




 本文介绍了Spark Shuffle调优的关键,聚焦于map task的内存缓冲参数`spark.shuffle.file.buffer`和reduce端内存占比参数`spark.shuffle.memoryFraction`。默认配置可能导致频繁磁盘IO,影响性能。调优方案包括观察Spark UI,根据shuffle write和read的量调整参数,以减少溢写次数并优化聚合操作。
本文介绍了Spark Shuffle调优的关键,聚焦于map task的内存缓冲参数`spark.shuffle.file.buffer`和reduce端内存占比参数`spark.shuffle.memoryFraction`。默认配置可能导致频繁磁盘IO,影响性能。调优方案包括观察Spark UI,根据shuffle write和read的量调整参数,以减少溢写次数并优化聚合操作。
一. 引言

本文首先介绍Spark中的两个配置参数:
spark.shuffle.file.buffer map端内存缓冲 spark.shuffle.memoryFraction reduce端内存占比
很多博客会说上面这两个参数是调节Spark shuffle性能的利器,实际上并不是这样的。
以实际的生产经验来说,这两个参数没有那么重要,往往来说shuffle的性能不是因为这方面的原因决定的,但是整体来说还是有一点点效果的。
这两个shuffle调优的小点能带来一些性能的提升,与其他调优小点结合起来最终可以会有可以看见的还算不错的性能调优的效果。

二. 调优原理
默认情况下shuffle的map task输出到磁盘文件的时候,统一都会先写入每个task自己关联的一个内存缓冲区。这个缓冲区大小,默认是32kb。
每一次当内存缓冲区满溢之后才会进行spill操作(溢写操作)溢写到磁盘文件中去。
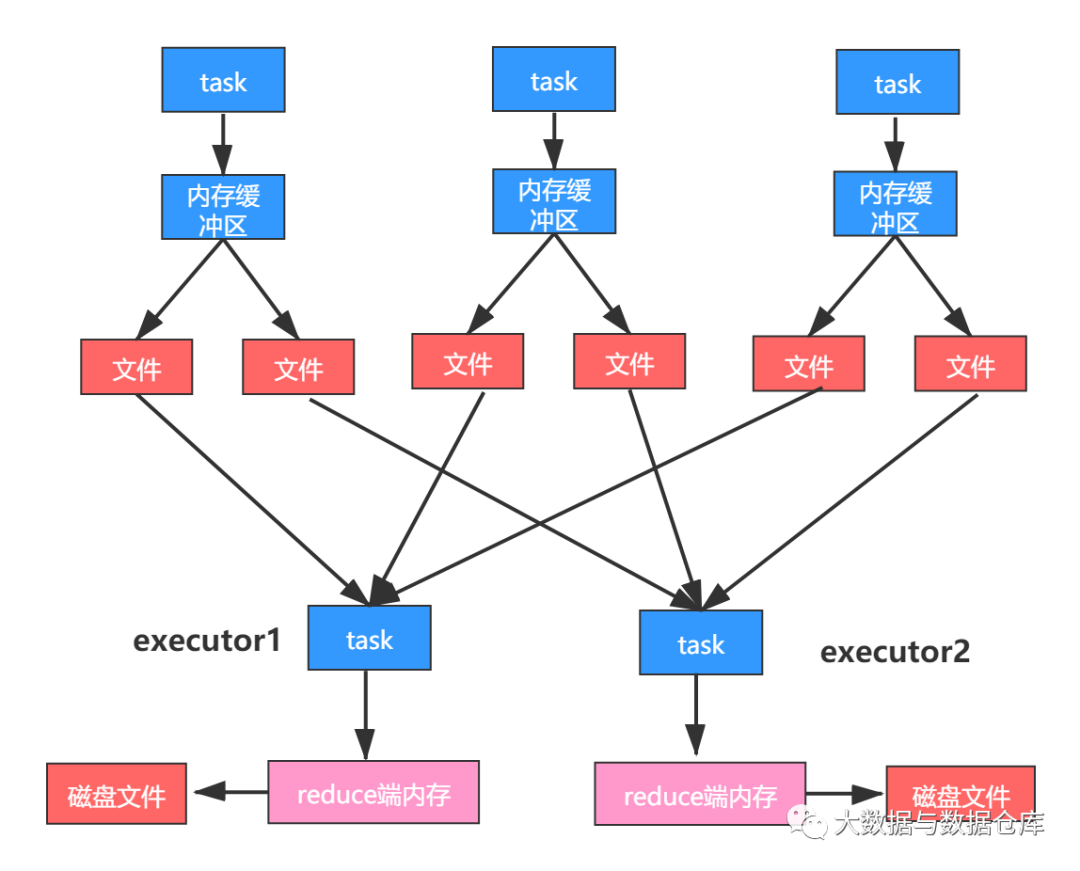
reduce端task拉取到数据之后会用hashmap这种数据格式来对各个key对应的values进行汇聚。针对每个key对应的values执行我们自定义的聚合函数的代码,比如_ + _(把所有values累加起来)。
reduce task在进行汇聚、聚合等操作的时候使用的就是自己对应的executor的内存,默认executor内存中划分给reduce task进行聚合的比例,是0.2。
问题来了,因为默认比例是0.2,理论上很有可能会出现拉取过来的数据很多导致在内存中放不下,内存无法放下的数据,都被spill(溢写)到磁盘文件中去了。
原理说完之后,来看一下默认情况下不调优会出现什么样的问题
默认配置下map端内存缓冲是每个task,32kb。
默认配置下reduce端聚合内存比例,是0.2,也就是20%。</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 855
855

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









