




本篇文章为Spark shuffle调优系列第一篇,主要分享Spark Shuffle调优之合并map端输出文件。
默认的shuffle过程如下图所示:
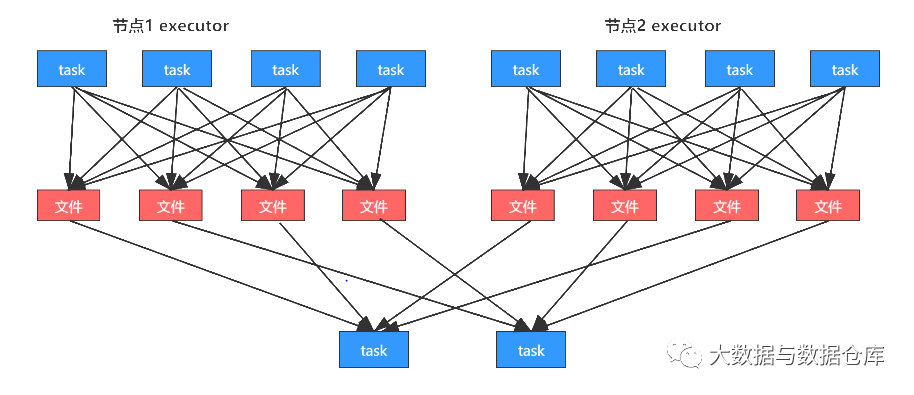
其中第一个stage中的每个task都会给第二个stage的每个task创建一份map端的输出文件;
第二个stage中每个task会到各个节点上面去拉取第一个stage中每个task输出的,属于自己的那一份文件。
问题来了:默认的这种shuffle行为,对性能有什么样的恶劣影响呢?
假设实际生产环境的条件如下:
100个节点(每个节点一个executor):100个executor
每个executor:2个 cpu core
总共1000个task:每个executor平均10个task
每个节点中包含10个task,每个节点会输出10 * 1000=1万 份map端文件
总共有多少份map端输出文件?100 * 10000 = 100万。
通过上面的分析,一个普通的生产环境的spark job的一个shuffle环节,会写入磁盘100万个文件。
shuffle中的写磁盘的操作,基本上就是shuffle中性能消耗最为严重的部分。
磁盘IO对性能和spark作业执行速度的影响,是极其惊人和吓人的。基本上,spark作业的性能,都消耗在shuffle中了,虽然不只是shuffle的map端输出文件这一个部分,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 324
324

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









