






这里写目录标题
概述:为什么格式之后就不能启动datanode节点
格式化hdfs后有的时候namenode会出现无法启动的问题,我们每次在格式化namenode时都会产生一个新的集群ID,如果格式化成功,在命令行输出信息里就有新产出的集群ID第一次配置Hadoop时我们会格式化一次,这时就产生了一个集群ID,并且这时datanode就会“记住”这个ID,就像认老大一样,datanode认了具有特定集群ID的namenode做老大,只听它的调遣。如果某一天我们又格式化了一遍namenode,好比老大改头换面了,那小弟们自然就不认识了,datanode“记住”的依然还是第一次格式化时产生的集群ID,不能跟新产生的集群ID相匹配,那它自然启动不了。

所以我们要把之前已有的,一些数据给删除掉。
最后的效果
注意重要!!!
有重要的数据记得备份。

格式化hdfs步骤
注意!!!:
所有的命令都要分别在三个节点执行,自己亲测,自己把主节点的Hadoop按照我的下面的方法格式化后,分发到三个节点上,让后启动start-all.sh。还是启动不起来。只有主节点的datanode启动起来了。所以一定要在三个节点上同时执行下面的命令,到最后三个节点的datanode才启动
每个人的用的不一样我用的是FinalShell。但是一定要每个节点都要发一遍。
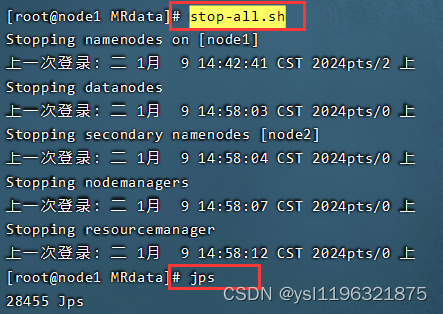
1. 停止Hadoop服务
在格式化之前,确保整个Hadoop集群已完全停止运行,包括NameNode、DataNode以及其他相关服务。
stop-all.sh
2、备份数据(可选)
如果不是第一次启动集群且你希望保存现有数据,请先备份NameNode的持久化目录,即 dfs.name.dir 指定的位置。
3、删除旧的元数据文件
删除NameNode上存储的命名空间镜像和编辑日志等元数据文件。这些文件通常位于配置参数 dfs.namenode.name.dir 所指定的目录下。例如:
Bash
假设dfs.namenode.name.dir设置为/home/hadoop/dfs/name
rm -rf /home/hadoop/dfs/name/*
如果没有dfs.namenode.name.dir可以不做。本人是没有的。但是方法看:4、确认DataNode目录。都差不多。
4、确认DataNode目录
删除 name 和 data 文件夹下的所有内容。可以使用以下命令来删除文件夹中的所有内容:
注意:每个人配置的文件的,路径、文件名都不一样。所以删除的name和data文件名不是一定的
,找到具体的路径的方法。
bash
rm -rf $HADOOP_HOME/data/hdfs/namenode/*
rm -rf $HADOOP_HOME/data/hdfs/datanode/* //自己的路径
具体的路径
根据需求,可能还需要清理DataNode上的数据块存储目录,它们位于 dfs.data.dir 指定的位置。
注意:这个是自己的
cd $HADOOP_HOME/etc/hadoop/
cat core-site.xml
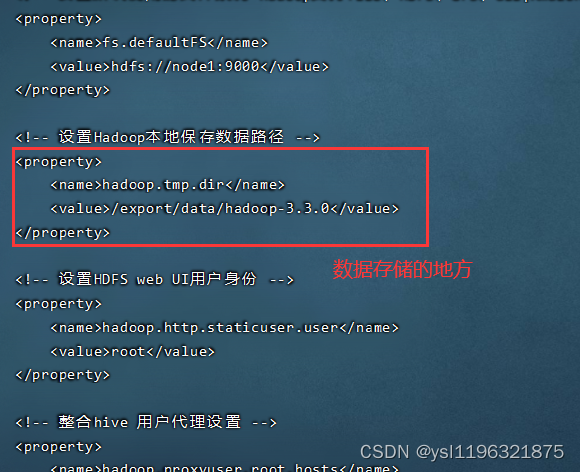
数据就是在上面的路径:cd /export/data/hadoop-3.3.0 进去 ,这个是我的数据
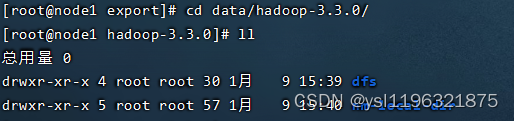
把里面的数据name、data,都给删除掉。
rm -rf 文件名;
5、格式化NameNode
使用Hadoop命令行工具执行NameNode格式化操作:
Bash
hdfs namenode -format
这个命令会创建新的元数据结构并初始化集群。

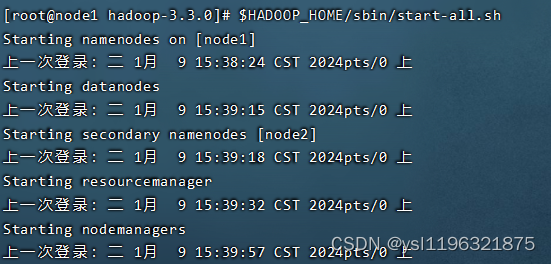
6、启动Hadoop集群
这个主节点,执行一下就可以了。主节点会自动把别的节点启动
start-all.sh //写这个命令就行,我的图片上的命令也可以。
完成格式化后,可以启动Hadoop集群的所有组件,包括NameNode和DataNode。
一定要jps看一下所有节点都启动了。
jps



请注意,重新格式化NameNode会导致集群中所有用户数据丢失,因此在执行此操作前务必确认操作意图并做好相应准备。















 444
444











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









