






第三章-传输层学习开始于8/15
目录
案例:ATM ABR(available bit rate)拥塞控制
3.1 概述和传输层服务
传输服务和协议:
为运行在不同主机上的应用进程提供通讯服务
传输协议运行在端系统:
发送方:将应用层的报文分成报文段,然后传递给网络层
接收方:将报文段重组成报文,然后传递给应用层
传输层协议:TCP、UDP
网络层服务:主机之间的逻辑通讯
传输层服务:进程之间的逻辑通讯
传输层依赖网络层提供的服务,并对服务的某些方面进行加强,如:可靠性(丢失、乱序、加密)
但有些方面不可加强,如:延迟、吞吐量(带宽)
类比:ann家和bill家各12个孩子进行通信,可以在寄信端打包(复用),邮政公司送达后再拆开,分发(解复用)
3.2 多路复用和解复用
TCP:
原先的message通过头部加入源端口和目标端口的信息,封装成TCP段,随后加入源和目标的IP信息,传给IP段,在打到对方去;对方通过四个信息找到socket,随后找到对应的进程
UDP:
向下传:1.message 2.UDP socket(含源的IP和端口号) 3.cad,包含目标的IP和端口号
3.3 无连接传输UDP
UDP:user datagram protocol
报文段可能:丢失、乱序
无连接:发送端和接收端都没有握手、每个UDP报文段被独立处理(因此快、开销小)
UDP的校验和:
目标:检测在被传输报文段中的差错
发送方:
将报文段的内容视为16比特的整数
校验和:报文段的加法和
发送方将校验和放在UDP的校验和字段中
接收方:
计算接受到的报文段的校验和
检查计算出的校验和与校验和字段的内容是否相等:
不相等——检测到差错
相等——没有检测到差错,但也许还是会犯错(残存错误)
3.4 可靠数据传输(RDT)的原理
底层channel的不可靠性会决定协议实体的复杂性
接下来采取渐增式开发rdt的发送方和接收方,并且使用有限状态机FSM方法:
rdt1.0:在可靠信道上的可靠数据传输
下层的信道是完全可靠的:不出错,不丢失
发送方和接收方的FSM:发送方将数据发送到下层信道;接收方从下层信道接收数据
rdt2.0:具有比特差错的信道
下层的信道可能会出差错:将分组中的比特反转
问题:怎样从差错中恢复?
接收方通过确认(ACK)和否定确认(NAK)告知发送方分组是否被正确接收
2.0的新机制:采用差错控制编码进行差错检测
发送方差错控制编码、缓存;
接收方用编码检错;
接收方发送反馈;
发送方收到反馈相应动作
引入rdt2.1:带序列号的协议
2.0的致命缺陷:如果ACK/NAK出错?
发送方不知道接收方发生了什么(出错后有可能既不是ACK也不是NAK)
此时发送方究竟是重传还是不重传?
引入新的机制:序列号(实际上0,1两个就够了,因为一次只发送一个未确认的分组)
发送方在每个分组中加入序号,倘若ACK/NAK出错,重发当前分组
如果是ACK,接收方丢弃分组;如果是NAK,重复进行校验(但是接收方不知道发送方是否正确接受到了ACK/NAK)
解决办法是:如果ack出错,接收方下一次应该收到的是P0,而非P1(说明ack被接受)
引入rdt2.2:无NAK协议
功能同2.1,但是只是用ACK(此时ACK需要编号)
