







本文由readlecture.cn转录总结专注于音、视频转录与总结,2小时视频,5分钟阅读,加速内容学习与传播。
大纲
-
介绍
-
个人背景
-
首席科学官和Hugging Face联合创始人
-
创建Transformers和Datasets库
-
从开源转向开放科学
-
著作《Natural Language Processing with Transformers》
-
-
Hugging Face概述
-
开源平台
-
模型和数据集的托管
-
用户和组织的使用情况
-
提供的开源库和工具
-
-
-
构建大型语言模型(LLM)的现状
-
数据准备
-
数据的重要性
-
数据准备的步骤
-
语言过滤
-
质量过滤
-
去重
-
数据洗牌和分词
-
-
数据质量评估
-
-
模型训练
-
训练流程
-
数据准备
-
高效训练技术
-
评估
-
微调
-
部署
-
-
训练技术和工具
-
Datatrove
-
Nanotron
-
LightEval
-
TRL
-
Text Generation Inference
-
-
-
模型架构和并行化
-
模型架构
-
混合专家系统(MoE)
-
Mamba(非Transformer架构)
-
-
并行化技术
-
数据并行
-
张量并行
-
流水线并行
-
序列并行
-
-
-
模型部署和推理
-
量化
-
推理优化
-
模型共享和评估
-
-
-
结论
-
总结和未来展望
-
内容总结
一句话总结
本文详细介绍了2024年构建大型语言模型的现状,包括数据准备、模型训练、架构设计、并行化技术以及模型部署和推理的最新进展。
观点与结论
-
开源模型在成本和透明度方面具有优势,但性能通常低于闭源模型。
-
数据质量对模型性能至关重要,需要仔细准备和评估。
-
并行化技术是提高模型训练效率的关键,包括数据并行、张量并行、流水线并行和序列并行。
-
模型部署时需要考虑量化和推理优化,以提高效率和降低成本。
-
开放科学和共享模型是推动AI领域发展的重要途径。
自问自答
-
问:Hugging Face的主要功能是什么?
-
答:Hugging Face是一个开源平台,主要用于托管模型和数据集,提供各种开源库和工具,支持模型开发、部署和研究。
-
-
问:为什么数据准备对大型语言模型如此重要?
-
答:数据质量直接影响模型性能,因此需要仔细准备和评估数据,包括语言过滤、质量过滤、去重和分词等步骤。
-
-
问:有哪些并行化技术可以提高模型训练效率?
-
答:常用的并行化技术包括数据并行、张量并行、流水线并行和序列并行,这些技术可以有效提高训练效率和利用GPU资源。
-
-
问:模型部署时需要考虑哪些因素?
-
答:模型部署时需要考虑量化、推理优化和模型共享,以提高效率、降低成本并促进模型的广泛应用。
-
-
问:开放科学在AI领域中的作用是什么?
-
答:开放科学通过共享方法和知识,促进AI领域的透明度和合作,有助于推动整个领域的发展和进步。
-
关键词标签
-
大型语言模型
-
数据准备
-
模型训练
-
并行化技术
-
模型部署
-
开源平台
-
开放科学
适合阅读人群
-
AI研究人员
-
数据科学家
-
软件工程师
-
技术爱好者
-
学术界人士
术语解释
-
开源模型:指源代码公开可用的模型,用户可以自由修改和分发。
-
闭源模型:指源代码不公开的模型,用户无法访问其内部实现。
-
并行化技术:指在多个计算资源上同时执行任务的技术,以提高效率和性能。
-
量化:指将模型参数从高精度转换为低精度的过程,以减少模型大小和提高推理速度。
-
混合专家系统(MoE):一种模型架构,通过路由机制将输入分配给不同的专家网络。
-
Mamba:一种非Transformer的模型架构,具有更快的推理速度。
-
Flash Attention:一种高效的注意力计算方法,避免生成完整的注意力矩阵。
-
Direct Preference Optimization (DPO):一种简化的人类反馈强化学习方法,减少模型复杂性。
视频来源
bilibili: Lecture 8 大模型实战指导_哔哩哔哩_bilibili
讲座回顾

-
演示文稿内容:总结2024年构建大型语言模型的现状。
-
内容涵盖:当前位置、地位及公开了解的信息。
-
贡献团队:中国团队和清华大学团队。
-
目的:尽管观点可能不新鲜,但汇集信息仍具趣味性。
这是几周前我准备的一个演示文稿,总结了2024年构建大型语言模型的现状,包括我们目前的位置、我们的地位以及我们所公开了解的内容。这个演示文稿有很大一部分是由中国团队和清华大学团队贡献的。祝贺他们,尽管其中许多观点对你们中的一些人来说可能并不新鲜,但将它们汇集在一起或许仍然颇具趣味。

