







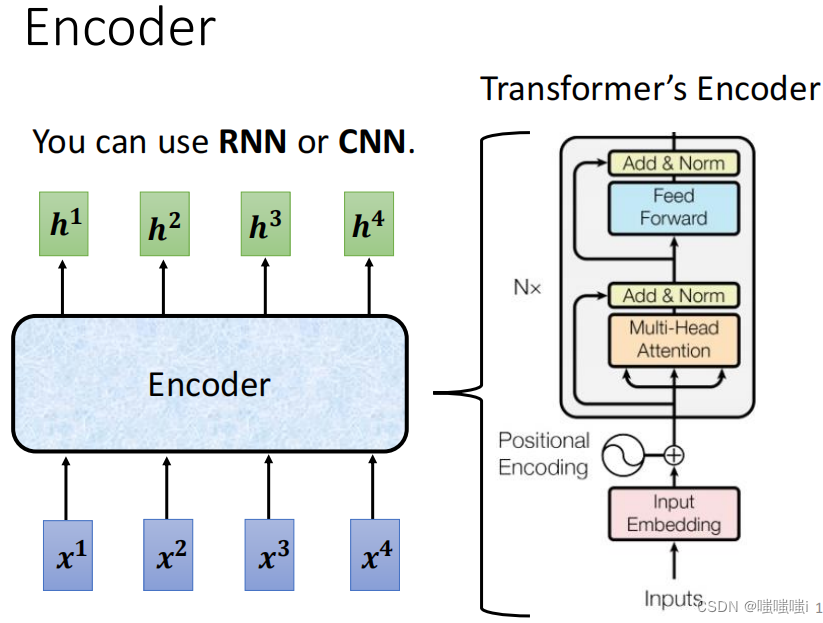
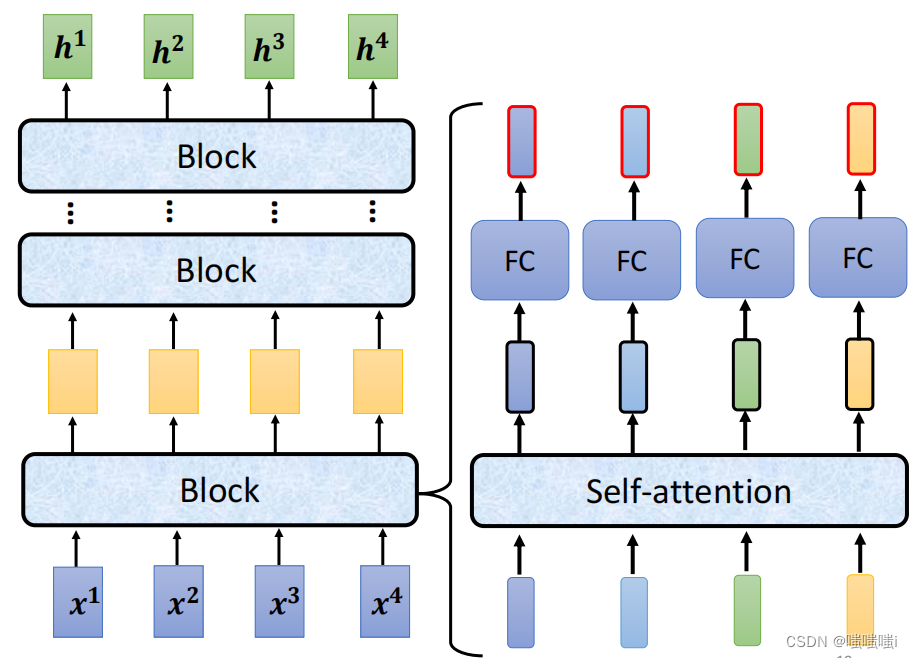
GNN
- 多层传播之后,节点表示缺乏可区分性,远处节点影响微乎其微
- 拓扑图
- 难以捕捉长依赖关系,不能并行计算
GCN
结合邻近节点特征的方式和图的结构依依相关,这局限了训练所得模型在其他图结构上的泛化能力
Graph Attention Network (GAT)
GAT提出了用注意力机制对邻近节点特征加权求和。邻近节点特征的权重完全取决于节点特征,独立于图结构。
Transformer
- 全连接图
- 缓解过平滑问题
- 捕捉全局依赖关系,高效并行计算
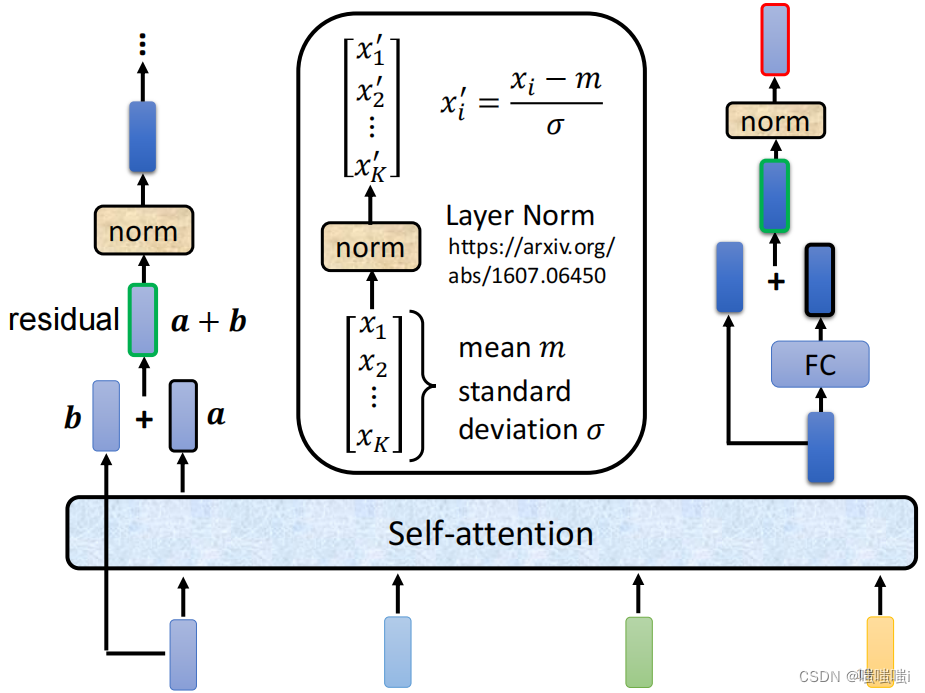
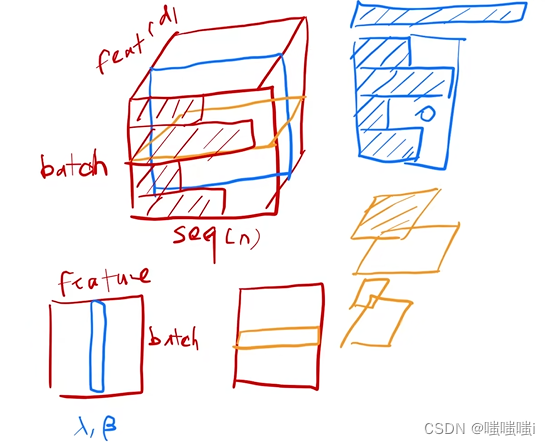
BatchNorm
每次把每一列在一个小mini-batch把均值变为0,方差变为1(减掉均值之后除以方差)。会学一个λ和γ,存下全局的方差和均值。下图蓝色部分
LayerNorm
对样本来做的,与batchnorm基本一样,变每一行。相当于数据转置以后放入batchnorm再转置回去。下图黄色部分
Transformer中一般使用LayerNorm,样本长度相差大时候用BatchNorm均值和方差抖动比较大,LayerNorm是在每个样本里面算的,均值和方差相对稳定一些。
Decoder
掩码层:T时间不能看到T时间之后的数据
注意力机制
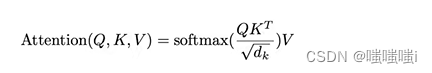

