







注:本篇所写的io均为java bio体系(即jdk1.0发布的io)
1.IO相关概念一览
1.1 什么是IO
所谓IO即input和output的缩写,是对数据的流入和流出的一种抽象,编程中很常见的一个概念。
1.2 什么是流
体会一下这几个词:水流(静止的水想必没人会叫水流),物流,人流(此人流非彼人流 = =!),可以发现流的特点:动态的,可转移的,从一处到另一处的
1.3 java io
java为了我们调用方便,而屏蔽输入/输出源和流动细节,抽象出的用于解决数据流动问题的类体系,这就是java的io流
1.4 输入流和输出流
用于读取的流称为输入流(输入流只能用来读),用于写入的流称为输出流(输出流只能用来写)。输入输出的概念一般是针对内存来说的,流(写)入内存,从内存流(读)出。
1.5 字节流和字符流
输入输出流可操作最小单位来区分字节流和字符流,最小操作单位是一个字节(8bit)的为字节流,最小操作单位为一个字符(16bit)的为字符流,java io体系中字节操作流以stream结尾,字符操作流以reader和writer结尾
1.6 节点流和包装(处理)流
1)节点流偏向实现细节,直接与细节打交道,比如FileInputStream,而包装(处理)流偏功能,以目标功能为抽象,比如PrintStream。
2)区分节点流和包装(处理)流最简单的一个方式:处理流的构造方法中需要另一个流作为参数,而节点流构造方法则是具体的物理节点,如上FileInputStream构造法中需要一个文件路径或者File对象,而PrintStream构造方法中则需要一个流对象
3)包装流使用了装饰器模式(什么是装饰器模式?传送门),包装流对节点流进行了一系列功能的强化包装,让包装后的流拥有了更多的操作手段或更高的操作效率,而隐藏节点流底层的复杂性。
1.7 低级流和高级流
低级流和高级流对应的概念即对应上面的节点流和包装(处理)流概念
1.8 普通流和缓冲流
普通流和缓冲流主要是针对读写性能上提出的相对概念。普通流与缓冲流的区别在于一个一个数据的流动还是一堆一堆数据的流动。
1.9 bio,nio,aio
bio:b有两说,一为base,jdk中最早抽象出的io体系;一为block,jdk 1.0 中的io体系是阻塞的。所以两说皆有道理,一般我们认为b取block之意
nio:n也有两说,一为new,针对base而言;一为non-block,针对block而言。
aio:a为asynchronous,异步的,异步io,aio还有个名字叫:nio2
发展历程:bio(jdk1.0) -> nio(jdk1.4) -> aio(jdk1.7)
2.BIO类体系
2.1 体系图
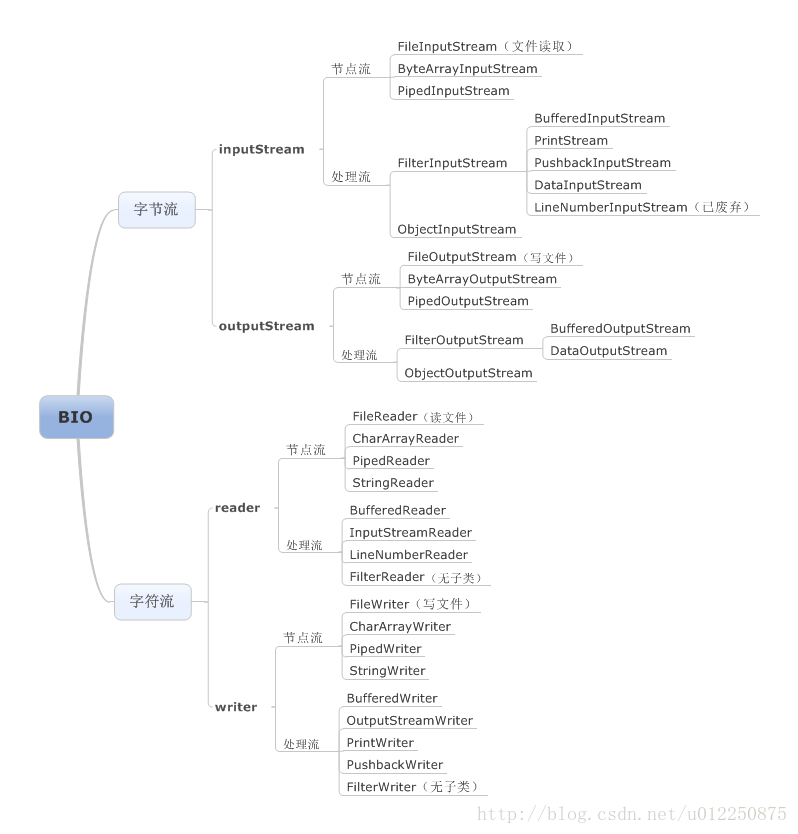
3.BIO体系中的类该怎么使用?
