







【医学影像 AI】用于检测 ROP plus 疾病的定制工程和无代码深度学习模型
0. 论文简介
0.1 基本信息
2023年,英国 Siegfried K Wagner 和 Bart Liefers 等 在 Lancet Digit Health 发表论文 “用于检测 ROP plus 疾病的定制工程和无代码深度学习模型的开发和国际验证:一项回顾性研究(Development and international validation of custom-engineered and code-free deep-learning models for detection of plus disease in retinopathy of prematurity: a retrospective study)”。
本文的主要贡献在于开发和验证了定制化深度学习和无代码深度学习模型(CFDL),为ROP筛查提供了新的工具,并展示了无代码方法在资源有限环境中的潜力。
-
模型开发与验证:
本研究开发了两种深度学习模型:定制化模型和无代码模型(CFDL),用于区分健康视网膜图像与pre-plus或plus疾病图像。这些模型在内部测试中表现出色,曲线下面积(AUC)分别达到0·986和0·989 [1]。同时,模型在四大洲、三个国家的多个外部验证数据集中进行了测试,证明了其在不同种族、地理和社会经济环境中的适用性 [1]。 -
跨设备性能评估:
研究还评估了模型在不同成像设备(如Retcam和3nethra neo)上的性能,发现尽管模型在使用与开发数据集相同的Retcam设备时表现良好,但在使用3nethra neo设备时性能有所下降 [1]。这表明在使用不同设备时需要谨慎。 -
无代码方法的潜力:
无代码深度学习模型(CFDL)在资源匮乏的医疗环境中特别有潜力,因为它不需要专业的数据科学家支持。尽管在某些情况下其泛化能力可能不如定制化模型,但它仍为ROP筛查提供了一种可行的替代方案 [1]。
论文下载: sciencedirect
引用格式:
Wagner SK, Liefers B, Radia M, et al. Development and international validation of custom-engineered and code-free deep-learning models for detection of plus disease in retinopathy of prematurity: a retrospective study. Lancet Digit Health. 2023 Jun;5(6):e340-e349. doi: 10.1016/S2589-7500(23)00050-X.

0.2 摘要
- 背景
早产儿视网膜病变(ROP)是儿童失明的主要原因之一,通常通过儿科眼科医生的定期筛查进行诊断。然而,随着早产儿存活率的提高以及专家资源的稀缺,这种方法的可持续性受到了质疑。本研究旨在为英国伦敦一个种族多样化的群体开发针对ROP标志性病变——plus疾病的无代码深度学习分类器,并在四大洲、三个国家的种族、地理和社会经济多样化群体中进行外部验证。无代码深度学习不依赖于经过专业训练的数据科学家,因此对资源匮乏的医疗环境具有特别的潜在优势。
方法
这项回顾性队列研究使用了2008年至2018年间伦敦霍默顿大学医院NHS基金会信托新生儿科的1370名新生儿的视网膜图像。所有胎龄小于32周或出生体重小于1501克的婴儿均使用Retcam 2设备(Natus Medical, Pleasanton, CA, USA)进行图像采集。每张图像由两位初级眼科医生进行分级,如有分歧则由一位高级儿科眼科医生裁定。针对健康、pre-plus疾病和plus疾病的区分,开发了定制化和无代码深度学习模型(CFDL)。在内部测试中,以三位高级儿科眼科医生的多数意见作为参考标准,对200张图像进行了性能评估。外部验证使用了来自美国、巴西和埃及的四个独立数据集的338张视网膜图像,这些图像分别来自Retcam和3nethra neo设备(Forus Health, Bengaluru, India)。
-
结果
在原始数据集的7414张视网膜图像中,6141张图像被用于最终开发数据集。在区分健康与pre-plus或plus疾病时,定制化模型的曲线下面积(AUC)为0·986(95% CI 0·973–0·996),CFDL模型的AUC为0∙989(0∙979–0∙997)。两种模型在使用Retcam设备的外部验证数据集中均表现良好(定制化模型范围为0∙975–1∙000,CFDL模型范围为0∙969–0∙995)。然而,在美国数据集中,CFDL模型在区分pre-plus疾病与健康或plus疾病时的表现劣于定制化模型(CFDL 0·808 [95% CI 0·671–0·909],定制化模型0·942 [0·892–0·982],p=0·0070)。在使用3nethra neo设备进行测试时,性能也有所下降(CFDL 0·865 [0·742–0·965],定制化模型0·891 [0·783–0·977])。 -
解释
定制化和CFDL模型在区分健康视网膜图像与pre-plus或plus疾病图像方面的表现与高级儿科眼科医生相当;然而,CFDL模型在处理少数类别时泛化能力可能较差。在使用与开发数据集不同的成像设备进行测试时应谨慎。本研究为ROP筛查中plus疾病分类器的进一步验证提供了依据,并支持无代码方法在预防易感新生儿失明方面的潜在作用。
0.3 研究背景
-
本研究前的证据
我们在PubMed、MEDLINE、Scopus、Web of Science、Embase和arXiv数据库中检索了从数据库建立至2022年11月21日的相关研究,使用的关键词包括“早产儿视网膜病变”、“plus疾病”、“眼底照片”、“机器学习”、“人工智能(AI)”和“深度学习”。
