







1.插入排序
(1)直接插入排序
思想: 利用有序表的插入操作进行排序
有序表的插入: 将一个记录插入到已排好序的有序表中,从而得到一个新的有序表。
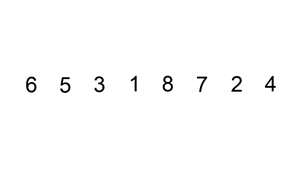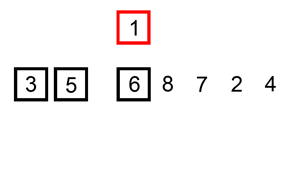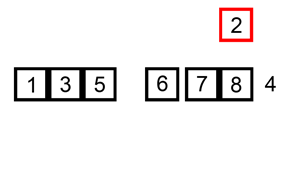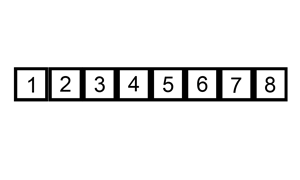
动画取自:http://www.cricode.com/3212.html
void insertsort(ElemType R[],int n)
//待排序元素用一个数组R表示,数组有n个元素
{
for ( int i=1; i<n; i++) //i表示插入次数,共进行n-1次插入
{
ElemType temp=R[i]; //把待排序元素赋给temp
int j=i-1;
while ((j>=0)&& (temp<R[j]))
{ R[j+1]=R[j]; j--;
} // 顺序比较和移动
R[j+1]=temp;
}
}
效率分析:
- 直接插入排序的时间复杂度为O( n2 )。
- 直接插入算法的元素移动是顺序的,所以该方法是稳定的。
(2)折半插入排序
由于直接插入排序算法利用了有序表的插入操作,故顺序查找操作可以替换为折半(二分法)查找操作。
void BinaryInsertSort(ElemType R[],int n)
{
for(int i = 1; i < n; i++) //共进行n-1次插入
{
int left = 0,right = i-1;
ElemType temp = R[i];
while(left <= right)
{
int middle = (left + right)/2; //取中点
if (temp < R[middle]) right = middle-1; //取左区间
else left = middle + 1; //取右区间
}
for(int j = i-1;j >= left;j--)
R[j+1] = R[j]; //元素后移空出插入位
R[left] = temp;
}
}
效率分析:
- 二分插入算法与直接插入算法相比,需要的辅助空间与直接插入排序基本一致;
- 时间上,二分插入的比较次数比直接插入查找的最坏情况好,最好的情况坏,两种方法的元素的移动次数相同,因此二分插入排序的时间复杂度仍为O( n2 )。
- 二分插入算法与直接插入算法的元素移动一样是顺序的,因此该方法也是稳定的。
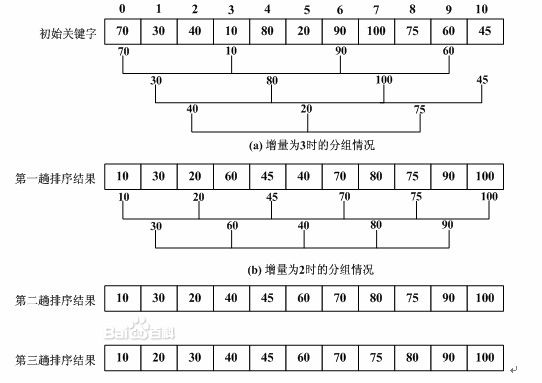
(3)希尔(shell)排序
思想:
先将待排序记录序列分割成为若干子序列分别进行直接插入排序;待整个序列中的记录基本有序后,再全体进行一次直接插入排序。
template <class T >
void ShellSort (T Vector[], int arrSize ) {
T temp;
int gap = arrSize / 2; //gap是子序列间隔
while ( gap != 0 ) { //循环,直到gap为零
for ( int i = gap; i < arrSize; i++) {
temp = Vector[i]; //直接插入排序
for ( int j = i; j >= gap; j -= gap )
if ( temp < Vector[j-gap] )
Vector[j] = Vector[j-gap];
else break;
Vector[j] = temp;
}
gap = ( int ) ( gap / 2 );
}
}
效率分析:
- 希尔排序的时间复杂性在O( nlog2n )和O( n2 )之间,大致为O( n1.3 )。
- 希尔排序是不稳定的排序算法。
交换排序
(1)冒泡排序
思想: 通过不断比较相邻元素的大小,进行交换来实现排序。
优点:
每趟结束时,不仅能挤出一个最大值到最后面位置(或者最小值到最前面位置),还能同时部分理顺其他元素;一旦下趟没有交换发生,还可以提前结束排序。
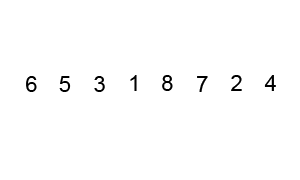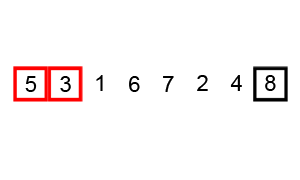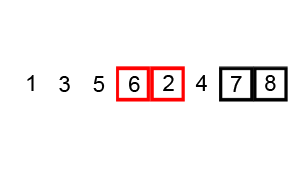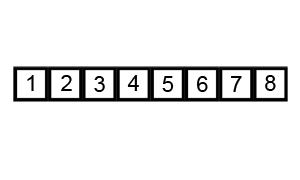
动画取自:http://images.cnitblog.com/blog/333003/201311/25223707-da62d63797924c5aba0579f9b46bbbab.gif
void Bubblesort(ElemType R[],int n)
{
int flag = 1; //当flag为0则停止排序
for(int i = 1; i < n; i++)
{ //i表示趟数,最多n-1趟
flag = 0;//开始时元素未交换
for (int j = n - 1; j >= i; j--)
if(R[j] < R[j-1])
{ //发生逆序
ElemType t = R[j];
R[j] = R[j-1];
R[j-1] = t;
flag = 1;
} //交换,并标记发生了交换
if(flag == 0) return;
}
}
效率分析:
- 冒泡排序算法的时间复杂度为O( n2 )。由于其中的元素移动较多,所以属于内排序中速度较慢的一种。
- 因为冒泡排序算法只进行元素间的顺序移动,所以是一个稳定的算法。
(2)快速排序
冒泡排序的一种改进算法。
算法思想:
- 取序列的一个元素作为轴,利用这个轴把序列分成三段:左段,中段(轴)和右段, 使左段中各元素都小于等于轴,右段中各元素都大于等于轴。(这个过程称做对序列分割或划分)。
- 左段和右段的元素可以独立排序, 将排好序的三段合并到一起即可。
- 上面的过程可以递归地执行,直到每段的长度为1。
快排序算法是个递归地对序列进行分割的过程,递归终止的条件是最终序列长度为1。
快排序—分割过程:
- 快排序是一个分治算法。
- 快排序的关键过程是每次递归的分割过程。
- 分割问题描述:对一个序列,取它的一个元素作为轴,把所有小于轴的元素放在它的左边,大于它的元素放在它的右边。
- 分割算法:
①用临时变量对轴备份;
②取两个指针low和high,它们的初始值就是序列的两端下标,在整个过程中保证low不大于high;
③移动两个指针,首先从high所指的位置向左搜索,找到第一个小于轴的元素, 把这个元素放在low的位置,再从low开始向右,找到第一个大于轴的元素,把它放在high的位置。
④重复上述过程,直到low=high;
⑤把轴放在low所指的位置。
这样所有大于轴的元素被放在右边,所有小于轴的元素被放在左边。

49为轴,经过一轮分割后,所有小于49的元素被放在左边,所有大于49的元素被放在右边。
迭代:
int Partition(T Array[], int low, int high){
T pivot = Array[low];
while(low < high){
while(low < high && Array[high] >= pivot)
high --;
Array[low] = Array[high];
while(low < high && Array[low] <= pivot)
low++;
Array[high] = Array[low];
}
Array[low] = pivot;
return low;
}
void QuickSort(T Array[], int low, int high){
int PivotLocation;
if(low < high){
PivotLocation = Partition(Array, low, high);
QuickSort(Array, low, PivotLocation-1);
QuickSort(Array, PivotLocation+1, high);
}
}
效率分析:
- 快速排序的最好时间复杂度应为O( nlog2n ),最坏时间复杂度为O( n2 )。
- 快速排序所占用的辅助空间为栈的深度,故最好的空间复杂度为O( log2n ),最坏的空间复杂度为O(n)。
- 快速排序是一种不稳定的排序方法。
选择排序
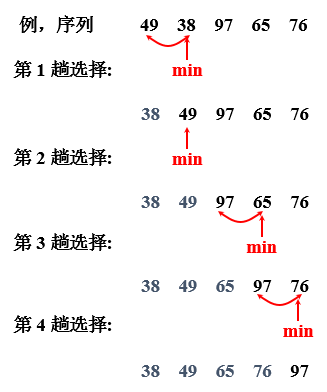
(1)直接选择排序
思想:
- 第 1 趟选择:从 1—n 个记录中选择关键字最小的记录,并和第 1 个记录交换。
- 第 2 趟选择:从 2—n 个记录中选择关键字最小的记录,并和第 2 个记录交换。
- …
- 第 n-1 趟选择:从 n-1—n 个记录中选择关键字最小的记录,并和第 n-1 个记录交换。
template <class T>
void SelectSort ( T Vector[], int CurrentSize) {
for ( int i = 0; i < CurrentSize-1; i++ ) {
int k = i; //选择具有最小排序码的对象
for ( int j = i+1; j < CurrentSize; j++)
if ( Vector[j] < Vector[k] )
k = j; //当前具最小排序码的对象
if ( k != i ) //对换到第 i 个位置
Swap ( Vector[i], Vector[k] );
}
}
效率分析:
- 时间效率: O( n2 )——虽移动次数较少,但比较次数仍多。
- 空间效率:O(1)——没有附加单元(仅用到1个temp)。
- 算法的稳定性:不稳定。
(2)树形选择排序
又称锦标赛排序,是一种按照锦标赛的思想进行选择排序的方法。
例,序列 49 38 65 97 76 13 27 50
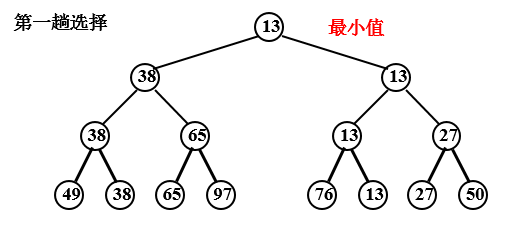
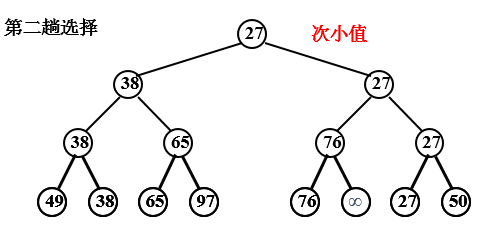
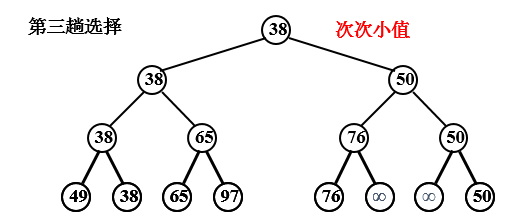
缺点:需要大量辅助存储空间。
(3)堆排序
思想:
- 将序列构造成一棵完全二叉树 ;
- 把这棵普通的完全二叉树改造成堆,便可获取最小值 ;
- 输出最小值 ;
- 删除根结点,继续改造剩余树成堆,便可获取次小值 ;
- 输出次小值 ;
- 重复改造,输出次次小值、次次次小值,直至所有结点均输出,便得到一个排序 。
效率分析:
- 时间效率:O( nlog2n )。因为整个排序过程中需要调用n-1次堆顶点的调整,而每次堆排序算法本身耗时为 log2n ;
- 空间效率:O(1)。仅在交换记录时用到一个临时变量temp。
- 稳定性: 不稳定。
- 优点:对小文件效果不明显,但对大文件有效。
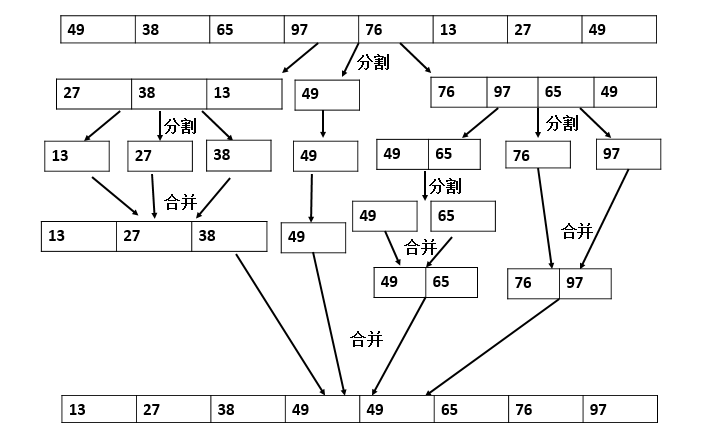
归并排序
归并—合并两个有序的序列:
假设有两个已排序好的序列A(长度为n1),B(长度为n2),将它们合并为一个有序的序列C(长度为n=n1+n2);
方法很简单:把A,B两个序列的最小元素进行比较,把其中较小的元素作为C的第一个元素;在A,B剩余的元素中继续挑最小的元素进行比较,确定C的第二个元素,依次类推,就可以完成对A和B的归并, 其复杂度为O(n)。
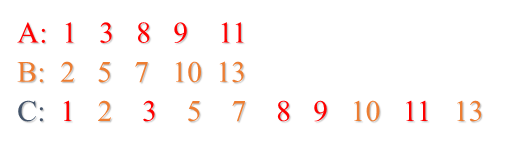
//归并算法
void merge(T A[], int Alen, T B[], int Blen, T C[]){
int i=0,j=0,k=0;
while(i < Alen && j < Blen){
if(A[i] < B[j])
C[k++] = A[i++];
else
C[k++] = B[j++];
}
while(i < Alen)
C[k++] = A[i++];
while(j < Blen)
C[k++] = B[j++];
}
归并排序:
- 归并排序是一个分治递归算法。
- 递归基础:若序列只有一个元素,则它是有序的,不执行任何操作。
- 递归步骤:
①先把序列划分成长度基本相等的两个序列;