要回答这个问题,我们需要将这个问题进行拆分为下面四个问题
3.1 什么时候该用输入流,什么时候用输出流?
从流中读取信息使用输入流(xxxInputStream/xxxReader),写入信息使用输出流(xxxOutputStream/xxxWriter)
3.2 什么时候该用字节流,什么时候用字符流?
处理纯文本数据时使用字符流(xxxReader/xxxWriter),处理非纯文本时使用字节流(xxxStream)。最后其实不管什么类型文件都可以用字节流处理,包括纯文本,但会增加一些额外的工作量。所以还是按原则选择最合适的流来处理
3.3 什么时候该用节点流,什么时候用包装(处理)流?
不管你用什么包装(处理)流,都需要先使用节点流获取对应节点的数据流,然后根据具体需求来选择相应的包装(处理)流来对节点流进行包装修饰,从而获取相应的功能
3.4 什么时候该用普通流,什么时候用缓冲流?
一般如果对数据流不做加工处理,而是单纯的读写,如数据转移(拷贝,上传,下载),则需要使用缓冲流来提高性能,当然你也可以自己使用buff数组来提高读写效率。
3.5 使用小结
1)判断操作的数据类型
纯文本数据:读用Reader系,写用Writer系
非纯文本数据:读用InputStream系,写用OutputStream系
如果纯文本数据只是简单的复制,下载,上传,不对数据内容本身做处理,那么使用Stream系
2)判断操作的物理节点
内存:ByteArrayXXX
硬盘:FileXXX
网络:http中的request和response均可获取流对象,tcp中socket对象可获取流对象
键盘(输入设备):System.in
显示器(输出设备):System.out
3)搞清读写顺序,一般是先获取输入流,从输入流中读取数据,然后再写到输出流中。
4)是否需增加特殊功能,如需要用缓冲提高读写效率则使用BufferedXXX,如果需要获取文本行号,则使用LineNumberXXX,如果需要转换流则使用InputStreamReader和OutputStreamWriter,如果需要写入和读取对象则使用ObjectOutputStream和ObjectInputStream
4.使用IO流一些注意点
4.1 关于流的read、write方法的使用
下面列出read和write的方法原型(这里以字节流为例,字符流道理相同):
// stream的read
int read();//返回值代表当前读取的字节(8bit)所对应的整形
int read(byte b[]);//将读入的数据装入缓冲区b,实际装了几个字节?实际装了返回值大小个字节,最常使用的read方法
int read(byte b[], int off, int len);//将读入的数据装入缓冲区b,从哪开始装?从off开始,装几个字节?装len个,实际装了几个?实际装了返回值大小个字节
// stream的write
void write(int b);//一次写入一个字节,写入的内容是整型b所对应的二进制数据写入流中
void write(byte b[]);//一次将b数组中的数据写入流中
write(byte b[], int off, int len);//将b数组中区间为[off,off+len]的数据写入流中,最常使用的write方法- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
如果不考虑性能会有如下两种形式来读写:读入一个字节,写入一个字节;使用缓冲区读入一堆字节,然后将缓冲区数据进行写入输出流。如下:
//读一个字节,写一个字节
int b = 0;
while((b = fis.read()) != -1){
fos.write(b);
}
//读入一堆,写入一堆
int b = 0;
byte[] buff = new byte[size];
while((b = fis.read(buff)) != -1){
fos.write(buff,0,b);//将缓冲数组索引区间为[0,b]的数据写入
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
上面第一种方式读一个字节写一个字节没什么说的;第二个方式则需要注意,调用write(buff,0,b)而不是write(buff,0,buff.length),为什么写入[0,b]而不是[0,buff.length]区间的数据呢?因为假如只剩余3个字节没有读取,而缓冲数组定义的大小是8个字节,那么使用[0,buff.length]则会造成多写入5个字节的脏数据
4.2 关于流读写性能问题
流的读写是比较耗时的操作,因此为了提高性能,便有缓冲的这个概念(什么是缓冲?假如你是个搬砖工,你工头让你把1000块砖从A点运到B点,你可以一次拿一块砖从A点运到B点放下砖,这样你要来回跑1000次,大多数的时间开销在路上了;你还可以使用一辆小车,在A点装满一车的砖,然后运到B点放下砖,如果一车最多可以装500块,那么你来回两次便可以把这些砖运完。这里的小车便是那个缓冲),在java bio中使用缓冲一般有两种方式。一种是自己申明一个缓冲数组,利用这个数组来提高读写效率;另一种方式是使用jdk提供的处理流BufferedXXX类。下面我们分别演示不使用缓冲读写,使用自定义的缓冲读写,使用BufferedXXX缓冲读写一个文件。
4.21 无缓冲读写文件
/**
* 拷贝文件(方法一)
