








1 概述
今天我们来谈一谈Spark中的窄依赖和宽依赖。RDD大家应该有一定的理解了,弹性的分布式数据集,这里的弹性依赖于RDD之间的依赖关系,即使数据丢失也能重新计算。RDD之间的依赖关系又分为窄依赖和宽依赖,那到底什么是窄依赖什么是宽依赖呢?带着这个问题进入我们今天的学习。
2 窄依赖和宽依赖
2.1Lineage血统
Lineage保存了RDD的依赖关系。 RDD只支持粗粒度转换,即在大量记录上执行的单个操作。将创建RDD的一系列Lineage(即血统)记录下来,以便恢复丢失的分区。RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
2.2窄依赖
窄依赖定义:一个父RDD的partition至多被子RDD的某个partition使用一次。
读起来试试感觉不是那么容易理解哈,下面我们配一张图小伙伴们对着理解这句话就容易了。
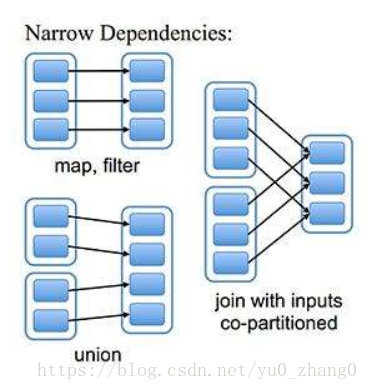
哪些操作是窄依赖呢,图上也有说明:对于map,filter,union ,join(co-partitioned)制定了父RDD中的分片具体交给哪个唯一的子RDD。这些都是窄依赖,不会产生shuffle的。
2.3 宽依赖
宽依赖定义: 一个父RDD的partition会被子RDD的某个partition使用多次。
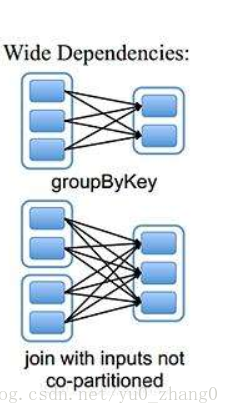
宽依赖是会产生shuffle的,对于groupByKey,join with inputs not co-partitioned,xxbykey(通过key分发都会产生shuffle)
2.4窄依赖于宽依赖对比
- 宽依赖往往对应着shuffle操作,需要在运行过程中将同一个父RDD的分区传入到不同的子RDD分区中,中间可能涉及多个节点之间的数据传输;而窄依赖的每个父RDD的分区只会传入到一个子RDD分区中,通常可以在一个节点内完成转换。
- 当RDD分区丢失时(某个节点故障),spark会对数据进行重算。
对于窄依赖,由于父RDD的一个分区只对应一个子RDD分区,这样只需要重算和子RDD分区对应的父RDD分区即可,所以这个重算对数据的利用率是100%的;
对于宽依赖,重算的父RDD分区对应多个子RDD分区,这样实际上父RDD 中只有一部分的数据是被用于恢复这个丢失的子RDD分区的,另一部分对应子RDD的其它未丢失分区,这就造成了多余的计算;更一般的,宽依赖中子RDD分区通常来自多个父RDD分区,极端情况下,所有的父RDD分区都要进行重新计算。
如下图所示,b1分区丢失,则需要重新计算a1,a2和a3,这就产生了冗余计算(a1,a2,a3中对应b2的数据)。
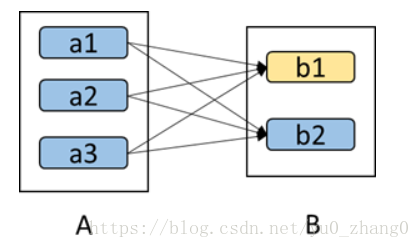
总结: 区分这两种依赖很有用。首先,窄依赖允许在一个集群节点上以流水线的方式(pipeline)计算所有父分区。例如,逐个元素地执行map、然后filter操作;而宽依赖则需要首先计算好所有父分区数据,然后在节点之间进行Shuffle,这与MapReduce类似。第二,窄依赖能够更有效地进行失效节点的恢复,即只需重新计算丢失RDD分区的父分区,而且不同节点之间可以并行计算;而对于一个宽依赖关系的Lineage图,单个节点失效可能导致这个RDD的所有祖先丢失部分分区,因而需要整体重新计算。