加性注意力机制:可以处理Q和K不等长的情况
点积注意力机制:Transformer用的是这个,比最简单的点乘多除以了一个。
当小的时候没关系,
大的时候(两个向量长度比较长),相对的差距会变大,最大的值做出来的softmax会更靠近1其他的靠近两端(0),梯度会比较小。有些QK对在经过点积运算后的结果相对于其他点积对来说过大,这就导致在之后的softmax中占据了绝大多数注意力,而其他的点积对在经过softmax之后的分数则趋于0,结果就是会出现梯度消失的问题。因此这里除以一个常数的操作类似于归一化,使得各点积对的结果更加平滑。
Attention解释:(来自B站一个评论)
你和女朋友去宜家买家具,然后看到了很多家具。
每个家具的设计理念不同,有些可能主打服务女性,比如化妆台,有些可能主打服务男性,比如电竞椅,这些主打的偏重性就是家具的K。
虽然他们设计出来就有天生的不可磨灭的偏重性,但是女生也有喜欢打游戏的呀,所以也可能会买电竞椅,因为女性和女性是不同的,这个不同就是Q。
如何判断你女朋友会不会买电竞椅,就要用电竞椅对你女性的吸引力乘以她自身的购买偏好,即Q*K。
那么我们得到了女朋友购买这个电竞椅的概率Q*K,同时每个电竞椅的价格是V,那么显而易见,QKV就是这个电竞椅对女性的销售额。
拓展开来,每个人有自己的Q,即embeding向量。每个家具有自己的K,自己的V。那么此时QKV都拓展成了二位矩阵,所以QKV的结果也从原来的电竞椅对女性的销售额扩大为了每个家具对每个不同人的销售额。
BLEU分数
BERT





GraphMAE
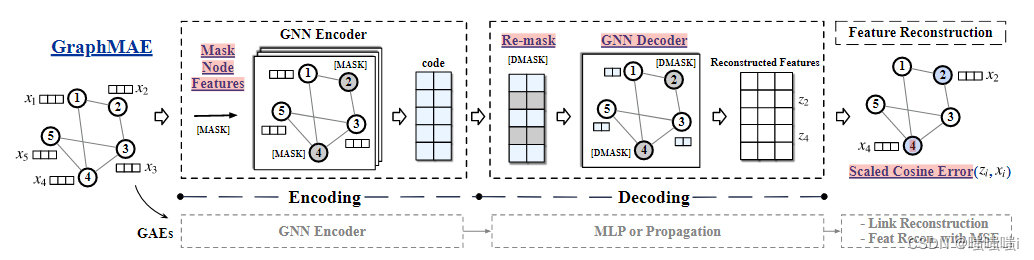