* @param src 被拷贝的文件
* @param dest 拷贝到的目的地
*/
public static void copyByFileStream(File src,File dest){
FileInputStream fis = null;
FileOutputStream fos = null;
long start = System.currentTimeMillis();
try {
fis = new FileInputStream(src);
fos = new FileOutputStream(dest);
int b = 0;
while((b = fis.read()) != -1){//一个字节一个字节的读
fos.write(b);//一个字节一个字节的写
}
} catch (Exception e) {
e.printStackTrace();
} finally{
close(fis,fos);
}
System.out.println("使用FileOutputStream拷贝大小"+getSize(src)+"的文件未使用缓冲数组耗时:"+(System.currentTimeMillis()-start)+"毫秒");
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
4.22 自定义数组做缓冲读写文件
/**
* 拷贝文件(方法二)
* @param src 被拷贝的文件
* @param dest 拷贝到的目的地
* @param size 缓冲数组大小
*/
public static void copyByFileStream(File src,File dest,int size){
FileInputStream fis = null;
FileOutputStream fos = null;
long start = System.currentTimeMillis();
try {
fis = new FileInputStream(src);
fos = new FileOutputStream(dest);
int b = 0;
byte[] buff = new byte[size];//定义一个缓冲数组
//读取一定量的数据(read返回值表示这次读了多少个数据)放入数组中
while((b = fis.read(buff)) != -1){
fos.write(buff,0,b);//一次将读入到数组中的有效数据(索引[0,b]范围的数据)写入输出流中
}
} catch (Exception e) {
e.printStackTrace();
} finally{
close(fos,fis);
}
System.out.println("使用FileOutputStream拷贝大小"+getSize(src)+"的文件使用了缓冲数组耗时:"+(System.currentTimeMillis()-start)+"毫秒,生成的目标文件大小为"+getSize(dest));
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
4.23 使用BufferedXXX类使用默认大小缓冲来读写文件
/**
* 拷贝文件(方法三)
* @param src
* @param dest
*/
public static void copyByBufferedStream(File src,File dest) {
BufferedInputStream bis = null;
BufferedOutputStream bos = null;
long start = System.currentTimeMillis();
try{
bis = new BufferedInputStream(new FileInputStream(src));
bos = new BufferedOutputStream(new FileOutputStream(dest));
int b = 0;
while( (b = bis.read())!=-1){
bos.write(b);//使用BufferedXXX重写的write方法进行写入数据。该方法看似未缓冲实际做了缓冲处理
}
bos.flush();
}catch(IOException e){
e.printStackTrace();
}finally{
close(bis,bos);
}
System.out.println("使用BufferedXXXStream拷贝大小"+getSize(src)+"的文件使用了缓冲数组耗时:"+(System.currentTimeMillis()-start)+"毫秒");
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
4.24 使用BufferedXXX类自定义大小缓冲来读写文件
/**
* 拷贝文件(方法四)
* @param src 被拷贝的文件对象
* @param dest 拷贝目的地文件对象
* @param size 自定义缓冲区大小
*/
public static void copyByBufferedStream(File src,File dest,int size) {
BufferedInputStream bis = null;
BufferedOutputStream bos = null;
