







HDFS是hadoop框架中的存储技术,由他来决定文件应该怎么存储在分布式集群当中,下面文章将讲述常见的HDFS操作
HDFS操作常用Shell命令
1、启动hadoop (在master上执行)
start-all.sh
mr-jobhistory-daemon.sh start historyserver

使用帮助
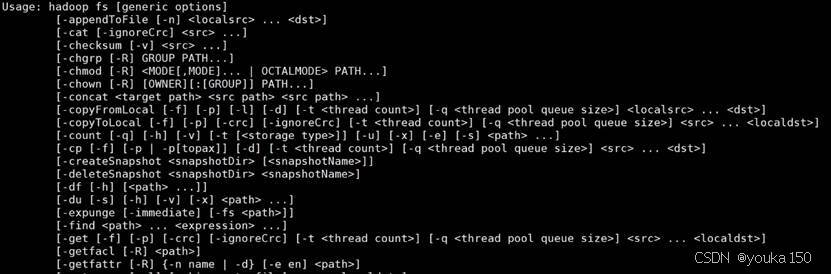
可以在终端输入如下命令,查看hdfs dfs总共支持哪些操作:
hdfs dfs
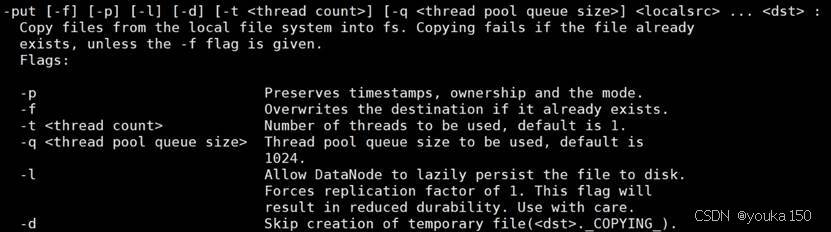
可以查看某个命令的作用,比如,当需要查询put命令的具体用法时,可以采用如下命令:
hdfs dfs -help put
2、目录操作
需要注意的是,Hadoop系统安装好以后,第一次使用HDFS时,需要首先在HDFS中创建用户目录。本教程全部采用hadoop用户登录Linux系统,因此,需要在HDFS中为hadoop用户创建一个用户目录,命令如下:
hdfs dfs -mkdir -p /user/hadoop
“/user/hadoop”目录就成为用户对应的用户目录,可以使用如下命令显示HDFS中与当前用户对应的用户目录下的内容:
hdfs dfs -ls .

hdfs dfs -ls /user/hadoop
如果要列出HDFS上的所有目录,可以使用如下命令:
hdfs dfs -ls
如果要列出HDFS根目录下的所有目录,可以使用如下命令:
hdfs dfs -ls /

下面,可以使用如下命令创建一个input目录(这个input目录是创建在用户目录下):
hdfs dfs -mkdir input

如果要在HDFS的根目录下创建一个名称为input的目录,则需要使用如下命令:
hdfs dfs -mkdir /input

可以使用rm命令删除一个目录,比如,可以使用如下命令删除刚才在HDFS中创建的“/input”目录(不是“/user/hadoop/input”目录):
hdfs dfs -rm -r /input

3、文件操作
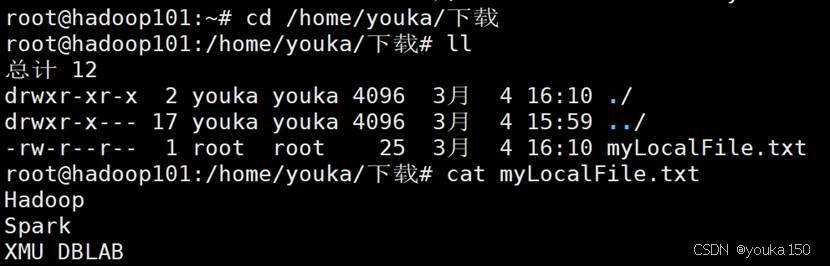
首先,使用vim编辑器,在本地Linux文件系统的“/home/youka/”目录下创建一个文件myLocalFile.txt,
vim myLocalFile.txt
里面可以随意输入一些单词,比如,输入如下三行:
Hadoop
Spark