②对每个子序列递归排序;
③把排好序的子序列归并成最后的结果。

void MergeSort(int A[], int l, int h)
{
if(l == h)
return;
int m = (l+h)/2;
MergeSort(A, l, m);
MergeSort(A, m+1, h);
Merge(A, l, m, h); //注意这里的归并是对一个序列的两段进行归并,需要对上面的算法进行修改,思想是一致的
}
以下为完整代码:
#include<stdio.h>
// 一个递归函数
void mergesort(int *num,int start,int end);
// 这个函数用来将两个排好序的数组进行合并
void merge(int *num,int start,int middle,int end);
int main()
{
// 测试数组
int num[10]= {12,54,23,67,86,45,97,32,14,65};
int i;
// 排序之前
printf("Before sorting:\n");
for (i=0; i<10; i++)
{
printf("%3d",num[i]);
}
printf("\n");
// 进行合并排序
mergesort(num,0,9);
printf("After sorting:\n");
// 排序之后
for (i=0; i<10; i++)
{
printf("%3d",num[i]);
}
printf("\n");
return 0;
}
//这个函数用来将问题细分
void mergesort(int *num,int start,int end)
{
int middle;
if(start<end)
{
middle=(start+end)/2;
// 归并的基本思想
// 排左边
mergesort(num,start,middle);
// 排右边
mergesort(num,middle+1,end);
// 合并
merge(num,start,middle,end);
}
}
//这个函数用于将两个已排好序的子序列合并
void merge(int *num,int start,int middle,int end)
{
int n1=middle-start+1;
int n2=end-middle;
// 动态分配内存,声明两个数组容纳左右两边的数组
int *L=new int[n1+1];
int *R=new int[n2+1];
int i,j=0,k;
//将新建的两个数组赋值
for (i=0; i<n1; i++)
{
*(L+i)=*(num+start+i);
}
// 哨兵元素
*(L+n1)=1000000;
for (i=0; i<n2; i++)
{
*(R+i)=*(num+middle+i+1);
}
*(R+n2)=1000000;
i=0;
// 进行合并
for (k=start; k<=end; k++)
{
if(L[i]<=R[j])
{
num[k]=L[i];
i++;
}
else
{
num[k]=R[j];
j++;
}
}
delete [] L;
delete [] R;
}效率分析:
- 最坏情况:归并排序是一个递归算法,所以算法最坏情况的复杂度为 θ(nlogn) 。
- 算法需要 θ(n) 的辅助空间。因为需要一个与原始序列同样大小的辅助序列。这是此算法的缺点。
- 稳定性:稳定。
其他策略:
上面归并排序每次迭代时将原序列分割为两个基本等长的序列,称为二路归并排序。也可以分割成其他等分,如3,4等等。
评论:
尽管归并排序最坏情况的比较次数比快速排序少,但它需要更多的元素移动,因此,它在实用中不一定比快速排序快。
以上均为以比较为基础的排序算法:具有O( nlgn )复杂度的比较排序算法在渐进意义下是最优的算法。
分配排序
(1)桶式排序
思想:
事先知道序列中的记录都位于某个小区间段[0,m)内将具有相同值的记录都分配到同一个桶中,然后依次按照编号从桶中取出记录,组成一个有序序列。
