







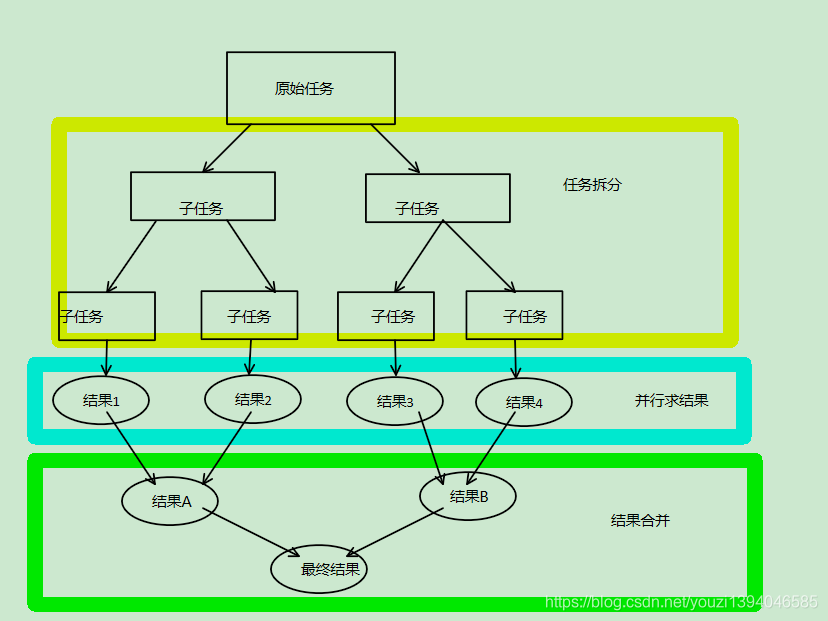
分治策略
当我们求解某些问题时,由于这些问题要处理的数据相当多,或求解过程相当复杂,使得直接求解法在时间上相当长,或者根本无法直接求出。对于这类问题,我们往往先把它分解成几个子问题,找到求出这几个子问题的解法后,再找到合适的方法,把它们组合成求整个问题的解法。如果这些子问题还较大,难以解决,可以再把它们分成几个更小的子问题,以此类推,直至可以直接求出解为止。这就是分治策略的基本思想。二分法就是一个典型的例子。
什么是Fork/Join框架 ?
Fork/Join框架是在java7之后提供的一种基于分治策略的多线程框架。与分支策略思想一样,即一个大问题可以被拆分为若干个小问题,而且小问题之间互不干扰,并且解法与原问题形式相同,最终将子问题的解合并可以得到原问题的解。
在fork/join框架中所有被拆分的任务都会进入一个任务队列中,然后由各个线程从任务队列取出对应的任务执行,由于每个任务的执行时间不一定相同,为了更加充分的利用线程,fork/join采用了一种 工作密取 的方式来处理。
工作密取: 假设有A,B,C三个线程。三个线程供一个工作队列,当A执行完成后如果B,C还没有执行完的话A会从队列尾部取出一个任务继续执行。
如何使用Fork/Join ?
使用Fork/Join框架我们首先需要了解两个类
- ForkJoinPool
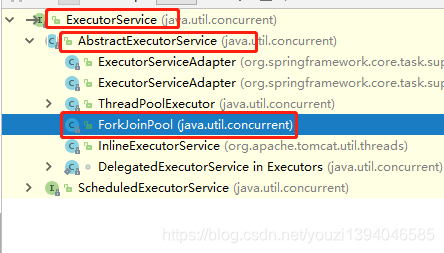
ForkJoinPool是ExecutorService的一个实现类,因此它也是一个线程池。它支持将一个任务拆分成多个“小任务”并行计算,再把多个“小任务”的结果合并成总的计算结果
ForkJoinPool构造方法可以接受一个ForkJoinTask类型的对象 - ForkJoinTask
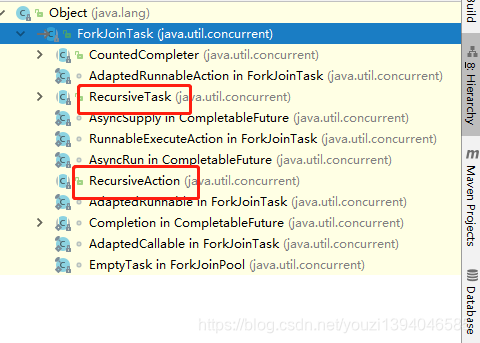
实现ForkJoinTask 的类代表这个对象任务是一个可以拆分的任务,ForkJoinTask提供了两个抽象实现类 RecusiveAction和RecusiveTask 其中RecusiveAction代表任务没有返回值,RecusiveTask 代表任务有返回值。
关系图如下:
ForkJoinPool:
ForkJoinTask:
Fork/Join实战 (从0累加到100000)
按照分治策略的原则,需要满足条件原始任务可以拆分为若干个互不干扰的子任务。
正好0-100000的累加可以拆分为若干个小一点的数据累加,如果将阈值设置为100,那么就可以拆分为1000个区间,然后将这1000个区间的和累加起来就是从0累加到100000的结果。同时每个区间的执行模式和原始任务也是一模一样的。
实现代码:
1. 创建任务类AddNum
class AddNum extends RecursiveTask<Integer> {
private int startNum;
private int endNum;
private int splitNum;
public AddNum(int startNum,int endNum,int splitNum){
this.startNum = startNum;
this.endNum = endNum;
this.splitNum = splitNum;
}
@Override
protected Integer compute() {
int sum = 0;
//判断任务是否需要拆分
if(this.endNum-this.startNum<=this.splitNum){
