, 任何类(除final类)都可以扩展,会有一些性能损耗,在效率上也有问题,往往还是会限定在具体的基类上。
(2)接口
当然有时候通过类多态来实现泛化的限制太强了, 而Java中支持接口, 如果通过接口来实现泛化, 会更灵活一些,因为不需要严格的继承关系, 只需要实现了该接口就可以。同样,这种泛化机制也会限定在具体的接口上。
(3)泛型
我们希望达到的目的是编写更通用的代码,要使代码能应用于“某种不具体的类型”,而不是一个具体的类或接口,这是一种更高的泛化要求, 在编写逻辑时, 对适用类型没有任何假设(基类, 接口),由此出现Java SE5重大变化之一:泛型,用来解决这个需求。
1.2 Java泛型
泛型这个术语的意思是:“适用于许多许多的类型”。
泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数,使代码可以应用于多种类型,而不是一个具体的接口或类。这种参数类型可以用在类、接口和方法的创建中,分别称为泛型类、泛型接口和泛型方法。
比如说工厂模式,我不知道生产出来的对象是什么类型的,同时我也不希望我的工厂只能生产一种类型的对象,那么这个时候就不能写死,如果不写死的话应该怎么操作才能符合上面的要求呢,这时候用Java泛型机制就可以解决了,我在具体的生产对象的时候,才确切地说明我要生成的对象是什么类型的。
现在我们通过一个例子来阐述一下,泛型引入的好处。


2 分类
2.1 泛型类
有许多原因促成了泛型的出现,而最引人注意的一个原因,就是为了创建容器类。
下面的例子没有采用泛型的概念,通过根类object类来强制转换实现。
class Apple {}
public class Holder1 {
private Apple a;
public Holder1(Apple a) { this.a = a; }
Apple get() { return a; }
}
Holder1缺乏可重用性,无法持有其他类型对象。
public class Holder2 {
private Object a;
public Holder2(Object a) { this.a = a; }
public void set(Object a) { this.a = a; }
public Object get() { return a; }
}
Holder2可持有任何类型的对象
public static void main(String[] args) {
Holder2 h2 = new Holder2(new Apple());
Apple a = (Apple)h2.get();
h2.set("Not an Apple");
String s = (String)h2.get();
h2.set(1); // Autoboxes to Integer
Integer x = (Integer)h2.get();
}
此时与其使用Object,我们更喜欢暂时不指定类型,而是稍后再决定具体使用什么类型。要达到这个目的,需要使用类型参数,用尖括号括住,放在类名后面。然后在使用这个类的时候,再用实际的类型替换此类型参数。在下面的例子中,T就是类型参数:
public class Holder3<T> {
private T a;
public Holder3(T a) { this.a = a; }
public void set(T a) { this.a = a; }
public T get() { return a; }
public static void main(String[] args) {
Holder3<Apple> h3 =
new Holder3<Apple>(new Apple());
Apple a = h3.get(); //不需要强制转换
// h3.set("Not an Apple"); // Error
// h3.set(1); // Error
}
}
当你创建Holder3对象时,必须指明想要持有什么类型的对象,将其置于尖括号内。
接下来介绍可以持有多个不同类型对象的泛型类。
public class TwoTuple <A,B>{
public final A first;
public final B second;
public TwoTuple(A a, B b){
first=a;second=b;
}
public String toString(){
return "first:"+first+" "+first.getClass().getSimpleName()+
"\nsecond: "+second+" "+second.getClass().getSimpleName();
}
}
上面是常用的Tuple工具类,它就是一个泛型类,这个类有两个泛型参数A和B。使用方法如下:
public static void main(String[] args) {
TwoTuple<String, Integer> twoTuple = new TwoTuple<String, Integer>("Apple", 123);
System.out.println(twoTuple);
}
输出:
first: Apple String
second: 123 Integer
泛型类也可以被继承,下面的代码在继承的时候指定了类型,然后它就不再是泛型类,在实例化的时候不需要用尖括号指定类型。
class StringIntegerTwoTuple extends TwoTuple<String,Integer>{
StringIntegerTwoTuple(String s, Integer integer) {
super(s, integer);
}
public static void main(String[] args) {
StringIntegerTwoTuple stringIntegerTwoTuple = new
StringIntegerTwoTuple("Apple", 123);
}
}
输出结果同样为:
first: Apple String
second: 123 Integer
当然,我们也可以让继承后的类仍然是泛型类,下面的ThreeeTuple类有三个泛型参数,前两个从TwoTuple继承而来,第三个是新加属性的类型。
public class ThreeTuple<A, B, C> extends TwoTuple<A, B> {
