







思路:
1、先找到耗CPU高的进程;
2、找到耗CPU高的线程;
3、找到耗CPU高的线程对应的业务代码;
操作:
1.1、执行“top -c”命令,显示进程运行信息列表,键入大写P,按CPU使用率降序排列:
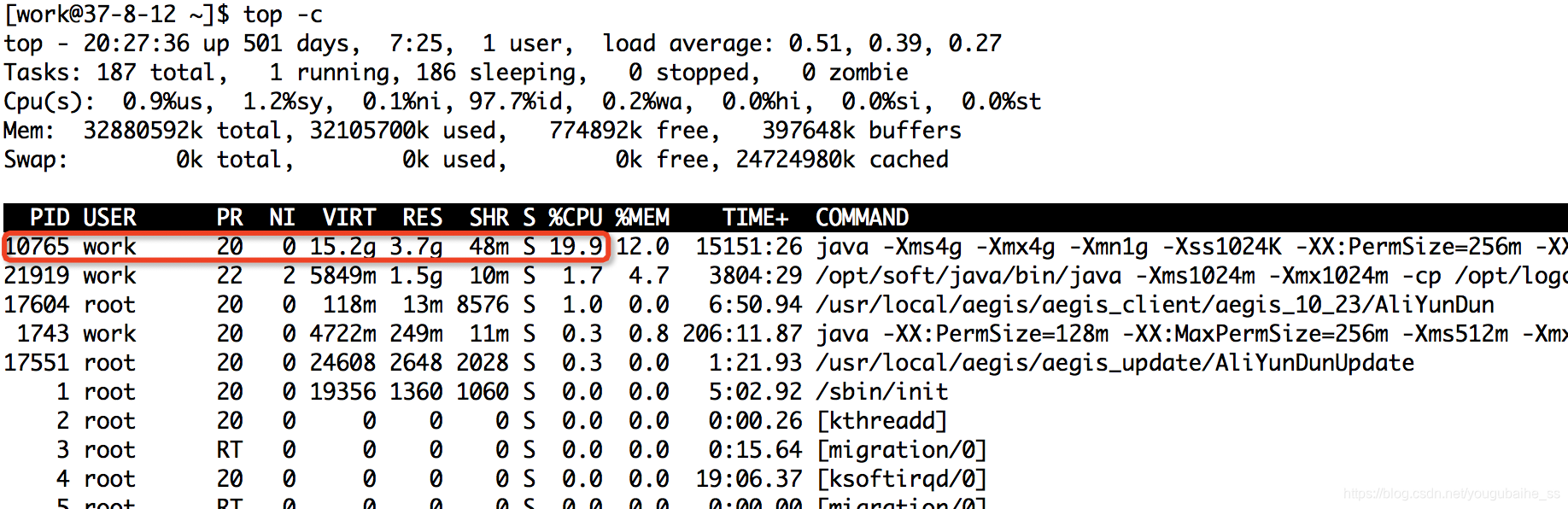
1.2、获取到进程PID为10765的进程,使用CPU资源最高19.9%;
至此,已找到耗CPU最高的进程,进程PID为10765,后续命令中需要使用到。
2.1、一个进程内有很多线程,执行“top -Hp 10765”,显示进程ID为10765的线程列表,键入大写P后,按CPU使用率降序排列:
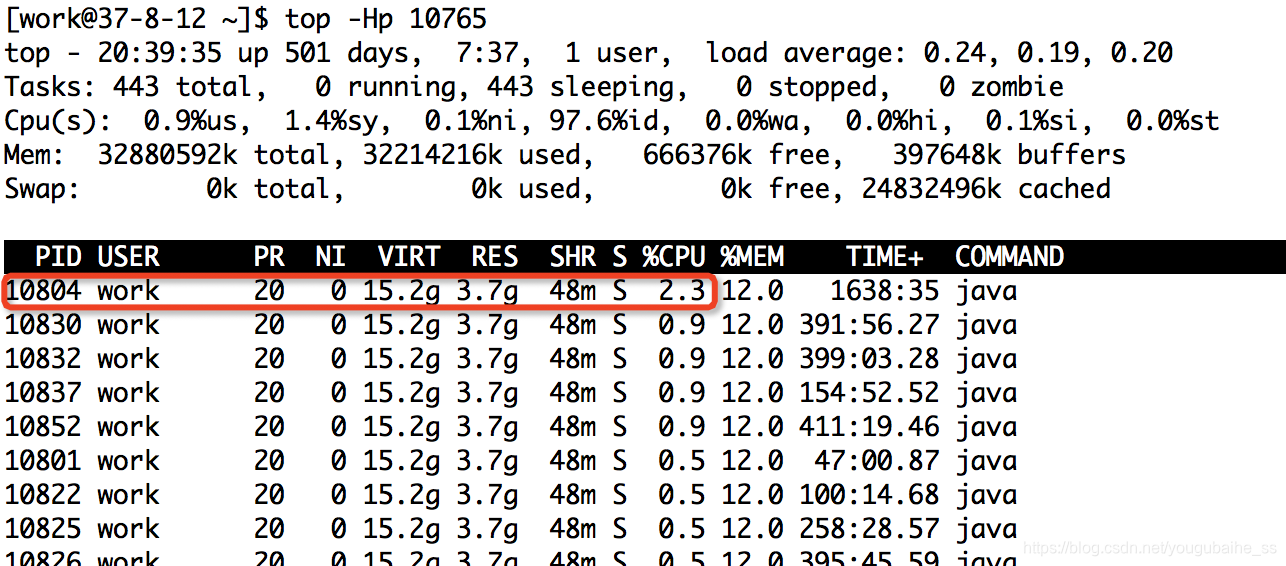
2.2、其中,PID为10804的线程,CPU使用率最高2.3%;
2.3、将线程ID(10804)按16进制展示,执行指令“printf "%x\n" 10804”:

