









利用python-docx完成英语单词默写本的制作
制作结果

实现源码
from docx import Document
from docx.shared import Pt
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
def Read_csv_all(filename, encoding):
# 读取csv文件中的所有单词
ls = []
fr = open(filename, 'r', encoding = encoding)
for line in fr.readlines():
items = line.strip('\n').split(',')
for item in items:
if item != None and item != '':
ls.append(item)
fr.close()
return ls
def Add_content(table, row, col, word):
# 将单词放到相应的单元格内
cell = table.cell(row, col)
cell.text = ''
p = cell.paragraphs[0]
p.alignment = WD_PARAGRAPH_ALIGNMENT.LEFT
word = p.add_run("{} ".format(word))
word.font.name = 'Times New Roman'
word.font.size = Pt(16)
Underline = p.add_run(" ")
Underline.font.size = Pt(16)
Underline.underline = True
def Add_TableSeq(table, SeqBegin, SeqEnd):
# 处理一个序列的单词,从SeqBegin到SeqEnd
for i in range(SeqBegin, SeqEnd):
Add_content(table, i, 0, Words_List[2*i])
if 2*i + 1 < Amount:
Add_content(table, i, 1, Words_List[2*i + 1])
document = Document()
Words_List = Read_csv_all('words.csv', encoding='UTF-8')
Amount = len(Words_List)
rownum = Amount // 2 + 1 if Amount % 2 else Amount // 2
colnum = 2
table = document.add_table(rows=rownum, cols=colnum, style='Table Grid')
Add_TableSeq(table, 0, rownum)
document.save('words.docx')
接下来介绍程序模块
一、数据读入模块
这里需要自行将单词数据转换成单词列表的形式,我将单词数据全部保存在csv文件中,故直接读取csv文件中的所有单词即可。
def Read_csv_all(filename, encoding):
# 读取csv文件中的所有单词
ls = []
fr = open(filename, 'r', encoding = encoding)
for line in fr.readlines():
items = line.strip('\n').split(',')
for item in items:
if item != None and item != '':
ls.append(item)
fr.close()
return ls
二、python-docx库
该程序需要的第三方库只有docx,因此只需要安装docx库就能实现该功能了。命令行输入以下指令便可以安装该包。
pip install python-docx
需要用到的子模块有Document,Pt以及WD_PARAGRAPH_ALIGNMENT。
from docx import Document
from docx.shared import Pt
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
其中最重要的模块就是Document类,用来创建Document实例,进行docx文件的创建、编辑、修改以及保存。
Pt用来设置段落字体的大小。
WD_PARAGRAPH_ALIGNMENT中包括与段落位置相关的枚举类型常量,比如WD_PARAGRAPH_ALIGNMENT.LEFT指的是段落左对齐。
WD_PARAGRAPH_ALIGNMENT中其他设置如下:
| type | 含义 | 值 |
|---|---|---|
| WD_PARAGRAPH_ALIGNMENT.LEFT | 左对齐 | 0 |
| WD_PARAGRAPH_ALIGNMENT.CENTER | 居中 | 1 |
| WD_PARAGRAPH_ALIGNMENT.RIGHT | 右对齐 | 2 |
| WD_PARAGRAPH_ALIGNMENT.JUSTIFY | 两端对齐 | 3 |
| WD_PARAGRAPH_ALIGNMENT.DISTRIBUTE | 分散对齐 | 4 |
- 其他段落格式设置请访问python-docx段落设置
三、docx文件的编辑
首先初始化一个Document的实例
document = Document()
然后读入单词数据,生成单词列表,Amount变量记录单词总个数。
为了实现左右两侧的单词严格对齐,这里使用了表格作为容器。
rownum指的是表格的总行数,一行两个单词,故rownum为2除单词个数向上取整。colnum为列数,固定为2。
Words_List = Read_csv_all('words2.csv', encoding='UTF-8')
Amount = len(Words_List)
rownum = Amount // 2 + 1 if Amount % 2 else Amount // 2
colnum = 2
接下来是程序的关键代码
初始化表格,表格的格式为Table Grid。选用这种格式是因为它没有背景色。
- 需要使用其他的表格格式请访问表格样式列表
table = document.add_table(rows=rownum, cols=colnum, style='Table Grid')
下述两种代码都是在单元格内新建段落,但是为什么我选择了前者呢?
def Add_content(table, row, col, word):
# 将单词放到相应的单元格内
cell = table.cell(row, col)
cell.text = ''
p = cell.paragraphs[0]
p = table.cell(row, col).add_paragraph()
这是因为后者在新建段落时前面插入了一个换行符,结果如下图所示。

而用前面的方法新建段落就不会这样。
下面设置单元格内段落所含文本的格式。
p.alignment = WD_PARAGRAPH_ALIGNMENT.LEFT # 段落左对齐
word = p.add_run("{} ".format(word)) # 段落添加单词
word.font.name = 'Times New Roman' # 文本字体style设置
word.font.size = Pt(16) # 文本字体大小设置
Underline = p.add_run(" ")
Underline.font.size = Pt(16)
Underline.underline = True # 下划线
最后处理所有的单元格
def Add_TableSeq(table, SeqBegin, SeqEnd):
# 处理一个序列的单词,从SeqBegin到SeqEnd
for i in range(SeqBegin, SeqEnd):
Add_content(table, i, 0, Words_List[2*i])
if 2*i + 1 < Amount:
Add_content(table, i, 1, Words_List[2*i + 1])
四、运行结果处理
最后运行的结果可能看不到下划线,如下图所示

要在word文件->选项->高级中将为尾部空格添加下划线选项勾选
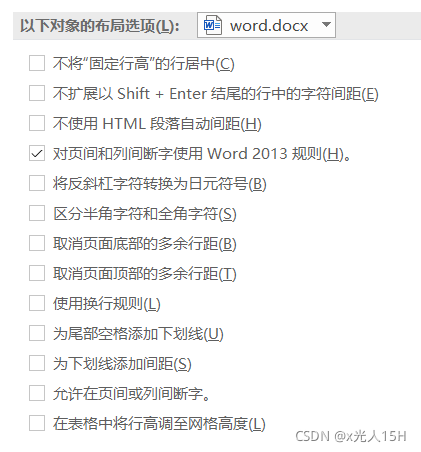
然后将表格设置成无框线即可完成制作。单词较多时运行时间较长,请耐心等待。
感谢大家的阅读!有不对的地方请在评论区加以指正!

















 291
291

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