private final C third;
public ThreeTuple(A a, B b, C c) {
super(a, b);
this.third = c;
}
public C getThird() {
return third;
}
public String toString(){
return "first:"+first+" "+first.getClass().getSimpleName()+
"\nsecond: "+second+" "+second.getClass().getSimpleName()+
"\nthird:"+third+" "+third.getClass().getSimpleName();
}
public static void main(String[] args) {
ThreeTuple<String, Integer, Long> threeTuple = new ThreeTuple<String, Integer, Long>(" Apple", 123, 123L);
System.out.println(threeTuple);
}
}
输出:
first: Apple String
second: 123 Integer
third:123 Long
2.2 泛型接口
泛型也可以应用于接口,在泛型接口中,生成器是一个很好的理解,看如下的生成器接口定义:
public interface Generator<T> {
public T next();
}
可看出接口使用泛型与类使用泛型没什么区别,我们定义一个生成器类来实现这个接口:
public class FruitGenerator implements Generator<String> {
private String[] fruits = new String[]{"Apple", "Banana", "Pear"};
@Override
public String next() {
Random rand = new Random();
return fruits[rand.nextInt(3)];
}
}
public class Main {
public static void main(String[] args) {
FruitGenerator generator = new FruitGenerator();
System.out.println(generator.next());
System.out.println(generator.next());
System.out.println(generator.next());
System.out.println(generator.next());
}
}
输出:
Banana
Banana
Pear
Banana
生成器(generator)是一种专门负责创建对象的类,不需要任何参数就知道如何创建对象。
2.3 泛型方法
到目前为止,我们看到的泛型,都是应用于整个类上,但同样可以在类中包含参数化方法,而这个方法所在的类可以是泛型类,也可以不是泛型类。也就是说,是否拥有泛型方法,与其所在的类是否是泛型没有关系。
泛型方法使得该方法能够独立于类而产生变化。以下是一个基本的原则:无论何时,只要你能做到,你就应该尽量使用泛型方法。如果使用泛型方法可以取代整个类的泛型化,就应只使用泛型方法。
要定义泛型方法,只需将泛型参数列表置于返回值之前,修饰符之后。

public class GenericMethods {
public <T> void f(T x) {
System.out.println(x.getClass().getName());
}
public static void main(String[] args) {
GenericMethods gm = new GenericMethods();
gm.f("");
gm.f(1);
gm.f(1.0);
gm.f(1.0F);
gm.f('c');
gm.f(gm);
}
}
输出:
java.lang.String
java.lang.Integer
java.lang.Double
java.lang.Float
java.lang.Character
GenericMethods
GenericMethods类并不是参数化的,尽管这个类和其内部的方法可以被同时参数化,但是在这个例子中,只有方法f()拥有类型参数。这是由该方法的返回类型前面的类型参数列表指明的。
注意,当使用泛型类时,必须在创建对象的时候指定类型参数的值,而使用泛型方法的时候,通常不必指明参数类型,因为编译器会为我们找出具体的类型。这称为类型参数推断(type argument inference)。因此,我们可以像调用普通方法一样调用f(),而且就好像是f()被无限次地重载过。它甚至可以接受GenericMethods作为其类型参数。这样在定义方法的时候不必考虑以后到底需要处理哪些类型的参数,大大增加了编程的灵活性。
如果调用f()时传入基本类型,自动打包机制就会介入其中,将基本类型的值包装为对应的对象。
再看一个泛型方法和可变参数的例子:
public class GenericMethods{
public static <T> void f (T... args) {
for (T x : args) {
System.out.println(x.getClass().getName());
}
}
public static void main(String[] args) {
GenericMethods gm = new GenericMethods();
f ("", 1, 1.0, 1.0F,’c’, gm);
}
}
输出和前一段代码相同,可以看到泛型可以和可变参数非常完美的结合。
注意,对于一个static的方法而言,无法访问泛型类的类型参数,所以,如果static方法需要使用泛型能力,就必须使其成为泛型方法。

有了类型参数推断和static方法,我们可以重新编写之前的元组工具,使其更通用。
package net.mindview.util;
class Apple{}
public class Tuple {
public static <A,B> TwoTuple<A,B> tuple(A a,B b){
