







Lamda架构
前言:日志分析中既有离线大规模需求,也有实时性需求,因此需要采用Lamda架构(目的是为大数据分析应用程序提供一个低响应延迟的组合数据环境)构建日志分析流水线。
Lamda组成部分
- 批处理层
通过hadoop,spark等作为批处理层的处理工具,HDFS,HBase等作为数据持久化系统。 - 服务层
用于加载和实现数据库中的批处理视图,便于用户查询。不一定需要随机写,但是需要支持批更新和随机读。采用如ElephantDB,Voldemort - 快速处理层
主要处理实时和服务层更新造成的高延迟补偿,利用流处理系统(如Storm,S4,SparkStreaming)和随机读写数据存储库来实现实时视图(HBase)
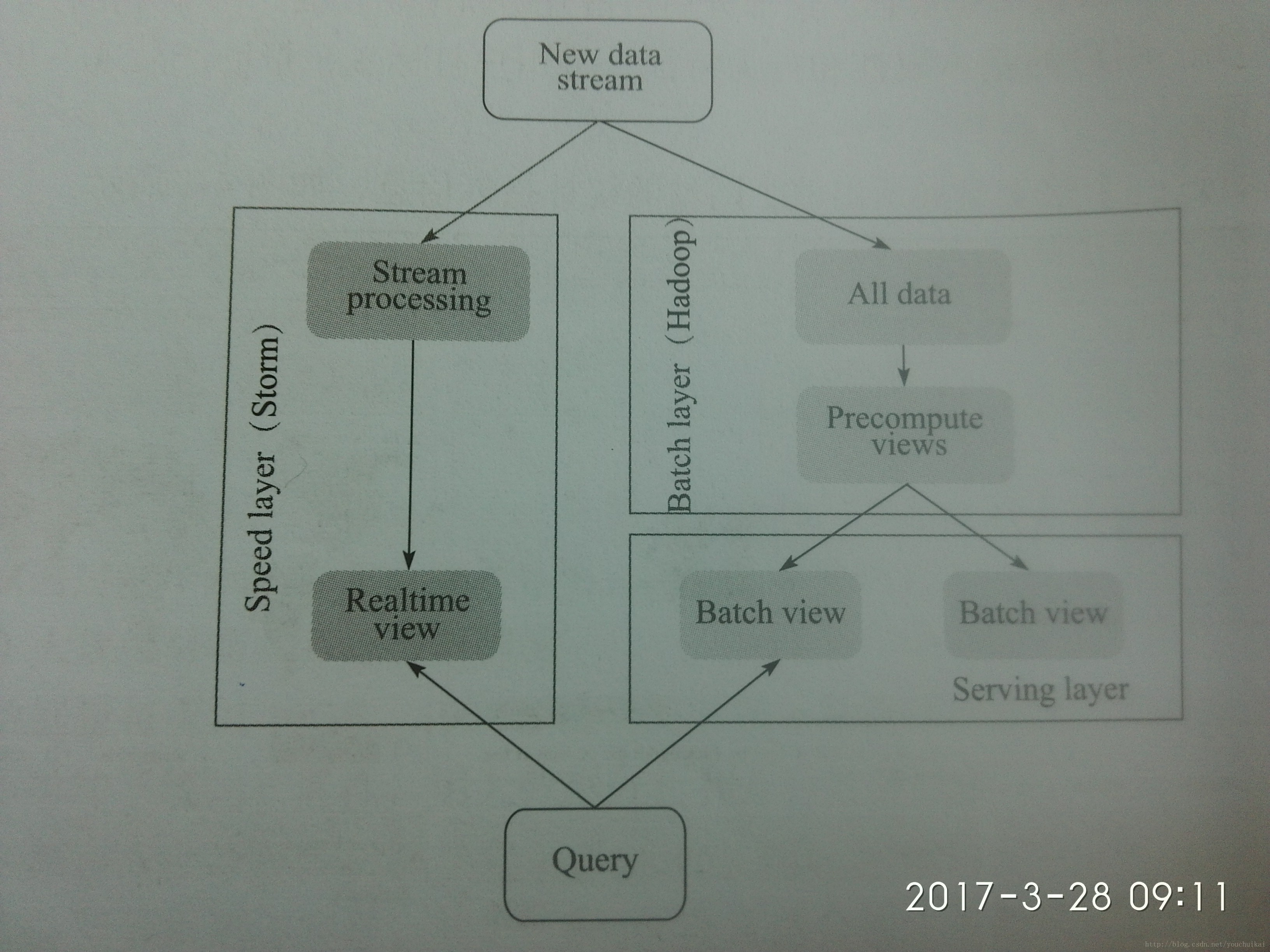
Lamda数据分析架构