long start = System.currentTimeMillis();
try{
bis = new BufferedInputStream(new FileInputStream(src));
bos = new BufferedOutputStream(new FileOutputStream(dest));
int b = 0;
byte[] buff = new byte[size];
while( (b = bis.read(buff))!=-1){//数据读入缓冲区
bos.write(buff,0,b);//将缓存区数据写入输出流中
}
bos.flush();
}catch(IOException e){
e.printStackTrace();
}finally{
close(bos,bis);
}
System.out.println("使用BufferedXXXStream拷贝大小"+getSize(src)+"的文件使用了缓冲数组耗时:"+(System.currentTimeMillis()-start)+"毫秒");
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
方法测试:
public static void main(String[] args) {
File src = new File("E:\\iotest\\1.bmp");
File dest = new File("E:\\iotest\\1_copy.bmp");
//无缓冲区
copyByFileStream(src,dest);
sleep(1000);
//32k缓冲区
copyByFileStream(src,dest,32);
sleep(1000);
//64k缓冲区
copyByFileStream(src,dest,64);
sleep(1000);
//BufferedOutputStream缓冲区默认大小为8192字节
copyByBufferedStream(src, dest);
sleep(1000);
//BufferedOutputStream缓冲区默认大小为8192*2字节
copyByBufferedStream(src, dest, 8192*2);
}
//我本地测试如下:
使用FileOutputStream拷贝大小864054字节的文件未使用缓冲数组耗时:5092毫秒,生成的目标文件大小为864054字节
使用FileOutputStream拷贝大小864054字节的文件使用了缓冲数组耗时:215毫秒,生成的目标文件大小为864054字节
使用FileOutputStream拷贝大小864054字节的文件使用了缓冲数组耗时:124毫秒,生成的目标文件大小为864054字节
使用BufferedXXXStream拷贝大小864054字节的文件使用了缓冲数组耗时:41毫秒,生成的目标文件大小为864054字节
使用BufferedXXXStream拷贝大小864054字节的文件使用了缓冲数组耗时:8毫秒,生成的目标文件大小为864054字节- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
从上面可以看出来,如果不使用缓冲(4.21)拷贝一个八百多k的文件,竟然要5秒钟,这个速度让人捉急啊,所以我们拷贝文件时应该使用缓冲技术。由于这是常用功能,便提供了BuffereXXX类简化这个工作,上面我们使用BufferedOutputStream(4.23),即使调用write(int b)方法没有显示使用缓冲数组为什么性能也大大得到提升?来看看BufferedOutputStream中的部分源码:
public class BufferedOutputStream extends FilterOutputStream {
/**
* The internal buffer where data is stored.
*/
protected byte buf[];
public BufferedOutputStream(OutputStream out) {
this(out, 8192);
}
public BufferedOutputStream(OutputStream out, int size) {
super(out);
if (size <= 0) {
throw new IllegalArgumentException("Buffer size <= 0");
}
buf = new byte[size];
}
public synchronized void write(int b) throws IOException {
if (count >= buf.length) {
flushBuffer();
}
buf[count++] = (byte)b;
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
从上面BufferedOutputStream中可以看出,构造实例的时候便创造了一个大小为8192字节的缓冲数组,当我们调用write(int b)方法时,并没有在调用完后直接写入,而是将每一个传入的int值放入到了buf中,只有count >= buf.length时,才调用flushBuffer将缓冲区的数据写入。
4.3 如何判断文件是否读写完毕?
