





4.实验
在本节中,我们首先研究深度卷积的影响,以及通过减少网络宽度而不是层数来收缩的选择。然后,我们展示了基于两个超参数(宽度因子和分辨率因子)减少网络的权衡,并将结果与一些流行模型进行比较。然后,我们将研究MobileNets应用于许多不同的应用程序。
4.1模型的选择
首先,我们展示了与用全卷积构建的模型相比,深度可分离卷积的MobileNet的结果。在表4中,我们看到,与全卷积相比,使用深度可分离卷积在ImageNet上只会减少1%的精度,但大大节省了多添加(mult-adds)和参数。
 表四
表四
接下来,我们将展示使用宽度因子的较薄模型与使用较少层的较浅模型的比较结果。为了使MobileNet更浅,去掉表1中特征大小为14 × 14 × 512的5层可分离滤波器。表5显示,在类似的计算和参数数量下,使MobileNet变薄比使它们变浅好3%。
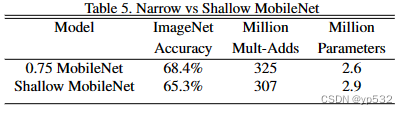 表五
表五
4.2. 模型收缩超参数
表6显示了用宽度因子α收缩MobileNet架构的精度、计算和大小权衡。精度平稳下降,直到在α = 0.25时结构变得太小。
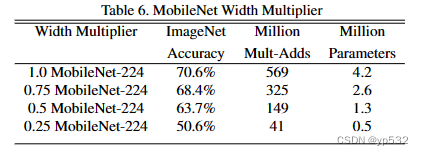 表6
表6
表7显示了通过减少输入分辨率训练MobileNets来实现不同分辨率因子的精度、计算和大小权衡。精度下降平滑跨越分辨率。
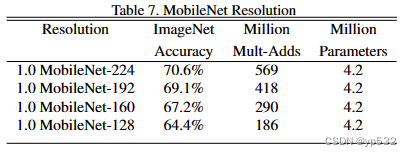 表7
表7
图4显示了由宽度因子α∈{1,0.75,0.5,0.25}和分辨率{224,192,160,128}的叉乘所得到的16个模型的ImageNet精度和计算之间的权衡。当α = 0.25时模型非常小,结果呈对数线性,且有跳跃。
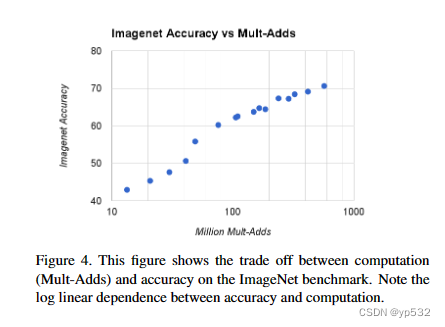 图4
图4
图5显示了由宽度因子α∈{1,0.75,0.5,0.25}和分辨率{224,192,160,128}的叉积制成的16个模型的ImageNet精度和参数数量之间的权衡。
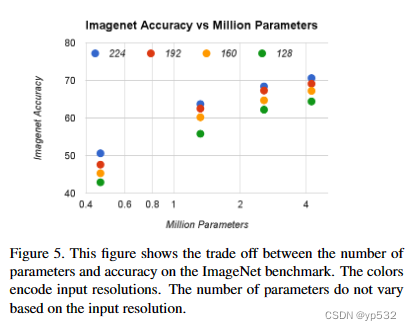 图5
图5
表8比较了完整的MobileNet与原始的GoogleNet[30](Going Deeper with Convolutions)和VGG16[27](Very deep convolutional networks for large-scale image recognition)。MobileNet几乎和VGG16一样精确,但体积是VGG16的1 / 32,计算量是VGG16的1 / 27。它比GoogleNet更精确,但体积更小,计算量少2.5倍以上。
 表8
表8
表9比较了宽度因子α = 0.5和分辨率降低为160 × 160时减小的MobileNet。减小的MobileNet比AlexNet[19](ImageNet Classification with Deep Convolutional Neural Networks)好4%,同时比AlexNet小45倍,计算量少9.4倍。在相同大小情况下,它也比Squeezenet[12](SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size)好4%,计算量少22倍。
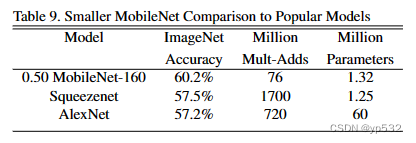 表9
表9
4.3. 细粒度识别
我们在斯坦福狗数据集[17](Novel dataset for fine-grained image categorization. In First Workshop on Fine-Grained Visual Categorization)上训练MobileNet进行细粒度识别。我们扩展了[18](The unreasonable effectiveness of noisy data for fine-grained recognition.)的方法,从网络上收集了一个比[18]更大但有噪声的训练集。我们使用噪声网络数据预训练一个细粒度的狗识别模型,然后在斯坦福狗训练集上对模型进行微调。斯坦福狗测试集的结果见表10。MobileNet几乎可以在大大减少计算和大小的情况下实现[18]的最先进结果。
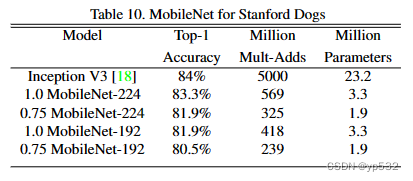 表10
表10
4.4. 大规模地理定位
PlaNet[35](PlaNet - Photo Geolocation with Convolutional Neural Networks)将确定照片在地球上的位置作为一个分类问题。 该方法将地球划分为地理单元格网格作为目标类,并通过数百万带有地理标记的照片训练卷积神经网络。PlaNet已被证明成功地本地化了大量不同类型的照片,并优于处理相同任务的Im2GPS[6,7](两个例子)。
