







Elasticsearch搜索引擎
一、概述
1. 概念
es是基于lucene的全文检索服务器,对外提供restful接口
2. 原理
使用倒排索引实现从 关键词 -> 文档 的快速查询
2.1 正排索引
把文档内容进行分词提取关键词,使用关键词+关键词出现的次数+关键词位置来代表这一文档,每一个文档又都有一个文档ID,则文档ID->关键词信息列表的索引结构就是正排索引
2.2 倒排索引
使用es通过单词进行搜索某文档,若使用正排索引,无法根据单词查文档,只能扫描所有文档内容,检索是否包含此单词,效率低下。既然使用单词查文档,那么可以把 文档ID->关键词信息列表 的结构反转过来变为 关键词信息-> 文档ID列表 这样的索引结构,以便使用索引,这样的索引就是倒排索引。
-
倒排索引:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eQ9bD4Pb-1666797764425)(C:\Users\wangp\AppData\Roaming\Typora\typora-user-images\image-20221025205401413.png)]](https://img-blog.csdnimg.cn/e99fa39392a34478b4bd007878bf607c.png)
- 倒排列表:所有文档信息的集合
- 每条数据对应一个分词,记录包含此分词的所有文档的ID集合,还记录在某文档出现的次数,位置。[[ID1, 词频1, 位置1],[ID2, 词频2, 位置2],…]
- 词典:所有文档提取出的分词所构成的字符串集合
- 每个分词都是唯一的
- 每条记录除了包含分词外,还包含该分词到其对应的倒排列表的指针,通过此指针可以快速定位到关键词对应的文档集合
- 词典索引:词典太大,则只将词典的索引放入内存
- 词典索引结构一般采用前缀树,也可使用哈希表
- 通过前缀树找到以此开头的所有单词所属的磁盘块,再去磁盘块找到单词及其文档列表
- 倒排列表:所有文档信息的集合
二、安装Elasticsearch
1. 环境要求
- jdk 必须是 jdk1.8.0_131 以上版本
- ElasticSearch 需要至少4096 的线程池和 262144字节以上空间的虚拟内存才能正常启动,所以需要为虚拟机分配至少1.5G以上的内存
- 从5.0开始,ElasticSearch 安全级别提高了,不允许采用root帐号启动,需另外创建用户
- Elasticsearch的插件要求至少centos的内核要3.5以上版本
2. 下载
3. 设置虚拟机内存
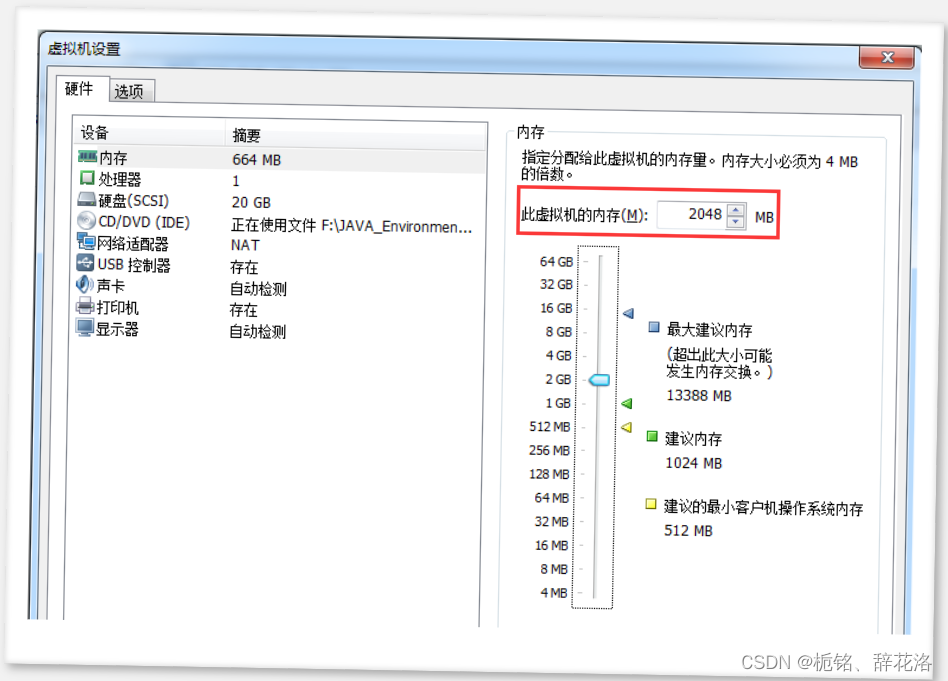
4. 创建用户
从5.0开始,ElasticSearch 安全级别提高了,不允许采用root帐号启动,所以我们要添加一个用户,如果已经有其他用户则可跳过此步骤
-
创建 elk 用户组
-
groupadd elk
-
-
创建用户admin
-
useradd admin passwd admin
-
-
将admin用户添加到elk组
-
usermod -G elk admin
-
-
为用户分配权限
-
#chown将指定文件的拥有者改为指定的用户或组 -R处理指定目录以及其子目录下的所有文件 chown -R admin:elk /usr/upload chown -R admin:elk /usr/local
-
-
切换用户
-
su admin
-
5. 解压安装
tar -zxvf elasticsearch-6.2.3.tar.gz -C /usr/local
ES的目录结构
bin 目录:可执行文件包
config 目录:配置相关目录
lib 目录:ES 需要依赖的 jar 包,ES 自开发的 jar 包
logs 目录:日志文件相关目录
modules 目录:功能模块的存放目录,如aggs、reindex、geoip、xpack、eval
plugins 目录:插件目录包,三方插件或自主开发插件
data 目录:在 ES 启动后,会自动创建的目录,内部保存 ES 运行过程中需要保存的数据。
6. 配置文件
ES安装目录config中配置文件如下:
elasticsearch.yml:用于配置Elasticsearch运行参数
jvm.options:用于配置Elasticsearch JVM设置
log4j2.properties:用于配置Elasticsearch日志,es使用log4j
6.1 修改elasticsearch.yml
cluster.name: example
node.name: example_node_1
network.host: 0.0.0.0
http.port: 9200
transport.tcp.port: 9300
discovery.zen.ping.unicast.hosts: ["0.0.0.0:9300", "0.0.0.0:9301"]
path.data: /usr/local/elasticsearch-6.2.3/data
path.logs: /usr/local/elasticsearch-6.2.3/logs
http.cors.enabled: true
http.cors.allow-origin: /.*/
elasticsearch.yml 常用配置项
cluster.name:
配置elasticsearch的集群名称,默认是elasticsearch。建议修改成一个有意义的名称。
node.name:
节点名,通常一台物理服务器就是一个节点,es会默认随机指定一个名字,建议指定一个有意义的名称,方便管理一个或多个节点组成一个cluster集群,集群是一个逻辑的概念,节点是物理概念,后边章节会详细介绍。
path.data:
设置索引数据的存储路径,默认是es_home下的data文件夹,可以设置多个存储路径,用逗号隔开。
path.logs:
设置日志文件的存储路径,默认是es_home下的logs文件夹
network.host:
设置绑定主机的ip地址,设置为0.0.0.0表示绑定任何ip,允许外网访问,生产环境建议设置为具体的ip。
http.port: 9200
设置对外服务的http端口,默认为9200。
transport.tcp.port: 9300
集群结点之间通信端口
discovery.zen.ping.unicast.hosts:[“host1:port”, “host2:port”, “…”]
设置集群中master节点的初始列表。
discovery.zen.ping.timeout: 3s
设置ES自动发现节点连接超时的时间,默认为3秒,如果网络延迟高可设置大些。
http.cors.enabled:
是否支持跨域,默认为false
http.cors.allow-origin:
当设置允许跨域,默认为*,表示支持所有域名
6.2 修改 jvm.options
将 Xmx 设置为不超过物理内存的一半,两个值设置为相等
-Xms512m
-Xmx512m
7. 启动和关闭
7.1 启动
需要先切换到其他非 root 用户,再启动 su admin
启动过程可能会有各种报错,在步骤8中处理
./elasticsearch
# 或
./elasticsearch -d
7.2 关闭
ps-ef|grep elasticsearch
kill -9 pid
8 报错处理
处理报错,先切换到 root 用户,将所有报错问题修改完毕,再切换回非root
su root
8.1 解决内核问题
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rCyFqhJl-1666797764427)(C:\Users\wangp\Desktop\java_note\note\06-微服务\d\动力优品07 - 全文检索服务ElasticSearch\课件\动力优品07 - 全文检索服务ElasticSearch\assets\1528598315714.png)]](https://img-blog.csdnimg.cn/87d4be306ae1416cb26c5a67bb064065.png)