我们一般在处理文件,一般是一边从输出流中读数据,然后将读出的部分进行处理,最后将处理好的数据写入到输出流中。那么要将一个文件完整的处理完,我们必须知道什么时候已经读到文件的末尾了。
一般来说可以根据read方法返回的值,如果返回了-1表示没有可读取的字节了。
另一种是使用available()方法查看还有多少可供读取的,当输入流每读一个字节,available()返回的值便减小1,这种模式很像游标的模式,但要注意的是available的适用场景是非阻塞读取,如本地文件读取,如果是网络io使用该方法,可能你拿到的值就不对了。
总的来说一般输入流提供的读取方法是可以获得文件是否结束的标志,比如流默认的read方法,根据返回值是否非负,比如PrintReader和BufferedReader的readLine()方法,根据返回数据是否非空。
4.4 关于flush()的问题
为什么缓冲输出流写数据结束需要调用flush方法?我们以BufferedOutputStream的write(int b)方法源码为例,源码如下:
public synchronized void write(int b) throws IOException {
if (count >= buf.length) {
flushBuffer();
}
buf[count++] = (byte)b;
}- 1
- 2
- 3
- 4
- 5
- 6
可以得知,BufferedOutputStream在write时候,只有count >= buf.length,即缓冲区数据填满的时候才会自动调用flushBuffer()将缓冲区数据进行写入,也就是说如果缓冲区数据未满则将不会写入,这时我们需人为的调用flush()方法将未满的缓冲区数据进行写入,如下例,可以看出未flush和flush后的区别。
public static void copyByBufferedStream(File src,File dest,int size) {
BufferedInputStream bis = null;
BufferedOutputStream bos = null;
long start = System.currentTimeMillis();
try{
bis = new BufferedInputStream(new FileInputStream(src));
bos = new BufferedOutputStream(new FileOutputStream(dest));
int b = 0;
byte[] buff = new byte[size];
while( (b = bis.read(buff))!=-1){
bos.write(buff,0,b);
}
System.out.println("拷贝大小"+getSize(src)+"的文件使用了缓冲数组耗时:"+(System.currentTimeMillis()-start)+"毫秒,未flush生成的目标文件大小为"+getSize(dest));
bos.flush();
System.out.println("拷贝大小"+getSize(src)+"的文件使用了缓冲数组耗时:"+(System.currentTimeMillis()-start)+"毫秒,flush后生成的目标文件大小为"+getSize(dest));
}catch(IOException e){
e.printStackTrace();
}
}
//测试
public static void main(String[] args) {
File src = new File("E:\\iotest\\1.bmp");
File dest = new File("E:\\iotest\\1_copy.bmp");
copyByBufferedStream(src, dest, 8192);
}
//测试结果:
拷贝大小864054字节的文件使用了缓冲数组耗时:3毫秒,未flush生成的目标文件大小为860160字节
拷贝大小864054字节的文件使用了缓冲数组耗时:3毫秒,flush后生成的目标文件大小为864054字节- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
从上面测试可以知道,如果未使用flush,带来的后果可能会造成部分数据丢失,为什么说是可能?因为如果文件大小刚好是缓冲区的整倍数,即最后一次写入的数据刚好填满缓冲区,write方法也会自动flushBuffer。另一种原因是,调用close方法后会自动将缓冲区的数据flush,我们看看close方法源码,由于BufferedOutputStream类中并没有重写close方法,因此我们去看看直接父类FilterOutputStream的close,源码如下:
public void close() throws IOException {
try (OutputStream ostream = out) {
flush();
}
}- 1
- 2
- 3
- 4
- 5
从上可以看出,在调用close后,其实内部调用了flush(),因此我们在调用close后,数据也能保证数据完整写入,我们验证下我们刚才的分析:
public static void copyByBufferedStream(File src,File dest,int size) {
BufferedInputStream bis = null;
BufferedOutputStream bos = null;
long start = System.currentTimeMillis();
try{
bis = new BufferedInputStream(new FileInputStream(src));
bos = new BufferedOutputStream(new FileOutputStream(dest));
int b = 0;
byte[] buff = new byte[size];
while( (b = bis.read(buff))!=-1){