for(int i=this.startNum;i<= this.endNum;i++){
//模拟业务代码执行
"123,456,123,123,123,123".split(",");
sum+=i;
}
return sum;
}else{
//进行任务拆分,使用2分拆分,当然也可以不均匀拆分
int middleNum = (this.startNum+this.endNum)/2;
AddNum addLeft = new AddNum(this.startNum,middleNum,this.splitNum);
AddNum addRight = new AddNum(middleNum+1,this.endNum,this.splitNum);
addLeft.fork();//将拆分的任务加入到任务队列
addRight.fork();//将拆分的任务加入到任务队列
return addLeft.join()+addRight.join(); //执行compute方法并返回当条件满足时候的执行结果
}
}
}
2. 定义并初始化线程池
public class TestForkJoin {
private static int SPLIT_NUM = 100;
private static int END_NUM = 1000000;
private static int START_NUM = 0;
public static void main(String[] args){
long bdate = System.currentTimeMillis();
int sum = 0;
for(int i=START_NUM;i<=END_NUM;i++){
//模拟业务代码执行
"123,456,123,123,123,123".split(",");
sum+=i;
}
System.out.println("普通循环结果===>"+sum+" 耗费时间===>"+(System.currentTimeMillis()-bdate));
bdate = System.currentTimeMillis();
ForkJoinPool forkJoinPool = new ForkJoinPool();
AddNum addNum = new AddNum(START_NUM,END_NUM,SPLIT_NUM);
int result = forkJoinPool.invoke(addNum);
System.out.println("forkJoin 结果===>"+result+" 耗费时间===>"+(System.currentTimeMillis()-bdate));
}
}
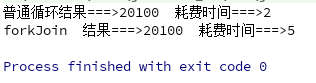
这里把普通循环和fork/join两种进行了对比
结果如下:

可见使用fork/join框架之后时间有明显的缩短
使用fork/join框架之后反而耗时更久?
在上面的代码中我把累加的数目有原来的100000改成200,
并且再次执行了一些,想象中应该是fork/join框架耗时更短。但是结果却啪啪啪打脸额,这是为什么呢?
很简单,由于fork/join是采用的多线程执行的子任务,这样就会涉及到一个CPU调度的问题,CPU进行线程调度的时候会存在一个上下文切换,而上下文切换是需要耗费一定时间的,而单线程执行是不需要进行上下文切换的,因此这时候fork/join会耗时更久一些














 701
701











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