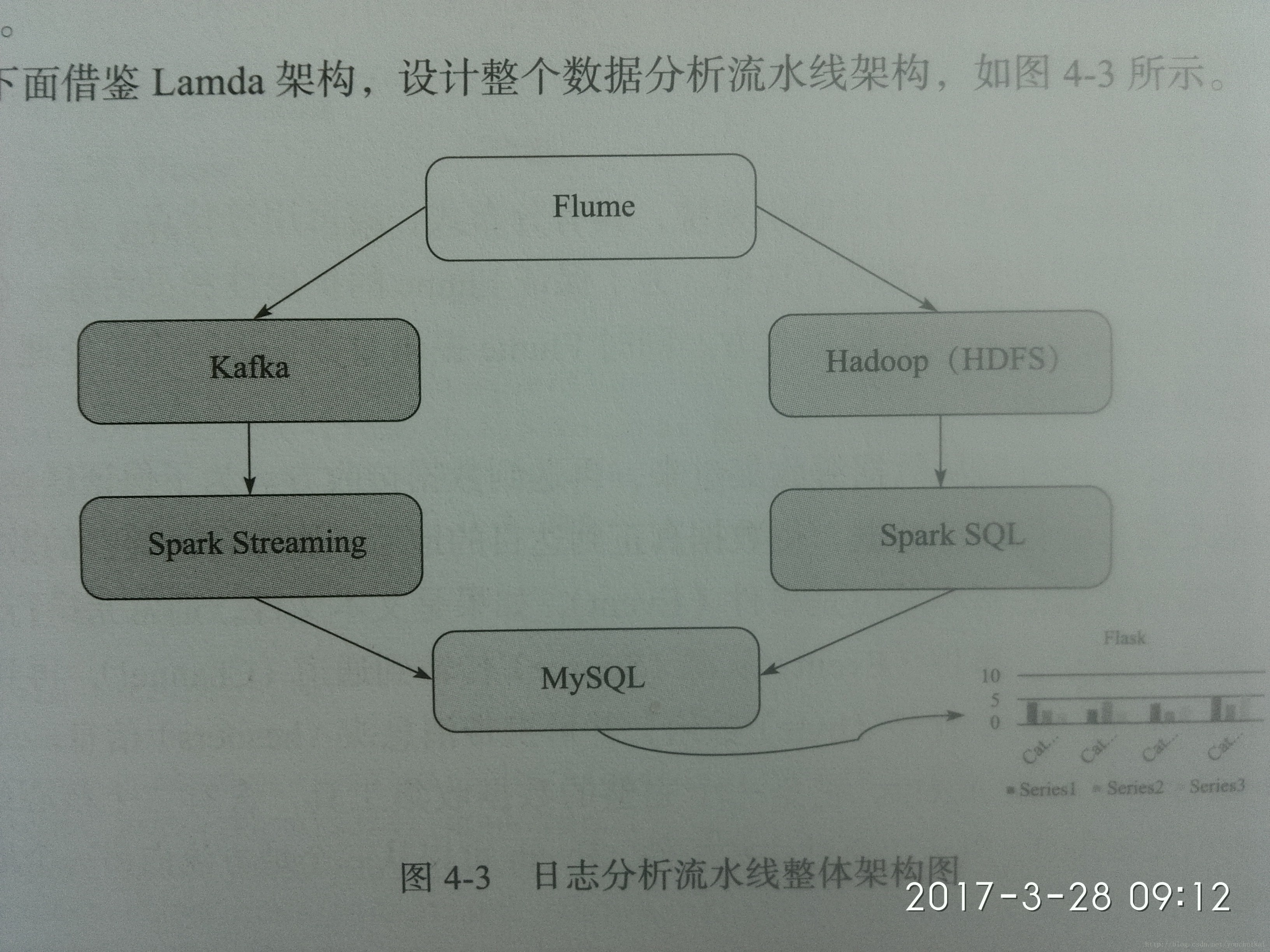
日志分析流水线整理架构
实时日志分析流水线步骤:
- 数据采集 采用Flume NG进行数据采集
- 数据汇总和转发 Flume将数据转发汇总到实时消息系统kafka
- 数据处理 SparkSteaming进行实时数据处理
- 结果呈现 采用Flask作为可视化呈现工具
离线日志分析流水步骤:
- 数据存储 通过Flume将数据转储至HDFS
- 数据处理 通过SparkSQL进行数据预处理
- 结果呈现 结果汇总存储到mysql最后通过Flask,tableau进行结果呈现















 8188
8188

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