return new TwoTuple<A,B> (a,b);
}
public static <A,B,C> ThreeTuple<A,B,C> tuple(A a,B b,C c){
return new ThreeTuple<A,B,C>(a,b,c);
}
public static void main(String[] args){
System.out.println(Tuple.tuple("Apple", 123));
System.out.println(Tuple.tuple("Apple", 123,new Apple()));
}
}
输出:
first: Apple String
second: 123 Integer
first: Apple String
second: 123 Integer
third:net.mindview.util.Apple@9cab16 Apple
3 实现原理
Java的泛型是伪泛型,其实现原理就是擦除。在编译期间,所有的泛型信息都会被擦除掉。正确理解泛型概念的首要前提是理解类型擦除(type erasure)。
3.1 类型擦除
Java中的泛型基本上都是在编译器这个层次来实现的,在生成的Java字节码中是不包含泛型中的类型信息的。使用泛型的时候加上的类型参数,会在编译器在编译的时候去掉,这个过程就称为类型擦除。
如在代码中定义的List<object>和List<String>等类型,在编译后都会擦除为原生类型List。JVM看到的只是List,而由泛型附加的类型信息对JVM来说是不可见的。Java编译器会在编译时尽可能的发现可能出错的地方,但是仍然无法避免在运行时刻出现类型转换异常的情况。下面的程序会认为ArrayList<String>和ArrayList<Integer>是相同的类型。
public class ErasedTypeEquivalence {
public static void main(String[] args) {
Class c1 = new ArrayList<String>().getClass();
Class c2 = new ArrayList<Integer>().getClass();
System.out.println(c1 == c2);
}
}
输出:
True
所以,在泛型代码的内部,无法获得任何有关泛型参数类型的信息。
Java的泛型是使用擦除来实现的,这意味着当你在使用泛型时,任何具体的类型都会被擦除了,你唯一知道的就是你在使用一个对象。
擦除不是一个语言特性,而是泛型实现的一种折中,其核心动机是使得泛化的客户端可以使用非泛化的类库,反之亦然,这经常被称之为“迁移兼容性”,来实现非泛型代码和泛型代码共存,且不破坏现有类库。
public class HasF {
public void f() { System.out.println("HasF.f()"); }
}
class Manipulator<T> {
private T obj;
public Manipulator(T x) { obj = x; }
// Error: cannot find symbol: method f():
public void manipulate() { obj.f(); }
}
public class Manipulation {
public static void main(String[] args) {
HasF hf = new HasF();
Manipulator<HasF> manipulator =
new Manipulator<HasF>(hf);
manipulator.manipulate();
}
}
编译提示: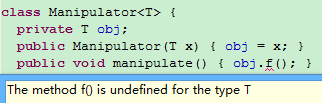
上面的代码没有通过编译,就是由于擦除,会将T替换为Object,这样就没法调用f()方法了。可以使用边界来解决这个问题。
class Manipulator<T extends HasF> {
private T obj;
public Manipulator(T x) { obj = x; }
public void manipulate() { obj.f(); }
}
此次输出:HasF.f()
泛型类型参数将擦除到它的第一个边界(可能有多个边界,只能有一个类做边界,而且必须是第一个边界)。类型参数的擦除,编译器实际上会把类型参数替换为它的擦除后类型,就像上面的例子,T擦除到了HasF,就好像在类的声明中用HasF替换了T一样。
擦除使得现有的非泛型客户端代码能在不改变的情况下继续使用,这是一个崇高的动机,因为它不会突然间破坏现有所有的代码。
3.2 擦除的补偿
Java泛型在instanceof、创建类型实例,及创建数组、转型时都会有问题。有时必须通过引入类型标签(即你的类型的Class对象)进行补偿,使用动态的isInstance()方法,而不是instanceof。
class Fruits {}
class Apple extends Fruits {}
public class ClassTypeCapture<T> {
Class<T> kind;
public ClassTypeCapture(Class<T> kind) {
this.kind = kind;
}
public boolean f(Object arg) {
return kind.isInstance(arg);
}
public static void main(String[] args) {
ClassTypeCapture<Fruits> ctt1 = new ClassTypeCapture<Fruits>(Fruits.class);
System.out.println(ctt1.f(new Fruits()));
System.out.println(ctt1.f(new Apple()));
ClassTypeCapture<Apple> ctt2 = new ClassTypeCapture<Apple>(Apple.class);
System.out.println(ctt2.f(new Fruits()));
System.out.println(ctt2.f(new Apple()));
}
}
输出:
true
true
false
true