首先是encoding结构,在autoencoder的基础上,主要的改动有:
是基于特征而非结构的重建,然后引入了mask操作。mask之后用gnn来进行特征聚合,得到节点的embedding。作者认为对输入进行破坏是必要的,否则有可能会学习到一个恒等映射,相当于什么都没有学习。所以需要对特征进行mask操作,具体表现为将某些节点的特征用一个无意义的向量进行替代。
然后是decoding结构:
加入了remask操作,对之前的mask集合内的点再做一次mask操作。因为这个模型是建立在局部同质性前提上的,所以信息其实冗余度会比较大。冗余度大的话,其实对特征重建来说难度会低一点,那么所能学习到的参数就会少一点,这里rmask,其实就是提高了重建的难度,进而提高学习质量。这样做可以进一步压缩信息,提高表现力。
decoder模型没有采用之前所说的mlp,而是采用了gnn
最后是特征重建过程
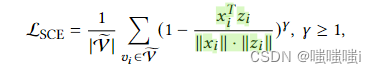
这里的改进主要是采用了新的误差函数。原本的MSE的缺点已经讲过了,那么采用cos来衡量向量的夹角的话会是一个比较合理的方法。这里作者在余弦函数的基础上又加了一点改进。相比于那些本身夹角就已经比较小的向量来说,其实我们跟应该去关注那些夹角比较大的向量的修正,所以这里加了一个参数γ用来进行缩放。其实不难发现,当夹角大于90度的时候,1-cos>1,此时随着 γ变大,整体的值会变大,权重也会变大,那么这种hard样本就会受到更多的关注。
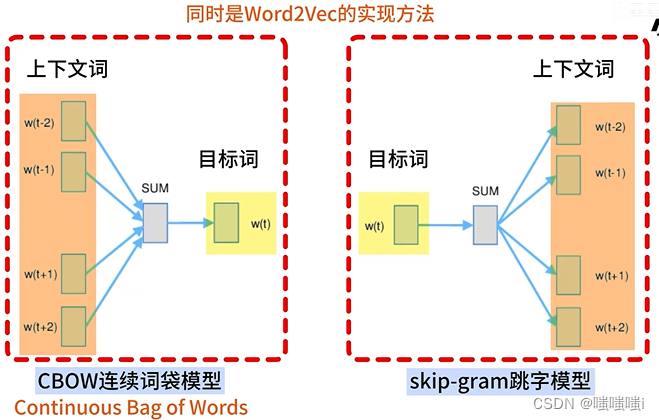
Word Embedding