- 窄依赖的函数有:map, filter, union, join(父RDD是hash-partitioned ), mapPartitions, mapValues
- 宽依赖的函数有:groupByKey, join(父RDD不是hash-partitioned ), partitionBy
2.5Stage过程的理解
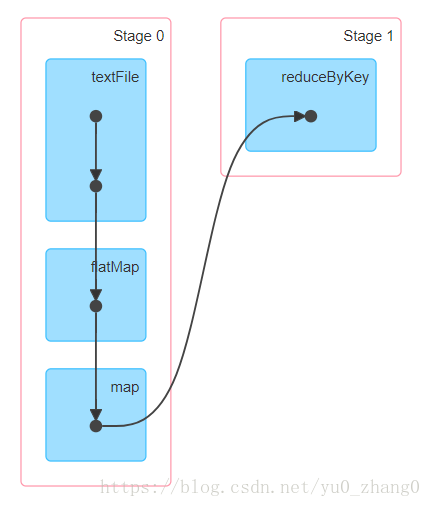
进行如下操作,通过UI界面查看DAG图:
sc.textFile("file:///home/hadoop/data/input.txt").flatMap(_.split("\t")).map((_,1)).reduceByKey(_+_).collect
- 一些基本概念
- 一个job中会有n个stage,每个stage对应n个task,task数量适合partition相对应的,stage是提交任务的最小单位。
- 在spark中,Task的类型分为2种:ShuffleMapTask和ResultTask;简单来说,DAG的最后一个阶段会为每个结果的partition生成一个ResultTask,即每个Stage里面的Task的数量是由该Stage中最后一个RDD的Partition的数量所决定的!而其余所有阶段都会生成ShuffleMapTask;之所以称之为ShuffleMapTask是因为它需要将自己的计算结果通过shuffle到下一个stage中;也就是说图2中的stage1和stage2相当于mapreduce中的Mapper,而ResultTask所代表的stage3就相当于mapreduce中的reducer。
-
解析DAG图
上图产生了2个stage,那这2个stage是怎么划分的呢?上面我们说了窄依赖是不是产生shuffle的宽依赖才会产生shuffle,如果job中有多次shuffle,那么每个shuffle之前都是一个stage。这里的reduceByKey产生了shuffle所以划分为两个stage,而在reduceByKey之前的flatMap和map操作是窄依赖所以划分为一个stage,所以一共2个stage。总的来说n个shuffle就会产生(n+1)个stage。 -
补充
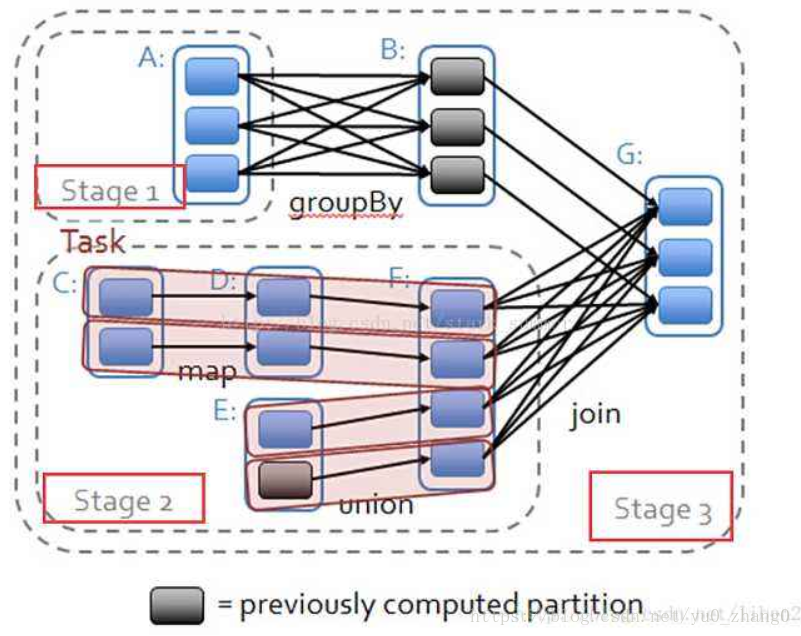
这里是网上找的一个图片,大家试着能不能理解呢?
总结,至此相信大家对于依赖有了一定的了解了吧,通过DAG图进行了一个详细的说明,可能这里也涉及到了shuffle的过程,在这之前大家可以先去看看mr的计算流程对于spark的shuffle会有一个更好的理解。

















 2964
2964

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