我们在相同的数据上使用MobileNet架构重新训练PlaNet。而基于Inception V3架构的完整PlaNet模型[31](Rethinking the Inception Architecture for Computer Vision)有5200万个参数和57.4亿个多重添加。MobileNet模型只有1300万个参数,通常主体有300万个参数,最后一层有1000万个参数,还有58万个多重添加参数。如表11所示,与PlaNet相比,MobileNet版本的性能仅略有下降,尽管它要紧凑得多。此外,它仍然比Im2GPS有很大的优势。
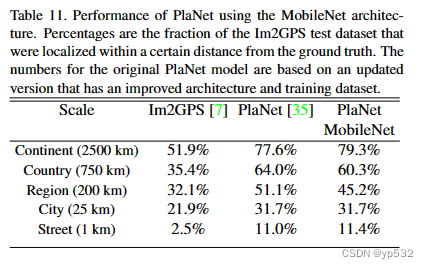 表11
表11
4.5.人脸识别
MobileNet的另一个用例是压缩具有未知或复杂训练过程的大型系统。在一个人脸属性分类任务中,我们展示了MobileNet和用于深度网络的知识转移技术蒸馏(distillation)[9](Distilling the Knowledge in a Neural Network)之间的协同关系。我们寻求减少一个具有7500万个参数和16亿个多重添加的大型人脸属性分类器。分类器在类似于YFCC100M[32]的多属性数据集上进行训练。
我们使用MobileNet架构提取一个人脸属性分类器。蒸馏[9]通过训练分类器来模拟更大模型2的输出,而不是基本真理标签,因此可以从大型(可能是无限的)未标记数据集进行训练。结合了蒸馏训练的可扩展性和MobileNet的简约参数化,最终系统不仅不需要正则化(例如权重衰减和早期停止),而且还展示了增强的性能。从表12中可以明显看出,基于MobileNet的分类器对激进的模型收缩具有弹性:它实现了与内部相似的跨属性的平均平均精度(平均AP),而只消耗了1%的多添加(multi - add)。
4.6. 物体检测
MobileNet也可以作为现代物体检测系统的有效基础网络。我们根据最近赢得2016年COCO挑战[10](Speed/accuracy trade-offs for modern convolutional object detectors)的工作,报告了针对COCO数据进行目标检测的MobileNet训练的结果。在表13中,MobileNet在fast - rcnn[23](Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks)和SSD[21](SSD: Single Shot MultiBox Detector)框架下与VGG和Inception V2[13](Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift)进行了比较。在我们的实验中,SSD以300输入分辨率(SSD 300)进行评估,fast - rcnn与300和600输入分辨率(fastrcnn 300, fast - rcnn 600)进行比较。fast - rcnn模型对每张图像评估300个RPN建议框。模型在COCO train+val上训练,排除8k minival图像并在其上求值。对于这两种框架,MobileNet在计算复杂度和模型规模都非常小的情况下,取得了与其他网络相当的结果。
4.7. 面对嵌入
FaceNet模型是目前最先进的人脸识别模型[25](FaceNet: A Unified Embedding for Face Recognition and Clustering)。它基于三元组损失构建人脸嵌入。为了构建移动FaceNet模型,我们使用蒸馏通过最小化FaceNet和MobileNet上的训练输出数据的平方差来训练。非常小的MobileNet模型的结果可以在表14中找到。
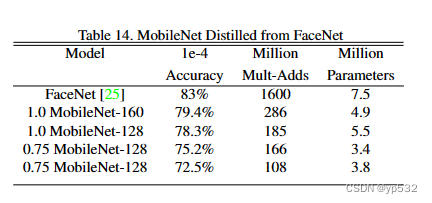 表14
表14
5. 结论
我们提出了一种新的基于深度可分离卷积的模型架构,称为MobileNets。我们调查了一些导致高效模型的重要设计决策。然后,我们演示了如何使用宽度因子和分辨率因子来构建更小、更快的MobileNets,通过权衡合理的精度来减少大小和延迟。然后,我们将不同的MobileNets与展示出更大、速度和精度特征的流行模型进行了比较。最后,我们展示了MobileNet应用于各种任务时的有效性。为了帮助MobileNets的采用和探索,我们计划在Tensor Flow中发布模型。















 174
174











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









