






应用场景:
将旧的数据从一个Elasticsearch集群,迁移到应外一个Elasticsearch集群
将每天或者每月的索引库,合并成一个索引库
1、安装插件
安装命令:进入到lostash的目录:
bin/logstash-plugin install logstash-input-elasticsearch
如果安装不上,卡在验证,请尝试一下一下安装命令:
bin/logstash-plugin install --no-verify logstash-input-elasticsearch
如果还是安装不上,请修改logstash下的Gemfile:
将ruby源修改为一下任意一个镜像:
source "https://rubygems.org" 修改为:source "https://ruby.taobao.org/" 或者 source "https://gems.ruby-china.org"
2、配置参数
2.1、描述
基于从Elastisearch集群中查询的结果。这对于重新索引日志等很有用处。
例如:
input {
# Read all documents from Elasticsearch matching the given query
elasticsearch {
hosts => “localhost”
query => ‘{ “query”: { “match”: { “statuscode”: 200 } }, “sort”: [ “_doc” ] }’
}
}
这相当于如下对Elasticsarch集群做了一次查询:
curl ‘http://localhost:9200/logstash-*/_search?&scroll=1m&size=1000’ -d ‘{
“query”: {
“match”: {
“statuscode”: 200
}
},
“sort”: [ “_doc” ]
}’
2.3、Elasticsearch输入的配置参数(Elastisearch Input Configuration Options)
支持一下参数选项,常见参数选项在后面列出。
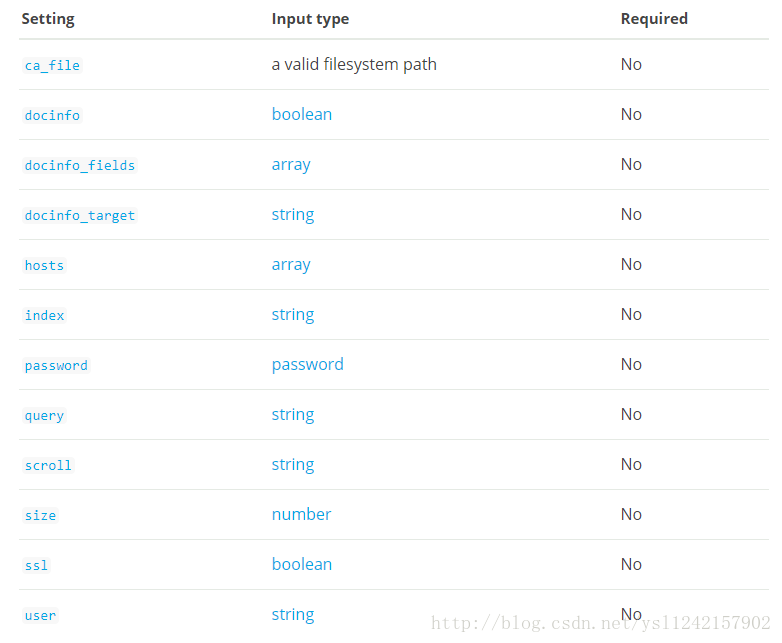
ca_file:
类型:path
没有默认值
具有PEM编码格式的SSL证书颁发机构文件,必要时还必须包含任何链式证书。
doc_info:
类型:boolean
默认:false
如果设置,请在事件中包含Elasticsearch文档信息,如索引,类型和id。
要注意的是,关于元数据,如果您正在查询文档以重新建立索引(或只是更新它们)。 它可以动态分配一个字段添加到元数据中。
例如:
input {
elasticsearch {
hosts => “es.production.mysite.org”
index => “mydata-2018.09.*”
query => ‘{ “query”: { “query_string”: { “query”: “*” } } }’
size => 500
scroll => “5m”
docinfo => true
}
}
output {
elasticsearch {
index => “copy-of-production.%{[@metadata][_index]}”
document_type => “%{[@metadata][_type]}”
document_id => “%{[@metadata][_id]}”
}
}
docino_fields:
类型:array
默认数据:[“_index”, “_type”, “_id”]
如果启用docinfo选项,则文档元数据是需要的,该选项将会列举所有的元数据字段以保存到当前事件中。查看[文档元数据]
(http://www.elasticsearch.org/guide/en/elasticsearch/guide/current/_document_metadata.html)
详情请参考Elasticsearch的文档获取更多的信息
docinfo_traget:
类型:string
默认:”@metadata”
当启用docinfo选项时,文档元数据是需要的,该选项将会确定那个字段存储元数据字段。
hosts:
类型:array
无默认值
列举一个或者多个Elasticsearch主机,用于查询数据,每一个host可以是IP也可以是HOST,IP:port 或者 HOST:port.默认端口是9200
index:
类型:string
默认:”logstash-*”
要查询的索引库的名称或者别名。
password:
类型:password
无默认值
在对Elasticsearch服务器进行身份验证时,与用户选项中的用户名一起使用的密码。 如果设置为空字符串,认证将被禁用。
query:
类型:string
默认:’{ “sort”: [ “_doc” ] }’
要执行的查询。 阅读[Elasticsearch查询DSL文档]。详情请参考:(https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl.html)
scroll:
类型:string
默认:1m
这个参数用于控制每次scrolling请求的报活时间并启动scrolling进程。该时间每次适用于往返时间。
size:
类型:number
默认:1000
每次scroll请求返回的最大命中数。
ssl:
类型:boolean
默认值:false
如果启用该参数,与Elasticsearch交互的时候将会使用HTTPS请求。
user:
类型:string
无默认值
当与Elasticsearch服务器进行认证时,user与password一起使用。如果设置空字符串,认证将失效。