我们使用的是centos6,其linux内核版本为2.6。而Elasticsearch的插件要求至少3.5以上版本。所以直接禁用这个插件即可。
修改elasticsearch.yml文件,在最下面添加如下配置:
bootstrap.system_call_filter: false
8.2 解决文件创建权限问题
[1]: max file descriptors [4096] for elasticsearch process likely too low, increase to at least [65536]
Linux 默认来说,一般限制应用最多创建的文件是 4096个。但是 ES 至少需要 65536 的文件创建权限。我们用的是admin用户,而不是root,所以文件权限不足。
使用root用户修改配置文件:
vim /etc/security/limits.conf
追加下面的内容:
* soft nofile 65536
* hard nofile 65536
8.3 解决线程开启限制问题
[2]: max number of threads [1024] for user [admin] is too low, increase to at least [4096]
默认的 Linux 限制 root 用户开启的进程可以开启任意数量的线程,其他用户开启的进程可以开启1024 个线程。必须修改限制数为4096+。因为 ES 至少需要 4096 的线程池预备。
如果虚拟机的内存是 1G,最多只能开启 3000+个线程数。至少为虚拟机分配 1.5G 以上的内存。
使用root用户修改配置:
vim /etc/security/limits.d/90-nproc.conf
修改下面的内容:
* soft nproc 1024
改为:
* soft nproc 4096
8.4 解决虚拟内存问题
[3]: max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least [262144]
ES 需要开辟一个 262144字节以上空间的虚拟内存。Linux 默认不允许任何用户和应用直接开辟虚拟内存。
vim /etc/sysctl.conf
追加下面内容:
vm.max_map_count=655360 #限制一个进程可以拥有的VMA(虚拟内存区域)的数量
然后执行命令,让sysctl.conf配置生效:
sysctl -p
三、安装Kibana
Kibana是ES提供的一个基于Node.js的管理控制台,主要用来编辑请求语句,操作es
1. 下载
2. 安装
在 windows 中安装,直接解压即可
3. 修改配置config/kibana.yml
server.port: 5601
server.host: "0.0.0.0" #允许来自远程用户的连接
elasticsearch.url: http://192.168.204.132:9200 #Elasticsearch实例的URL
4. 启动
./bin/kibana
5. 访问
浏览器访问:http://127.0.0.1:5601
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TeZFo18n-1666797764428)(C:\Users\wangp\AppData\Roaming\Typora\typora-user-images\image-20221026000606915.png)]](https://img-blog.csdnimg.cn/31d420dcbf054936a327e703c6bd0063.png)
四、安装head
head插件是ES的一个可视化管理插件,主要用于查看数据,也可用来监视ES的状态,并通过head客户端和ES服务进行交互,比如创建映射、创建索引等。从ES6.0开始,head插件支持使得node.js运行。
1. 下载
2. 安装
在 windows 中,解压即可
3. 启动
npm run start
3. 访问
浏览器访问:http://127.0.0.1:9100/
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OQorSlYS-1666797764428)(C:\Users\wangp\AppData\Roaming\Typora\typora-user-images\image-20221026000457872.png)]](https://img-blog.csdnimg.cn/cfd2d5806a24449db8fc58f4a7c60ada.png)
五、ES基本使用
es 与 数据库的类比
| elasticsearch | 关系数据库 |
|---|---|
| index(索引库) | database(数据库) |
| type(类型) | table(表) |
| document(文档) | row(记录) |
| field(域) | column(字段) |
使用 kibana 进行语法测试,进入kibana的ui界面,进入Dev Tools,进入Console
1. index
1.1 创建index
PUT /index0
{
"settings": {
"number_of_shards": 2,
"number_of_replicas": 1
}
}
number_of_shards : 表示一个索引库将拆分成多片分别存储不同的结点,部署在不同的服务器上,提高了ES的处理能力
number_of_replicas :是为每个 primary shard分配的replica shard数,和主节点相当于主从的关系,所以需要位于不同的服务器上,若只有一台机器,则设置为0
这里先用一台机器进行部署
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DpJhiqVa-1666797764429)(C:\Users\wangp\AppData\Roaming\Typora\typora-user-images\image-20221026000838327.png)]](https://img-blog.csdnimg.cn/a25e3596bb884294b6601a2672890966.png)
运行后,进入elasticsearch-head界面进行查看
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eJO5t8w9-1666797764431)(C:\Users\wangp\AppData\Roaming\Typora\typora-user-images\image-20221026001829596.png)]](https://img-blog.csdnimg.cn/0fe1862e329b4e30ae3d28ee753917c8.png)
1.2 修改index
索引一旦创建,primary shard 数量不可变化,可以改变replica shard 数量
PUT /java06/_settings
{
"number_of_replicas" : 0
}
1.3 删除index
DELETE /index0
2. mapping
映射,创建映射就是向索引库中创建field(类型、是否索引、是否存储等特性)的过程
2.1 创建mapping
POST /index0/type0/_mapping
{
"properties": {
"name": {
"type": "text"
},
"description": {
"type": "text"
},
"studymodel": {
"type": "keyword"
}
}