仅纳入以英文撰写的研究报告并进行审查,同时审阅了其他语言报告的英文摘要。我们特别关注了地理环境、新生儿检查的选择标准、社会人口特征、参考标准、模型开发以及与人类专家的比较。
结果显示,各研究报告中的诊断准确性普遍较高,几乎所有研究均来自北美和亚洲。部分研究未明确规定新生儿检查的纳入标准,或使用了与国际公认的早产儿视网膜病变筛查项目显著不同的阈值。仅发现一项研究使用了无代码深度学习平台,且未见无代码与定制化架构之间的比较。两项研究考察了不同成像设备的泛化能力,仅有两个模型在开发数据集以外的人群中进行了外部验证。与专家的比较通常仅限于少数资深儿科眼科医生。 -
本研究的附加值
我们报告了在英国明确符合标准化筛查标准的不同种族和社会经济背景的早产儿群体中,定制化和无代码深度学习模型对plus疾病的诊断准确性。
在区分健康视网膜图像与pre-plus疾病或plus疾病图像时,定制化和无代码方法表现相似;然而,在检测少数类别pre-plus疾病时,无代码模型的表现劣于定制化模型。
总体而言,两种模型在内部测试集中的表现与经常进行早产儿视网膜病变筛查的资深儿科眼科医生相当。两种模型在美国、巴西和埃及的独立外部验证测试集中表现良好,但在使用不同的新生儿相机进行区分健康与pre-plus疾病或plus疾病图像的任务时,性能有所下降。 -
现有证据的启示
定制化和无代码深度学习方法在区分健康与pre-plus疾病或plus疾病方面均表现出可接受的性能。
在硬件和深度学习资源可能有限的资源匮乏环境中,无代码方法可能为当地团队提供一种开发、验证并可能在其自身人群中部署的替代方案。
这种方法在早产儿视网膜病变筛查中可能具有特别吸引力,因为泛化过程中数据集偏移的风险较高——不同种族群体的疾病自然史不同,图像捕捉设备可能因机构而异,筛查标准也各不相同。进一步研究将此类分类模型整合到筛查项目中的实施和有效性是必要的。
1. 引言
早产儿视网膜病变(Retinopathy of Prematurity, ROP)是一种增殖性视网膜血管疾病,通常影响低体重的早产新生儿。自 1988 年多中心 CRYO-ROP 研究的里程碑发现以来,ROP 已成为一种在及时识别威胁视力的特征后可以治疗的疾病[1]。 其中一个特征是 plus 病,这是一种以视网膜后部血管异常扩张和迂曲为特征的病症[1]。Plus 病对最终视力丧失具有高度预测性,其存在需要根据国际共识和指南进行紧急治疗[2]。
在高收入国家,ROP 传统上通过筛查计划进行识别,由儿科眼科医生定期对有风险的早产儿进行临床检查。例如,美国儿科学会建议对所有出生体重 ≤1500 克或胎龄 ≤30 周的婴儿进行筛查[3]。然而,人们对这种计划的可持续性存在担忧。ROP 筛查检查需要具有丰富亚专科经验的临床医生进行,而新生儿医学的进步提高了早产儿的存活率[4],但儿科眼科医生的数量并未相应增长。事实上,美国一项全国调查显示,超过一半的新生儿科医生报告称,眼科专家的稀缺是 ROP 筛查的障碍[5]。越来越多的证据表明,远程医疗方法可能提供更高效的护理模式[6]。然而,这种方法仍然受到训练有素的诊断医生数量的限制,在低收入和中等收入国家(LMICs)这一问题更为严重[7]。
通过深度学习(人工智能的一个子领域,受生物神经网络启发)自动识别 plus 病可能是改善快速获取专家专业知识的一种策略。自 2016 年首次报道使用深度学习检测 plus 病以来[8],该领域已经成熟,多个具有高诊断准确性的模型被开发和验证[9, 10, 11, 12, 13]。然而,这些模型从高计算机诊断准确性到安全实际部署仍面临一些挑战[14]。 ROP 是全球范围内儿童视力丧失的最常见原因,但疾病的自然史因种族群体而异,且 ROP 筛查指南缺乏统一性,这强调了在尽可能地理多样化的数据集上开发和验证模型的必要性。首先,迄今为止,大多数关于 ROP 深度学习的文献来自北美和亚洲,反映了所谓的“健康数据贫困”,即少数族裔和社会经济弱势群体在临床 AI 开发中的代表性不足[15]。在 ROP 等疾病中,疾病的自然史因种族群体而异,开发与部署人群之间的不匹配可能导致部署时泛化能力差[16, 17]。其次,ROP 筛查指南(如出生体重和胎龄)在北美和西欧已明确;然而,这些地区以外的大多数报告要么未明确检查的具体标准,要么使用了可能不适合人群健康筛查的阈值;例如,一项报告涉及胎龄 <37 周的婴儿的开发数据[13],而在美国,筛查仅针对胎龄 ≤30 周的婴儿,在英国,截至 2022 年 3 月,阈值为胎龄 <31 周。第三,使用深度学习框架开发的模型在测试与开发数据集不同设备获取的图像时,通常泛化能力较差,而目前只有一种 plus 病检测模型使用了非 Retcam 设备获取的图像进行验证[18, 19]。特别是在 LMICs 中,某些设备的高成本限制了其购买、使用和广泛部署[20, 21]。
即使对数据集偏移问题更加警惕,许多机构仍可能缺乏开发此类工具的技术和硬件资源,特别是在 LMICs 中,预计 ROP 发病率的上升使一些人将撒哈拉以南非洲称为 ROP 的新前沿[22]。缓解数据集偏移问题的一个潜在解决方案是通过无代码深度学习(CFDL)工具进行本地开发、验证和部署。自 2018 年首次描述用于医学成像任务以来,CFDL 已应用于多种视网膜疾病,但在医学文献中与传统定制深度学习设计的比较较少[23, 24]。
在本研究中,我们首先旨在使用真实世界的训练数据集开发和内部验证针对英国人群优化的定制和 CFDL plus 病分类器。
我们使用了根据英国皇家眼科医学院(RCOphth)标准符合 ROP 筛查条件的新生儿视网膜图像,这些图像来自英国伦敦一个服务于种族和社会经济多样化地区的大型单一中心,该地区在国民健康服务(NHS)的规定下提供免费医疗服务。
其次,我们旨在比较 CFDL 与定制模块化架构,假设 CFDL 模型在检测 plus 病和 pre-plus 病以及评估图像质量方面具有相似的表现。
