







前言
网络爬虫是大数据时代收集数据的一种有效手段,合理合法的运用技术手段获取网络数据,实现数据的再利用也是程序员的一项重要技能。本节我们使用java环境下的jsoup实现网络数据的爬取,主要是图片数据的异步爬取,并实现网络图片的下载及图片的预览功能,预览功能使用具有丰富功能的v-viewer实现。

正文
- 引入爬虫pom工具包
<dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpclient</artifactId> <version>4.5.6</version> </dependency> <dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.14.2</version> </dependency>
- 爬虫案例后端控制层controller
package com.yundi.atp.platform.module.test.controller; import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper; import com.baomidou.mybatisplus.extension.plugins.pagination.Page; import com.yundi.atp.platform.common.Result; import com.yundi.atp.platform.module.test.entity.SpiderData; import com.yundi.atp.platform.module.test.service.SpiderDataService; import io.swagger.annotations.Api; import org.apache.commons.lang3.StringUtils; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.bind.annotation.*; import sun.misc.BASE64Encoder; import java.io.File; import java.io.FileInputStream; import java.io.IOException; import java.util.concurrent.CompletableFuture; import java.util.concurrent.ThreadPoolExecutor; /** * <p> * 前端控制器 * </p> * * @author yanp * @since 2021-09-10 */ @Api(tags = {"爬虫抓取案例API"}) @RestController @RequestMapping("/test/spiderData") public class SpiderDataController { @Autowired private SpiderDataService spiderDataService; @Autowired private ThreadPoolExecutor threadPoolExecutor; @GetMapping(value = "startSpiderData") public Result startSpiderData() { CompletableFuture.runAsync(() -> { spiderDataService.startSpiderData(); }, threadPoolExecutor); return Result.success(); } @PostMapping(value = "listPage") public Result listPage(@RequestBody SpiderData spiderData) { Page page = spiderDataService.page(spiderData.getPage(), new QueryWrapper<SpiderData>().like(StringUtils.isNotBlank(spiderData.getSrcImageName()), "src_image_name", spiderData.getSrcImageName())); return Result.success(page); } @GetMapping(value = "download/{id}") public Result download(@PathVariable(value = "id") String id) { spiderDataService.download(id); return Result.success(); } @GetMapping(value = "batchDownload") public Result batchDownload() { spiderDataService.batchDownload(); return Result.success(); } @GetMapping(value = "preview/{id}") public Result preview(@PathVariable(value = "id") String id) throws IOException { SpiderData spiderData = spiderDataService.getById(id); File file = new File(spiderData.getStoreAddress()); FileInputStream fileInputStream = new FileInputStream(file); int size = fileInputStream.available(); byte[] bytes = new byte[size]; fileInputStream.read(bytes); fileInputStream.close(); BASE64Encoder encoder = new BASE64Encoder(); return Result.success(encoder.encode(bytes)); } }
- 爬虫案例后端业务层