bos.write(buff,0,b);
}
System.out.println("拷贝大小"+getSize(src)+"的文件使用了缓冲数组耗时:"+(System.currentTimeMillis()-start)+"毫秒,未flush,未调close生成的目标文件大小为"+getSize(dest));
}catch(IOException e){
e.printStackTrace();
}finally{
close(bos,bis);//一个工具方法,内部调用了输出流的close方法,文章后面部分可以看到该方法的源码
System.out.println("拷贝大小"+getSize(src)+"的文件使用了缓冲数组耗时:"+(System.currentTimeMillis()-start)+"毫秒,未flush,调用close后生成的目标文件大小为"+getSize(dest));
}
}
//测试
public static void main(String[] args) {
File src = new File("E:\\iotest\\1.bmp");
File dest = new File("E:\\iotest\\1_copy.bmp");
copyByBufferedStream(src, dest, 8192);
}
//测试结果如下:
拷贝大小864054字节的文件使用了缓冲数组耗时:5毫秒,未flush,未调close生成的目标文件大小为860160字节
拷贝大小864054字节的文件使用了缓冲数组耗时:6毫秒,未flush,调用close后生成的目标文件大小为864054字节- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
这样的结果确实符合我们对源码的分析
4.5 关于网络流中使用available()方法的问题
当你在网络io中,比如你用socket编程时获取到的流进行读写时,会发现使用available方法有问题,原因是网络io的特点是:
1.非实时性。你调用available()方法判断剩余流的大小时,远端数据可能还未发送,或者要发送的数据处于队列中,因此通过available()拿到的可用长度可能是0
2.非连续性。由于网络数据传输中,一般会分段多次发送,available仅仅能返回本次的可用长度。
鉴于以上两个特点,使用available判断网络io还有多少数据可读是不合适的,因此解决该问题一般采用自定义协议,比如文件大小,文件名等信息放入流的头几个字节中,接收方根据收到的头信息来解析出对法传送的文件大小,根据大小来判断还剩多少字节需要读取,是否读取完毕。
4.6 关于关闭流的问题
1)为什么需要手动关闭?
参见【java】手动释放资源问题
2) 关闭流的正确写法
先来两个不规范的,上代码:
/**
* 案例一
*/
public static void main(String[] args) {
try {
FileInputStream fis = new FileInputStream(new File("E:\\iotest\\1.bmp"));
FileOutputStream fos = new FileOutputStream(new File("E:\\iotest\\1_copy.bmp"));
//其他代码
//......
fos.close();
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 案例二
*/
public static void main(String[] args) {
FileInputStream fis = null;
FileOutputStream fos = null;
try {
fis = new FileInputStream(new File("E:\\iotest\\1.bmp"));
fos = new FileOutputStream(new File("E:\\iotest\\1_copy.bmp"));
//其他代码
//......
} catch (IOException e) {
e.printStackTrace();
} finally{
try {
if(fos!=null){
fos.close();
}
if(fis!=null){
fis.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
案例一写法不规范的原因是fis和fos对象执行一些方法时是可能发生异常的,一旦出现异常,虽然由于进行了try catch,但是执行流程会直接进入到catch中,会跳过流的关闭操作。
案例二写法不规范的原因是,虽然讲close操作放入了finally中,但是一旦fos.close执行出现异常,则fis无法正常关闭,修改方法是在finally块中的同时对每个close都单独try catch。
因此写一个关闭流的工具方法,写法如下:
/**
* 关闭给定的io流
*/
public static void close(Closeable...closes){
for (Closeable closeable : closes) {
try {
if(closeable!=null){
closeable.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
/**
* 调用close()方法
*/
public static void main(String[] args) {
FileInputStream fis = null;
FileOutputStream fos = null;
try {
fis = new FileInputStream(new File("E:\\iotest\\1.bmp"));
fos = new FileOutputStream(new File("E:\\iotest\\1_copy.bmp"));
//其他代码
//......