第三,我们旨在对来自两个 LMICs(巴西和埃及)和美国的四个独立数据集进行外部验证,其中包括使用不同设备获取的图像。
这些目标旨在解决现有研究的局限性,并为 ROP 筛查提供更广泛适用的 AI 工具。
2. 方法
2.1 数据集与参与者
在这项回顾性队列研究中,连续收集了 2008 年 1 月 1 日至 2018 年 1 月 31 日期间作为常规护理的一部分,在英国伦敦 Homerton 大学医院 NHS 基金会信托机构获取的婴儿视网膜图像。
在研究期间,所有符合 2008 年英国皇家眼科医学院(RCOphth)ROP 筛查标准的婴儿均被纳入图像采集范围(注:RCOphth 指南于 2022 年 3 月更新)[25]。简而言之,2008 年指南建议对胎龄小于 32 周或出生体重小于 1501 克的婴儿进行 ROP 筛查。
使用 Retcam 2 设备(Natus Medical,美国加利福尼亚州普莱森顿)获取匿名视网膜图像,图像采集范围包括多个固定目标(如上部和后极),最大视野为 130 度。由一名眼科医生(MR)手动筛选出后极固定良好的图像。图像像素分辨率为 1600 × 1200,色彩深度为 24 位。
本研究获得了 Moorfields 眼科医院研究与开发部门(BALK1004)和英国健康研究管理局(IRAS ID 253237)的研究与开发机构审查委员会批准。由于研究仅限于使用数据,英国健康研究管理局认为不需要伦理批准。由于研究涉及对回顾性获取的匿名数据进行分析,因此不需要获得同意。报告符合 TRIPOD 声明[26]。
2.2 方法与流程
图像分级仅基于视网膜图像;即,在分级过程中未提供额外的临床数据(如出生体重)。参考标准基于分层分级方案:每张图像由两名具有 3 年眼科经验的初级眼科医生独立分级,分为不可分级(由于角膜混浊、白内障、玻璃体混浊或出血、患者固定不良导致视野受限无法检测病理表现,或图像伪影)、健康、pre-plus 病或 plus 病。两组初级眼科医生(JT、SB、CH 和 CK)参与了本研究。初级眼科医生之间的分歧由一名具有超过 25 年经验的高级儿科眼科医生(GA)解决,该医生对初级眼科医生的分级结果不知情(附录 3 第 6 页)。
我们采用了两种主要方法进行模型开发,假设定制架构和无代码深度学习(CFDL)架构具有相似的性能。
所有模型首先训练用于图像可分级性的二元分类(定义为图像质量足以让临床医生对是否存在 plus 病做出自信判断),其次训练用于将图像分为健康、pre-plus 病和 plus 病的多分类。
定制模型基于 PyTorch 的 DenseNet201 架构(2021 年 3 月 11 日更新;附录 3 第 3 页),该架构在 ImageNet 数据库上进行了预训练。
定制模型的训练通过五折交叉验证进行;更具体地说,开发数据集在患者水平上分为五折,其中四折用于训练,一折用于调优。每次使用一折作为验证的迭代过程生成了五个模型,这些模型被集成为一个整体模型,其决策是五个模型输出的平均值。
为了探索无代码深度学习在 plus 病检测中的可行性,我们还使用 Google Cloud AutoML Vision 应用程序编程接口(API)评估了一个 CFDL 模型,如前所述[23]。模型训练使用了 API 推荐的 40 节点小时。
可分级性模型的性能在包含 308 张图像(308 只眼睛,200 张可分级和 108 张不可分级)的内部测试集上进行了评估,这些图像来自 155 名婴儿。对于区分健康、pre-plus 病和 plus 病的主要任务,内部验证测试集包含来自 112 名婴儿的 200 张图像(200 只眼睛)。我们有意在内部测试集中对 pre-plus 病和 plus 病病例进行了过采样,以更稳定地估计模型在这些类别上的性能。因此,一些图像被排除在开发数据集之外,以避免数据泄露(患者不会同时出现在开发集和测试集中)。
参考标准是三位高级儿科眼科医生顾问(A-MH、RH 和 HIP;经验范围:21-45 年)的多数类别。在三类之间存在分歧的情况下,我们采用最严重的标签。为了进一步评估模型性能,内部验证测试集还由其他七名临床医生进行了分级,包括一名儿科眼科顾问、一名儿科眼科研究员、四名初级眼科住院医师和一名新生儿护理专家(SH、JT、SB、CH、CK、MR 和 JR;附录 3 第 6 页)。所有误分类错误(定义为模型输出概率最高的类别与参考标准不同)均经过视觉检查并报告。此外,为了增强模型的可解释性,我们使用五种技术开发了显著性图(将模型决策归因于特定图像像素的技术;附录 3 第 3 页)。
可分级性模型在埃及亚历山大大学医院的 Retcam 数据集上进行了外部验证,该数据集包含 14 张不可分级和 46 张可分级图像,参考标准是由一名儿科眼科医生(HK)基于图像分类的结果。区分 plus 病存在的模型在四个独立的数据集上进行了外部验证:三个来自低收入和中等收入国家(LMICs),一个来自美国。三个数据集使用与开发数据集相同的成像设备(Retcam)获取,另一个使用 3nethra neo 设备(Forus Health,印度班加罗尔)获取。
对于来自 LMICs 的三个数据集,plus 病的存在以二元方式分级——即健康或 pre-plus 病和 plus 病。因此,这三个数据集的性能指标仅包含单一曲线下面积(AUC)指标。所有来自 LMICs 的外部验证数据集的参考标准均通过双目间接检眼镜检查和基于图像的分级相结合确定。
ROP 成像与信息学(i-ROP)数据集是先前描述的来自 i-ROP 研究的独立美国测试集[27, 28]。i-ROP 数据集包含 100 张 Retcam 图像(54 张健康、31 张 pre-plus 病和 15 张 plus 病),来自 70 名新生儿,收集时间为 2011 年 7 月 1 日至 2014 年 12 月 31 日,参考标准诊断如前所述。巴西数据集包含 92 张图像(20 张 plus 病或 pre-plus 病和 72 张健康),来自 46 名新生儿,于 2020 年 1 月 1 日至 2022 年 8 月 31 日在巴西圣保罗大学使用 Retcam 设备获取。