Java中 new T()尝试无法实现,解决方案是传递一个工厂对象,并使用它来创建新的实例。最便利的工厂对象就是Class对象,引入类型标签,就可以转而使用动态的newInstance()来创建类型实例。
class ClassAsFactory<T>{
T x;
public ClassAsFactory(Class<T> kind){
try{
x = kind.newInstance();
} catch(Exception e){
throw new RuntimeException(e);
}
}
}
但是对于没有默认构造器的类,比如Integer,上述方法不奏效了,可以使用显式的工厂。
interface Factory<T> {
T create();
}
class IntegerFactory implements Factory<Integer> {
public Integer create() {
return new Integer(0);
}
}
public class InstanceCreation<T> {
private T x;
public <F extends Factory<T>> InstanceCreation(F factory) {
x = factory.create();
}
public T getInstance(){
return x;
}
public static void main(String[] args) {
InstanceCreation<Integer> creator = new InstanceCreation<Integer>(new IntegerFactory());
System.out.println(creator.getInstance().getClass());
}
}
输出:class java.lang.Integer
4 通配符与上下界
4.1 无限制的通配符
使用原生态类型很危险,用无限制的通配符类型来替代。在使用泛型类的时候,既可以指定一个具体的类型,如List<String>就声明了具体的类型是String;也可以用通配符?来表示未知类型。
List<?>所声明的就是所有类型都是可以的,但是List<?>并不等同于List<Object>。List<Object>实际上确定了List中包含的是Object及其子类,在使用的时候都可以通过Object来进行引用;而List<?>则其中所包含的元素类型是不确定,其中可能包含的是String,也可能是Integer。如果它包含了String的话,往里面添加Integer类型的元素就是错误的。正因为类型未知,就不能通过new ArrayList<?>()的方法来创建一个新的ArrayList对象,因为编译器无法知道具体的类型是什么,但是对于 List<?>中的元素却总是可以用Object来引用的,因为虽然类型未知,但肯定是Object及其子类。考虑下面的代码:
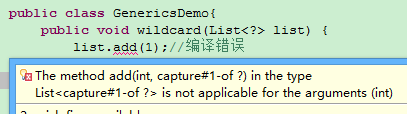
如上所示,试图对一个带通配符的泛型类进行操作的时候,总是会出现编译错误,其原因在于通配符所表示的类型是未知的,?无法确定是否将来匹配的是Integer类型。
在Holder3中添加toString方法:
public String toString(){ // 直接打印
return this.a.toString() ;
}
再让我们看这段代码:
public class GenericsDemo{
public static void main(String args[]){
Holder3< String> h3 = new Holder3< String>("Apple") ; // 使用String为泛型类型
fun(h3) ;
}
public static void fun(Holder3< ?> obj){ // 可以接收任意的泛型对象
System.out.println(obj) ;
}
};
输出:Apple
由此说明通配符可以调用与参数化无关的方法,不能调用与参数化有关的方法。在Java集合框架中,对于参数值是未知类型的容器类,只能读取其中元素,不能向其中添加元素,其类型是未知,所以编译器无法识别添加元素的类型和容器的类型是否兼容,唯一的例外是NULL。
4.2 有限制的通配符
因为对于List<?>中的元素只能用Object来引用,在有些情况下不是很方便,可以使用上下界来限制未知类型的范围。如List<? extends Number>说明List中可能包含的元素类型是Number及其子类。而List<? super Number>则说明List中包含的是Number及其父类。当引入了上界之后,在使用类型的时候就可以使用上界类中定义的方法。比如访问 List<? extends Number>的时候,就可以使用Number类的intValue等方法。
public class GenericsDemo1 {
public static void main(String args[]) {
Holder3<Integer> h1 = new Holder3<Integer>(1); // 声明Integer的泛型对象
Holder3<Float> h2 = new Holder3<Float>(1.0F); // 声明Float的泛型对象
fun(h1);
fun(h2);
}
public static void fun(Holder3<? extends Number> obj) { // 只能接收Number及其Number的子类
System.out.println(obj);
}
};
输出:
1
1.0
public class GenericsDemo2 {
public static void main(String args[]){
Holder3< String> h1 = new Holder3< String>("Apple") ; // 声明String的泛型对象
Holder3< Object> h2 = new Holder3< Object>(new Object()) ; // 声明Object的泛型对象
fun(h1) ;
fun(h2) ;
}
public static void fun(Holder3<? super String> obj) { // 只能接收String或Object类型的泛型