package com.yundi.atp.platform.module.test.service.impl; import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper; import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl; import com.yundi.atp.platform.module.test.entity.SpiderData; import com.yundi.atp.platform.module.test.mapper.SpiderDataMapper; import com.yundi.atp.platform.module.test.service.SpiderDataService; import com.yundi.atp.platform.spider.MzituImageSpider; import lombok.extern.slf4j.Slf4j; import org.jsoup.Connection; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; import org.springframework.stereotype.Service; import java.io.IOException; import java.util.List; /** * <p> * 服务实现类 * </p> * * @author yanp * @since 2021-09-10 */ @Slf4j @Service public class SpiderDataServiceImpl extends ServiceImpl<SpiderDataMapper, SpiderData> implements SpiderDataService { @Override public void startSpiderData() { try { //1.创建连接 String url = "https://www.mzitu.com"; Connection conn = Jsoup.connect(url).timeout(50000); conn.header("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3100.0 Safari/537.36"); conn.header("referer", url); //2.获取栏目图片连接 Document document = conn.get(); Element element = document.getElementById("menu-nav"); Elements elements = element.getElementsByTag("a"); List<String> linkList = elements.eachAttr("abs:href"); linkList.remove(0); linkList.forEach(it -> { Connection connect = Jsoup.connect(it).timeout(50000); connect.header("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3100.0 Safari/537.36"); connect.header("referer", it); try { Document doc = connect.get(); //3.获取栏目图片最大分页页数 Elements docElements = doc.getElementsByClass("nav-links"); Element docElement = docElements.get(0); Elements tag = docElement.getElementsByTag("a"); List<String> tagValues = tag.eachText(); tagValues.remove(tagValues.size() - 1); Integer maxPage = Integer.parseInt(tagValues.get(tagValues.size() - 1)); log.info("--------------------开始解析下载图片---------------------------"); String imageUrl = it.substring(0, it.length() - 1); String imageCategory = imageUrl.substring(imageUrl.lastIndexOf("/") + 1); //4.开始爬取图片 for (int i = 1; i <= maxPage; i++) { String imgUrl = it + "page/" + i + "/"; Connection imgConn = Jsoup.connect(imgUrl).timeout(50000); imgConn.header("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3100.0 Safari/537.36"); imgConn.header("referer", imgUrl); try { Document imgDocument = imgConn.get(); Element pins = imgDocument.getElementById("pins"); Elements imgTag = pins.getElementsByTag("img"); for (Element ele : imgTag) { SpiderData spiderData = new SpiderData(); spiderData.setSrcLink(imgUrl); spiderData.setSrcImageName(ele.attr("alt")); spiderData.setSrcImageAddress(ele.attr("data-original")); spiderData.setSrcImageCategory(imageCategory); this.save(spiderData); } } catch (IOException ioException) { log.error("获取资源失败:" + ioException); } Thread.sleep(5000); } } catch (IOException | InterruptedException ioException) { log.error("获取资源失败:" + ioException); } }); } catch (IOException ioException) { log.error("获取资源失败:" + ioException); } } @Override public void download(String id) { SpiderData spiderData = this.getById(id); String path = MzituImageSpider.downloadImage(spiderData.getSrcImageAddress()); if (path != null) { spiderData.setStoreAddress(path); spiderData.setStatus(true); this.updateById(spiderData); } } @Override public void batchDownload() { List<SpiderData> list = this.list(new QueryWrapper<SpiderData>().eq("status", 0)); for (SpiderData spiderData : list) { String path = MzituImageSpider.downloadImage(spiderData.getSrcImageAddress()); if (path != null) { spiderData.setStoreAddress(path); spiderData.setStatus(true); this.updateById(spiderData); } } } }
