







虚拟机创建
背景
1、centos 7 系统文件
链接: 阿里镜像
2、VMware
关键步骤
文件为你在阿里镜像上下载的文件

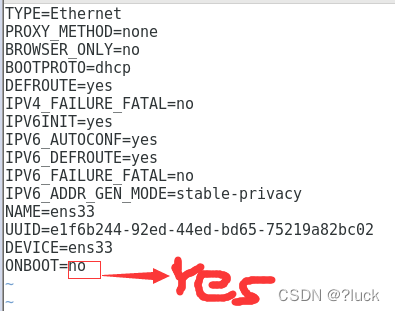
问题
1)发现 ens33 没有 inet 这个属性,那么就没法通过IP地址连接虚拟机。
1、root 用户下执行
vi /etc/sysconfig/network-scripts/ifcfg-ens33
2、改为 yes 后重启网卡
sudo service network restart
搭建ES集群
背景
1、新建虚拟机三台(centos 7)
2、ES 版本 7.6.1
3、Kibana 7.6.1
4、IK 7.6.1
步骤
1、创建分组
groupadd elasticsearch
补充:
组就像一个社团,用户就像成员,一般linux下创建用户默认是自动给该用户创建一个组的,除非是指定组
2、创建用户 -- es不能用root启动
useradd yzhp
passwd “你自己的密码,设置好立即会让你修改-- 密码太简单不行”
3、将用户移到制定分组下
usermod -G elasticsearch yzhp
4、文件归属变更,多用户情况下防止篡改
chown -R yzhp /usr/local/es/ 表示es下所有文件归“yzhp”用户拥有,其他用户无法更改(root例外)范围看你自己;
5、给用户设置权限
visudo
找到
root ALL=(ALL) ALL
加其一:
1)yzhp ALL=(ALL) ALL : 这种在以root身份(命令前加sudo)执行命令时要输密码
2)yzhp ALL=(ALL) NOPASSWD:ALL :这样就不用输密码了
------------上用root身份执行
-------------------------------------------------------------------------------------
------------下用yzhp身份执行
6、切换用户
su yzhp
7、解压文件
cd /usr/local/es
tar -zvxf elasticsearch-7.6.1-linux-x86_64.tar.gz
mv elasticsearch-7.6.1 es7
8、创建放节点数据文件夹 && 放日志文件夹
mkdir /usr/local/es/es7/data
mkdir /usr/local/es/es7/log
9、修改elasticsearch.yml 文件 ···· 最初文件内容都是被注释的,可以直接删除,
vim elasticsearch.yml
修改内容:
cluster.name: yzhp-es #集群名称
node.name: es-m #节点名称
path.logs: /usr/local/es/es7/log #运行日志存放位子
path.data: /usr/local/es/es7/data #子节点数据存放点
network.host: 0.0.0.0 #都可以访问
http.port: 9200 #端口号
transport.port: 9300 #节点间访问端口号
node.data: true #此个节点可以作为数据节点
node.master: true #此节点可以作为主节点,当主节点挂了被设置为true的节点去竞争
discovery.seed_hosts: ["服务器:9300","服务器IP:9300","服务器IP:9300"]
cluster.initial_master_nodes: ["es-m","es-s2","es-s1"]
bootstrap.system_call_filter: false
bootstrap.memory_lock: false