XMU DBLAB然后,可以使用如下命令把本地文件系统的“/home/youka/myLocalFile.txt”上传到HDFS中的当前用户目录的input目录下,也就是上传到HDFS的“/user/youka/input/”目录下:
本地文件传到HDFS:
./bin/hdfs dfs -put /home/youka/myLocalFile.txt input
可以使用ls命令查看一下文件是否成功上传到HDFS中,具体如下:
hdfs dfs -ls input

下面使用如下命令查看HDFS中的myLocalFile.txt这个文件的内容:
hdfs dfs -cat input/myLocalFile.txt

下面把HDFS中的myLocalFile.txt文件下载到本地文件系统中的“/home/youka/下载”这个目录下(注意大小写!!!),命令如下:
hdfs dfs -get input/myLocalFile.txt /home/youka/下载
可以使用如下命令,到本地文件系统查看下载下来的文件myLocalFile.txt:
cd /home/youka/下载
ls
cat myLocalFile.txt
最后,了解一下如何把文件从HDFS中的一个目录拷贝到HDFS中的另外一个目录。比如,如果要把HDFS的“/user/hadoop/input/myLocalFile.txt”文件,拷贝到HDFS的另外一个目录“/input”中(注意,这个input目录位于HDFS根目录下),可以使用如下命令:
hdfs dfs -cp input/myLocalFile.txt /input
中文的目录名,如果在Ubuntu里需要安装中文输入法,参照:
Ubuntu如何开启中文输入法?(多图教学)_ubuntu中文输入法-CSDN博客
4、利用HDFS的Web管理界面
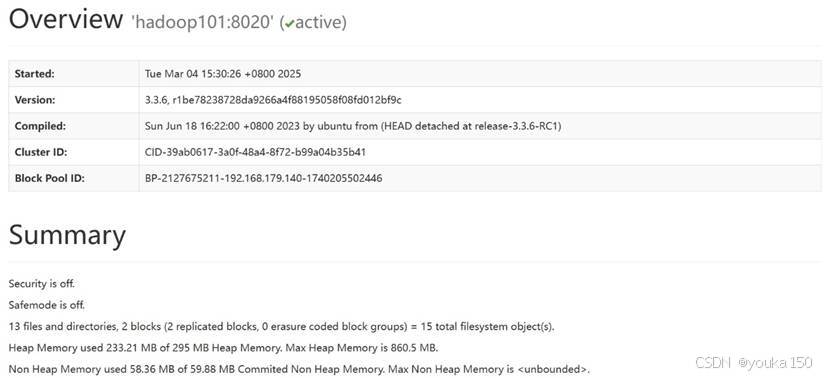
打开浏览器,输入 http://主节点ip地址:9870/,例如我输入了http://hadoop101:9870/,可以在浏览器中查看hadoop集群的状态
里面有各种工具可以使用,例如,选择Utinities下的Browser the file system,可以看到文件系统的状态
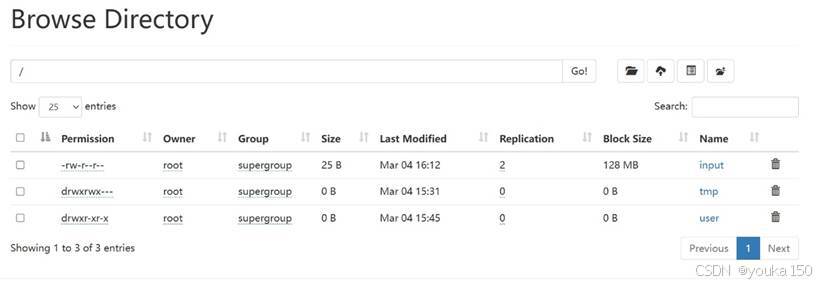
Java操作HDFS
我们首先展现一个例题,以此为例讲述Java API操作HDFS
题目
