









Apache Sqoop是一种工具,用于在Apache Hadoop和结构化数据存储(如关系数据库)之间高效传输批量数据 。
模块开发–数据仓库的设计
维度建模的基本概念
维度建模(dimensional modeling)是专门用于分析数据库、数据仓库、数据集市建模的方法。数据集市可以理解为一种“小型数据仓库”。
-
维度表(dimension)
维度表是你要对数据进行分析时所用的一个量,比如你要分析产品销售情况,你可以选择按类别来进行分析,或按区域来分析。这样的分析就构成一个维度。再比如"昨天下午我在星巴克花费 200 元喝了一杯卡布奇诺"。那么以消费为主题进行分析,可从这段信息中提取三个维度:时间维度(昨天下午),地点维度(星巴克), 商品维度(卡布奇诺)。通常来说维度表信息比较固定,且数据量小。
-
事实表
事实表表示对分析主题的度量。事实表包含了与各维度表相关联的外键,并通过JOIN 方式与维度表关联。事实表的度量通常是数值类型,且记录数会不断增加,表规模迅速增长。 比如上面的消费例子, 它的消费事实表结构示例如:消费事实表: Prod_id(引用商品维度表), TimeKey(引用时间维度表),Place_id(引用地点维度表), Unit(销售量)。
总的说来, 在数据仓库中不需要严格遵守规范化设计原则。 因为数据仓库的主导功能就是面向分析,以查询为主,不涉及数据更新操作。 事实表的设计是以能够正确记录历史信息为准则,维度表的设计是以能够以合适的角度来聚合主题内容为准则。
维度建模三种模式
-
星型模式
星形模式(Star Schema)是最常用的维度建模方式。 星型模式是以事实表为中心,所有的维度表直接连接在事实表上,像星星一样。
星形模式的维度建模由一个事实表和一组维表成,且具有以下特点:
1. 维度只和事实表关联,维度之间没有关联。 2. 每个维度主键为单例,且该主键放置在事实表中,作为两边连接的外键。 3. 以事实表为核心,维表围绕核心呈星形分布。
-
雪花模式
雪花模式(Snowflake Schema)是对星形模式的扩展。 雪花模式的维度表可以拥有其他维度表的,虽然这种模型相比星型更规范一些,但是由于这种模型不太容易理解,维护成本比较高,而且性能方面需要关联多层维表,性能也比星型模型要低。所以一般不是很常用。

-
星座模式
星座模式是星型模式延伸而来,星型模式是基于一张事实表的,而星座模式是基于多张事实表的,而且共享维度信息。
前面介绍的两种维度建模方法都是多维表对应单事实表,但在很多时候维度空间内的事实表不止一个,而一个维表也可能被多个事实表用到。 在业务发展后期,绝大部分维度建模都采用的是星座模式。

ETL 之结果导出–sqoop
ETL 工作的实质就是从各个数据源提取数据,对数据进行转换,并最终加载填充数据到数据仓库维度建模后的表中。 只有当这些维度/事实表被填充好, ETL 工作才算完成
Sqoop 是 Hadoop 和关系数据库服务器之间传送数据的一种工具。它是用来从关系数据库如: MySQL, Oracle 到 Hadoop 的 HDFS,并从 Hadoop 的文件系统导出数据到关系数据库。 由 Apache 软件基金会提供。
Sqoop: “SQL 到 Hadoop 和 Hadoop 到 SQL” 。

Sqoop 工作机制是将导入或导出命令翻译成 mapreduce 程序来实现
在翻译出的 mapreduce 中主要是对 inputformat 和 outputformat 进行定制。
sqoop 的安装
安装 sqoop 的前提是已经具备 java 和 hadoop 的环境。
-
上传安装包并解压:tar -zxvf xxx.gz
-
配置文件修改( $SQOOP_HOME/conf )
cp sqoop-env-template.sh sqoop-env.sh
vi sqoop-env.sh
export HADOOP_COMMON_HOME=/opt/software/hadoop-2.6.5
export HADOOP_MAPRED_HOME=/opt/software/hadoop-2.6.5
export HIVE_HOME=/opt/software/hive -
加入 mysq 的 jdbc 驱动包到 lib 下
-
验证启动:bin/sqoop list-databases --connect jdbc:mysql://vm2:3306/ --username root --password 123456

Sqoop 导入
-
导入 mysql 表数据到 HDFS
bin/sqoop import \ --connect jdbc:mysql://node:3306/userdb \ --username root \ --password 123456 \ --target-dir /sqoopresult \ --table emp --m 1其中–target-dir 可以用来指定导出数据存放至 HDFS 的目录;
mysql jdbc url 请使用 ip 地址。
–table 是导出那张表的数据
–m 用几个mapreduce执行为了验证在 HDFS 导入的数据,使用以下命令查看导入的数据:
hdfs dfs -cat /sqoopresult/part-m-00000