}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-m5gziO32-1666797764433)(C:\Users\wangp\AppData\Roaming\Typora\typora-user-images\image-20221026002703084.png)]](https://img-blog.csdnimg.cn/3898f5b1c2f140409fbd9a59c061e10c.png)
2.2 查询mapping
查询所有索引的映射
GET /index0/type0/_mapping
2.3 删除
删除索引来删除映射
3. document
3.1 创建document
语法:POST /index_name/type_name/id
POST /index0/type0/1
{
"name": "python从入门到放弃",
"description": "人生苦短,我用Python",
"studymodel": "201002"
}
不给定 id 则随机生成字符串 id
POST /index0/type0
{
"name": "php从入门到放弃",
"description": "php是世界上最好的语言",
"studymodel": "201001"
}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ebZ9ih5f-1666797764434)(C:\Users\wangp\AppData\Roaming\Typora\typora-user-images\image-20221026003530236.png)]](https://img-blog.csdnimg.cn/8acb6fab87174787b67d9be698845cbe.png)
3.2 PUT
语法:PUT/index_name/type_name/id{field_name:field_value}
若 id 不存在则为新增,id 已存在则为更新,id 不能为空
PUT /index0/type0/3
{
"name":".net从入门到放弃",
"description":".net程序员谁都不服",
"studymodel":"201003"
}
结果
{
"_index": "index0", 新增的 document 在什么 index 中,
"_type": "type0", 新增的 document 在 index 中的哪一个 type 中。
"_id": "1", 指定的 id 是多少
"_version": 1, document 的版本是多少,版本从 1 开始递增,每次写操作都会+1
"result": "created", 本次操作的结果,created 创建,updated 修改,deleted 删除
"_shards": { 分片信息
"total": 2, 分片数量只提示 primary shard
"successful": 1, 数据 document 一定只存放在 index 中的某一个 primary shard 中
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
3.3 查询document
语法:
GET /index_name/type_name/id- ``GET /index_name/type_name/_search?q=field_name:field_value`
查所有
GET /index0/type0/_search
根据id查
GET /index0/type0/1
条件查
查询名称中包括php 关键字的的记录
GET /index0/type0/_search?q=name:php
结果
{
"took": 1, # 执行的时长。单位毫秒
"timed_out": false, # 是否超时
"_shards": { # shard 相关数据
"total": 1, # 总计多少个 shard
"successful": 1, # 成功返回结果的 shard 数量
"skipped": 0,
"failed": 0
},
"hits": { # 搜索结果相关数据
"total": 3, # 总计多少数据,符合搜索条件的数据数量
"max_score": 1, # 最大相关度分数,和搜索条件的匹配度
"hits": [# 具体的搜索结果
{
"_index": "index0",# 索引名称
"_type": "type0", # 类型名称
"_id": "1",# id 值
"_score": 1, # 匹配度分数,本条数据匹配度分数
"_source": { # 具体的数据内容
"name": "php从入门到放弃",
"description": "php是世界上最好的语言",
"studymodel": "201001"
}
]
}
}
3.3 删除Document
ES 中执行删除操作时,ES先标记Document为deleted状态,而不是直接物理删除。当ES 存储空间不足或工作空闲时,才会执行物理删除操作,标记为deleted状态的数据不会被查询搜索到(ES 中删除 index ,也是标记。后续才会执行物理删除。所有的标记动作都是为了NRT(近实时)实现)
语法:DELETE /index_name/type_name/id
DELETE /index0/type0/1
六、ES读写过程
1. documnet routing(数据路由)
当客户端创建document的时候,es需要确定这个document放在该index哪个shard上,这个过程就是document routing。
路由过程:
路由算法:shard = hash(5) %number_of_primary_shards
id:document的_id,可能是手动指定,也可能是自动生成,决定一个document在哪个shard上
number_of_primary_shards*:*主分片數量。
2. 为什么primary shard数量不可变?
原因:假如我们的集群在初始化的时候有5个primary shard,我们往里边加入一个document id=5,假如hash(5)=23,这时该document 将被加入 (shard=23%5=3)P3这个分片上。如果随后我们给es集群添加一个primary shard ,此时就有6个primary shard,当我们GET id=5 ,这条数据的时候,es会计算该请求的路由信息找到存储他的 primary shard(shard=23%6=5) ,根据计算结果定位到P5分片上。而我们的数据在P3上。所以es集群无法添加primary shard,但是可以扩展replicas shard。
3. luke查看ES的逻辑结构
- 拷贝elasticsearch-6.2.3/data到windows
- 双击luke.bat,启动luke
- 使用luke打开data\nodes\0\indices路径
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NAnJ3rXT-1666797764435)(C:\Users\wangp\AppData\Roaming\Typora\typora-user-images\image-20221026010419272.png)]](https://img-blog.csdnimg.cn/aa7b07bba54c44b3b07f30a873007978.png)
七、IK分词器
1. 查看分词器
查看当前索引库使用的分词器:
POST /_analyze
{
"text":"测试分词器,后边是测试内容:spring cloud"