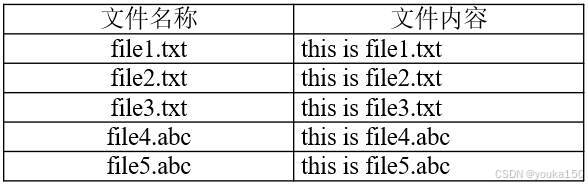
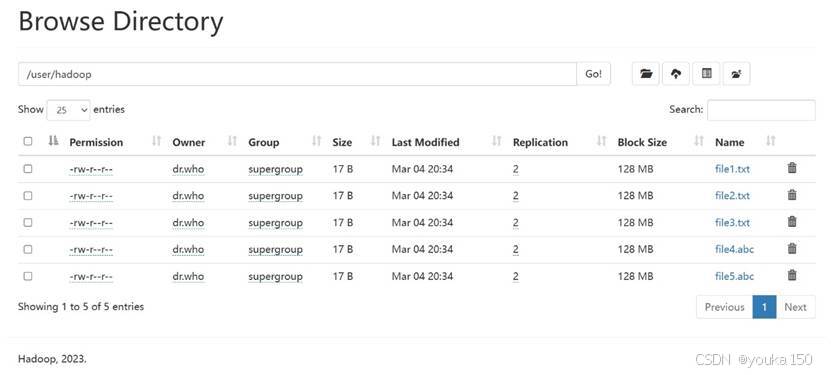
现在要执行的任务是:假设在目录“hdfs://hadoop101:9000/user/hadoop”下面有几个文件,分别是file1.txt、file2.txt、file3.txt、file4.abc和file5.abc,这里需要从该目录中过滤出所有后缀名不为“.abc”的文件,对过滤之后的文件进行读取,并将这些文件的内容合并到文件“hdfs://hadoop101: 8020/user/hadoop/merge.txt”中。文件内容为:
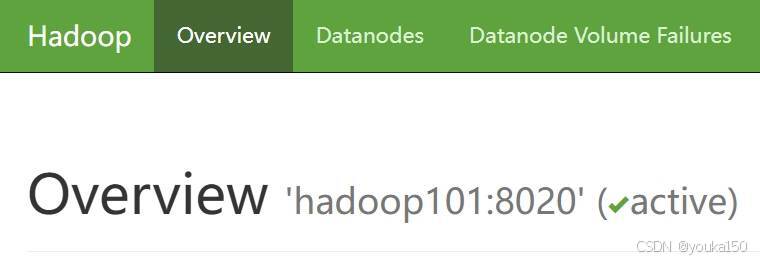
备注:ip地址使用你自己的hadoop hdfs名称节点的虚拟机地址,我的名称节点是hadoop101,9000是hdfs的服务端口号。在这里可以看到hadoop的服务端口号默认是9000(我的是8020):
在IDEA中创建项目:
使用Maven的好处是不需要到处去找相关的jar文件,只需要配置好pom.xml就可以自动从中央仓库下载需要的依赖包(jar文件)。
配置pom.xml
通过使用Java API操作HDFS_使用java api读取hdfs的数据-CSDN博客 发现需要配置三个依赖Apache Hadoop Common、Apache Hadoop HDFS、Apache Hadoop Client(还有一个Junit是做单元测试用的,暂时可以不用),先去下面这个网站看看有哪些可用的版本,以及配置文件应该怎么写
https://mvnrepository.com/
搜索Apache Hadoop Common
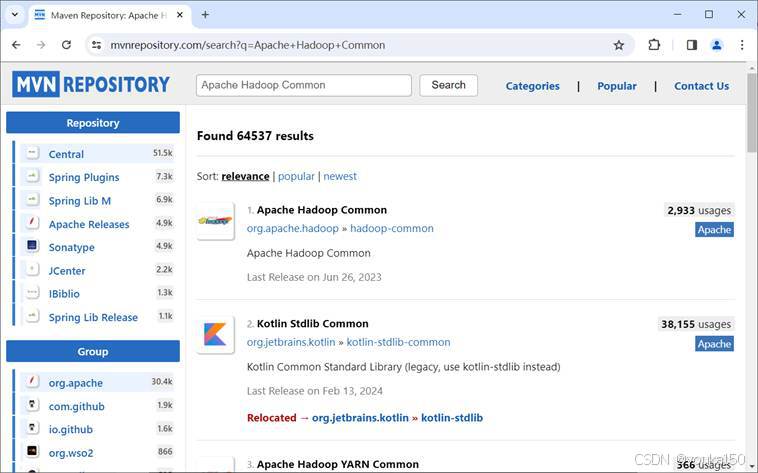
打开找到的第一个Apache Haddoop Common,查看版本号,最新版是3.3.6
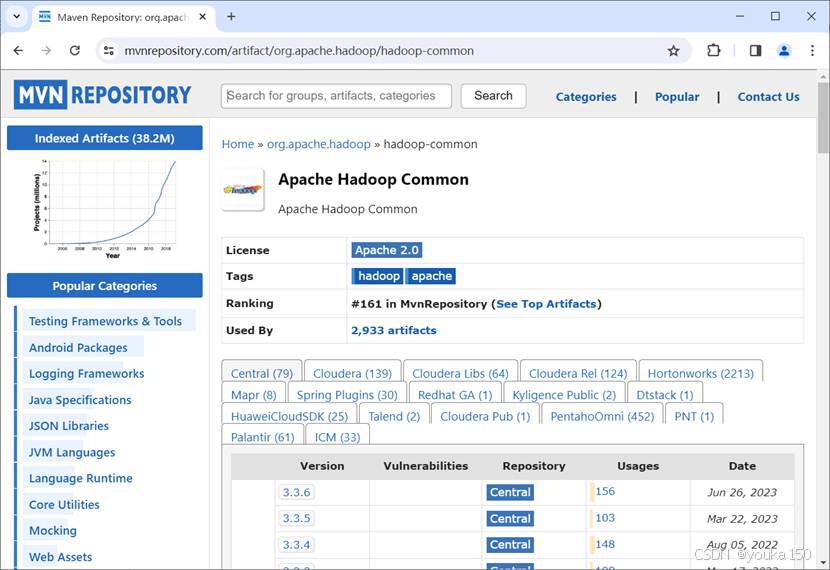
点击3.3.6,查看详情
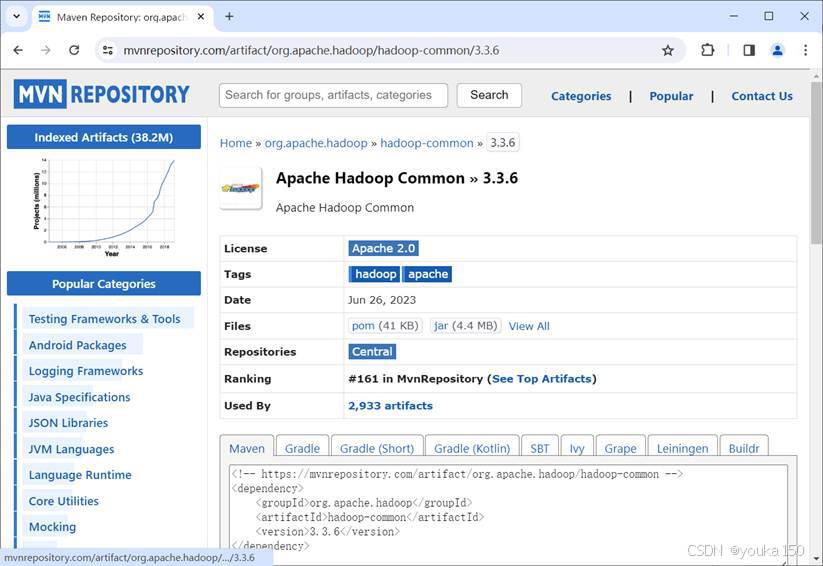
里面有Maven的配置语句,等会儿我们要用
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.6</version>
</dependency>再搜索Apache Hadoop HDFS,
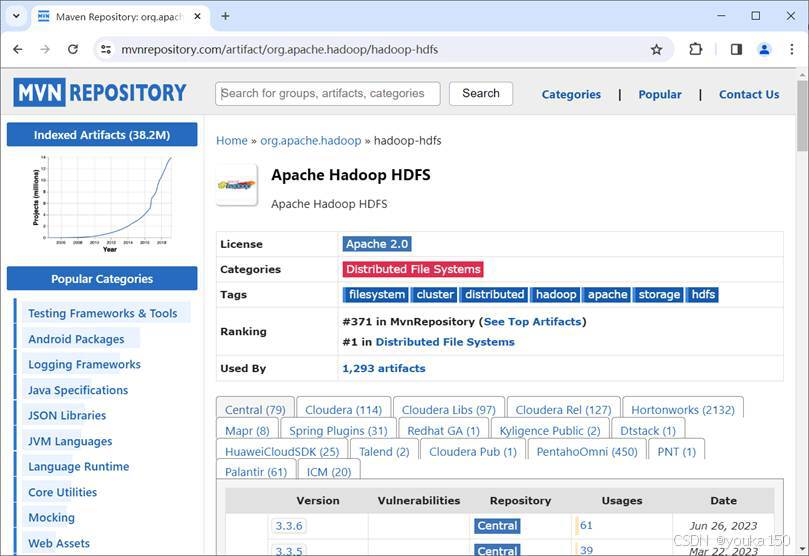