埃及 Retcam 数据集包含 45 张图像(32 张 plus 病或 pre-plus 病和 13 张健康),来自 45 名新生儿,于 2020 年 1 月 1 日至 2022 年 8 月 31 日在埃及亚历山大大学医院获取。埃及 3nethra 数据集包含 101 张图像(71 张 plus 病或 pre-plus 病和 30 张健康),来自 33 名新生儿,于 2018 年 4 月 1 日至 2022 年 8 月 31 日在埃及开罗 Ain Shams 大学医院眼科和 Al Mashreq 眼科中心获取。图像使用 Forus Health 制造的 3nethra neo 设备拍摄,该设备提供最大 120 度的视野。有关外部验证数据集的更多信息,包括种族数据和参考标准,请参见附录 3(第 7 页)。
2.3 结果
主要结果是疾病检测模型在外部验证中对 plus 病、pre-plus 病或健康的分类准确性,以及可分级性模型对图像可分级性(可分级或不可分级)的二元分类准确性。次要结果包括开发数据集的评分者间一致性、疾病检测模型的内部验证、误分类错误审核、定制和无代码疾病检测模型的性能比较,以及通过显著性图增强模型的可解释性。
2.4 统计分析
两名评分者之间的评分者间一致性通过二次加权 Cohen κ 统计量评估,超过两名评分者时使用组内相关系数(ICC;附录 3 第 4 页)。模型性能通过敏感性、特异性和 AUC 进行估计,必要时使用一对多方法,并通过自举法计算 95% 置信区间。为了模拟图像可分级性和疾病检测模型的实际使用场景,我们还提供了在设定特异性和敏感性为 1 时的性能指标(即 100% 的不可分级图像将被分类为不可分级,100% 的疾病图像将被识别)。为了可视化不同操作点下的敏感性和特异性权衡,我们生成了定制和 CFDL 模型的 ROC 曲线。定制和 CFDL 模型通过 DeLong 等人描述的非参数方法进行比较[29],这是一种用于比较两个或多个相关 AUC 的非参数方法,或者对于每个患者有多张图像的测试集,使用聚类自举技术来考虑聚类效应[30]。所有统计检验均为双尾检验,显著性水平设为 p<0.05。分析使用 Python v3.6.9 和 R v4.1.0 进行。
2.5 资金来源的作用
本研究的资助者在研究设计、数据收集、数据分析、数据解释或撰写手稿方面没有任何作用。
3. 结果
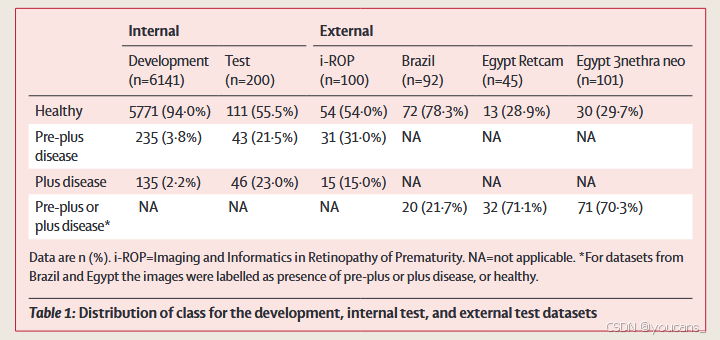
在2008年1月1日至2018年1月31日期间,共采集了47,158张连续婴儿视网膜图像。最终数据集包含1370名婴儿的7414张后极部图像。未收集个体层面的种族和社会经济剥夺数据;该队列的总体种族构成为:44%为白人,33%为黑人,13%为南亚人,4%为其他亚洲人,5%为华人,1%为其他种族。开发、内部验证和外部验证数据集中的类别分布见表1。
在最初的7414张开发数据集中,487张(6.6%)被认为不可分级。另有786张图像被移除,因为这些图像属于测试集中的患者,最终开发数据集为6141张图像。三个类别的示例图像见附录3(第9页)。
开发数据集中两位初级眼科医生之间的二次加权κ值分别为0.433(95% CI 0.404–0.462)和0.500(0.461–0.540)。对于200张图像的内部测试数据集,所有分级者之间的内部一致性系数(ICC)较高,为0.977(0.972–0.982)。形成参考标准的三位资深儿科眼科医生之间的ICC为0.954(0.941–0.964),高于住院眼科医生(0.801 [0.751–0.842])。在内部验证集中,十位分级者、三位资深儿科眼科医生的多数意见以及模型之间的成对加权κ值见图1。
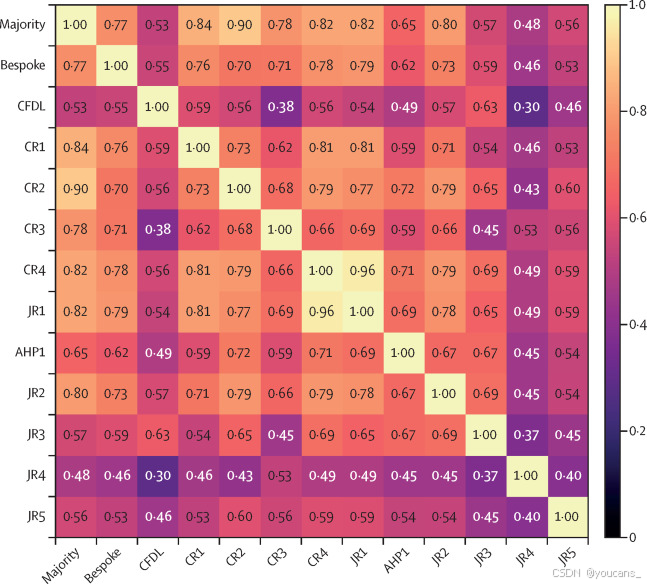
图1。成对二次加权κ值矩阵
多数标签基于CR1、CR2和CR3之间的多数票,因此这些标签不是独立的。CR是提供参考标准的三位高级儿科眼科医生。AHP=专职医疗人员。CFDL=无代码深度学习。CR=顾问评分员。JR=初级评分员。
在内部测试集上,定制模型在区分可分级图像和不可分级图像时,达到了0.979的AUC(95%置信区间为0.966–0.990)。在特异性为1的情况下,灵敏度为0.775(0.710–0.910)。在外部验证中,AUC为0.998(0.991–1.000)。定制模型在区分健康、前加病变和加病变时,分别与无代码模型和评估内部验证数据集的人类专家评分者相比,AUC分别为0.986(0.973–0.996)、0.927(0.884–0.962)和0.974(0.951–0.991)(图2)。与医疗保健专业人员的性能对比见表2。
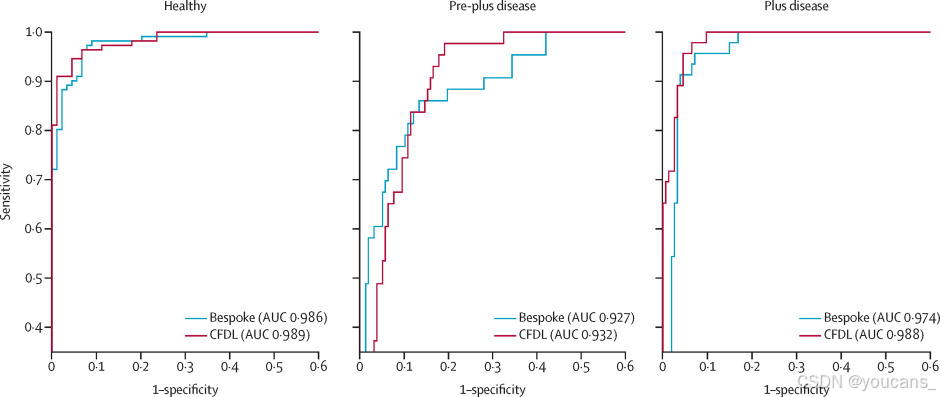
图2:内部测试装置上定制和CFDL型号的接收器工作特性曲线
AUC=曲线下面积。CFDL=无代码深度学习。
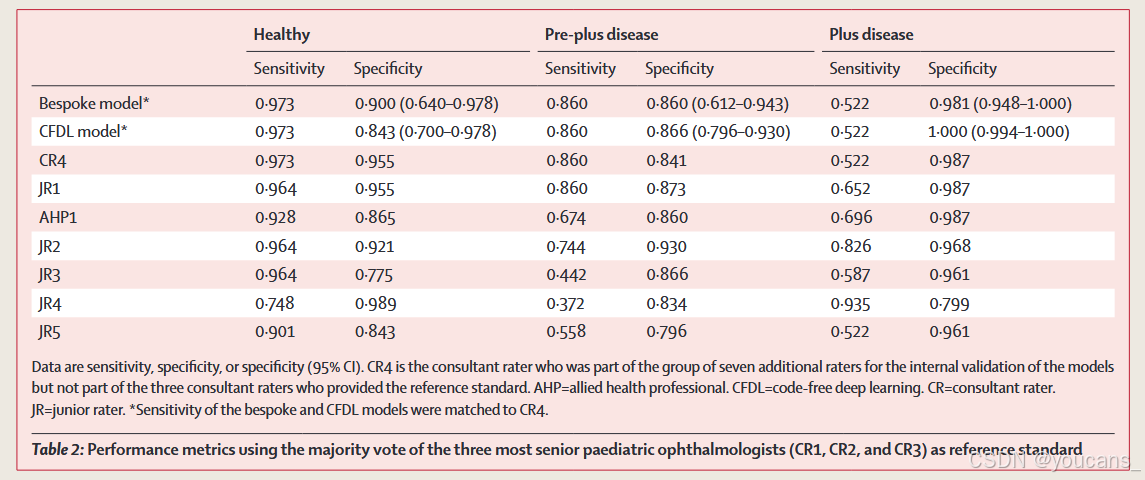
在检测健康与前加病变或加病变时,当灵敏度设置为1时,特异性为0.691(95% CI 0.562–0.944)。参考标准与定制模型之间的二次加权κ值为0.77(0.66–0.87)。定制模型在使用Retcam设备获取的外部验证数据集上也达到了相似的AUC值(巴西为0.975 [95% CI 0.942–0.997],埃及为0.976 [0.928–1.000];表3),但在埃及3nethra neo数据集上的性能下降至AUC为0.891(0.783–0.977)。
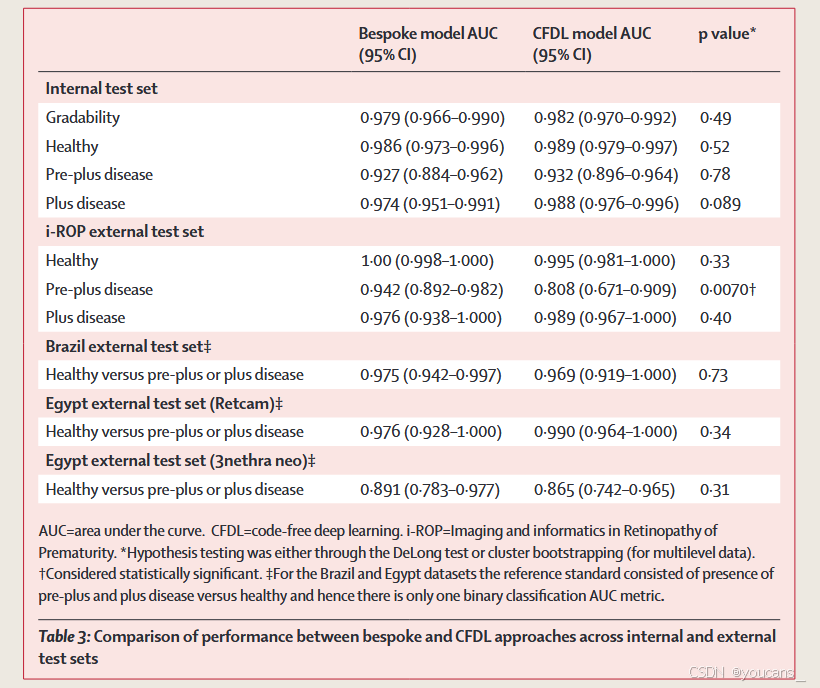