-
导入 mysql 表数据到 HIVE
-
将关系型数据的表结构复制到 hive 中
bin/sqoop create-hive-table \ --connect jdbc:mysql://vm2:3306/userdb \ --table emp_add \ --username root \ --password 123456 \ --hive-table bw.emp_add_sp其中:
–table emp_add 为 mysql 中的数据库 sqoopdb 中的表。
–hive-table emp_add_sp 为 hive 中新建的表名称。 -
从关系数据库导入文件到 hive 中
bin/sqoop import \ --connect jdbc:mysql://node5:3306/userdb \ --username root \ --password root \ --table emp_add \ --hive-table bw.emp_add_sp \ --hive-import \ --m 1
-
-
导入表数据子集
--where 可以指定从关系数据库导入数据时的查询条件。它执行在各自的数据库服务器相应的 SQL 查询,并将结果存储在 HDFS 的目标目录。bin/sqoop import \ --connect jdbc:mysql://node5:3306/userdb \ --username root \ --password root \ --where "city ='sec-bad'" \ --target-dir /wherequery3 \ --table emp_add --m 1复杂查询条件:
bin/sqoop import \ --connect jdbc:mysql://node5:3306/userdb \ --username root \ --password root \ --target-dir /wherequery10 \ --query 'select id,name,deg from emp WHERE id>1203 and $CONDITIONS' \ --split-by id \ --fields-terminated-by '\t' \ --m 1 -
增量导入
增量导入是仅导入新添加的表中的行的技术。
--check-column (col) 用来作为判断的列名,如 id
--incremental (mode) append:追加,比如对大于 last-value 指定的值之后的记录进行追加导入。 lastmodified:最后的修改时间,追加 last-value 指定的日期之后的记录。
--last-value (value) 指定自从上次导入后列的最大值(大于该指定的值),也可以自己设定某一值
假设新添加的数据转换成 emp 表如下:
1206, satish p, grp des, 20000, GR。
下面的命令用于在 EMP 表执行增量导入:bin/sqoop import \ --connect jdbc:mysql://node5:3306/userdb \ --username root \ --password root \ --table emp --m 1 \ --incremental append \ --check-column id \ --last-value 1205Sqoop 导出
将数据从 HDFS 导出到 RDBMS 数据库导出前, 目标表必须存在于目标数据库中。默认操作是从将文件中的数据使用 INSERT 语句插入到表中,更新模式下,是生成 UPDATE语句更新表数据。
-
导出 HDFS 数据到 mysql
数据在 HDFS 中 emp/ 目录的 emp_data 文件中。
1201,gopal,manager,50000,TP
1202,manisha,preader,50000,TP
1203,kalil,php dev,30000,AC
1204,prasanth,php dev,30000,AC
1205,kranthi,admin,20000,TP
1206,satishp,grpdes,20000,GR
首先,需要手动创建 mysql 中的目标表CREATE TABLE employee ( id INT NOT NULL PRIMARY KEY, name VARCHAR(20), deg VARCHAR(20), salary INT, dept VARCHAR(10));然后执行导出命令:
bin/sqoop export \ --connect jdbc:mysql://node5:3306/userdb \ --username root \ --password root \ --table employee \ --export-dir /sqoopresult/part-m-00000还可以用下面命令指定输入文件的的分隔符
–input-fields-terminated-by ‘\t’
如果运行报错如下:
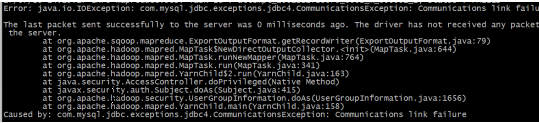
则需要吧 localhost 改为 ip 或者域名。
实例如下,将电机流模型表导出到 mysql。sqoop export \ --connect jdbc:mysql://hdp-node-01:3306/webdb --username root --password root \ --table click_stream_visit \ --export-dir /user/hive/warehouse/dw_click.db/click_stream_visit/datestr=2013-09-18 \ --input-fields-terminated-by '\001' -
两个命令补充:
- 列出 mysql 数据库中的所有数据库命令
bin/sqoop list-databases \ --connect jdbc:mysql://vm2:3306 \ --username root \ --password hadoop - 连接 mysql 并列出数据库中的表的命令
bin/sqoop list-tables \ --connect jdbc:mysql://vm2:3306/sqoopdb \ --username root \ --password 123456
- 列出 mysql 数据库中的所有数据库命令
-















 4261
4261











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