} catch (IOException e) {
e.printStackTrace();
} finally{
close(fos,fis);
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
5.java io流到底能干些什么?
java io主要做两类事情:
1)数据传输,实际例子如文件上传,下载,文件本地拷贝等
2)数据处理,如文本内容加密,图片处理,文件压缩,音视频处理等
6.实践一下
下面就来个简单的实践
6.1 文件拷贝
本文中4.2中的几个方法均可进行文件拷贝,拷贝一般都会使用缓冲来提高性能
6.2 文本加密
因为我们通过java io流处理可以获得文本的原始数据,我们在数据上进行加工就可以加密文本,通过相反的方式就可以解密文本,实际生产中当然不会像下面这么简单的加密,下面我们只是做个示意
public static void encrypt(File src, File dest) {
FileReader fr = null;
FileWriter fw = null;
try {
fr = new FileReader(src);
fw = new FileWriter(dest);
int tmp = 0;
while ((tmp = fr.read()) != -1) {
fw.write(tmp+1);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
close(fw, fr);
}
}
public static void decrypt(File src, File dest) {
FileReader fr = null;
FileWriter fw = null;
try {
fr = new FileReader(src);
fw = new FileWriter(dest);
int tmp = 0;
while ((tmp = fr.read()) != -1) {
fw.write(tmp-1);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
close(fw, fr);
}
}
public static void main(String[] args) {
File src = new File("E:\\iotest\\1.txt");
File dest = new File("E:\\iotest\\1_jiami.txt");
File dest2 = new File("E:\\iotest\\1_jiemi.txt");
encrypt(src, dest);
decrypt(dest, dest2);
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
上面代码中处理方式很简单,仅仅做了一个字符加1处理,然后解密在字符上进行减1处理,便能达到一个加密解密的效果,效果如下
原始密文:
赵兄托你帮我办点事- 1
加密后的文本:
赶充扙佡帯戒功為二- 1
解密后的文本:
赵兄托你帮我办点事- 1
6.3 图片处理
图片文件中存放中图片的分辨率,以及每个像素的色值等信息。我们经常看见如photoshop这类软件对图片进行旋转,扭曲,滤镜等处理,就是对图片中的二进制信息进行一个矩阵变换。下面我们试着做一个图片反相效果。
做这个处理前有两个问题需要考虑:
1)由于平时使用的jpg采用了压缩算法,所以图片中的每个字节并不是图片本身的像素信息,因此我们选择一个bmp格式的图片,来对每一位进行处理,以便达到我们想要的效果。
2)基本所有的二进制文件,图片,音频等文件都有一个头信息,存放该文件的一些基本信息,这些基本信息决定了这个文件是一个bmp图片或者是个gif图片或者是个jpg图片。因此我们对bmp图片做处理时不能破坏bmp文件的头信息。我们知道bmp文件很大,是因为他没有进行压缩,文件内容保存的是图片上对应的像素点的颜色值信息,因此我们队这些颜色值信息做一个处理,即可以得到一些特别的效果。
代码如下:
public static void imageFilter(File src, File dest) {
FileInputStream fis = null;
FileOutputStream fos = null;
try {
fis = new FileInputStream(src);
fos = new FileOutputStream(dest);
int b = 0;
int hasRead = 0;
int headSize = 8*12;
while ((b = fis.read()) != -1) {
hasRead++;
if(hasRead>headSize){
fos.write(-b);
}else{
fos.write(b);
}
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
close(fos, fis);
}
}
public static void main(String[] args) {
File src = new File("E:\\iotest\\1.bmp");
File dest = new File("E:\\iotest\\1_copy.bmp");
imageFilter(src, dest);//800k的文件执行时间大概好几秒,比较长,这里只是做个示意处理
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
上面代码中写数据时,如果字节长度小于headSize则原样输出(headSize我这里取的是12个字节,bmp头信息具体多大我并没有去查询。如果取太小头信息被破坏,bmp文件将不是bmp文件。因此取几十个字节只要保证头信息完整即可。),大于headSize的部分进行一个处理,我们对颜色值取反。效果如下:
原图: 
处理后图片:

通过上面三个的示例可以大致了解java io能做些什么。当然上面只是一个简单的处理,并不能用于实际生产,这里只是说明持有二进制数据,你将可以对文件为所欲为。














 1876
1876











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









