










熟悉hash算法的你,有没有对一致性hash算法也比较熟悉?
一致性hash算法的主要应用场景是在分布式的算法中,比如在一个缓存的分布式系统中,我们可以使用一致性hash算法实现间接的人为控制对每台服务器的缓存命中情况。一致性hash算法,可以理解成为了缓存系统在提供缓存服务过程中,更好的实现高可用,即在对服务器节点进行变更时,最大程度的减少对当前系统的影响。
下面一起来看一致性hash算法:
假设当前的缓存系统中有五台服务器(A-E),我们将每一台服务器的IP地址使用某种hash算法,计算出每一个地址对应的hash值,之后将这五个hash值按照大小顺序分布在一个0-2^32的环上,如下图所示:

当我们使用四台服务器(俗称节点),对当前缓存系统进行访问时,也需要先将每个节点对应的hash值算出,按照顺时针的方向分布在上图构成的环中:
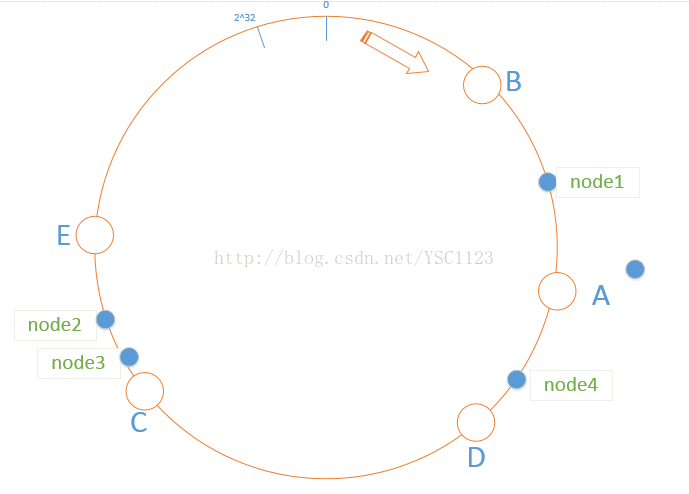
这时,遵照一致性hash算法,当四个节点获取缓存时,命中的机器分别是当前环中每个节点的顺时针方向的下一个缓存服务器,如node1的请求会落在A服务器上,也就是说获取的缓存来自于A服务器;这时每个节点获取缓存的请求分布在不同的服务器上,如下图所示:

从上面的图片中我们不难发现,通过一致性hash算法,我们可以实现对当前获取缓存的请求进行一定程度上分担,不至于某台缓存服务器上压力过大,但是有朋友就会有疑问,既然这样我们可以将某个节点的请求绑定为某个固定的服务器,不也可以实现请求均摊?
这个问题就是我们接下来要考虑的问题:当上图中某个缓存服务器出现宕机,比如E出现异常,无法提供服务,那么按照顺时针的方向,当前node2和node3的请求会落在B服务器上,这样B服务器就会出现承载更大的压力,一旦压力过大,B服务器出现宕机,那么原先需要B和E服务器提供缓存数据的请求都会落在A上,久而久之就会出现“雪崩”,缓存系统中的所有服务器都会因为无法承载压力而宕机,导致整个系统的崩溃。这就与我们使用一致性hash算法实现高可用的初衷背道而驰了!
所以,一致性hash算法中提供了另外一种方式--添加虚拟节点,添加虚拟节点的原理:
我们将当前缓存系统里五台机器做某倍的扩充,即每台机器都添加一定数目的虚拟机器,这些衍生出的虚拟机器都指向它的实际机器。如,A服务器创建出3个虚拟节点 A1,A2,A3,并将虚拟节点的IP地址设置为实际机器的IP+标记,这时缓存系统中的机器个数将由5个变为20个,对每一个机器进行hash计算,环中的服务器的分布将会更密集:这样就会出现15个虚拟服务器节点分布以某种规则分布在环上,而且环上的服务器分布密集,环由最开始的六段变成了20多段,这样的话,第二幅图中的访问请求就会发生变化,比如:
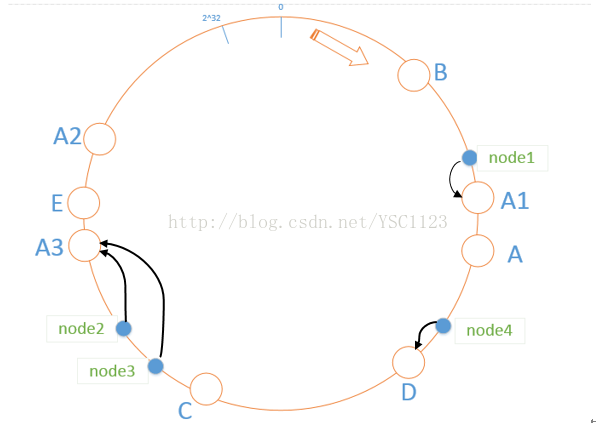
这时,如果其中一台服务器宕机,该服务器顺时针方向的下一台服务器可能是一个虚拟服务器也可能是实际服务器,但是可以确保的是,这时某台服务器宕机影响的范围从最开始的1/6变成了1/20 ,概率大大降低,终止服务的风险也大大降低。
之前在网上看见有网友说,一致性hash算法在redis2.8中有使用,但是通过查阅和验证,发现并没有,只是说redis中使用槽的概念与一致性hash算法的思想相似:

截图源于 redis官方网站
根据上述场景,小编整理了一份不带虚拟节点的程序和添加虚拟节点的两份代码:
package ownTest.redisTest;
import java.util.SortedMap;
import java.util.TreeMap;
/**
* 不带虚拟节点的一致性Hash算法实现
*
* @author yangshichao
*
*/
public class ConsistentHashingWithoutVirtualNode {
/**
* 待添加入Hash环的服务器列表
*/
private static String[] servers = {
"192.168.0.0:111",
"192.168.0.1:111",
"192.168.0.2:111",
"192.168.0.3:111",
"192.168.0.4:111"};
/**
* key表示服务器的hash值,value表示服务器的名称
*/
private static SortedMap<Integer, String> sortedMap = new TreeMap<Integer, String>();
/**
* 程序初始化,将所有的服务器放入sortedMap中
*/
static {
for (int i = 0; i < servers.length; i++) {
int hash = getHash(servers[i]);
System.out.println("[" + servers[i] + "]加入集合中, 其Hash值为" + hash);
sortedMap.put(hash, servers[i]);
}
System.out.println();//输出空行
}
/**
* 使用FNV1_32_HASH算法计算服务器的Hash值
*/
private static int getHash(String str) {
final int p = 16777619;
int hash = (int) 2166136261L;
for (int i = 0; i < str.length(); i++)
hash = (hash ^ str.charAt(i)) * p;
hash += hash << 13;
hash ^= hash >> 7;
hash += hash << 3;
hash ^= hash >> 17;
hash += hash << 5;
// 如果算出来的值为负数则取其绝对值
if (hash < 0)
hash = Math.abs(hash);
return hash;
}
/**
* 得到应当路由到的结点
*/
private static String getServer(String node) {
// 得到带路由的结点的Hash值
int hash = getHash(node);
// 得到大于该Hash值的所有Map
SortedMap<Integer, String> subMap = sortedMap.tailMap(hash);
// 第一个Key就是顺时针过去离node最近的那个结点
Integer i = subMap.firstKey();
// 返回对应的服务器名称
return subMap.get(i);
}
public static void main(String[] args) {
String[] nodes = { "127.0.0.1:1111", "221.226.0.1:2222", "10.211.0.1:3333","192.168.80.21:4444" };
for (int i = 0; i < nodes.length; i++)
System.out.println(
"["
+ nodes[i]
+ "]的hash值为"
+ getHash(nodes[i])
+ ", 被路由到结点["
+ getServer(nodes[i])
+ "]");
}
}
package ownTest.redisTest;
import java.util.LinkedList;
import java.util.List;
import java.util.SortedMap;
import java.util.TreeMap;
/**
* 带虚拟节点的一致性hash算法
* @author YangShiChao
*
*/
public class ConsistentHashingWithVirtualNode {
/**
* 待添加入Hash环的服务器列表
*/
private static String[] servers = {"192.168.0.0:111", "192.168.0.1:111", "192.168.0.2:111",
"192.168.0.3:111", "192.168.0.4:111"};
/**
* 真实结点列表,考虑到服务器上线、下线的场景,即添加、删除的场景会比较频繁,这里使用LinkedList会更好
*/
private static List<String> realNodes = new LinkedList<String>();
/**
* 虚拟节点,key表示虚拟节点的hash值,value表示虚拟节点的名称
*/
private static SortedMap<Integer, String> virtualNodes =
new TreeMap<Integer, String>();
/**
* 虚拟节点的数目,这里写死,为了演示需要,一个真实结点对应3个虚拟节点
*/
private static final int VIRTUAL_NODES = 3;
static
{
// 先把原始的服务器添加到真实结点列表中
for (int i = 0; i < servers.length; i++)
realNodes.add(servers[i]);
// 再添加虚拟节点,遍历LinkedList使用foreach循环效率会比较高
for (String str : realNodes)
{
for (int i = 0; i < VIRTUAL_NODES; i++)
{
String virtualNodeName = str + "&&VN" + String.valueOf(i);
int hash = getHash(virtualNodeName);
System.out.println("虚拟节点[" + virtualNodeName + "]被添加, hash值为" + hash);
virtualNodes.put(hash, virtualNodeName);
}
}
System.out.println();
}
/**
* 使用FNV1_32_HASH算法计算服务器的Hash值
*/
private static int getHash(String str)
{
final int p = 16777619;
int hash = (int)2166136261L;
for (int i = 0; i < str.length(); i++)
hash = (hash ^ str.charAt(i)) * p;
hash += hash << 13;
hash ^= hash >> 7;
hash += hash << 3;
hash ^= hash >> 17;
hash += hash << 5;
// 如果算出来的值为负数则取其绝对值
if (hash < 0)
hash = Math.abs(hash);
return hash;
}
/**
* 得到应当路由到的结点
*/
private static String getServer(String node)
{
// 得到带路由的结点的Hash值
int hash = getHash(node);
// 得到大于该Hash值的所有Map,借助了treeMap的有序特性
SortedMap<Integer, String> subMap =
virtualNodes.tailMap(hash);
// 第一个Key就是顺时针过去离node最近的那个结点
Integer i = subMap.firstKey();
// 返回对应的虚拟节点名称,这里字符串稍微截取一下,为了只显示当前访问对应的实际机器
String virtualNode = subMap.get(i);
return virtualNode.substring(0, virtualNode.indexOf("&&"));
}
public static void main(String[] args)
{
/**
* 可以把这些nodes理解成不同的服务器发来的对当前集群中服务器的请求
*/
String[] nodes = {"127.0.0.1:1111", "221.226.0.1:2222", "10.211.0.1:3333"};
for (int i = 0; i < nodes.length; i++)
System.out.println("[" + nodes[i] + "]的hash值为" +
getHash(nodes[i]) + ", 被路由到结点[" + getServer(nodes[i]) + "]");
}
}















 563
563











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