最新版本也是3.3.6,同样方法查看详情
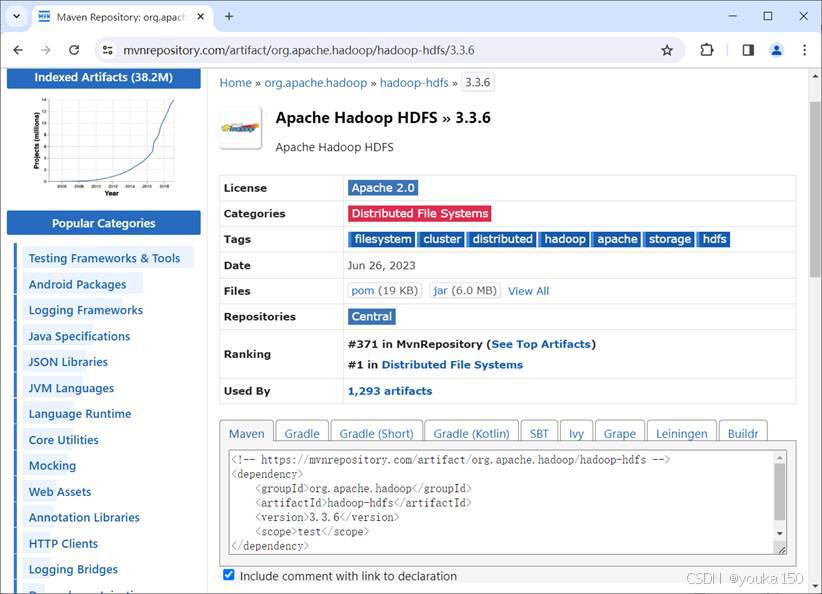
配置代码如下:
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.3.6</version>
<scope>test</scope>
</dependency>
再找到Apache Hadoop Client
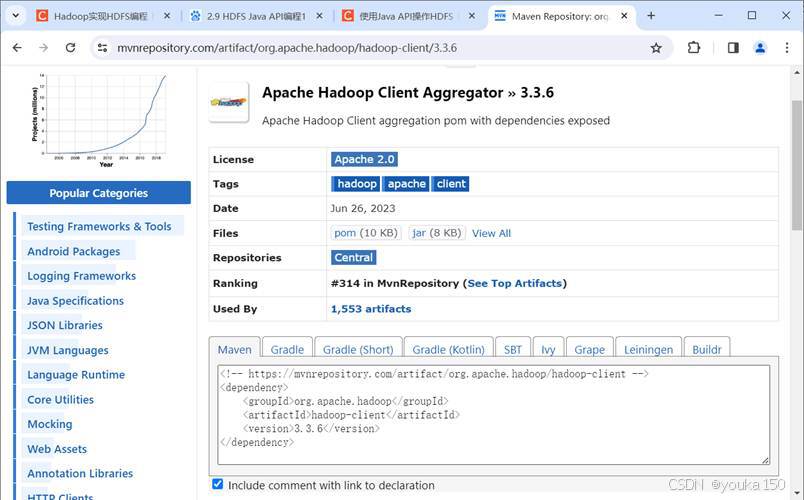
配置代码如下:
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.6</version>
</dependency>
在IDEA中,打开pom.xml(在左边的树形菜单中),这个文件是Maven的核心配置文件
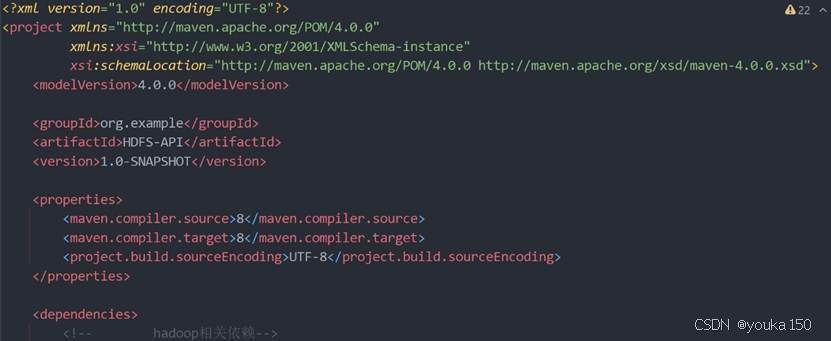
配置dependency,添加内容
相关的包没有下载,所以Maven还认不出来。
刷新一下Maven,让Maven从中央仓库把相关的jar包下载下来,刷新按钮在右上角。
一般来说,你的maven会卡住,这是因为国内访问maven速度很慢,可以配置阿里云镜像,由于我已经配置了,这里就不再多说,可以参考网上的做法
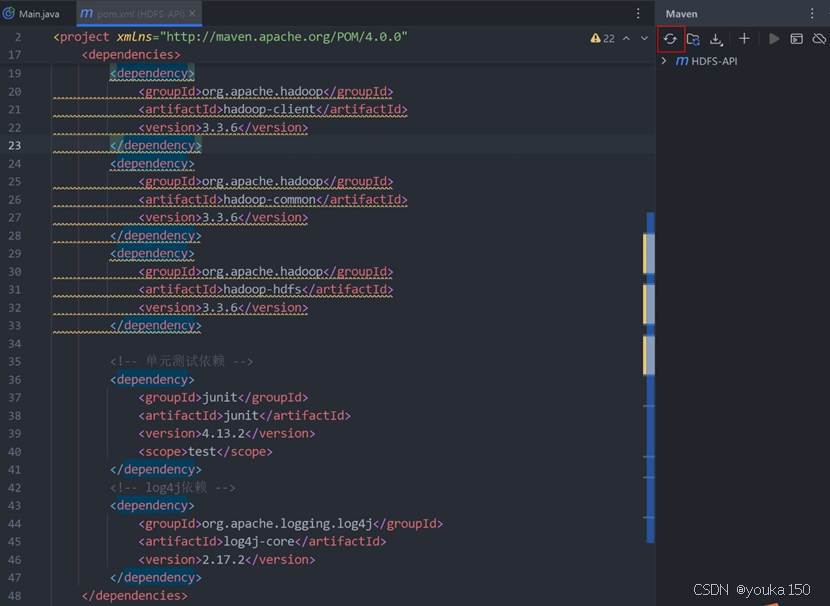
点击右侧的Maven,展开Dependencies,可以看到三个依赖包已经导入进来了:
使用HDFS的Java API 实现文件操作
Hadoop中常用的Java API

先写一个测试类,看看能不能正确操作HDFS,这个测试类主要模仿
https://blog.csdn.net/HMLieder/article/details/128041615
输入下列代码:
package HDFS_API;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.net.URI;
public class CreateFileOnHDFS {
public static void main(String[] args) throws Exception {
// 创建Configuration类的对象,用于HDFS配置
Configuration conf = new Configuration();
// 定义uri字符串
String uri = "hdfs://hadoop101:8020";
