







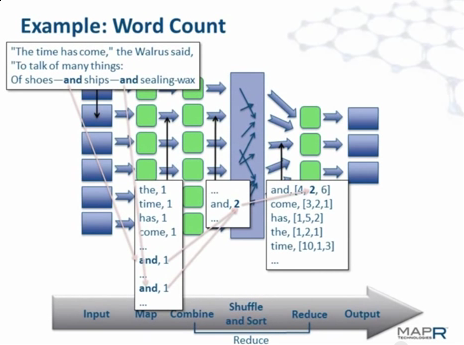
一个map-reduce流水线是一个任务,多条任务同时处理。
此图之前的数据分割省略,假定数据已被分成最左边蓝色大小的块,那么传给map的<key,value>就可能是,
key为数据块所属文件及偏移,value为该数据块包含的文本,map函数开始统计,生成一个列表list<word, 1>,
输出就是<key, value> == <list<word>, list<1>>,就是每个单词统计一次,无视重复,combine则是去重的,输出
的<key, value> == <list<word>, list<count>>,然后进入shuffle阶段,shuffle开始合并多条流水线,也可以看作是
去重,输出的<key, value> == <list<word>, list<count1, count2, count3>>,然后每个reduce只要把传给它的中间
结果统计一下就得到映射到它这条流水线的单词集的计数了,其它的流水线也有自己的单词集计数,所有流水线合
起来就是所有文本的单词集的计数了
一图胜千言
















 2615
2615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