add_field:
类型:hash
默认:{}
添加一个字段到事件中。
codec:
类型:codec
默认值:”plain”
用于输入数据编解码器,输入编码器是一种便捷的方法,用于在数据进入输入之前进行编码,而不需要在Logstash的pipleline中添加过滤器。
enable_metric:
类型:boolean
默认值:true
是否启用metric日志,默认情况下,我们是尽可能的收集所有插件示例的metrics日志,但你也可以不启用特定插件的metric日志。
id:
类型:string
无默认值
为插件配置添加一个唯一的ID。 如果没有指定ID,Logstash将会生成一个。 强烈建议在您的配置中设置此ID。 当你有两个或多个相同类型的插件时,这是特别有用的,例如,如果你有两个elasticsearch输入。 在这种情况下添加一个命名的ID将有助于在使用监视API时监视Logstash。
input {
elasticsearch {
id => “my_plugin_id”
}
}
tags:
类型:array
无默认值
添加任意的数字标识到事件中。这可以帮助我们后期处理。
type:
类型:string
无默认值
Logstash输入的基本类型,输入将会在所有的事件中添加type类型字段。它将会主要用于过滤。Type作为时间本身的一部分,因此你可以在kibana上进行查询。
如果对事件设置了type,新的输入是不会覆盖已经存在的type的。设置的type将会在传输的过程中一直存在。
3、配置文件
input {
elasticsearch {
hosts => [“172.22.9.3:9200”,”172.22.9.4:9200”,”172.22.9.20:9200”,”172.22.9.21:9200”]
index => “inner-nginx-20170412”
query => ‘{ “query”: { “query_string”: { “query”: “*” } } }’
size => 1000
scroll => “1m”
docinfo => true
}
}
output {
elasticsearch {
hosts => [“172.22.9.3:9200”,”172.22.9.4:9200”,”172.22.9.20:9200”,”172.22.9.21:9200”]
index => “inner-nginx-201704”
document_type => “%{[@metadata][_type]}”
document_id => “%{[@metadata][_id]}”
}
stdout {
}
}
以上使用得是将四月份每天生成的索引库,合并成一个索引库。
官网参考:https://www.elastic.co/guide/en/logstash/current/plugins-inputs-elasticsearch.html















 6412
6412











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