CFDL模型在区分可分级图像和不可分级图像时,AUC为0.982(95% CI 0.970–0.992),当特异性设置为1时,灵敏度为0.850(0.785–0.915)。在外部验证中,AUC为0.977(0.941–0.999)。在健康、前加病变和加病变检测任务中,与定制模型和评估内部验证数据集的人类专家评分者相比,CFDL模型在内部测试集上的AUC分别为:健康0.989(0.979–0.997)、前加病变0.932(0.896–0.964)、加病变0.988(0.976–0.996)(图2)。当灵敏度设置为1时,区分健康与前加病变或加病变的特异性为0.775(0.674–0.899)。参考标准与CFDL模型之间的二次加权κ值为0.53(95% CI 0.41–0.66)。在使用Retcam设备获取的外部验证数据集上,CFDL模型的性能普遍较高(表3)。在埃及3nethra neo数据集上测试时,AUC性能下降至0.865(0.742–0.965)。
总体而言,定制模型和CFDL模型在内部测试集以及巴西和埃及的外部验证中的所有任务中表现相似。在i-ROP外部验证测试集中,有证据表明定制模型在前加病变检测中的诊断准确性优于CFDL模型(0.942 [95% CI 0.892–0.982] vs 0.808 [0.671–0.909],p=0.0070;表3)。部分差异可能归因于定制模型采用的集成方法;然而,即使是单个模型的输出也高于CFDL模型的输出(附录3第8页)。
图3显示了内部测试集中错误分类的队列标签矩阵。大多数错误分类发生在多数人认为图像为前加病变的情况下。CFDL模型经常在加病变或健康之间做出二元决策(附录3第5页)。错误分类的示例如附录3(第10页)所示。显著性图检查表明,涉及视网膜血管的像素,特别是弯曲和充血区域,影响了模型的输出(附录3第11页)。
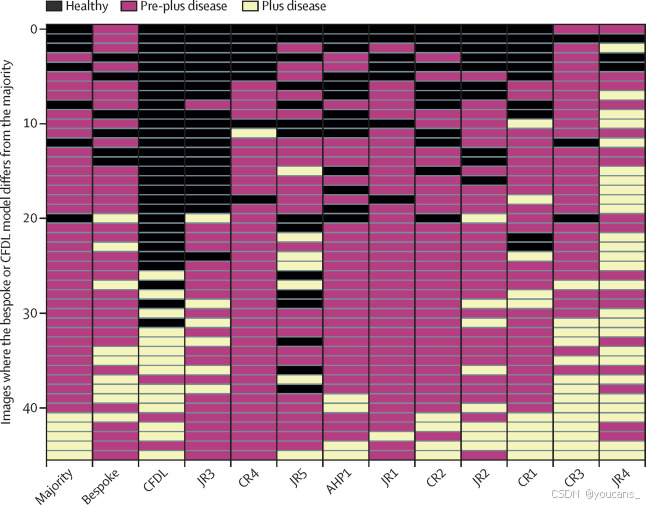
图3。矩阵热图显示了内部测试集中模型和评分者之间的分歧。
每一行表示不同的观察或图像,列表示不同的等级,颜色表示不同的类别(健康、疾病前期和疾病前期)。病例按所有十个等级的平均严重程度垂直排列。水平方向上,评分者按敏感度从左到右排列。所有四个CR都包括在内。AHP=专职医疗人员。CFDL=无代码深度学习。CR=顾问评分员。JR=初级评分员。
5. 结论
在本研究中,定制模型和CFDL模型在区分健康与加病变或前加病变方面的表现与目前从事ROP筛查的高级临床医生相当。两种模型在使用相同成像设备(Retcam)的国际外部验证数据集上均表现出良好的泛化能力;然而,CFDL模型在检测前加病变任务中的表现不如定制模型。当在另一种成像设备(3nethra neo)上测试时,两种模型的性能均有所下降。尽管部署此类模型需要对其有效性进行全面评估,但我们的诊断准确性结果突显了自动化加病变诊断的潜力。在英国,新生儿科室目前正在利用基于Retcam的新生儿筛查方法以及CFDL平台进行内部开发,用于ROP筛查的自动深度学习分类系统。
此前,我们评估了无代码深度学习方法在医学图像分类任务中的可行性,并报告了与当代最先进模型相似的诊断准确性。在本研究中,我们展示了预训练的定制模型架构与通过Google Cloud提供的自动深度学习方法(神经架构搜索)在大多数任务中的相似性能[23, 31]。CFDL方法在检查和调整模型架构的特定细节方面存在局限性。例如,我们为定制模型采用了交叉验证和集成方法,但这些方法无法在CFDL中实现。事实上,我们的单个定制模型的表现不如集成模型,但它们仍然在 i-ROP外部验证数据集上超过了CFDL模型(附录3第7页)。然而,当专业数据科学知识和高性能计算资源(如图形处理单元)可能稀缺时,CFDL确实为模型开发提供了一种替代选择。这种稀缺性在低收入和中等收入国家(如撒哈拉以南非洲)尤为明显,这些地区对专业新生儿护理的可及性相对增加,导致早产儿存活率提高,进而ROP发病率上升[32]。此外,特别是在ROP等疾病中,有证据表明自然病程可能因种族和社会经济地位而异,在一个环境中开发的模型可能由于分布变化而在另一个环境中泛化能力较差[16, 17, 33]。例如,在最近一项关于深度学习分类器的系统综述中,9 个研究的开发数据集中均未包括来自南美或非洲的新生儿[34, 35]。通过CFDL方法促进的本地训练可能提供一定的缓解,使资源匮乏地区的新生儿科室能够开发适合其特定人群的优化模型。
我们研究中的观察者间差异与之前的报告基本一致[27, 28, 36, 37],但我们研究的一个新颖之处是检查了具有不同经验的临床医生的表现。高级临床医生(即顾问眼科医生)之间的一致性高于初级临床医生,而初级临床医生之间的差异较大。即使在高级眼科医生中,加病变诊断的观察者间一致性也仅为中等,这为建立严格的参考标准带来了挑战[27, 36]。Chen及其同事[38]提出了三种基于主观解释提高参考标准可重复性的方法:增加分级者的专业知识、增加每个案例的分级者数量,以及确保分歧解决过程无偏见。我们的研究利用了两名至少具有3年眼科经验的初级眼科医生的独立分级,并由一名高级眼科医生进行仲裁,旨在实现无偏见的解决过程,尽量减少群体思维。然而,随着模型向实际部署方向发展,真实情况可能会通过更多经验丰富的分级者来定义。其他研究团队已经研究了一些替代策略:i-ROP研究联盟将多个分级者的图像标签与临床检查的辅助信息相结合[11, 39]。这些标签具有鲁棒性,但在实践中可能具有挑战性,因为它们需要使用标准化检查协议进行前瞻性数据收集。此外,同一团队的研究还表明,基于图像的加病变诊断准确性可能实际上超过了眼科检查。另一种选择可能是考虑使用彩色眼底摄影分割工具,自动提取定量视网膜血管指标(如静脉管径和动脉弯曲度),并将其作为疾病的替代指标。