http.cors.enabled: true
http.cors.allow-origin: "*"
备注:
1)额外配置信息可以去这个老哥那看看
https://blog.csdn.net/pbymw8iwm/article/details/84067374
2)节点分工不同
主节点:
主资格节点的主要职责是和集群操作相关的内容,如创建或删除索引,跟踪哪些节点是群集的一部分,并决定哪些分片
分配给相关的节点。稳定的主节点对集群的健康是非常重要的,默认情况下任何一个集群中的节点都有可能被选为主节
点,索引数据和搜索查询等操作会占用大量的cpu,内存,io资源,为了确保一个集群的稳定,分离主节点和数据节点
是一个比较好的选择。
数据节点:
数据节点主要是存储索引数据的节点,主要对文档进行增删改查操作,聚合操作等。数据节点对cpu,内存,io要求较
高,在优化的时候需要监控数据节点的状态,当资源不够的时候,需要在集群中添加新的节点。
10、设置JVM堆大小,
vim /usr/local/es/es7/config/jvm.options
-Xms2g
-Xmx2g
-----------------到这基本信息完成,接下来修改部分内容避免启动时报错----------------------------------------------------------------
11、打开文件的最大数限制
1)原因:
ES因为需要大量的创建索引文件,需要大量的打开系统的文件,所以我们需要解除linux系统当中打开文件最大数
目的限制,不然ES启动就会抛错。
2)错误信息:
max file descriptors [4096] for elasticsearch process likely too low, increase to at least [65536]
3)解决:
sudo vi /etc/security/limits.conf
加
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
注意:“*”不要去掉了
12、增加启动线程数限制
1)错误信息:
max number of threads [1024] for user [es] likely too low, increase to at least [4096]
2)解决:
Centos6
sudo vi /etc/security/limits.d/90-nproc.conf
Centos7
sudo vi /etc/security/limits.d/20-nproc.conf
改
* soft nproc 1024#修改为
* soft nproc 4096
3)备注:
修改后最好重新启动一下虚拟机 ···· 可以等后面改完了一起启动
13、调大虚拟内存
1)错误信息:
max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least [262144]
2)解决
sudo vi /etc/sysctl.conf
加
vm.max_map_count=262144
保存后执行下面命令才能生效
sysctl -p
3)备注
按照给的顺序改完了重启一下虚拟机,es的内容基本就改完了可以试着启动
-------------------------启动ES---------------------------------------------------------------
14、启动命令
1)后台运行命令:
1.1)nohup /usr/local/es/es7/bin/elasticsearch 2>&1 &
若报:nohup: 忽略输入并把输出追加到"nohup.out" 使用下面的命令----虽然我也不完全了解为什么,知道的可以留言