}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tUFw325W-1666797764435)(C:\Users\wangp\AppData\Roaming\Typora\typora-user-images\image-20221026010703402.png)]](https://img-blog.csdnimg.cn/04555d79f6de4c4b842c2baa96bc2b37.png)
则可看出对中文为单字拆分
2. 第三方中文分词器 IK-analyzer
IK-analyzer:最新版在https://code.google.com/p/ik-analyzer/上,IK实现了简单的分词 歧义排除算法,标志着IK分词器从单纯的词典分词向模拟语义分词衍化。 但是也就是2012年12月后没有在更新。
2.1 安装
- 下载zip:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-M1yqywEZ-1666797764437)(C:\Users\wangp\Desktop\java_note\note\06-微服务\d\动力优品07 - 全文检索服务ElasticSearch\课件\动力优品07 - 全文检索服务ElasticSearch\assets\1589293239473.png)]](https://img-blog.csdnimg.cn/5c841b95f4b8405d843ba371960310b2.png)
- 解压到/usr/local/elasticsearch-6.2.3/plugs,并重命名为ik,重启es
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1qJNMBft-1666797764438)(C:\Users\wangp\Desktop\java_note\note\06-微服务\d\动力优品07 - 全文检索服务ElasticSearch\课件\动力优品07 - 全文检索服务ElasticSearch\assets\1589293444503.png)]](https://img-blog.csdnimg.cn/075db458fafb4dd2986a42eeb04555da.png)
- 测试分词效果:
POST /_analyze
{
"text":"中华人民共和国人民大会堂",
"analyzer":"ik_smart"
}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DkC0rAhS-1666797764438)(C:\Users\wangp\AppData\Roaming\Typora\typora-user-images\image-20221026094550383.png)]](https://img-blog.csdnimg.cn/f674b7652c5640b987bb632549085e19.png)
3. ik分词器的两种分词模式
-
ik_max_word
- 搜索时使用(细粒度)
- 会将文本做最细粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为“中华人民共和国、中华人民、中华、华人、人民大会堂、人民、共和国、大会堂、大会、会堂等词语。
-
ik_smart
- 往索引目录写时使用(粗粒度)
- 会做最粗粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为中华人民共和国、人民大会堂。
4. 自定义词库
iK分词器自带的main.dic的文件为扩展词典,stopword.dic为停用词典,直接追加词汇,再将文件格式改为utf-8即可(不是utf-8 BOM)
若自己新建扩展文件需要另存为 utf-8 格式,并在IKAnalyzer.cfg.xml引入
- IKAnalyzer.cfg.xml:配置扩展词典和停用词库
- main.dic:扩展词典,eg:奥利给
- stopword.dic:停用词典,eg:a、an、the、得、地、的
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-I7gnQT4f-1666797764439)(C:\Users\wangp\AppData\Roaming\Typora\typora-user-images\image-20221026100321897.png)]](https://img-blog.csdnimg.cn/840b4caa44374a0ebbd9cb8ce6715d28.png)
八、Field
1. field的数据类型
- 文本
- text (varchar)
- keyword (特殊的varchar)
- 数字
- interger, long, float, double
2. field的属性
-
type
- 指定 field 的类型
-
analyzer
- 指定分词模式
-
index
- 指定是否索引,默认true
-
source
-
某些字段内容很多,放 es 只会占用空间,增大索引,并且业务只需要对该字段搜索, 拿数据去数据库拿,如商品描述,则可通过source的incudes来指定包含其关键词即可
-
POST /index0/type0/_mapping { "_source": { "includes":["description"] } }
-
-
也可以通过excludes参数排除某些字段
-
POST /index0/type0/_mapping { "_source": { "includes":["description"] } }
-
-
3. field 属性设置标准
- type
- 分词是否有意义
- 像身份证号等无需分词,可设置其类型为keyword
- index
- 是否需要搜索,一般都需要搜索,像图片链接等无需搜索
- source
- 是否展示,不展示只搜索则仅设置关键词即可,不必将内容放入es
九、Spring Boot 整合 ES
1. 客户端
- TransportClient:ES提供的传统客户端,官方计划8.0版本删除此客户端
- RestClient:RestClient是官方推荐使用的,它包括两种:REST Low Level Client和 REST High Level Client
2. 搭建工程
2.1 pom.xml引入依赖
<!-- elasticsearch的版本 -->
<properties>
<elasticsearch.version>6.2.3</elasticsearch.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>${elasticsearch.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
</dependencies>
2.2 application.yml 配置文件
spring:
elasticsearch:
rest:
uris:
- http://192.168.40.136:9200
2.3 App 启动类
@SpringBootApplication
public class ESDemoApp {
public static void main(String[] args) {
SpringApplication.run(ESDemoApp.class, args);
}
}
3. ES交互-write
3.1 创建index
3.1.1 普通api
PUT /index1
{
"settings":{
"number_of_shards" : 2,
"number_of_replicas" : 0
}
}
POST /index1/type1/_mapping
{
"_source": {
"excludes":["description"]
},
"properties": {
"name": {
"type": "text",
"analyzer":"ik_max_word",
