






综述:
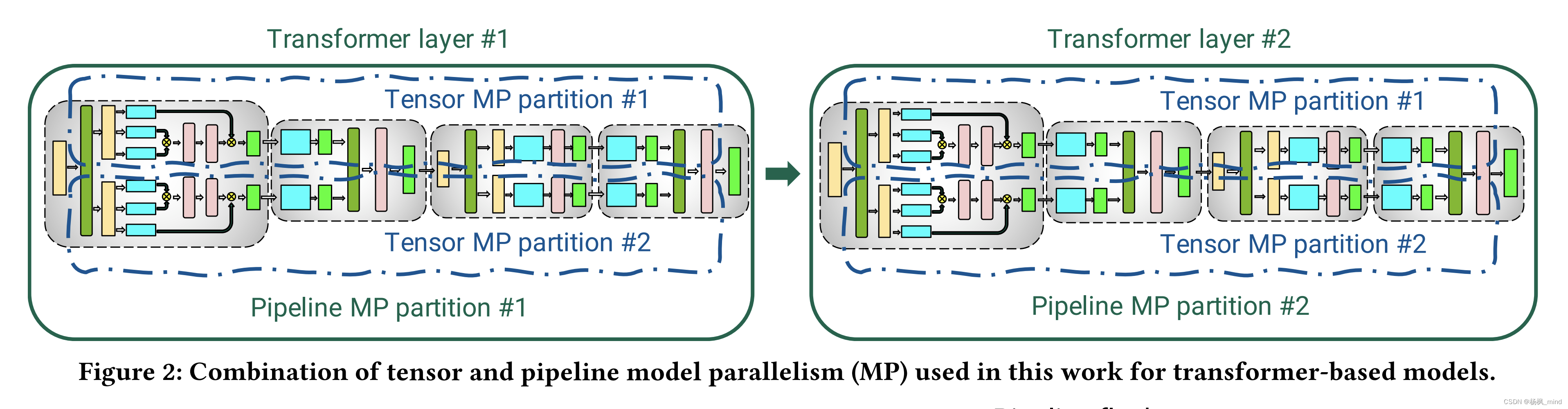
最sha傻呵呵的pipeline parallelism调度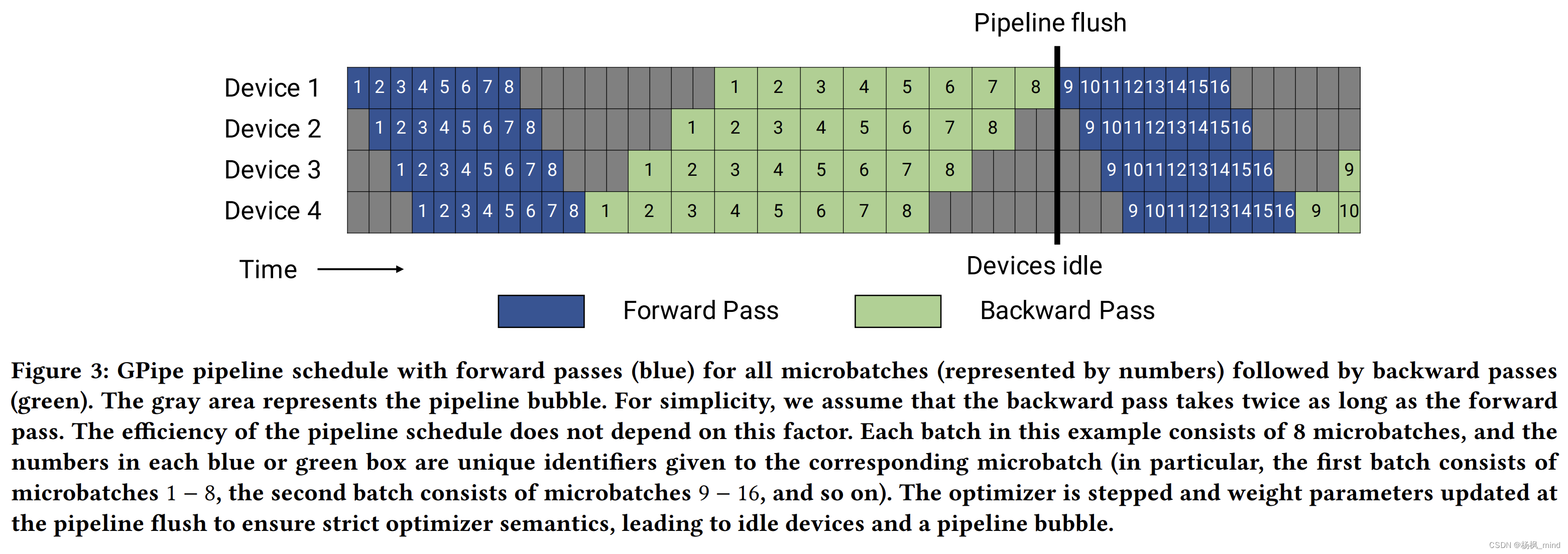
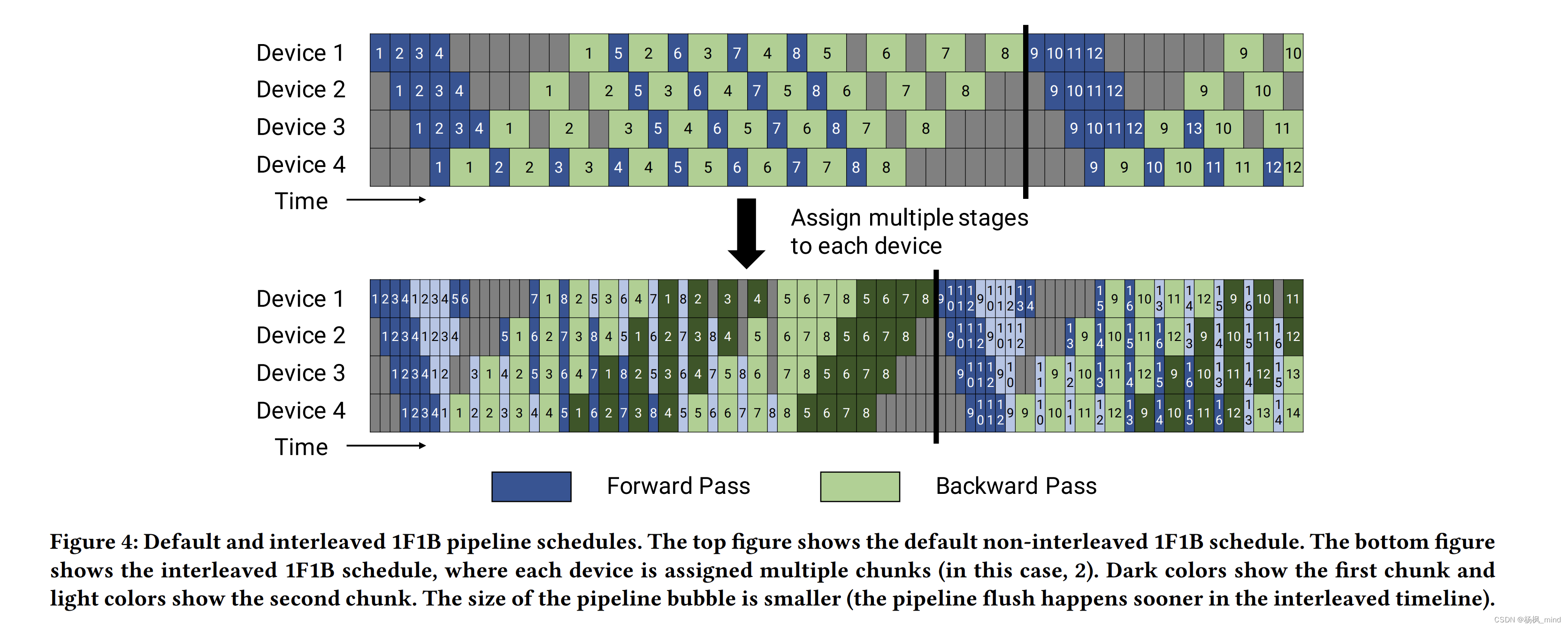
普通1F1B(一步Forward 一步Backword)和更优秀的interleaving的1F1B pipeline parallelism调度