- 爬虫案例前端安装v-viewer预览组件
命令:npm i v-viewer -s
- 爬虫案例前端main.js中引入v-viewer
import Vue from 'vue'; import ElementUI from 'element-ui'; import 'element-ui/lib/theme-chalk/index.css'; import router from '@/router'; import {http} from '@/axios/index'; import qs from 'qs'; import '@/util/derective' import App from '@/App.vue'; import Print from 'vue-print-nb' import VideoPlayer from 'vue-video-player' require('video.js/dist/video-js.css') require('vue-video-player/src/custom-theme.css') import VueQuillEditor from 'vue-quill-editor' // require styles import 'quill/dist/quill.core.css' import 'quill/dist/quill.snow.css' import 'quill/dist/quill.bubble.css' import mavonEditor from 'mavon-editor' import 'mavon-editor/dist/css/index.css' import TinymceVueH from 'tinymce-vue-h' import Viewer from 'v-viewer' import 'viewerjs/dist/viewer.css' Vue.use(Viewer); Viewer.setDefaults({ Options: { "inline": true, "button": true, "navbar": true, "title": true, "toolbar": true, "tooltip": true, "movable": true, "zoomable": true, "rotatable": true, "scalable": true, "transition": true, "fullscreen": true, "keyboard": true, "url": "data-source" } }); Vue.use(TinymceVueH); // use Vue.use(mavonEditor); Vue.use(VueQuillEditor, /* { default global options } */); Vue.use(VideoPlayer); Vue.use(Print); Vue.use(ElementUI); Vue.prototype.$http = http; Vue.prototype.$qs = qs; Vue.config.productionTip = false; new Vue({ router, render: h => h(App), }).$mount('#app')
- 爬虫案例前端Spider.vue
<template> <div class="container"> <div class="title"> <span>爬虫案例(以https://www.mzitu.com网站为例)</span> <el-divider direction="vertical"></el-divider> <router-link to="home"> <span style="font-size: 18px;">退出</span> </router-link> </div> <el-divider>Test Staring</el-divider> <el-form :inline="true" :model="query"> <el-form-item> <el-input v-model="query.srcImageName" placeholder="源图片名称" clearable></el-input> </el-form-item> <el-form-item> <el-button type="primary" @click="startSpider">启动爬虫</el-button> </el-form-item> <el-form-item> <el-button type="success" @click="search">查询</el-button> </el-form-item> <el-form-item> <el-button type="success" @click="batchDownload">批量下载</el-button> </el-form-item> </el-form> <el-table :data="data" border stripe v-loading="loading" element-loading-text="数据加载中..."> <el-table-column prop="id" label="ID"> </el-table-column> <el-table-column prop="srcLink" label="源网址"> </el-table-column> <el-table-column prop="srcImageName" label="源图片名称"> </el-table-column> <el-table-column prop="srcImageAddress" label="源图片地址"> </el-table-column> <el-table-column prop="srcImageCategory" label="源图片分类"> </el-table-column> <el-table-column label="状态"> <template slot-scope="scope"> <el-tag size="medium" v-show="scope.row.status" type="success" effect="dark">已下载</el-tag> <el-tag size="medium" v-show="!scope.row.status" type="warning" effect="dark">未下载</el-tag> </template> </el-table-column> <el-table-column