假如待排序列K= {49、38 、35、 97 、 76、 73 、 27、 49 }。这些数据全部在1—100之间。因此我们定制10个桶,然后确定映射函数f(k)=k/10。则第一个关键字49将定位到第4个桶中(49/10=4)。依次将所有关键字全部堆入桶中,并在每个非空的桶中进行快速排序后得到如下图所示:
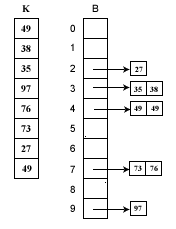
算法:
#include <stdio.h>
// Count数组大小
#define MAXNUM 100
// 功能:桶式排序
// 输入:待排序数组 arrayForSort[]
// 待排序数组大小 arraySize
// 待排序数组元素上界 maxItem;数组中的元素都落在[0, maxItem]区间
// 输出:void
void BucketSort(int arrayForSort[], int arraySize, int maxItem)
{
int Count[MAXNUM];
// 置空
for (int i = 0; i <= maxItem; ++i)
{
Count[i] = 0;
}
// 遍历待排序数组
for (int i = 0; i < arraySize; ++i)
{
++Count[arrayForSort[i]];
}
// 桶排序输出
// 也可以存储在数组中,然后返回数组
for (int i = 0; i <= maxItem; ++i)
{
for (int j = 1; j <= Count[i]; ++j)//一个桶中有多个数,依次输出
{
printf("%3d", i);
}
}
printf("\n");
}
void main()
{
// 测试
int a[] = {2, 5, 6, 12, 4, 8, 8, 6, 7, 8, 8, 10, 7, 6, 0, 1};
BucketSort(a, sizeof(a) / sizeof(a[0]), 12);
} 效率分析:
- 数组长度为n, 所有记录区间[0,m)上。
- 时间代价:
①统计计数时: Θ (n+m)
②输出有序序列时循环n次
③总的时间代价为 Θ (n+m)
④适用于m相对于n很小的情况 - 空间代价:m个计数器,长度为n的临时数组, Θ (m+n)
- 稳定。
(2)基数排序
基数排序就是借助于“分配”和“收集”两种操作实现对单逻辑关键字的排序。
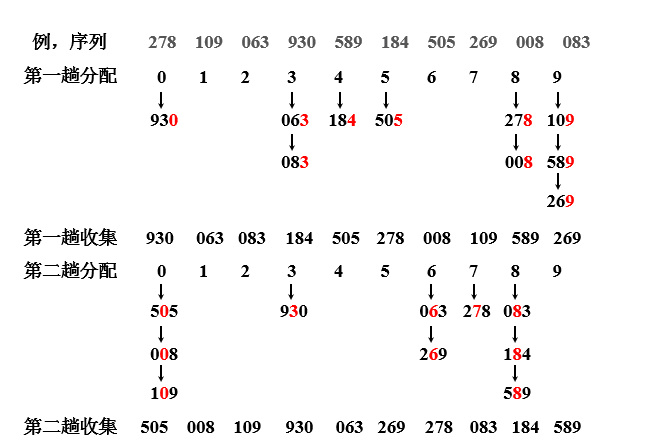
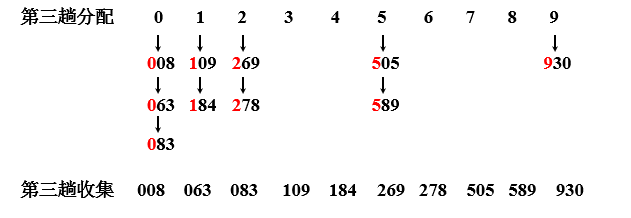
算法实现:
/********************************************************
*函数名称:GetNumInPos
*参数说明:num 一个整形数据
* pos 表示要获得的整形的第pos位数据
*说明: 找到num的从低到高的第pos位的数据
*********************************************************/
int GetNumInPos(int num,int pos)
{
int temp = 1;
for (int i = 0; i < pos - 1; i++)
temp *= 10;
return (num / temp) % 10;
}
/********************************************************
*函数名称:RadixSort
*参数说明:pDataArray 无序数组;
* iDataNum为无序数据个数
*说明: 基数排序
*********************************************************/
#define RADIX_10 10 //整形排序
#define KEYNUM_10 10 //关键字个数,这里为整形位数
void RadixSort(int* pDataArray, int iDataNum)
{