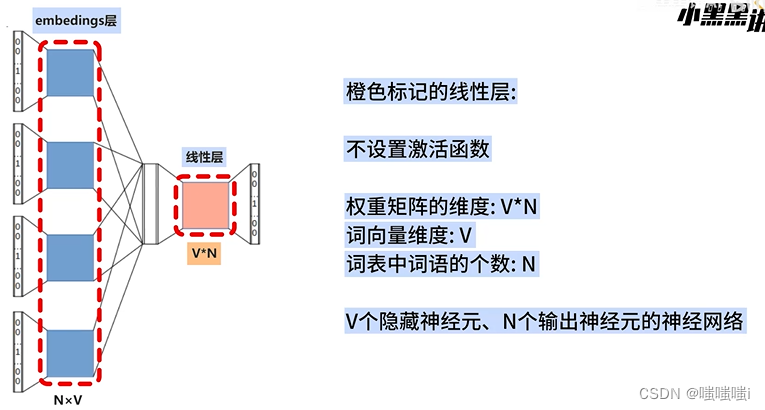
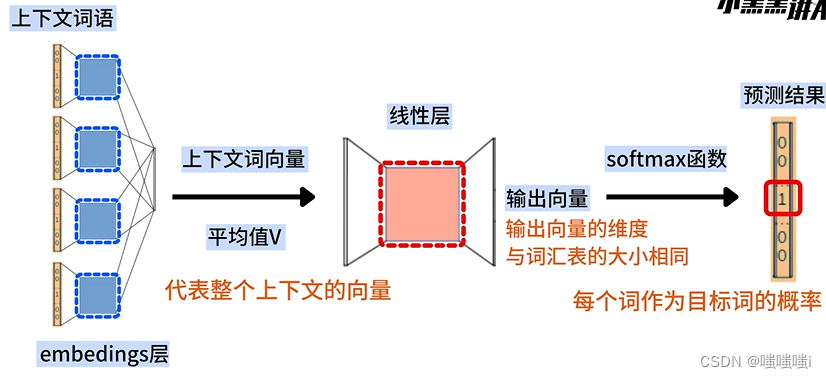
word2vec连续词袋模型CBOW

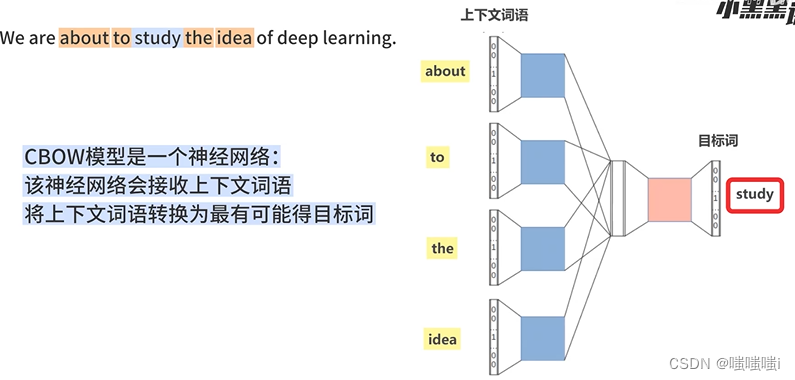
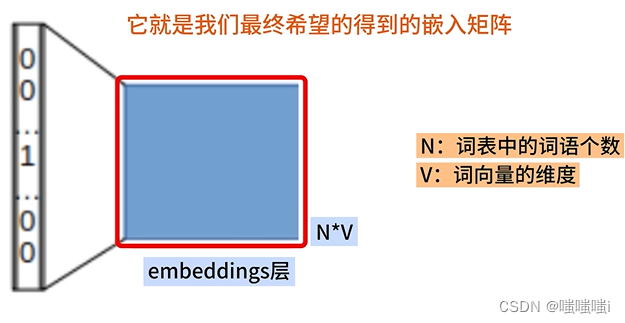
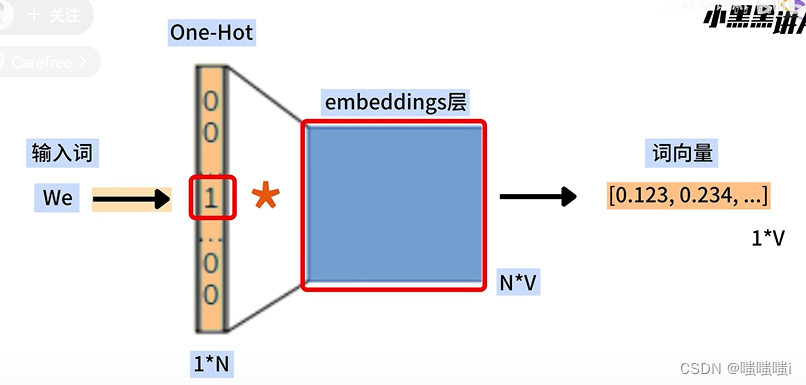
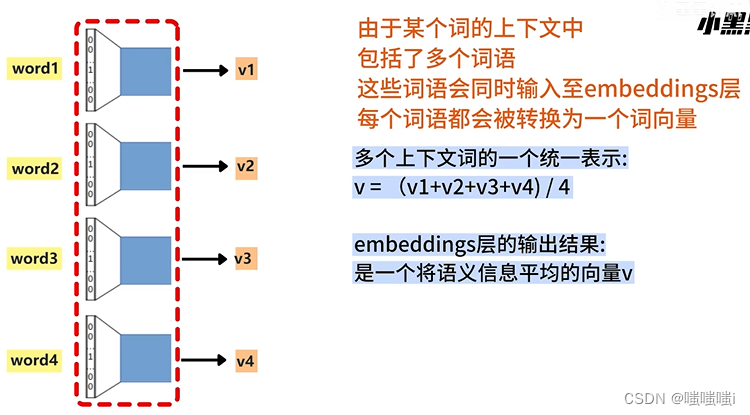
数据增强
在深度学习中,数据增强是通过一定的方式改变输入数据,以生成更多的训练样本,从而提高模型的泛化能力和效果。数据增强可以减少模型对某些特征的过度依赖,从而避免过拟合。
使用数据增强的原因:在深度学习中,要求样本数量充足,样本数量越多,训练出来的模型效果越好,模型的泛化能力越强。但是实际中,样本数量不足或者样本质量不够好,这时就需要对样本做数据增强,来提高样本质量。
例如在图像分类任务中,对于输入的图像可以进行一些简单的平移、缩放、颜色变换等操作,这些操作不会改变图像的类别,但可以增加训练样本的数量。这些增强后的样本可以帮助模型更好地学习和理解图像的特征,提高模型的泛化能力和准确率。
原文链接:http://t.csdnimg.cn/X2hBj
Dropout原理及作用
Dropout叫做随机失活,是作为缓解卷积神经网络CNN过拟合而被提出的一种正则化方法。简单来说就是在模型训练阶段的前向传播过程中,让某些神经元的激活值以一定的概率停止工作,这样可以使模型的泛化性更强。