System.out.println(obj);
}
}
输出:
Apple
java.lang.Object@757aef
4.3 存取原则和PECS法则
总结 ? extends 和 the ? super 通配符的特征,我们可以得出以下结论:
如果你想从一个数据类型里获取数据,使用 ? extends 通配符
如果你想把对象写入一个数据结构里,使用 ? super 通配符
如果你既想存,又想取,那就别用通配符。
PECS法则:Bloch提醒说,这PECS是指”Producer-Extends, Consumer-Super”,这个更容易记忆和运用,如果参数化类型表示一个T生产者,就使用<? extends T>,如果表示一个T消费者,就是用<? super T>。
这就是Maurice Naftalin在他的《Java Generics and Collections》这本书中所说的存取原则,以及Joshua Bloch在他的《Effective Java》这本书中所说的PECS法则。
5 协变和逆变
首先看看协变和逆变的定义:
如果S是T的子类型,如果可以把Collection[S]当作Collection[T]的子类型,就可以说Collection与它的参数类型保持协变
如果S是T的子类型,如果可以把Collection[T]当作Collection[S]的子类型,就可以说Collection与它的参数类型保持逆变
在java里数组默认就是协变的,但集合是不协变的:
Object[] array=new String[10];//正确
List<String> stringList = new ArrayList<String>();
List<Object> objectList=stringList;//错误
因为上转型会有风险,我如果将放Apple的集合转型为Fruit的集合,再放入Orange,这个理论是支持的,但结果并不是我们想要的。
class Fruit{}
class Apple extends Fruit{}
class Jonathan extends Apple{}
class Orange extends Fruit{}
java为解决这个问题,引入了通配符(?)。通配符代表你不需要知道它的实际类型,只知道它的上界或下界,或者把它当作Object来看待。
首先看协变,为避免类型转换风险,协变数据只允许读取,不允许添加和修改数据:
class convert{
public static void main(String[] args) {
List<Apple> apples = new ArrayList<Apple>();
apples.add(new Apple());
// List<Fruit> fruits=apples; //不能转换
List<? extends Fruit> fruits=apples;
Fruit fruit = fruits.get(0);
// fruits.add(new Apple()); //不能添加数据
// fruits.add(new Fruit());//不能添加数据
}
}
再来看看逆变,接上面的例子,现在我们集合可以操作数据。
List<? super Apple> apples2 = apples;
apples2.add(new Apple());
apples2.add(new Jonathan());
6 异常
出错应尽快发现,最好在编译时发现。
使用原生态类型(失掉类型安全性)提供兼容性—移植兼容性,会在运行时导致异常,不要在新代码中使用
泛型有子类型化的规则:List<String>可传递给类型List的参数,但不能传递给类型List<Object>的参数
要尽可能消除每一个非受检警告,如果无法消除并确定代码是类型安全的才可以用@SuppressWarning
(“unchecked”)注解来禁止这条警告

泛型只在编译时强化类型信息,并在运行时丢弃—擦除
transactionTemplate.execute(new TransactionCallback<Object>() {
public Object doInTransaction(TransactionStatus status) {
return add();
}
});
public <T> T execute(TransactionCallback<T> action) throws TransactionException {…}
7 总结
泛型实现了参数化类型的概念,使代码可以应用于多种类型。要定义泛型方法,只需将泛型参数列表置于返回值之前:在调用泛型方法的时候,不需要显式指定参数类型,java会自动进行类型推断。在方法名前用尖括号指出类型。借助类型推断,可以帮助我们在创建泛型对象时简化代码。
java为了兼容JDK5前的代码,在实现泛型的时候,采用了“类型擦除”,虽然我们的类参数使用了泛型,java最后还是会当作Object来处理,只不过在编译时做了类型检查,在我们获取数据 时做隐式转换 罢了。
7.1 优点
1)类型安全:提高Java程序的类型安全,通过知道使用类型定义的变量的类型限制,将运行时期的类转换异常体现在编译时期;
简单而安全地创建复杂模型,示例可参见《Java 编程思想》371页。
2)消除强制类型转换:消除源代码中的许多强制类型转换,这使得代码更加可读,并且减少了出错机会
3)潜在的性能收益:泛型为较大的优化带来可能。在泛型的初始实现中,编译器将强制类型转换(如果没有泛型的话,程序员会指定这些强制类型转换)插入生成的字节码中。但是更多类型信息可用于编译器这一事实,为未来版本的JVM优化带来可能。由于泛型的实现方式,支持泛型(几乎)不需要JVM或类文件更改。所有工作都在编译器中完成,编译器生成类似于没有泛型(和强制类型转换)时缩写的代码,只是更能确保类型安全而已。
7.2 缺点
需要向程序中加入更多的代码,但泛型方法的类型参数推断可以简化一部分工作
基本类型无法作为类型参数,但Java SE5具备自动打包和拆包的功能。
Java泛型限于擦除,不像C++泛型一样在模板被实例化时,能知道模板参数的类型,导致不能在某些重要的上下文环境中使用















 91
91











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









