






目录
智能助手学习
1.将excel表格某一列全填充为0
import pandas as pd
# 读取Excel文件
df = pd.read_excel('文件名.xlsx',sheet_name='Sheet1')# 假设需要填充的列为'Column_Name'
df['H'] = df['H'].fillna(0)# 保存到新的Excel文件,或者覆盖原文件
with pd.ExcelWriter('附件2-1.xlsx') as writer:
df.to_excel(writer, sheet_name='Sheet1-1', index=False)
2.查找替换
这段代码首先使用pd.merge函数来匹配df_target和df_source中的数据,基于C列(目标数据)和A列(源数据)进行匹配,并且只保留目标数据的所有行(使用how='left')。接着,使用apply函数和lambda表达式来更新H列的值,如果匹配到源数据的D列有值,则替换,否则保持原H列值。最后,删除辅助列并保存到新的Excel文件中。
这种方法避免了循环操作,对于大型数据集而言,效率会有显著提升。
import pandas as pd
# 读取第一个Excel文件(源数据)
df_source = pd.read_excel('附件1.xlsx')# 读取第二个Excel文件(目标数据),并指定了工作表名称Sheet1
df_target = pd.read_excel('附件2.xlsx', sheet_name='Sheet1')# 假设我们基于'A'列在源数据中匹配目标数据的'C'列,并希望用源数据的'D'列值替换目标数据的'H'列值
# 使用merge函数进行匹配,注意这里我们左连接目标数据(df_target),确保所有目标数据的行都被保留
df_merged = pd.merge(df_target, df_source[['A', 'D']], left_on='C', right_on='A', how='left')# 使用合并后的DataFrame来更新'H'列,如果源数据的'D'列有值,则使用该值,否则保持原值
df_merged['H'] = df_merged.apply(lambda x: x['D'] if pd.notnull(x['D']) else x['H'], axis=1)# 删除辅助列(来自源数据的列),这里假设我们不再需要它们
df_final = df_merged.drop(columns=['A', 'D'])# 保存修改后的数据到新的Excel文件
df_final.to_excel('附件2-1.xlsx', index=False)
3.表格间自然连接
import pandas as pd
# 读取Excel文件
df1 = pd.read_excel('path_to_file1.xlsx', sheet_name='Sheet1')
df2 = pd.read_excel('path_to_file2.xlsx', sheet_name='Sheet1')# 进行自然连接
# 假设我们想要根据'ID'列进行连接
result = pd.merge(df1, df2, on='ID', how='outer')#ID列用于标识每行数据;how='outer':自然连接(外连接)# 查看结果
print(result)# 将结果保存到新的Excel文件
result.to_excel('path_to_output_file.xlsx', index=False)#不包含索引
4.时间序列处理
转换为日期时间格式
df['SaleDateTime'] = pd.to_datetime(df['SaleDateTime'])
将日期时间列设置为索引
df.set_index('SaleDateTime', inplace=True)
4.One-hot编码
import pandas as pd
# 创建一个包含分类变量的DataFrame
df = pd.DataFrame({
'Color': ['Red', 'Green', 'Blue', 'Green', 'Red'],
'Value': [10, 20, 30, 40, 50]
})# 进行One-hot编码
one_hot_encoded_df = pd.get_dummies(df, columns=['Color'])# 查看结果
print(one_hot_encoded_df)

对Color列进行One-hot编码后,Color列被转换为三个新的列:Color_Red、Color_Green和Color_Blue。每个颜色类别都转换为一个二进制列,如果行属于该颜色类别,则对应列的值为1,否则为0。
注意:
1.分类变量不宜过多,维度灾难
2.One-hot编码不能出现缺失值
3.One-hot编码可能会引入多重共线性问题,特别是当分类变量的类别是有序的时候
4.One-hot编码、标签编码(Label Encoding)
5.数据聚合
数据聚合是数据分析中的一项基本技术,它可以帮助我们理解数据的不同方面,如不同组的销售情况,或者随时间变化的趋势等
import pandas as pd
# 创建示例数据
data = {
'Group': ['A', 'A', 'B', 'B', 'C', 'C', 'C'],
'Sales': [100, 200, 300, 400, 500, 600, 700],
'Year': [2020, 2020, 2021, 2021, 2020, 2021, 2021]
}
df = pd.DataFrame(data)# 按'Group'分组并聚合
grouped = df.groupby('Group')
total_sales = grouped['Sales'].sum()
average_sales = grouped['Sales'].mean()
#结合多个聚合函数
#summary = grouped['Sales'].agg(['sum', 'mean'])# 分组和聚合多个列
# grouped_multiple = df.groupby(['Group', 'Year'])
# total_sales_by_group_year = grouped_multiple['Sales'].sum()
# 打印结果
print("Total Sales by Group:\n", total_sales)