"search_analyzer":"ik_smart"
},
"description": {
"type": "text",
"analyzer":"ik_max_word",
"search_analyzer":"ik_smart"
},
"studymodel": {
"type": "keyword"
},
"price": {
"type": "float"
},
"pic":{
"type":"text",
"index":false
}
}
}
3.1.2 java端api
先编写一个 ESString 类用来存储 es 语句的 json 字符串,在外部编写好es 语句,直接复制进来变为字符串即可
public class ESString {
public static String CREATE_INDEX ;
public static String CREATE_INDEX_MAPPING;
static {
CREATE_INDEX = "{\n" +
" \"number_of_shards\" : 2,\n" +
" \"number_of_replicas\" : 0\n" +
" }";
CREATE_INDEX_MAPPING = "{\n" +
" \"_source\": {\n" +
" \"excludes\":[\"description\"]\n" +
" }, \n" +
" \t\"properties\": {\n" +
" \"name\": {\n" +
" \"type\": \"text\",\n" +
" \"analyzer\":\"ik_max_word\",\n" +
" \"search_analyzer\":\"ik_smart\"\n" +
" },\n" +
" \"description\": {\n" +
" \"type\": \"text\",\n" +
" \"analyzer\":\"ik_max_word\",\n" +
" \"search_analyzer\":\"ik_smart\"\n" +
" },\n" +
" \"studymodel\": {\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"price\": {\n" +
" \"type\": \"float\"\n" +
" },\n" +
" \"pic\":{\n" +
"\t\t \"type\":\"text\",\n" +
"\t\t \"index\":false\n" +
"\t }\n" +
" }\n" +
"}";
}
}
创建一个测试类 IndexTest
@Autowired
private RestHighLevelClient restHighLevelClient;
//新建index
@Test
void createIndex() throws IOException {
//创建新增索引请求,并给定索引名
CreateIndexRequest createIndexRequest = new CreateIndexRequest("index1");
// 设置索引参数
createIndexRequest.settings(ESString.CREATE_INDEX, XContentType.JSON);
createIndexRequest.mapping("type1", ESString.CREATE_INDEX_MAPPING, XContentType.JSON);
//创建索引操作客户端
IndicesClient indices = restHighLevelClient.indices();
//发送请求并接收响应
CreateIndexResponse createIndexResponse = indices.create(createIndexRequest);
System.out.println(createIndexResponse.isAcknowledged());
}
3.2 删除index
3.2.1 普通api删除
DELETE /index0
3.2.2 java端删除
//删除index
@Test
void deleteIndex() throws IOException {
//创建删除索引请求对象
DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest("index0");
//创建索引操作客户端
IndicesClient indices = restHighLevelClient.indices();
//发送删除请求并接收响应
DeleteIndexResponse deleteIndexResponse = indices.delete(deleteIndexRequest);
System.out.println(deleteIndexResponse.isAcknowledged());
}
3.3 新增文档
3.3.1 api
POST /index1/type1/1
{
"name":"spring cloud",
"description":"spring cloud 是一个微服务框架",
"studymodel":"201001",
"price":5.6
}
3.3.2 java端api
ESString类中加入es创建文档语句,创建其字符串
public static String CREATE_DOCUMENT;
static {
CREATE_DOCUMENT = "{\n" +
" \"name\":\"spring cloud\",\n" +
" \"description\":\"spring cloud 是一个微服务框架\",\n" +
" \"studymodel\":\"201001\",\n" +
" \"price\":5.6\n" +
"}";
}
测试类
//创建新文档记录
@Test
void createDocument() throws IOException {
//创建索引对象,给定索引名类型名及文档ID
IndexRequest indexRequest = new IndexRequest("index1", "type1", "1");
//新增的文档内容
indexRequest.source(ESString.CREATE_DOCUMENT, XContentType.JSON);
//发送新增请求,并接收响应
IndexResponse indexResponse = restHighLevelClient.index(indexRequest);
System.out.println(indexResponse.toString());
}
3.4 修改文档
3.4.1 api
PUT /index1/type1/1
{
"price":66.6
}
3.4.2 java端api
SString
public static String UPDATE_DOCUMENT;
static {
UPDATE_DOCUMENT = "{\n" +
" \"price\":66.6\n" +
"}";
}
测试
//更新文档
@Test
void updateDocument() throws IOException {
UpdateRequest updateRequest = new UpdateRequest("index1", "type1", "1");
updateRequest.doc(updateRequest, XContentType.JSON);
UpdateResponse updateResponse = restHighLevelClient.update(updateRequest);
System.out.println(updateResponse.toString());
}
3.5 删除文档