1.1)nohup /usr/local/es/es7/bin/elasticsearch >/dev/null 2>&1 &
1.2)/usr/local/es/es7/bin/elasticsearch -d
2)直接运行:
2.1)/usr/local/es/es7/bin/elasticsearch
15、关闭防火墙
systemctl status firewalld 查看防火墙状态
systemctl stop firewalld 停止当前防火墙
systemctl enable firewalld 永久关闭防火墙
16、运行Kibana
nohup /usr/local/es/kibana7/bin/kibana >/dev/null 2>&1 &
-----------------------------------三台虚拟机上按顺序执行一遍------------------------------------------------
最后安装Kibana
安装ik分词器
过两天在完善
展示
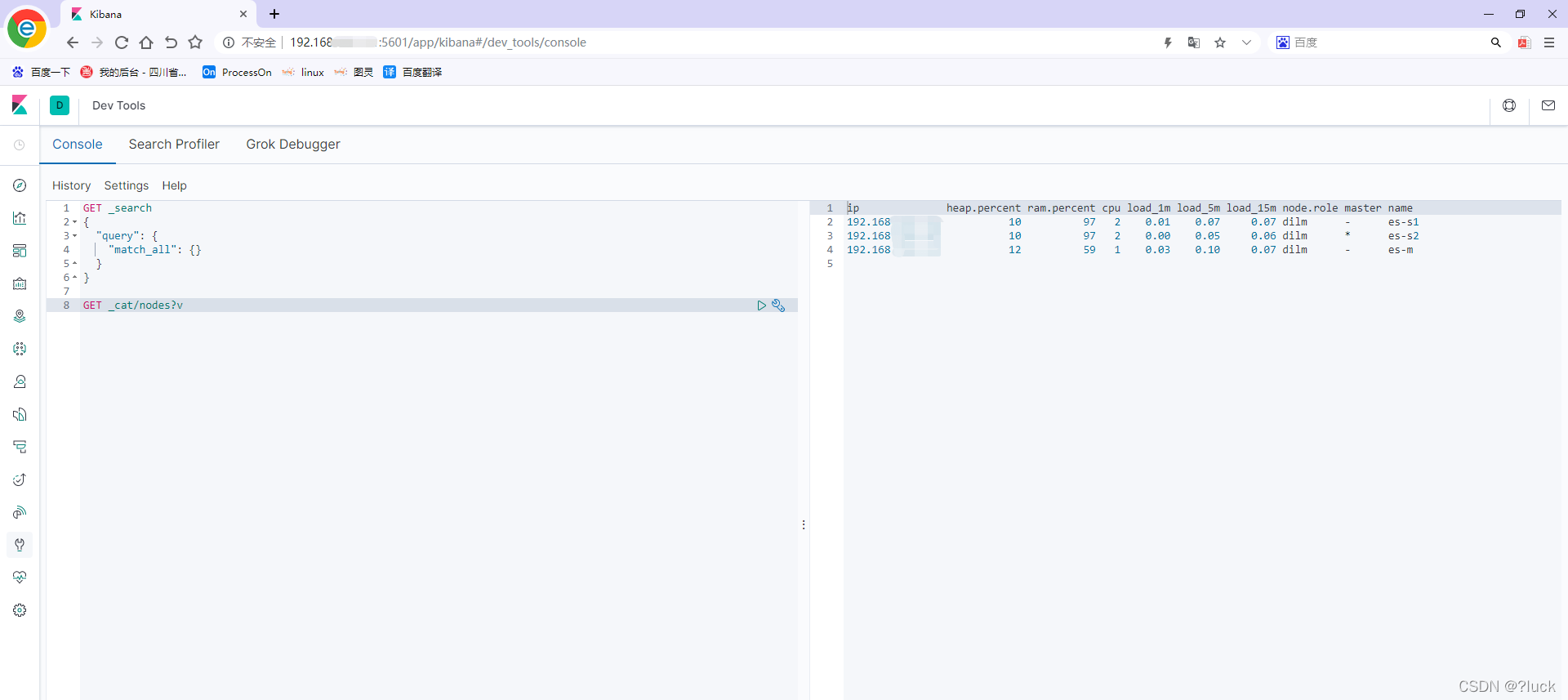
Kibana
安装
问题
1、please set xpack.security.encryptionKey in kibana.yml
kibana.yml 加上这两句
xpack.security.encryptionKey: "something_at_least_32_characters"
xpack.reporting.encryptionKey: "something_at_least_32_characters"
语法
1、请求方式
| 请求方式 | 描述 |
| PUT | 创建、修改、新增 |
| POST | 新增 |
| GET | 查询 |
| DELETE | 删除 |
2、应用
2.1、查询
全量查询
格式: GET /索引名称/类型/_search
举例: GET /yzhp1/_doc/_search
ID查询
1、单个ID
格式: GET /索引名称/类型/ID
举例: GET /yzhp1/_doc/1
2、多ID
GET /yzh1/_doc/_mget
{
"ids": [
"1",
"2"
]
}
范围查询
格式: GET /索引名称/类型/_search?q=**"字段名"**[1 TO 2]
举例: GET /yzhp1/_doc/_search?q=age[1 TO 2]
分页查询
格式: GET /索引名称/类型/_search?q=age[1 TO 2]&from=0&size=1
举例: GET /yzhp1/_doc/_search?q=age[1 TO 2]&from=0&size=1
查询个别字段
格式: GET /索引名称/类型/_search?_source=字段,字段
举例: GET /yzhp1/_doc/_search?_source=name,age
排序
格式: GET /索引名称/类型/_search?sort=字段 desc
举例: GET /yzhp1/_doc/_search?sort=age:desc
归纳
| 符号 | 描述 |
|---|---|
| :<= | 小于等于 |
| :> | 大于 |
| [A TO B] | 大于等于A且小于等于B |
| from=A&size=B | 于A且小于等于B |
| _source=A,B | 只查询A和B字段 |
| sort=A:desc | 根据字段A降序排列 |














 2768
2768











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









