







理论和源代码分析:
一,数据输入格式(InputFormat)用于描述MapReduce的作业
数据输入规范。MapReduce框架依靠数据输入格式完成输入
规范检查(比如输入文件的目录的检查),对数据文件进行
输入分块(InputSplit),以及提供从输入分块中 将数据逐一
读出,并转换为,Map过程的输入键值对等功能。
最常用的数据输入格式:TextInputFormat和KeyValueTextInputFormat
1,TextInputFormat是系统默认的数据输入格式,可以
将文本文件分块并逐行读入以便Map节点进行处理。读入一行时
所产生的主键key就是当前在整个文本文件中的字节偏移位置,
而value就是该行的内容。
KeyValueTextInputFormat是可将一个按照<key,value>格式逐行
存放的文本文件逐行读出,并自动解析生产相应的的key和value.
对于一个数据输入格式(TextInputFormat和KeyValueTextInputFormat)
,都需要有一个对应的RecordReader方法。RecordReader主要用于将一个
文件中的数据记录分拆成具体的键值对,传送给Map过程作为键值对
输入参数。每个数据输入格式都有输入格式有一个默认的RecordReader。
1,TextInputFormat的默认RecordReader是LineRecordReader。
2,KeyValueTextInputFormat的默认RecordReader是KeyValueLineRrcordReader
二,数据输出格式(OutputFormat)用于描述MapReduce作业的数据输出规范。
MapReduce框架依靠数据格式完成输出规范检查(如检查输出目录是否存在)
以及提供作业数据输出等功能。
最常用的数据输出格式是TextOutputFormat,也是系统默认的数据输出格式
可以将计算结果以"key+\t+value"的形式输出到文本文件中。
数据输出格式也提供一个对应的RecordWriter,以便系统明确输出结果写入到
文件中的具体格式。TextInputFormat的默认RecordWriter是lineRecordWriter
也是将计算结果以"key+\t+value"的形式输出到文本文件中。
查看KeyValueTextInputFormat源码:
1,点击KeyValueTextInputFormat.class进入源码:
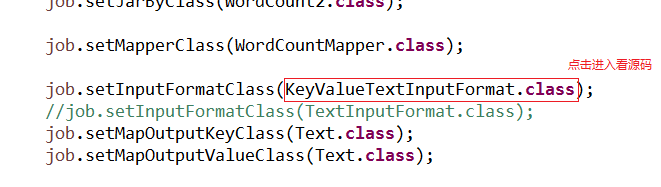
2,在KeyValueTextInputFormat类中找到RecordReader方法点击
KeyValueLineRecordReader进入到KeyValueLineRecordReader类
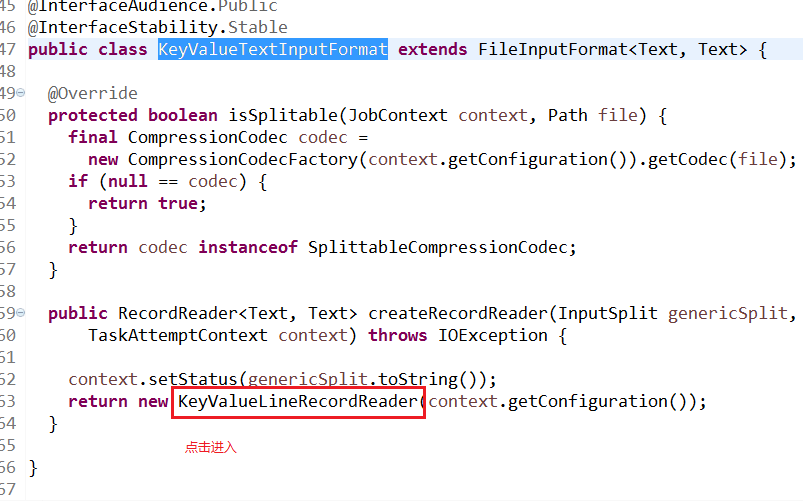
3,查看具体的KeyValueLineRecordReader方法:
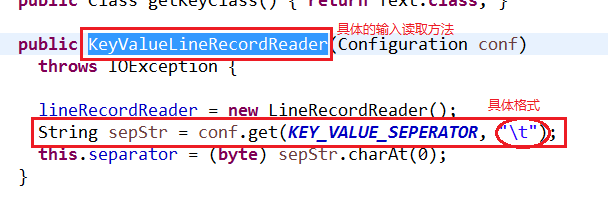
输出数据格式的源码也类似以上的查看,可以根据源码的内容自定义,自己的输入输出格式。















 252
252

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