print("Average Sales by Group:\n", average_sales)
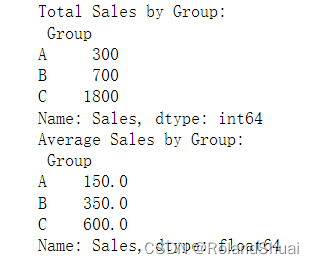
自定义聚合函数,在.agg()中使用:先定义,再聚合
参数:column指列名,aggfunc指聚合函数
def custom_agg(x):
return x.mean() * 2 # 举例:将均值乘以2
result = df.groupby('Group').agg(
CustomSales=pd.NamedAgg(column='Sales', aggfunc=custom_agg)
)
6.Fisher精确性检验
是一种用于分析计数数据的统计方法,特别是当样本量较小且假设条件不满足进行卡方检验时。
此检验通常用于2x2列联表(contingency table),以确定两个分类变量之间是否存在显著的关联性。
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.stats import fisher_exact# 创建一个2x2列联表的numpy数组
contingency_table = np.array([[10, 20], [30, 40]])# 进行Fisher精确性检验
oddsratio, p_value = fisher_exact(contingency_table)
print(f"Odds Ratio: {oddsratio:.4f}, P-value: {p_value:.4f}")# 使用Seaborn的heatmap函数可视化列联表
sns.heatmap(contingency_table, annot=True, fmt="d", cmap="Blues",
xticklabels=['Yes', 'No'], yticklabels=['Category A', 'Category B'])
plt.title('Contingency Table for Category A vs Category B\nP-value: {p_value:.4f}'.format(p_value=p_value))# 显示图表
plt.show()
7.删除含有#N/A缺失值的行
#删除含有缺失值#N/A的行
import pandas as pd
df = pd.read_excel('附件1.xlsx', sheet_name="Sheet1")
df_cleaned = df[df.notna().all(axis=1)]
new_sheet_name = 'Sheet2'
with pd.ExcelWriter('附件1.xlsx', engine='openpyxl', mode='a', if_sheet_exists='replace') as writer:
# 写入新工作表,如果工作表已存在,将会追加数据
df_cleaned.to_excel(writer, sheet_name=new_sheet_name, index=True)
8.计算相关系数矩阵
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
# 直接输入数据,这里使用numpy数组
data = np.array([[9.26,25.53,17.06,9.43], [14,19.8,9,16], [143.64,525.294,162.54,166.88],[0.329,0.702,0.445,0.207]])# 将numpy数组转换为pandas DataFrame
df = pd.DataFrame(data, columns=['西兰花', '紫白菜(1)', '青梗散花', '紫白菜(2)'])# 计算相关系数矩阵
corr_matrix = df.corr()
# 设置seaborn的全局字体,确保它支持中文
sns.set(font='SimHei') # 'SimHei' 是一种支持中文的字体
# 定义自定义颜色映射的列表
custom_colors = ['#46788e', '#78b7c9', '#f6e093', '#97b319']
# 使用Seaborn绘制热力图
plt.figure(figsize=(8, 6)) # 可以根据需要调整图形大小
sns.heatmap(corr_matrix, annot=True, fmt=".2f", cmap=custom_colors, square=True, cbar_kws={"shrink": .5})
plt.title('花菜类相关系数热力图')
# 显示图形
plt.savefig('heatmap.png', dpi=300, bbox_inches='tight', transparent=True)
plt.show()
数据处理各具体步骤
python可实现代码
# #1.将表格2和表格3进行自然连接
# import pandas as pd
#
# # 读取Excel文件
# df1 = pd.read_excel(r"附件2.xlsx", sheet_name='Sheet1')
# df2 = pd.read_excel(r"附件3.xlsx", sheet_name='Sheet1')
#
# # 进行自然连接
# # 假设我们想要根据'ID'列进行连接
# result = pd.merge(df1, df2, on=['销售日期','单品编码'], how='outer')#ID列用于标识每行数据;how='outer':自然连接(外连接)
#
# # 查看结果
# #print(result)
#
# # 将结果保存到新的Excel文件
# result.to_excel(r"2-3.xlsx", index=True)#包含索引
#
# #时间序列处理
# import pandas as pd
#
# # 读取Excel文件
# df = pd.read_excel(r"2-3.xlsx", sheet_name='Sheet1')
#
# # 转换为日期时间格式
# df['销售日期'] = pd.to_datetime(df['销售日期'])
#
# # 假设 '扫码销售时间' 也是一列,并且你想将其与 '销售日期' 一起作为复合索引
# # 确保 '扫码销售时间' 列存在并且是字符串格式,如果不是,则需要进行转换