java端api
@Test
void deleteDocument() throws IOException {
DeleteRequest deleteRequest = new DeleteRequest("index1", "type1", "1");
System.out.println(restHighLevelClient.delete(deleteRequest).toString());
}
4. ES交互-read
环境准备
向索引库中插入一些数据
PUT /index1/type1/1
{
"name": "Bootstrap开发",
"description": "Bootstrap是由Twitter推出的一个前台页面开发css框架,是一个非常流行的开发框架,此框架集成了多种页面效果。此开发框架包含了大量的CSS、JS程序代码,可以帮助开发者(尤其是不擅长css页面开发的程序人员)轻松的实现一个css,不受浏览器限制的精美界面css效果。",
"studymodel": "201002",
"price":38.6,
"pic":"group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg"
}
PUT /index1/type1/2
{
"name": "java编程基础",
"description": "java语言是世界第一编程语言,在软件开发领域使用人数最多。",
"studymodel": "201001",
"price":68.6,
"pic":"group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg"
}
PUT /index1/type1/3
{
"name": "spring开发基础",
"description": "spring 在java领域非常流行,java程序员都在用。",
"studymodel": "201001",
"price":88.6,
"pic":"group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg"
}
4.1 简单查询GET
4.1.1 api
GET /index1/type1/1
4.1.2 java端
//GET简单查询
@Test
void get() throws IOException {
GetRequest getRequest = new GetRequest("index1", "type1", "1");
GetResponse documentFields = restHighLevelClient.get(getRequest);
System.out.println(documentFields.isExists());
if(documentFields.isExists()){
System.out.println(documentFields.getSourceAsString());
}
}
4.2 DSL搜索
DSL(Domain Specific Language)是ES提出的基于json的搜索方式,在搜索时传入特定的json格式的数据来完成不同的搜索需求,DSL比URI搜索方式功能强大
5. ES交互-DSL搜索
5.1 match_all查询
5.1.1 api
GET /index1/type1/1
{
"query" : {
"match_all" : {}
}
}
5.1.2 java端
@Test
void matchAll() throws IOException {
//------1. 构建查找请求-------
SearchRequest searchRequest = new SearchRequest();
searchRequest.indices("index1");
searchRequest.types("type1");
//-----2. 构建查找条件-------
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//查找所有
searchSourceBuilder.query(QueryBuilders.matchAllQuery());
//-------3. 查找条件放入请求中-------
searchRequest.source(searchSourceBuilder);
//-------4. 发送请求并接收响应--------
SearchResponse searchResponse = restHighLevelClient.search(searchRequest);
//----------5. 处理结果---------
SearchHits hits = searchResponse.getHits();
System.out.println("总条数:"+hits.totalHits);
for (SearchHit hit : hits.getHits()) {
System.out.println(hit.getSourceAsString());
}
}
5.2 分页查询
5.2.1 api
GET /java06/course/_search
{
"query" : { "match_all" : {} },
"from" : 1, # 从第几条数据开始查询,从0开始计数
"size" : 3, # 查询多少数据
"sort" : [
{ "price" : "asc" }
]
}
5.2.2 java端
在第二步搜索条件构造器中进行分页和排序即可
//分页
@Test
void matchAllPage() throws IOException {
//------1. 构建查找请求-------
SearchRequest searchRequest = new SearchRequest();
searchRequest.indices("index1");
searchRequest.types("type1");
//-----2. 构建查找条件-------
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//查找所有
searchSourceBuilder.query(new MatchAllQueryBuilder());
//分页并排序
searchSourceBuilder.from(0);
searchSourceBuilder.size(2);
searchSourceBuilder.sort("price", SortOrder.DESC);
//-------3. 查找条件放入请求中-------
searchRequest.source(searchSourceBuilder);
//-------4. 发送请求并接收响应--------
SearchResponse searchResponse = restHighLevelClient.search(searchRequest);
//----------5. 处理结果---------
SearchHits hits = searchResponse.getHits();
System.out.println("总条数:"+hits.totalHits);
for (SearchHit hit : hits.getHits()) {
System.out.println(hit.getSourceAsString());
}
}
5.3 代码优化
所有的查找过程中都有 第一步构建查找请求 和 最后的处理结果,则可将其放入前置和后置方法统一处理
private SearchRequest searchRequest;
private SearchResponse searchResponse;
//junit5.x 使用 @BeforeEach 和 @AfterEach,之前的版本使用 @Before 和 @After