prop="storeAddress" label="存储地址"> </el-table-column> <el-table-column label="操作" align="left"> <template slot-scope="scope"> <el-button type="text" @click="download(scope.row)" v-if="!scope.row.storeAddress">下载</el-button> <el-button type="text" @click="preview(scope.row)" v-if="scope.row.storeAddress">预览</el-button> </template> </el-table-column> </el-table> <el-pagination layout="total,sizes,prev,pager,next,jumper" @size-change="handlerSizeChange" @current-change="handlerCurrentChange" :current-page="query.page.current" :page-sizes="query.page.sizes" :page-size="query.page.size" :total="query.page.total" class="page" background> </el-pagination> <el-dialog :visible.sync="show"> <div style="text-align: center;"> <viewer> <img :src="imgSrc"> </viewer> </div> </el-dialog> </div> </template> <script> export default { name: "Spider", data() { return { data: [], loading: false, query: { page: { total: 0, current: 1, size: 10, pageSizes: [10, 50, 100, 500], } }, show: false, imgSrc: '', } }, created() { this.listPage(); }, methods: { startSpider() { this.$http.get('/test/spiderData/startSpiderData').then(res => { if (res.data.code === 1) { this.$message.success("爬取结束!"); this.search(); } else { this.$message.warning(res.data.msg); } }).catch(error => { this.$message.error(error); }); }, search() { this.query.page.current = 1; this.listPage(); }, listPage() { this.$http.post('/test/spiderData/listPage', this.query).then(res => { if (res.data.code === 1) { this.data = res.data.data.records; this.query.page.total = res.data.data.total; } else { this.$message.warning(res.data.msg); } }).catch(error => { this.$message.error(error); }); }, download(data) { this.$http.get('/test/spiderData/download/' + data.id).then(res => { if (res.data.code === 1) { this.$message.success("下载完成!"); this.search(); } else { this.$message.warning(res.data.msg); } }).catch(error => { this.$message.error(error); }); }, batchDownload() { this.$http.get('/test/spiderData/batchDownload').then(res => { if (res.data.code === 1) { this.$message.success("下载完成!"); this.search(); } else { this.$message.warning(res.data.msg); } }).catch(error => { this.$message.error(error); }); }, preview(data) { this.$http.get('/test/spiderData/preview/' + data.id).then(res => { if (res.data.code === 1) { this.show = true; this.imgSrc = "data:image/png;base64," + res.data.data; } else { this.$message.warning(res.data.msg); } }).catch(error => { this.$message.error(error); }); }, handlerSizeChange(data) { this.query.page.size = data; this.listPage(); }, handlerCurrentChange(data) { this.query.page.current = data; this.listPage(); } } } </script> <style scoped lang="scss"> .container { padding: 10px; a { text-decoration: none; } .title { font-size: 20px; font-weight: bold; } .page { float: right; margin-top: 20px; } } </style>
- 验证效果



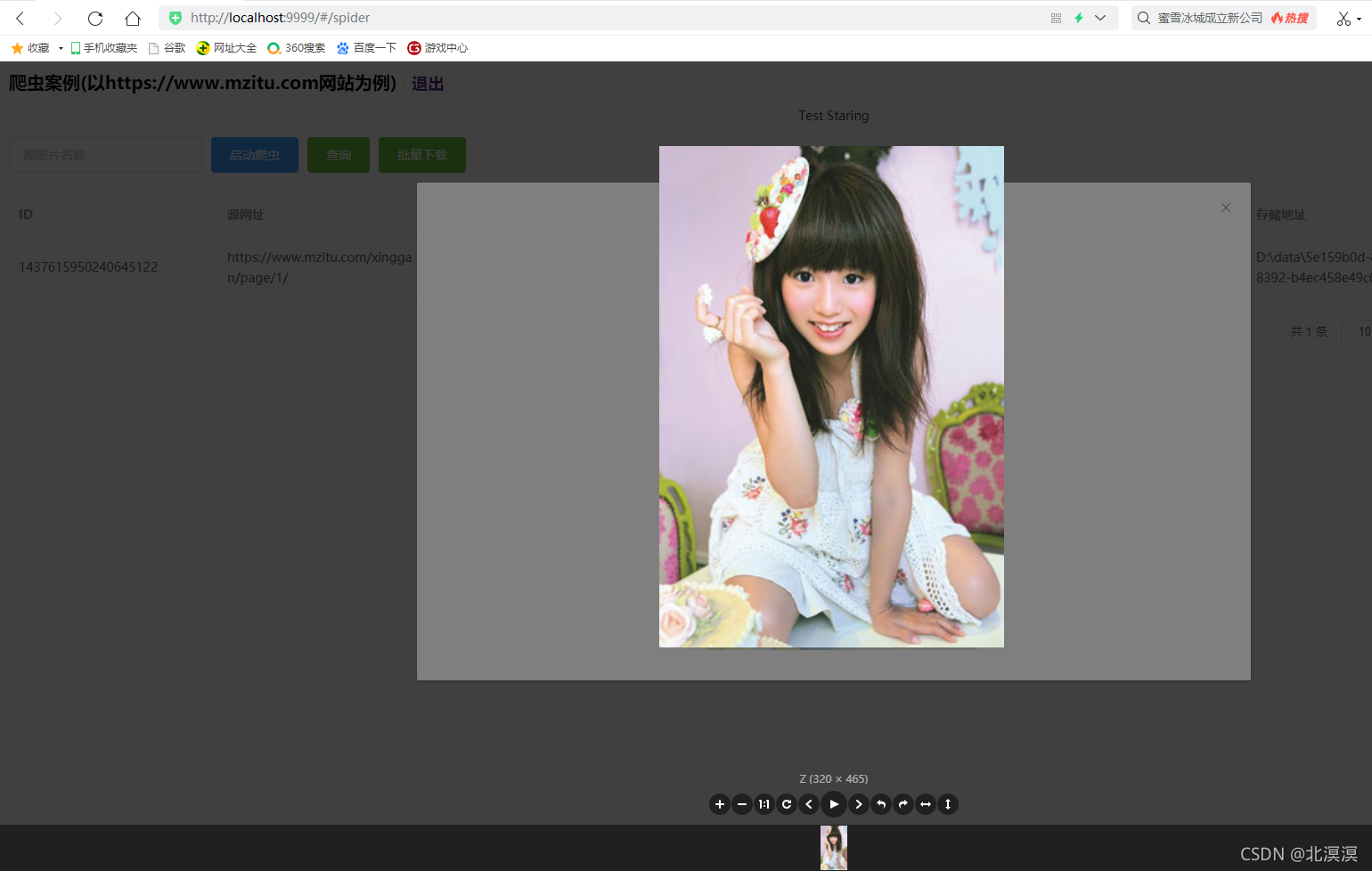
结语
关于java环境下的jsoup实现网络数据图片的爬取及网络图片的下载和图片的预览功到这里就结束了,下期见。。。
















 7089
7089











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