缺点:能会减缓模型收敛的速度,因为每次迭代只有一部分参数更新,可能导致梯度下降变慢。
温度参数τ
较大时,给低值赋予更多的权重,使分布更均匀;较小时,较大数值会有更大的优势。
温度越高,模型更愿意选择可能性较低的词。
MASK
各向异性
什么叫各向异性?举个例子,一些电阻原件,正接是良导体,反接是绝缘体或者电阻很大,沿不同方向差异很大。在bert出来的向量中表现为,用不同的方式去衡量它,他表现出不同的语义,差别很大,也就是不能完整的衡量出bert向量中全部语义信息。
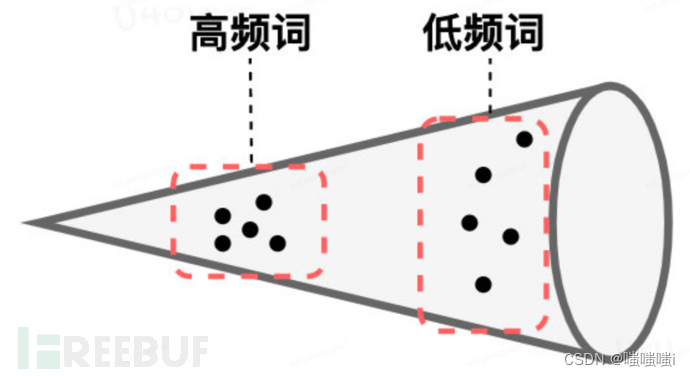
各向异性(Anisotropic)犹如词嵌入领域的一道独特的风景线:它意味着词向量在向量空间中呈现出一种定向的、非均匀的分布,仿佛一个精致的锥形结构(锥形体的形象并不完全准确,但确实揭示了其方向敏感的特性)。
它可能导致向量过于密集,相似向量间的余弦相似度过高,缺乏理想的分散均匀性。理想的情况是,向量既对齐,又均匀,也就是呈现出各向同性的特性,如图所示(理想表示与各向异性缺点的对比)。
各向同化是一个有效的方法,如BERT-flow通过校准分布至高斯分布,达到各向同性的目标。另一种策略是白化操作,通过SVD分解后旋转缩放,使向量接近标准正态分布。
Bert 词向量存在各向异性(不同方向表现出的特征不一致),高频词分布在狭小的区域,靠近原点,低频词训练不充分,分布相对稀疏,远离原点,词向量整体的空间分布呈现锥形。















 23万+
23万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