@BeforeEach
public void init(){
//------1. 构建查找请求-------
searchRequest = new SearchRequest();
searchRequest.indices("index1");
searchRequest.types("type1");
}
@AfterEach
public void result(){
//----------5. 处理结果---------
SearchHits hits = searchResponse.getHits();
System.out.println("总条数:"+hits.totalHits);
for (SearchHit hit : hits.getHits()) {
System.out.println(hit.getSourceAsString());
}
}
5.4 match查询
match Query即全文检索,它的搜索方式是先将搜索字符串分词,再使用各各词条从索引中搜索
5.4.1 api
query:搜索关键字
operator:设置为 or 表示关键字拆分后的关键词只要有一个在文档中出现即可,设置为 and 表示拆分后的关键词需同时出现的文档才符合要求
GET /index1/type1/_search
{
"query" : {
"match" : {
"name": {
"query": "spring开发",
"operator": "and"
}
}
}
}
- 上述执行逻辑:
- 将“spring开发”拆分为spirng、开发
- 使用spirng和开发两次去索引中匹配搜索
- operator设置为and,则需同时匹配两词的文档才返回
5.4.2 java端
@Test
void match() throws IOException{
//--------构建查询条件------------
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchQuery("name",
"spring开发").operator(Operator.AND));
//--------条件放入请求对象中------
searchRequest.source(searchSourceBuilder);
//-------------执行搜索------------
searchResponse = restHighLevelClient.search(searchRequest);
}
5.5 multi_match查询
matchQuery是在一个field中去匹配,multiQuery是拿关键字去多个Field中匹配
5.5.1 api
使用关键字 “开发”去匹配name 和description字段
GET /index1/type1/_search
{
"query": {
"multi_match": {
"query": "开发",
"fields": ["name","description"]
}
}
}
适合构建复杂查询条件,生产环境常用
5.5.2 java端
@Test
void multiMatch() throws IOException{
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.multiMatchQuery("开发",
"name", "description"));
searchRequest.source(searchSourceBuilder);
searchResponse = restHighLevelClient.search(searchRequest);
}
5.6 bool查询
布尔查询对应于Lucene的BooleanQuery查询,实现将多个查询组合起来
参数:
must:表示必须,多个查询条件必须都满足。(通常使用must)
should:表示或者,多个查询条件只要有一个满足即可。
must_not:表示非
5.6.1 api
查询name包括“开发”并且价格区间是1-100的文档
GET /index1/type1/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "开发"
}
},
{
"range": {
"price": {
"gte": 50,
"lte": 100
}
}
}
]
}
}
}
5.6.2 java端
@Test
void bool() throws IOException{
//条件构造器
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//构建布尔条件
BoolQueryBuilder boolQueryBuilder = new BoolQueryBuilder();
boolQueryBuilder.must(QueryBuilders.matchQuery("name", "开发"))
.must(QueryBuilders.rangeQuery("price").gte(50).lte(100));
searchSourceBuilder.query(boolQueryBuilder);
//将条件装入查询请求对象
searchRequest.source(searchSourceBuilder);
//执行搜索请求,并接收响应
searchResponse = restHighLevelClient.search(searchRequest);
}
5.7 filter查询
过滤查询。过滤的时候,不进行任何的匹配分数计算,相对于 query 来说,filter 相对效率较高。Query 要计算搜索匹配相关度分数,更加适合复杂的条件搜索
5.7.1 api
使用bool查询,搜索 name中包含 "开发"的数据,且price在 10~100 之间
使用 filter,则 price 不需要计算相关度分数:
GET /index1/type1/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "开发"
}
}
],
"filter": {# 过滤,在已有的搜索结果中进行过滤,满足条件的返回。
"range": {
"price": {
"gte": 1,
"lte": 100
}
}
}
}
}
}
5.7.2 java端
@Test
void filter() throws IOException{
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
BoolQueryBuilder boolQueryBuilder = new BoolQueryBuilder();
boolQueryBuilder.must(QueryBuilders.matchQuery("name", "开发"));
boolQueryBuilder.filter(QueryBuilders.rangeQuery("price").gte(50).lte(100));
searchSourceBuilder.query(boolQueryBuilder);
searchRequest.source(searchSourceBuilder);
searchResponse = restHighLevelClient.search(searchRequest);
}
5.8 highlight查询
高亮显示:高亮不是搜索条件,是显示逻辑,在搜索的时候,经常需要对搜索关键字实现高亮显示
5.8.1 api
GET /index1/type1/_search
{
"query": {
"match": {
"name": "开发"
}
},
"highlight": {
"pre_tags": ["<font color='red'>"],
"post_tags": ["</font>"],