# df.set_index(['销售日期', '扫码销售时间'], inplace=True)
#
# # 对分类列进行One-hot编码
# df1 = pd.get_dummies(df, columns=['销售类型', '是否打折销售'])
#
# # 指定新工作表的名称,确保它与原工作表不同
# new_sheet_name = 'Sheet2'
#
# # 使用ExcelWriter以追加模式写入同一个文件的新工作表
# # if_sheet_exists='replace'(替换)
# # 或 if_sheet_exists='overlay'(追加)
# with pd.ExcelWriter(r"2-3.xlsx", engine='openpyxl', mode='a', if_sheet_exists='replace') as writer:
# # 写入新工作表,如果工作表已存在,将会追加数据
# df1.to_excel(writer, sheet_name=new_sheet_name, index=True)
#
# #Fisher精确性检验
# import numpy as np
# import matplotlib.pyplot as plt
# from matplotlib.font_manager import FontProperties
# import seaborn as sns
# from scipy.stats import fisher_exact
#
# # 创建一个2x2列联表的numpy数组
# contingency_table = np.array([[, 830680], [4, 47362]])
#
# # 进行Fisher精确性检验:Odds Ratio: 6.5141, P-value: 0.0000
# oddsratio, p_value = fisher_exact(contingency_table)
# print(f"Odds Ratio: {oddsratio:.4f}, P-value: {p_value:.4f}")
#
# # 设置seaborn的全局字体,确保它支持中文
# sns.set(font='SimHei') # 'SimHei' 是一种支持中文的字体
# # 定义自定义颜色映射的列表
# custom_colors = ['#46788e', '#78b7c9', '#f6e093', '#97b319']
# # 使用Seaborn的heatmap函数可视化列联表
# ax = sns.heatmap(contingency_table, annot=True, fmt="d", cmap=custom_colors,
# xticklabels=['退货', '不退货'], yticklabels=['不打折', '打折'])
# # 设置热力图背景为无色(透明)
# ax.set_facecolor('none')
# plt.title('Fisher精确性检验\nP-value: {p_value:.4f}'.format(p_value=p_value))
# #保存图像
# plt.savefig('contingency_table_heatmap.png', dpi=300, bbox_inches='tight', transparent=True)
# # 显示图表
# plt.show()
# #删除含有缺失值#N/A的行
# import pandas as pd
# df = pd.read_excel(r"附件1.xlsx", sheet_name="Sheet1")
# df_cleaned = df[df.notna().all(axis=1)]
# new_sheet_name = 'Sheet2'
# with pd.ExcelWriter(r"附件1.xlsx", engine='openpyxl', mode='a', if_sheet_exists='replace') as writer:
# # 写入新工作表,如果工作表已存在,将会追加数据
# df_cleaned.to_excel(writer, sheet_name=new_sheet_name, index=True)
# #计算相关系数矩阵
# import numpy as np
# import seaborn as sns
# import matplotlib.pyplot as plt
# import pandas as pd
# # 直接输入数据,这里使用numpy数组
# data = np.array([[9.26,25.53,17.06,9.43], [14,19.8,9,16], [143.64,525.294,162.54,166.88],[0.329,0.702,0.445,0.207]])
#
# # 将numpy数组转换为pandas DataFrame
# df = pd.DataFrame(data, columns=['西兰花', '紫白菜(1)', '青梗散花', '紫白菜(2)'])
#
# # 计算相关系数矩阵
# corr_matrix = df.corr()
# # 设置seaborn的全局字体,确保它支持中文
# sns.set(font='SimHei') # 'SimHei' 是一种支持中文的字体
# # 定义自定义颜色映射的列表
# custom_colors = ['#46788e', '#78b7c9', '#f6e093', '#97b319']
# # 使用Seaborn绘制热力图
# plt.figure(figsize=(8, 6)) # 可以根据需要调整图形大小
# sns.heatmap(corr_matrix, annot=True, fmt=".2f", cmap=custom_colors, square=True, cbar_kws={"shrink": .5})
# plt.title('花菜类相关系数热力图')
# # 显示图形
# plt.savefig('heatmap.png', dpi=300, bbox_inches='tight', transparent=True)
# plt.show()














 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