// 创建文件系统
FileSystem fs = FileSystem.get(new URI(uri), conf);
// 创建路径对象(文件或者目录)
Path path = new Path(uri + "/input/hadoop.txt");
// 创建文件
boolean result = fs.createNewFile(path);
if (result) {
System.out.println("文件[" + path + "创建成功!");
} else {
System.out.println("文件[" + path + "创建失败!");
}
}
}
检查异常的堆栈,第一条是这样的问题,看来是权限的问题,这里需要有用户名的变量定义,才能正确连接
package HDFS_API;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.net.URI;
public class CreateFileOnHDFS {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String uri = "hdfs://hadoop101:8020";
String user = "root";
FileSystem fs = FileSystem.get(new URI(uri), conf, user);
// 先创建父目录
Path inputDir = new Path("/input");
if (!fs.exists(inputDir)) {
fs.mkdirs(inputDir);
}
// 然后创建文件
Path path = new Path("/input/hadoop.txt");
boolean result = fs.createNewFile(path);
if (result) {
System.out.println("文件[" + path + "]创建成功!");
} else {
System.out.println("文件[" + path + "]创建失败!");
}
}
}
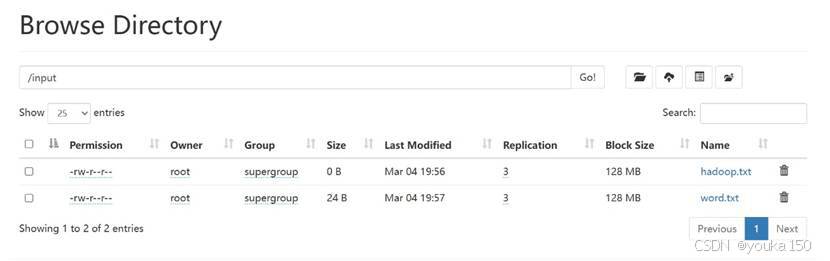
运行成功
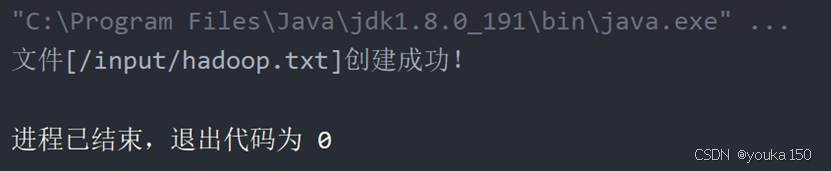
利用HDFS集群WebUI查看成功创建文件
再写一个Java程序,把本地文件上传到hadoop集群中:
package HDFS_API;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import java.io.FileInputStream;
import java.net.URI;
public class WriteFileOnHDFS {
public static void main(String[] args) throws Exception {
// 创建Configuration类的对象,用于HDFS配置
Configuration conf = new Configuration();
// 定义uri字符串
String uri = "hdfs://hadoop101:8020";
// 创建文件系统
String user = "root";
FileSystem fs = FileSystem.get(new URI(uri), conf, user);
// 创建路径对象(文件或者目录)
Path path = new Path(uri + "/input/word.txt");
// 创建文件输出流
FSDataOutputStream out = fs.create(path);
// 创建文件输入流
FileInputStream in = new FileInputStream("D:\\BaiduNetdiskDownload\\Spark\\spark-3.4.1-bin-hadoop3\\bin\\input\\word.txt");
// 使用工具类IOUtils来完成文件的相关操作
IOUtils.copyBytes(in, out, conf);
System.out.println("word.txt写入[" + path + "]!");
// 关闭相关对象,节约系统资源
in.close();
out.close();
fs.close();
}
}
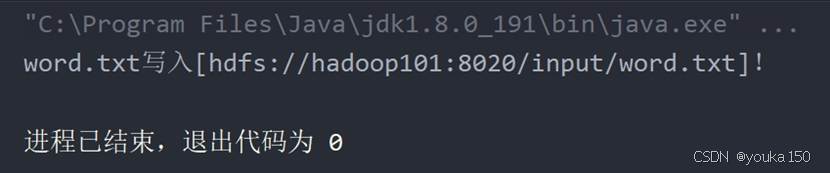
可能会遇到的问题(我都没有遇到过):(1)权限问题;(2)域名解析问题
在C:\Windows\System32\drivers\etc目录下找到hosts文件进行修改
使用Web UI时,hadoop不知道我们是哪个用户,用这里的方法解决一下
https://blog.csdn.net/weixin_51967583/article/details/121214812
Unbuntu shell命令
cd /usr/local/hadoop-3.3.6/etc/hadoop