分级者与定制模型(bespoke model)及无代码深度学习模型(CFDL)之间的分歧主要集中在被标记为pre-plus疾病的病例上。例如,在内部测试集中,几乎所有的错误分类都发生在多数投票结果为pre-plus疾病的情况下。尽管CFDL模型在区分pre-plus疾病时表现出较高的AUC值(0.932,95% CI 0.896–0.964),但其输出通常为plus疾病或健康视网膜。以下两点进一步揭示了这一细微差别:(1)在i-ROP数据集的外部验证中,定制模型在检测pre-plus疾病时的表现显著优于CFDL模型;(2)通过加权κ值的检查发现,多数投票与定制模型之间的一致性(κ 0.77)明显优于多数投票与CFDL模型之间的一致性(κ 0.53)。这可能是由于CFDL在训练过程中对类别分布不均的情况更为敏感。一种可能的解决方案是将plus疾病视为增殖性视网膜血管病变谱系的一个端点,并采用连续的血管严重程度评分进行建模,该策略得到了国际早产儿视网膜病变分类最新共识声明的支持[41]。i-ROP研究联盟的最新工作验证了定量评分的有效性,并展示了其在监测疾病进展、预测需要治疗的ROP以及治疗后疾病消退方面的应用[42,43,44]。
*局限性
在解释我们的结果时,需要考虑几个局限性。
首先,由于信息治理限制,我们在开发数据集中未明确收集可能影响模型性能的个体层面数据,如性别和种族。尽管数据集来自多样化的人群,但我们仅能报告种族方面的汇总信息。通过分层分析这些潜在的混杂因素,可以阐明其在模型推断中的贡献,并回应关于算法公平性的担忧。
其次,数据集的评分仅限于图像质量及pre-plus或plus疾病的存在。尽管在我们的开发数据集中,Retcam图像捕获区域内视网膜病变(如出血)的检测率非常低,但模型可能利用这些特征作为捷径信号。未来的工作可以明确标注视网膜病变的图像,并基于其存在与否分层提供测试性能结果。
第三,我们的研究采用了分级评分方法,第一级评分者为初级眼科医生,但即使是资深眼科医生之间的ROP诊断一致性也仅为中等水平。在部署前,可以采用其他方法改进基准事实的生成过程。
第四,本研究中对图像质量的评分及以视神经为中心的图像选择均为人工完成。尽管我们开发了图像可分级性模型,但未明确评估模型在不同图像质量水平下的表现,也未将质量评估整合到患者工作流程中。在临床实施前,应进一步考虑整合图像质量控制及其对诊断准确性的影响,正如其他关于糖尿病视网膜病变和ROP的研究所建议的[12, 45, 46]。
第五,尽管我们受益于相对较大的数据集来训练定制和CFDL模型,但其他机构可能无法获得类似规模的数据集。目前尚不清楚需要多少图像才能构成足够建模plus疾病分类的样本量,但大多数研究报告使用了数千张图像。目前尚无公开的大型新生儿视网膜图像数据集,但一种潜在的解决方案是同时使用真实和合成的新生儿图像训练深度学习模型。最近的研究表明[47],这种方法能够获得与仅使用真实图像训练的模型相似的性能。最后,尽管在使用与开发数据集相同的成像设备(Retcam)时,我们的模型表现出了良好的泛化能力,但应注意单个外部验证数据集(尤其是图像可分级性)的规模相对较小。开发自动化深度学习ROP筛查模型的一个主要动力是不同医疗环境中新生儿护理实践模式的巨大差异,而开发数据集中的所有婴儿均接受了英国新生儿护理,这可能引入一定的偏差。然而,模型在外部验证中的表现表明其偏差较低且具有较高的泛化能力。进一步的验证有助于积累模型广泛适用性的证据。例如,中国患有严重ROP的婴儿往往体重更大且年龄更大[48]。
总之,在根据RCOphth标准进行ROP筛查的新生儿中,通过深度学习实现的自动化plus疾病检测具有与资深儿科眼科医生相似的诊断准确性。
定制模块化架构的强大性能可以通过自动化深度学习工具实现,特别是在区分需转诊与无需转诊疾病的二分类任务中。
这种无代码选项可能为中低收入国家提供了一个解决方案,因为这些国家ROP发病率上升、资源匮乏以及具备适当专业知识的临床医生稀缺可能导致儿童失明率增加。
尽管在部署前需要进一步的验证和跨人群的有效性研究,但深度学习可能为减轻这些年轻患者终身视力损害的风险提供了一个工具。
6. 参考文献
- Cryotherapy for Retinopathy of Prematurity Cooperative Group. Multicenter trial of cryotherapy for retinopathy of prematurity. Preliminary results. Arch Ophthalmol 1988; 106: 471–79.
- Early Treatment For Retinopathy Of Prematurity Cooperative Group. Revised indications for the treatment of retinopathy of prematurity: results of the early treatment for retinopathy of prematurity randomized trial. Arch Ophthalmol 2003; 121: 1684–94.
- Fierson WM, Chiang MF, Good W, et al. Screening examination of premature infants for retinopathy of prematurity. Pediatrics 2018; 142: e20183061.
- Glass HC, Costarino AT, Stayer SA, Brett CM, Cladis F, Davis PJ. Outcomes for extremely premature infants. Anesth Analg 2015; 120: 1337–51.
- Kemper AR, Wallace DK. Neonatologists’ practices and experiences in arranging retinopathy of prematurity screening services. Pediatrics 2007; 120: 527–31.