至此,找到了CPU使用率最高的线程ID为10804,并获取到10804的16进制标识:2a34
(转为16进制,是因为jstack打印出的线程栈信息中,线程id是通过16进制展示的)
3.1、通过jstack检索到进程(进程ID=10765)中,最耗CPU的线程(线程ID=2a34)的线程栈信息;
执行指令“jstack 10765 | grep "2a34" -C5 --color”:
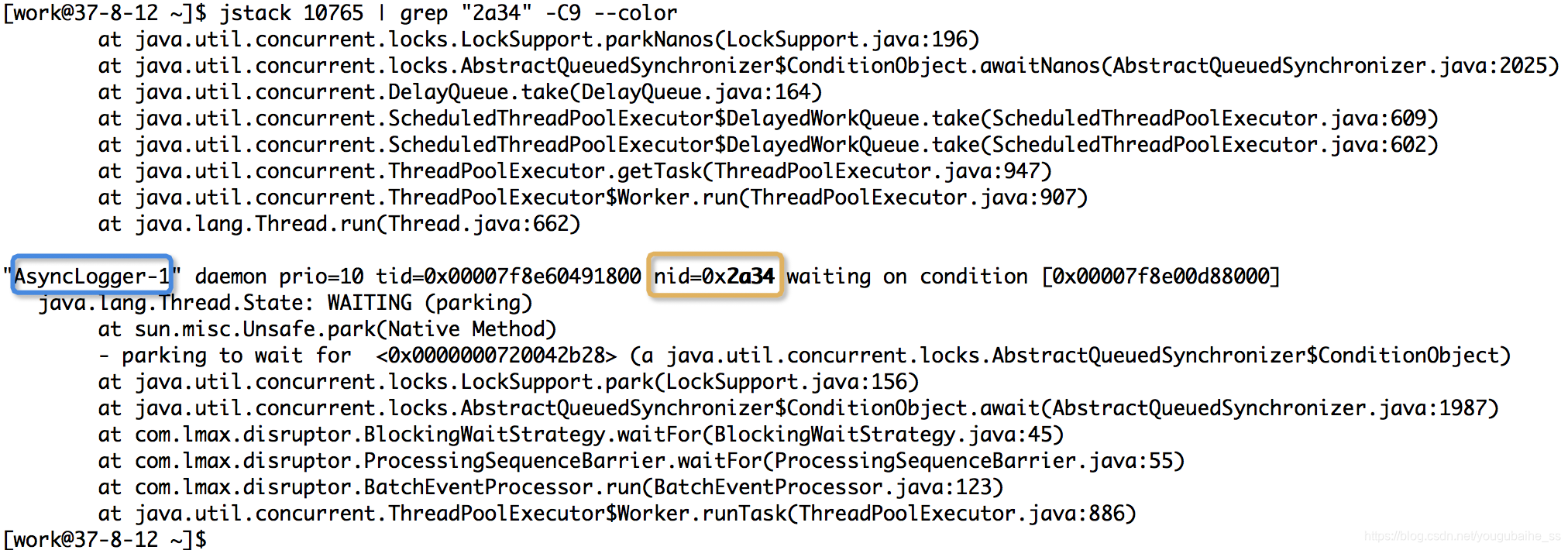
至此,找到了耗CPU高的线程对应的线程名称“AsyncLogger-1”,而这个线程名称是我们业务代码中给线程取的名称,可以快速定位到业务代码。
tips:给线程取一个与业务处理相关的名称,对快速定位问题尤为重要。
如果我们没有给线程取名称“AsyncLogger-1”,那打印出来的线程名称可能是:

通过不知名的线程名称“pool-5-thread-1”,以及只包含jdk代码的线程栈信息,我们无法定位到业务代码。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