vim core-site.xml
core-site.xml配置代码:
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
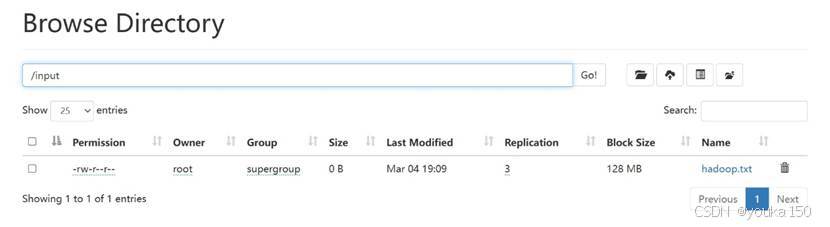
如果没有问题,在web端查看,成功上传
继续完成程序要求:
先在客户端创建file1 file2 file3,先利用Web UI上传这几个文件到指定的目录。这里我一开始上传失败了
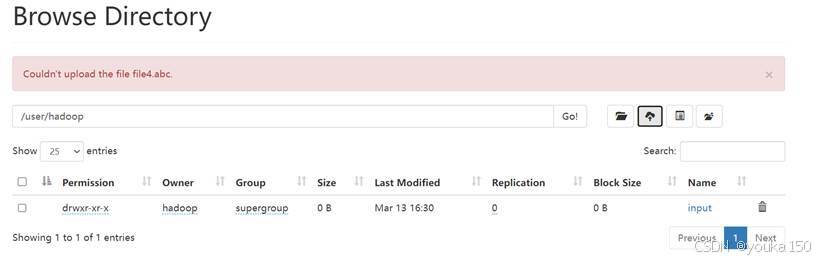
与教程相同,这里是由于/user/hadoop权限不够导致,在Linux中执行:
dfs dfs -chmod 777 /user/hadoop
随后上传成功
编写代码
package HDFS_API;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
// import org.apache.hadoop.io.IOUtils;
// import java.io.FileInputStream;
import java.io.PrintStream;
import java.net.URI;
/**
* 过滤掉文件名满足特定条件的文件
*/
class MyPathFilter implements PathFilter {
String reg;
MyPathFilter(String reg) {
this.reg = reg;
}
public boolean accept(Path path) {
return !(path.toString().matches(reg));
}
}
public class MergeFile {
public static void main(String[] args) throws Exception {
// 创建Configuration类的对象,用于HDFS配置
Configuration conf = new Configuration();
// 定义uri字符串
String uri = "hdfs://hadoop101:8020";
// 创建文件系统
String user = "root";
FileSystem fs = FileSystem.get(new URI(uri), conf, user);
// 创建路径对象(文件或者目录),inputPath为输入路径,outputPath为输出路径