- Wang SK, Callaway NF, Wallenstein MB, Henderson MT, Leng T, Moshfeghi DM. SUNDROP: six years of screening for retinopathy of prematurity with telemedicine. Can J Ophthalmol 2015; 50: 101–06.
- Bronsard A, Geneau R, Duke R, et al. Cataract in children in sub-Saharan Africa: an overview. Expert Rev Ophthalmol 2018; 13: 343–50.
- Worrall DE, Wilson CM, Brostow GJ. Automated retinopathy of prematurity case detection with convolutional neural networks. In: Carneiro G, Mateus M, Peter L, et al. Deep learning and data labeling for medical applications. Switzerland: Springer Cham, 2016: 68–76.
- Tong Y, Lu W, Deng Q-Q, Chen C, Shen Y. Automated identification of retinopathy of prematurity by image-based deep learning. Eye Vis (Lond) 2020; 7: 40.
- Wang J, Ju R, Chen Y, et al. Automated retinopathy of prematurity screening using deep neural networks. EBioMedicine 2018; 35: 361–68.
- Brown JM, Campbell JP, Beers A, et al. Automated diagnosis of plus disease in retinopathy of prematurity using deep convolutional neural networks. JAMA Ophthalmol 2018; 136: 803–10.
- Wang J, Ji J, Zhang M, et al. Automated explainable multidimensional deep learning platform of retinal images for retinopathy of prematurity screening. JAMA Netw Open 2021; 4: e218758.
- Li J, Huang K, Ju R, et al. Evaluation of artificial intelligence-based quantitative analysis to identify clinically significant severe retinopathy of prematurity. Retina 2022; 42: 195–203.
- Finlayson SG, Subbaswamy A, Singh K, et al. The clinician and dataset shift in artificial intelligence. N Engl J Med 2021; 385: 283–86.
- Ibrahim H, Liu X, Zariffa N, Morris AD, Denniston AK. Health data poverty: an assailable barrier to equitable digital health care. Lancet Digit Health 2021; 3: e260–65.
- Eliason KJ, Dane Osborn J, Amsel E, Richards SC. Incidence, progression, and duration of retinopathy of prematurity in Hispanic and White non-Hispanic infants. J AAPOS 2007; 11: 447–51.
- Aralikatti AKV, Mitra A, Denniston AKO, Haque MS, Ewer AK, Butler L. Is ethnicity a risk factor for severe retinopathy of prematurity? Arch Dis Child Fetal Neonatal Ed 2010; 95: F174–76.
- Chen JS, Coyner AS, Ostmo S, et al. Deep learning for the diagnosis of stage in retinopathy of prematurity: accuracy and generalizability across populations and cameras. Ophthalmol Retina 2021; 5: 1027–35.
- Cole E, Valikodath NG, Al-Khaled T, et al. Evaluation of an artificial intelligence system for retinopathy of prematurity screening in Nepal and Mongolia. Ophthalmol Sci 2022; 2: 100165.
