







摘要:
最近学习爬虫,做了个简单能实现爬取小说网站整页小说功能的DEMO
主要实现逻辑:“套娃”通过MyWebClient获取小说网站页面内所有小说的网络地址,然后通过网络地址找到每本小说的单独的网络地址,然后再通过每本小说的网络地址 找到小说章节正文的网络地址,最后通过章节地址获取到章节内容,最最后将章节内容整合起来的到整本小说。
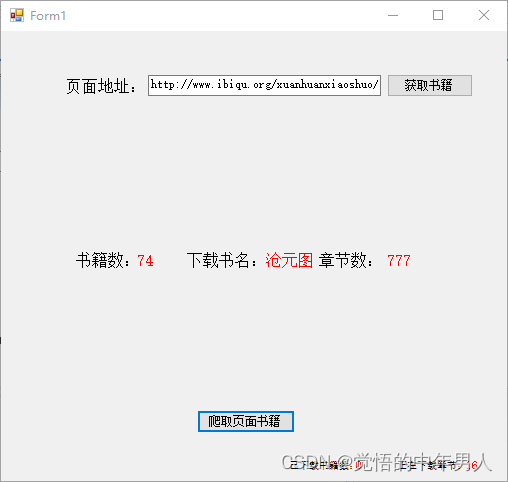
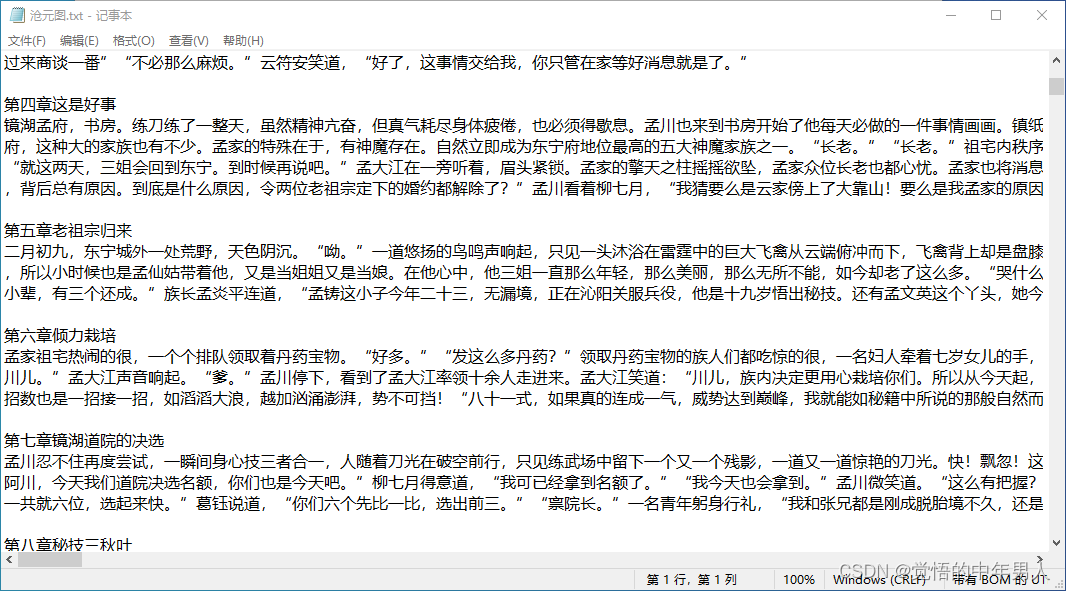
简单说说实现功能的部分程序内容:
1、使用MyWebClient对小说网站源代码进行获取
WebClient MyWebClient = new WebClient();
MyWebClient.Credentials = CredentialCache.DefaultCredentials;//获取或设置用于向Internet资源的请求进行身份验证的网络凭据
Byte[] bookPageData = MyWebClient.DownloadData("http://www.ibiqu.org/xuanhuanxiaoshuo/");
//string pageHtml_Unicode = Encoding.Unicode.GetString(pageData);
string bookPageHtml_Default = Encoding.Default.GetString(bookPageData);2、分析bookPageHtml_Default中获取到的网站页面源代码文本,从而用正则表达式获取所有小说的url、小说名
//获取当前页面所有书籍的url
Regex regex_AllBookUrl = new Regex(@"/book/\d+/");
MatchCollection bookMatch = regex_AllBookUrl.Matches(bookPageHtml_Default);
foreach (Match m in bookMatch)
{
allBookUrl.Add("http://www.ibiqu.org" + m.Value);
}
allBookUrl = allBookUrl.Distinct().ToList();//去除集合中重复的数据
ibBookCount.Text = Convert.ToString(allBookUrl.Count);3、用以上获取到的小说url,获取每本小说的章节地址url
for (int i = 0; i < allBookUrl.Count; i++)
{
UpdataUIBCN(Convert.ToString(i));
Byte[] sectionPageData = MyWebClient.DownloadData(allBookUrl[i]);
string sectionPageHtml_Default = Encoding.Default.GetString(sectionPageData);
//获取小说名
Regex regex_AllBookName = new Regex(@"<h1>[\s\S]+</h1>");
MatchCollection bookMatch = regex_AllBookName.Matches(sectionPageHtml_Default);
foreach (Match a in bookMatch)
{
bookName = GetChinese(a.Value);
UpdataUIBN(bookName);
}4、最后获取小说正文,并保存
//获取小说正文URL
Regex regex_AllsectionUrl = new Regex(@"/book/\d+/\d+.htm");
MatchCollection sectionMatch = regex_AllsectionUrl.Matches(sectionPageHtml_Default);