Path inputPath = new Path(uri + "/user/hadoop");
Path outputPath = new Path(uri + "/user/hadoop/merge.txt");
// 列出输入路径下的所有文件,并用MyPathFilter进行过滤,".*\\.abc"为过滤用的正则表达式
FileStatus[] sourceStatus = fs.listStatus(inputPath, new MyPathFilter(".*\\.abc"));
// 为“hdfs://192.168.70.100:9000/user/hadoop/merge.txt”创建一个输出流
FSDataOutputStream fsdos = fs.create(outputPath);
PrintStream ps = new PrintStream(System.out);
// 遍历输入目录下每一个符合要求的文件
for (FileStatus sta : sourceStatus) {
System.out.print("\n路径:" + sta.getPath() + " 文件大小:" + sta.getLen() + " 权限:" + sta.getPermission() + " 内容:");
// 为每一个符合要求的文件创建一个输入流
FSDataInputStream fsdis = fs.open(sta.getPath());
// 创建字符缓冲区
byte[] data = new byte[1024];
int read;
// 如果输入流读取的字符长度>0,就用输出流写到merge.txt中去,同时在本地控制台中输出结果
while ((read = fsdis.read(data)) > 0) {
ps.write(data, 0, read);
fsdos.write(data, 0, read);
}
fsdis.close();
}
ps.close();
fsdos.close();
}
}
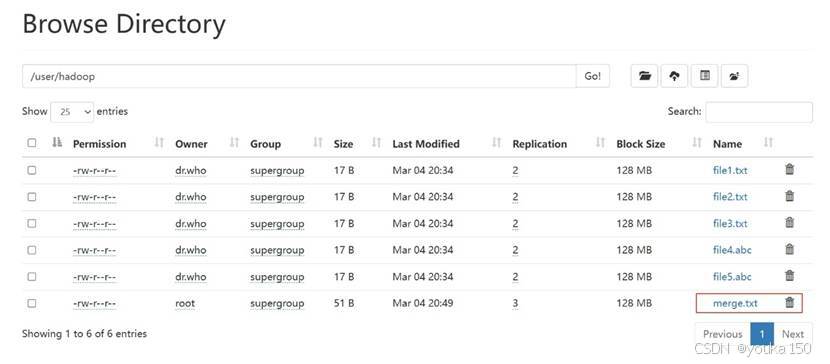
运行成功

WebUI发现已经创建了“merge.txt”文件
在命令行显示正确
![]()

















 1572
1572

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