int *radixArrays[RADIX_10]; //分别为0~9的序列空间
for (int i = 0; i < 10; i++)
{
radixArrays[i] = (int *)malloc(sizeof(int) * (iDataNum + 1));
radixArrays[i][0] = 0; //index为0处记录这组数据的个数
}
for (int pos = 1; pos <= KEYNUM_10; pos++) //从个位开始到第10位
{
for (int i = 0; i < iDataNum; i++) //分配过程
{
int num = GetNumInPos(pDataArray[i], pos);
int index = ++radixArrays[num][0];
radixArrays[num][index] = pDataArray[i];
}
for (int i = 0, j =0; i < RADIX_10; i++) //收集
{
for (int k = 1; k <= radixArrays[i][0]; k++)
pDataArray[j++] = radixArrays[i][k];
radixArrays[i][0] = 0; //复位
}
}
} 效率分析:
- 特点:不用比较和移动,改用分配和收集,时间效率高!
- 时间复杂度为:O (mn)。
- 空间复杂度:O(n)。
- 稳定性:稳定(一直前后有序)。
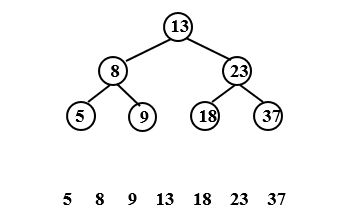
二叉排序树排序
中序遍历可实现二叉搜索树结点的有序化。
总结
(1)各种排序方法性能比较
| 排序方法 | 最好时间 | 平均时间 | 最坏时间 | 辅助空间 | 稳定性 |
|---|---|---|---|---|---|
| 直接插入排序 | O(n) | O(n2) | O(n2) | O(1) | 稳定 |
| 希尔排序 | O(n1.3) | O(1) | 不稳定 | ||
| 直接选择排序 | O(n2) | O(n2) | O(n2) | O(1) | 不稳定 |
| 堆排序 | O(nlog2n) | O(nlog2n) | O(nlog2n) | O(1) | 不稳定 |
| 冒泡排序 | O(n) | O(n2) | O(n2) | O(1) | 稳定 |
| 快速排序 | O(nlog2n) | O(nlog2n) | O(n2) | O(log2n) | 不稳定 |
| 归并排序 | O(nlog2n) | O(nlog2n) | O(nlog2n) | O(n) | 稳定 |
| 基数排序(基于链式队列) | O(mn) | O(mn) | O(mn) | O(n) | 稳定 |
| 基数排序(基于顺序队列) | O(mn) | O(mn) | O(mn) | O(mn) | 稳定 |
(2)各种内排序方法的选择
- 从时间复杂度选择:
对元素个数较多的排序,可以选快速排序、堆排序、归并排序,元素个数较少时,可以选简单的排序方法。 - 从空间复杂度选择:
尽量选空间复杂度为 O(1) 的排序方法,其次选空间复杂度为 O(log2n) 的快速排序方法,最后才选空间复杂度为 O(n) 二路归并排序的排序方法。 - 一般选择规则:
①当待排序元素的个数n较大,排序码分布是随机,而对稳定性不做要求时,则采用快速排序为宜。
②当待排序元素的个数n大,内存空间允许,且要求排序稳定时,则采用二路归并排序为宜。
③当待排序元素的个数n大,排序码分布可能会出现正序或逆序的情形,且对稳定性不做要求时,则采用堆排序或二路归并排序为宜。
④当待排序元素的个数n小,元素基本有序或分布较随机,且要求稳定时,则采用直接插入排序为宜。
⑤当待排序元素的个数n小,对稳定性不做要求时,则采用直接选择排序为宜,若排序码不接近逆序,也可以采用直接插入排序。冒泡排序一般很少采用。















 3938
3938











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}