transformer的MLP(多层感知机,类似resnet隐藏层)矩阵乘的tiling:
其中MLP是A按列Tiling成两半,两个GPU各出半个Y,然后各自半个Y再跟row tiling的B算出结果矩阵中50%的psum,然后两个GPU all-reduce做一下加法在两个GPU都合成出最终结果。
self-attention是按照multi-head attention,两个GPU一边一个head计算各自出半个Y,然后各自半个Y再跟row tiling的B算出结果矩阵中50%的psum,然后两个GPU all-reduce做一下加法在两个GPU都合成出最终结果。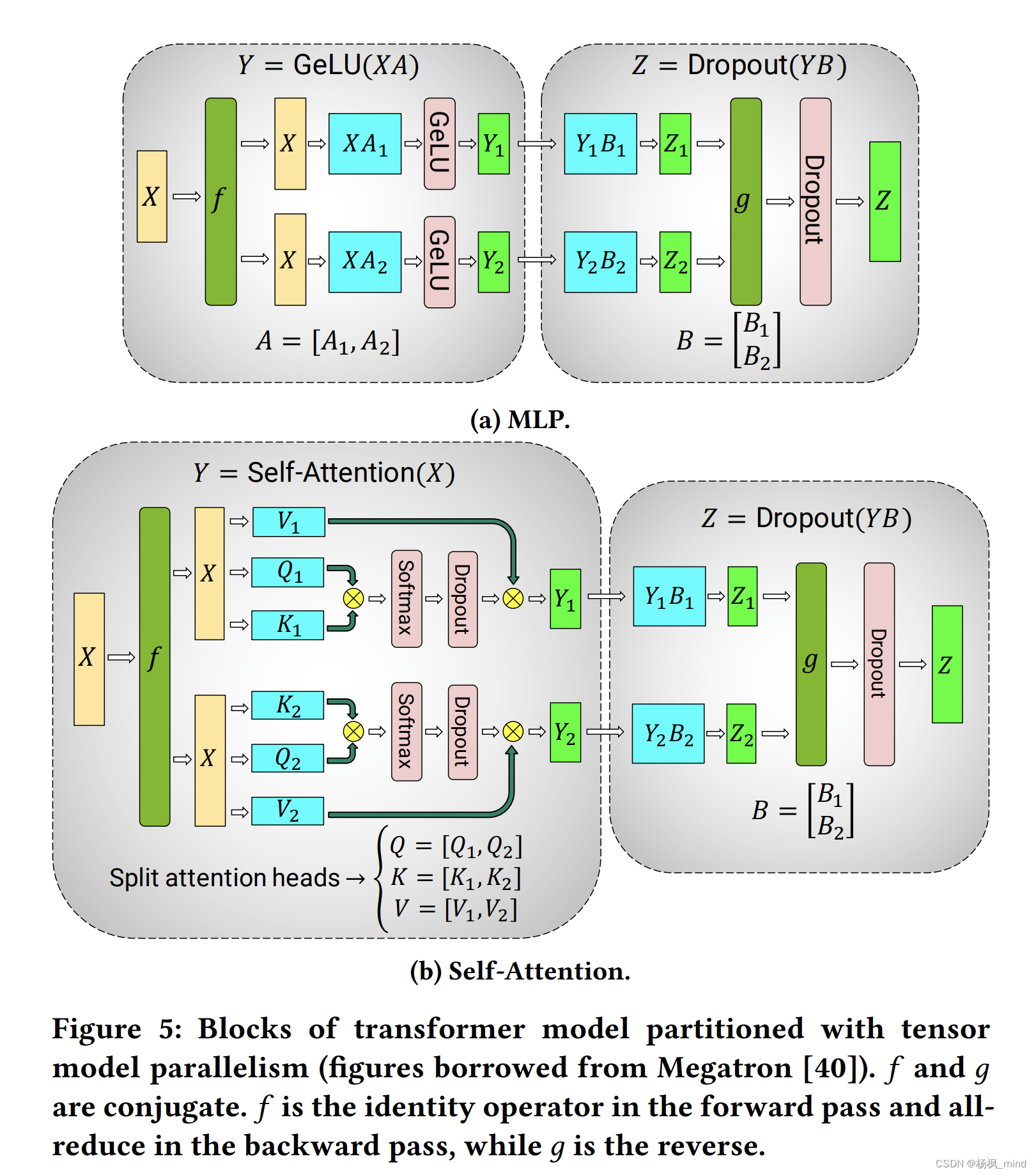



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