foreach (Match m in sectionMatch)
{
allSectionUrl.Add("http://www.ibiqu.org" + m.Value);
}
allSectionUrl = allSectionUrl.Distinct().ToList();//去除集合中重复的数据
UpdataUISC(Convert.ToString(allSectionUrl.Count));
for (int ii = 0; ii < allSectionUrl.Count; ii++)
{
UpdataUISCN(Convert.ToString(ii));
Byte[] txtPageData = MyWebClient.DownloadData(allSectionUrl[ii]);
string txtPageHtml_Default = Encoding.Default.GetString(txtPageData);
Regex regex_AllTxt_ZW = new Regex(@"[\uff01\u3002\uff1b\uff0c\uff1a\u201c\u201d\uff08\uff09\u3001\uff1f\u300a\u300b\u4e00-\u9fa5]+");
Regex regex_AllTxt_ZE = new Regex(@"[0-9\uff01\u3002\uff1b\uff0c\uff1a\u201c\u201d\uff08\uff09\u3001\uff1f\u300a\u300b\u4e00-\u9fa5]+");
Regex regex_AllTxt = new Regex(@"id=[-,.?:;'""!']{1}content[-,.?:;'""!']{1}[\s\S]+id=[-,.?:;'""!']{1}cbad[-,.?:;'""!']{1}");
Regex regex_AllSectionName = new Regex(@"<h1>[\s\S]+</h1>");
MatchCollection txtMatch = regex_AllTxt.Matches(txtPageHtml_Default);
MatchCollection sectionNameMatch = regex_AllSectionName.Matches(txtPageHtml_Default);
//ibSectionCount.Text = Convert.ToString(sectionNameMatch.Count);
string sectiontxt = "";
string sectionName = "";
foreach (Match q in sectionNameMatch)
{
sectionName = GetChinese(q.Value);
}
foreach (Match mm in txtMatch)
{
MatchCollection txtMatch_ZW = regex_AllTxt_ZW.Matches(mm.Value);
foreach (Match tt in txtMatch_ZW)
{
sectiontxt = sectiontxt + tt;
}
}
StreamWriter sw = new StreamWriter("C:\\Users\\User\\Desktop\\文本\\" + bookName + ".txt", true, Encoding.UTF8);
sw.WriteLine("\r\n" + sectionName + "\r\n" + sectiontxt);
sw.Flush();
sw.Close();
}结语:作为一名初级程序员,可能用到的技术太落后,希望有大佬能在评论里再指点指点,谢谢。















 1546
1546











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