"fields": {"name": {}}
}
}
5.8.2 java端
@Test
void highlight() throws IOException{
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchQuery("name", "spring"));
//设置高亮
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.preTags("<font color='red'>");
highlightBuilder.postTags("</font>");
highlightBuilder.fields().add(new HighlightBuilder.Field("name"));
searchSourceBuilder.highlighter(highlightBuilder);
searchRequest.source(searchSourceBuilder);
searchResponse = restHighLevelClient.search(searchRequest);
}
@AfterEach
public void result(){
//----------5. 处理结果---------
SearchHits hits = searchResponse.getHits();
System.out.println("总条数:"+hits.totalHits);
for (SearchHit hit : hits.getHits()) {
System.out.println(hit.getSourceAsString());
//是否是高亮
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
if (highlightFields != null) {
HighlightField highlightField = highlightFields.get("name");
Text[] fragments = highlightField.getFragments();
System.out.println("高亮字段:" + fragments[0].toString());
}
}
}
十、集群管理
1. 集群结构
ES通常以集群方式工作,这样做不仅能够提高 ES的搜索能力还可以处理大数据搜索的能力,同时也增加了系统的容错能力及高可用
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-f8AG6GiF-1666797764440)(C:\Users\wangp\AppData\Roaming\Typora\typora-user-images\image-20221026225627002.png)]](https://img-blog.csdnimg.cn/badddfa42cc1401daafb1e7ec9bd0d16.png)
此处的设置为:每个主分片有两个副本, 如果某个节点挂了也不影响集群的正常使用,比如节点1挂了,还可以查询位于节点2和节点3上的副本0
- 添加文档
- 发送添加文档的请求到某一节点,假设为节点1
- 系统计算求余得到文档应该存储的位置,假设为主分片2,则请求被转发到节点3
- 节点3存储文档到主分片2中,并发送请求到其余副本所在节点进行同步
- 查询文档
- 发送查询文档的请求到某一节点,假设为节点1
- 节点1计算求余得到文档应该存储的位置,假设为主分片2,则此时可选择节点 1 和节点 2 的副本 2 ,也可选择节点 3 的主分片 2。假设采用轮询方式选中了节点 2 ,则把请求转发到节点2
- 节点 2 把数据返回给节点 1 ,节点 1 最后返回给客户端
2. 搭建集群
前面已经创建过节点 1 ,则此时创建节点 2 即可
-
复制节点 1 ,克隆原有的虚拟机,命名为elasticsearch-2(记得修改ip和关闭防火墙)
-
修改配置文件 elasticsearch.yml
-
node.name: example_node_2 discovery.zen.ping.unicast.hosts: ["192.168.40.136:9300", "192.168.40.136:9300"]
-
-
删除节点 2 的data目录
-
启动两结点
-
删除原有索引,并创建新索引
-
DELETE /index1 PUT /index1 { "settings": { "number_of_shards": 2, "number_of_replicas": 0 } } -
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6YZu8BOQ-1666797764440)(C:\Users\wangp\AppData\Roaming\Typora\typora-user-images\image-20221026231335604.png)]](https://img-blog.csdnimg.cn/06ec40dad7ef4f7097e8f05dd129c1f0.png)
-
-
关闭节点 2
-
删除原有索引库,创建新的索引库,每个分片创建一个备份
-
DELETE /index1 PUT /index1 { "settings": { "number_of_shards": 2, "number_of_replicas": 1 } } -
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-n3mIBME6-1666797764442)(C:\Users\wangp\AppData\Roaming\Typora\typora-user-images\image-20221026231659014.png)]](https://img-blog.csdnimg.cn/1a715aa6b5284f5bb79079b302913dba.png)
-
-
启动节点 2
-
查看集群健康状态
-
GET /_cluster/health -
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JePCR3zU-1666797764443)(C:\Users\wangp\AppData\Roaming\Typora\typora-user-images\image-20221026231913908.png)]](https://img-blog.csdnimg.cn/e537f0a7ebaa4bc6b13264b7d2ee3384.png)
-
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sRPKMfTH-1666797764441)(C:\Users\wangp\AppData\Roaming\Typora\typora-user-images\image-20221026231502081.png)]](https://img-blog.csdnimg.cn/484fc7bcf2904a918dc6c96fd158eaef.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AaQfsfTu-1666797764442)(C:\Users\wangp\AppData\Roaming\Typora\typora-user-images\image-20221026231809949.png)]](https://img-blog.csdnimg.cn/a20e12b3457e413f8bcab6c0fd5cfbe3.png)















 33
33











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