-
作者是Hugging Face的首席科学官兼联合创始人。
-
创建了Transformers和Datasets库。
-
从开源转向开放科学,关注AI领域的方法论和知识分享。
-
观察到AI研究变得更为封闭,对此表示遗憾。
-
撰写了《基于Transformers的自然语言处理》一书,但承认可能存在个人偏见。
在某个角落,我想简单介绍一下自己。我是Hugging Face的首席科学官兼联合创始人。我在Hugging Face创建了Transformers和Datasets库。最近,我逐渐从开源转向更专注于开放科学,旨在分享人工智能领域的方法论和知识。这一转变的部分原因在于,我注意到与过去相比,现在的AI研究似乎变得更加封闭,我认为这颇为遗憾。此外,我还撰写了一本名为《基于Transformers的自然语言处理》的书籍。不过,我得承认,由于是我自己写的,我可能会有所偏颇。

我写了这篇文章,不过确实,今天天气很好。所以我会快速介绍一下什么是 Hugging Face,然后。2024年如何构建大型语言模型?


-
Hugging Face 是一个基于开源理念的平台。
-
开源模型与闭源模型在安全性、成本和性能方面有显著差异。
-
开源模型提供更高的透明度和控制权,允许用户进行定制和微调。
-
开源模型成本较低,延迟小,但性能通常低于闭源模型。
-
开源模型正在迅速改进,一些中国模型如 Yiyi、DeepSeek 和 MiniCPM 正在追赶闭源模型。
那么,Hugging Face 是什么?Hugging Face 是一个围绕开源理念构建的平台。在这里,我将简要讨论开源模型与闭源模型之间的区别。我承认自己对开源模型有些偏爱,但在使用闭源模型时也有许多有趣之处值得考虑。
在安全性方面,你可以将模型托管在自己的数据中心或笔记本电脑上。将模型保存在本地设备(如笔记本电脑)上是有益的。你对开源模型有更大的控制权,因为它们类似于开源代码,就像一个开放的盒子。你可以进行定制、微调和修改部分内容。开源模型更加透明,让你能看到用于创建模型的数据和代码。有时,你只能访问模型的权重,这透明度较低,但总体而言,开源模型提供了更多的透明度。你可以理解模型及其支持其功能的相关系统。
在成本方面,开源模型相当经济实惠。你经常能在开源项目中找到较小的模型,如果在自己的笔记本电脑上运行,成本非常低。延迟可以非常低,特别是如果你在本地运行模型或模型本身较小。目前,开源模型的质量是限制因素,因为它们的性能通常低于闭源模型。然而,开源模型在最近几个月和几年里迅速改进。一些令人印象深刻的中国模型,如 Yi、DeepSeek 和 MiniCPM,正在与闭源模型强势追赶。在2024年,使用开源模型是令人兴奋的。

-
Hugging Face 是一个托管模型数据集和演示的平台。
-
平台目前拥有接近100万个模型,数量以指数级增长。
-
平台拥有超过10万个数据集,数据集数量大约在200万到400万之间。
所以,Hugging Face 是一个托管模型数据集和演示的平台。我们拥有大量的模型,实际上,这个说法已经有点过时了,因为我们现在接近拥有100万个模型。这个数字正在以指数级增长。我们拥有超过10万个数据集,大约在200万到400万之间。

用户几乎无处不在,至少在众多组织中都能见到他们的身影,我们通常将他们视为介于各大组织之间的独立第三方。
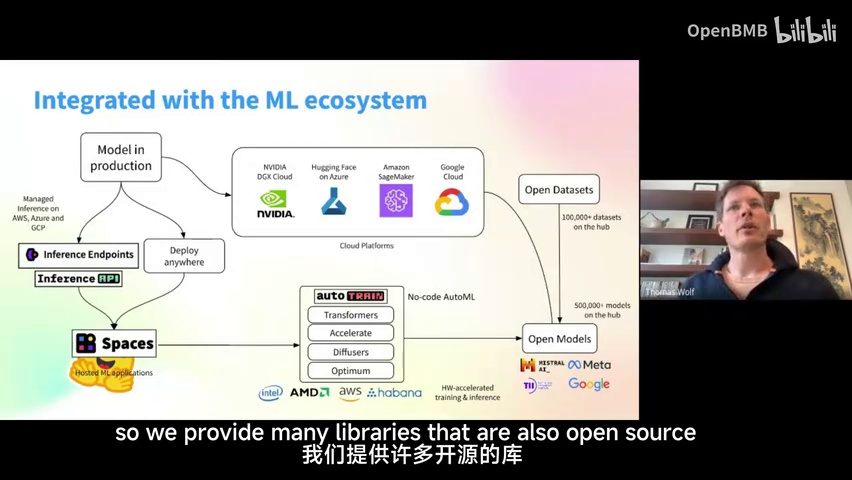
-
该组织专注于人工智能领域,提供多种开源库。
-
这些开源库支持模型开发和部署的全过程。
-
具体库如Transformers和Accelerate,以及相关数据集,用于模型构建、应用和研究。
-
开发后的模型可用于推理部署。
该组织在人工智能领域运作,提供众多开源库,这些库可在模型开发和部署的全
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