- Vinekar A, Rao SV, Murthy S, et al. A novel, low-cost, wide-field, infant retinal camera, “Neo”: technical and safety report for the use on premature infants. Transl Vis Sci Technol 2019; 8: 2.
- Vinekar A, Jayadev C, Mangalesh S, Shetty B, Vidyasagar D. Role of tele-medicine in retinopathy of prematurity screening in rural outreach centers in India—a report of 20,214 imaging sessions in the KIDROP program. Semin Fetal Neonatal Med 2015; 20: 335–45.
- Gilbert C, Malik ANJ, Nahar N, et al. Epidemiology of ROP update - Africa is the new frontier. Semin Perinatol 2019; 43: 317–22.
- Faes L, Wagner SK, Fu DJ, et al. Automated deep learning design for medical image classification by health-care professionals with no coding experience: a feasibility study. Lancet Digit Health 2019; 1: e232–42.
- Antaki F, Coussa RG, Kahwati G, Hammamji K, Sebag M, Duval R. Accuracy of automated machine learning in classifying retinal pathologies from ultra-widefield pseudocolour fundus images. Br J Ophthalmol 2023; 107: 90–95.
- British Association of Perinatal Medicine, BLISS. Guideline for the Screening and Treatment of Retinopathy of Prematurity (2008). https://www.bapm.org/resources/37-guideline-for-the-screening-and-treatm… (accessed Dec 11, 2022).
- Collins GS, Reitsma JB, Altman DG, Moons KGM. Transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (TRIPOD): the TRIPOD statement. Circulation 2015; 131: 211–19.
- Kalpathy-Cramer J, Campbell JP, Erdogmus D, et al. Plus disease in retinopathy of prematurity: improving diagnosis by ranking disease severity and using quantitative image analysis. Ophthalmology 2016; 123: 2345–51.
- Campbell JP, Kalpathy-Cramer J, Erdogmus D, et al. Plus disease in retinopathy of prematurity: a continuous spectrum of vascular abnormality as a basis of diagnostic variability. Ophthalmology 2016; 123: 2338–44.
- DeLong ER, DeLong DM, Clarke-Pearson DL. Comparing the areas under two or more correlated receiver operating characteristic curves: a nonparametric approach. Biometrics 1988; 44: 837–45.
- Ying G-S, Maguire MG, Glynn RJ, Rosner B. Tutorial on biostatistics: receiver-operating characteristic (ROC) analysis for correlated eye data. Ophthalmic Epidemiol 2022; 29: 117–27.
- Korot E, Guan Z, Ferraz D, et al. Code-free deep learning for multi-modality medical image classification. Nat Mach Intell 2021; 3: 288–98.
- Herrod SK, Adio A, Isenberg SJ, Lambert SR. Blindness secondary to retinopathy of prematurity in sub-Saharan Africa. Ophthalmic Epidemiol 2022; 29: 156–63.
- Karmouta R, Altendahl M, Romero T, et al. Association between social determinants of health and retinopathy of prematurity outcomes. JAMA Ophthalmol 2022; 140: 496–502.
- Zhang J, Liu Y, Mitsuhashi T, Matsuo T. Accuracy of deep learning algorithms for the diagnosis of retinopathy of prematurity by fundus images: a systematic review and meta-analysis. J Ophthalmol 2021; 2021: 8883946.
- Khan SM, Liu X, Nath S, et al. A global review of publicly available datasets for ophthalmological imaging: barriers to access, usability, and generalisability. Lancet Digit Health 2021; 3: e51–66.
- Chiang MF, Jiang L, Gelman R, Du YE, Flynn JT. Interexpert agreement of plus disease diagnosis in retinopathy of prematurity. Arch Ophthalmol 2007; 125: 875–80.
- Campbell JP, Ryan MC, Lore E, et al. Diagnostic discrepancies in retinopathy of prematurity classification. Ophthalmology 2016; 123: 1795–801.
- Chen PC, Mermel CH, Liu Y. Evaluation of artificial intelligence on a reference standard based on subjective interpretation. Lancet Digit Health 2021; 3: e693–95.
- Ryan MC, Ostmo S, Jonas K, et al. Development and evaluation of reference standards for image-based telemedicine diagnosis and clinical research studies in ophthalmology. AMIA Annu Symp Proc 2014; 2014: 1902–10.
- Biten H, Redd TK, Moleta C, et al. Diagnostic accuracy of ophthalmoscopy vs telemedicine in examinations for retinopathy of prematurity. JAMA Ophthalmol 2018; 136: 498–504.
- Chiang MF, Quinn GE, Fielder AR, et al. International classification of retinopathy of prematurity, third Edition. Ophthalmology 2021; 128: e51–68.
- Taylor S, Brown JM, Gupta K, et al. Monitoring disease progression with a quantitative severity scale for retinopathy of prematurity using deep learning. JAMA Ophthalmol 2019; 137: 1022–28.
- Gupta K, Campbell JP, Taylor S, et al. A quantitative severity scale for retinopathy of prematurity using deep learning to monitor disease regression after treatment. JAMA Ophthalmol 2019; 137: 1029–36.
- Redd TK, Campbell JP, Brown JM, et al. Evaluation of a deep learning image assessment system for detecting severe retinopathy of prematurity. Br J Ophthalmol 2018; published online Nov 23. 10.1136/bjophthalmol-2018-313156.
- Dai L, Wu L, Li H, et al. A deep learning system for detecting diabetic retinopathy across the disease spectrum. Nat Commun 2021; 12: 3242.
- Ruamviboonsuk P, Tiwari R, Sayres R, et al. Real-time diabetic retinopathy screening by deep learning in a multisite national screening programme: a prospective interventional cohort study. Lancet Digit Health 2022; 4: e235–44.
- Coyner AS, Chen JS, Chang K, et al. Synthetic medical images for robust, privacy-preserving training of artificial intelligence. Ophthalmol Sci 2022; 2: 100126.
- Xu Y, Zhou X, Zhang Q, et al. Screening for retinopathy of prematurity in China: a neonatal units-based prospective study. Invest Ophthalmol Vis Sci 2013; 54: 8229–36.
版权说明:
本文由 youcans@xidian 对论文 Development and international validation of custom-engineered and code-free deep-learning models for detection of plus disease in retinopathy of prematurity: a retrospective study 进行摘编和翻译。该论文版权属于原文期刊和作者,本译文只供研究学习使用。
youcans@xidian 作品,转载必须标注原文链接:
【医学影像 AI】用于检测 ROP plus 疾病的定制工程和无代码深度学习模型(https://youcans.blog.csdn.net/article/details/146295295)
Crated:2025-03



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