接收方对最后正确接收的分组发ACK,以代替NAK(接收方必须显示的包含被正确接受分组的序号)
当收到重复的ACK(如二次收到ACK0)时,发送方与收到NAK时采取相同的动作:重传当前分组
为后续一次能够发送多个数据单位做准备
即用带序号的正向确认,去取代每一个序号的正向、反向确认,数据量减少一半
rdt3.0:具有比特差错和分组丢失的通信
假设:下层信道可能会丢失分组(数据或ACK)
数据丢失后,发送方和接收方都在等待对方新的消息而决定下一步的行动,这样会死锁
增加新机制:超时重传(时延大概比一个来回多一些)
超时重传有可能带来数据重复的问题(ACK未发送成功时),重复问题可通过序列号解决
但是说到底,停-等协议的效率比较低,因此需要改进成流水线形式(pop line)
流水线协议
允许发送方在未得到对方确认的情况下,一次发送多个分组
必须增加序号的范围;
在发送方/接收方要有缓冲区;
发送方缓冲:未得到确认,有可能要重传
接收方缓冲:上层用户取数据速率≠接受数据速率;或接受的数据乱序,需要排序交付
两种通用流水线协议:回退N步(GBN:go back N)和选择重传(SR:selective repeat)
铺垫:滑动窗口协议
将发送窗口(SW)和接收窗口(RW)大小和1比较
SW=1 RW=1 即停-等协议
SW>1 RW=1 即GBN协议
SW>1 RW>1 即SR协议
后两者都是流水线协议
发送缓冲区:内存中的一个区域,落入缓冲区的分组可以发送
功能:用于存放已发送,但是没有得到确认的分组
必要性:需要重发时可用
发送缓冲区的大小:一次最多可以发送多少未经确认的分组
停-等协议:=1
流水线协议:>1,但是必须合理,不能很大
发送缓冲区的分组:
未发送的:落入发送缓冲区的分组,可以连续发送出去;
已发送、等待确认的:发送缓冲区的分组只有得到确认才能够被删除
发送窗口:
定义:发送缓冲区内容的一个范围,是缓冲区的子集
所以有:发送窗口的最大值≤发送缓冲区的值
开始:没有发送任何一个分组,此时前沿等于后沿,发送窗口的尺寸=0
每发送一个分组,前沿前移一个单位(每发送一个分组,都要启动一个定时器)

前沿移动的极限:不能超过发送缓冲区
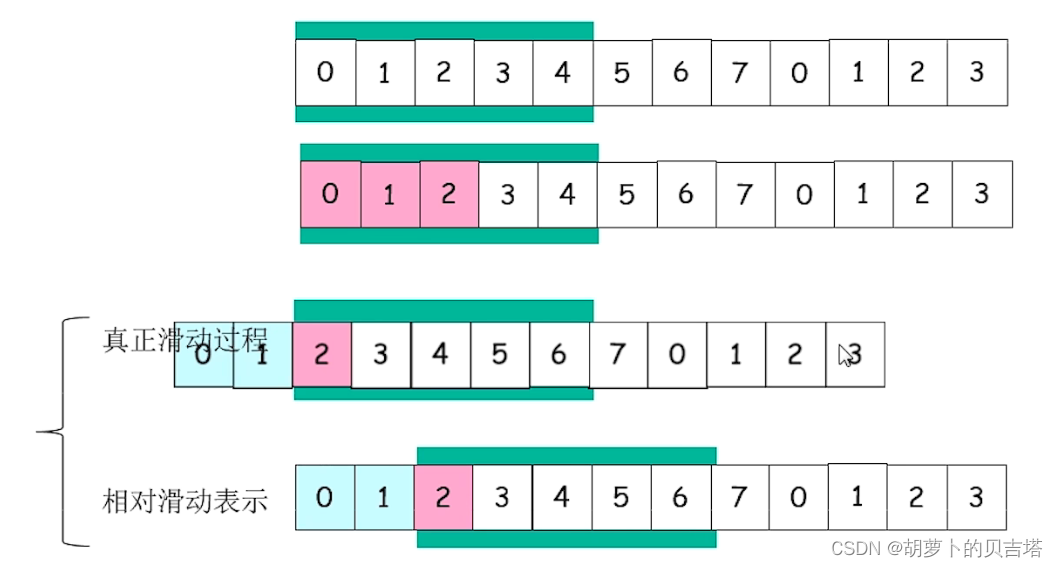
绿色框表示发送缓冲区(能发,但未发),红色部分表示发送窗口 (能发,已发,未确认)
滑动过程应当是类似队列,得到确认的部分出窗口;
但是为了直观,采用滑动窗口的后沿移动表示
接收窗口:
在接收方,接收窗口即接收缓冲区
定义:用于控制那些分组可以被接收,只有收到的分组序号落入接收窗口内才允许接受
接受窗口尺寸Wr=1,只能顺序接收(GBN);>1,则可以乱序接受(SR)(但是提交给上层需要按序)
对于顺序接收,含序号的ACK相当于累计确认,在收到ACK3后表示含3之前的都确认过了
对于乱序接收:每接收一个分组就要向对方发送该分组的ACK(独立确认);
低序号的分组到来,接收窗口滑动
高序号分组先到,缓存但不交付(等低序到来再顺序上交),也不滑动
GBN和SR协议的异同:
相同:
SendWindow>1;
一次可以发送多个未经确认的分组
不同:
GBN:
RW=1,接收端只能顺序接收;一旦一大组有一个分组没发出去,需要重新发送
SR:
RW>1,可以乱序接收;如果有一个分组没发出去,只需要选择性重传该分组即可
3.5 面向连接的传输:TCP
TCP的特点:
1.点对点,一个发送方,一个接收方
2.可靠的,按顺序的字节流;但是没有报文边界
3.管道化(流水线):TCP能进行拥塞控制和流量控制设置窗口大小
4.发送和接收缓存
5.全双工数据:在同一连接中,数据流双向流动(MSS:最大报文段大小)
6.面向连接:数据交换之前需要进行握手,初始化双方状态变量
7.有流量控制,发送方不会淹没接收方
TCP报文段结构
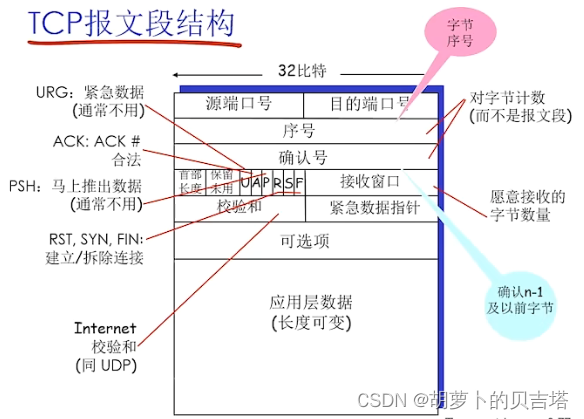
1.序号:表示TCP body部分首字节在整个字节流中的偏移量X(其后每一个是X+n*MSS长度),是字节的序号,而非PDU的序号(即上一节的包的序号);该序号在TCP建立连接时确定
2.确认号:期望从另一方收到的下一个字节的的序号(采用累计确认的方法)
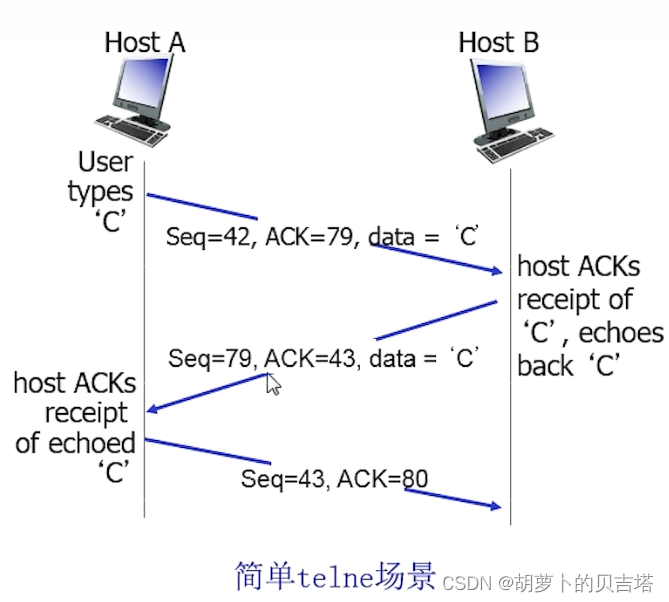
参考下图以加深理解:
如何设置TCP超时定时器:比RRT(往返延时)要长,但是RRT会变化,因此采取自适应的方法
如果设置太短,导致太早超时,造成不必要的重传
设置太长,对报文段丢失反应太慢,消极
采用sample RTT形式,对过去的一段时间进行采样,得到合适的RRT时间(越靠前的时间占比越呈指数型下降)
TCP可靠数据传输
TCP在IP不可靠服务的基础上建立了rdt,某些方面像GBN,某些方面像SR
如:只有一个超定时器;累计确认(GBN);
超时重传只发送最早的未确认的段(类似SR);
对于乱序到来的报文段,TCP没有专门的应对策略,可以丢弃,也可以缓存
TCP的ACK只对顺序到来的最后一个字节+1;
例如:发送方发92,8字节,接收方应该回复ACK100;随后发送方又发了100,20字节
但是超时定时器设置较短,在ACK100还没回来时候就超时,重新发送92,8字节;
过一会接收方收到100,20字节,开始发送ACK120;
此时超时重发的92,8字节发送到了,此时接收方不发送ACK100,而发送ACK120(想想累计确认,这里说明119及以前都没问题)
快速重传:比超时重发来的还要快一些的重传
应用场景:某些情况下超时周期比较长,重传丢失报文段之前的延迟比较大
(它假设跟在被确认数据后面的数据丢失了:第1个ACK是正常的,收到第2个ACK表明收到了该段后面的乱序段,收到第3、4个ACK表示收到后面其他的乱序段,那么大概率这一段丢失了)
方法:通过重复的ACK检测报文丢失
如果发送方收到了同一数据的3个冗余ACK,则重传最小序号的段

TCP流量控制
防止发送方发送太快,超过接收方处理能力(接收方缓冲区溢出)
具体而言:接收方在向发送方发TCP段,头部的rwnd字段通告空闲缓冲区大小(通过捎带方式)
TCP连接建立
在正式交换数据之前,双方握手建立通信关系
三次握手!
两次握手的问题
如果只有两次握手,可能会导致服务器出现虚假的半连接状态:
案例如下:
1.客户端向服务器发出连接建立请求;
2.服务器回应连接建立请求
3.但是在回应请求到来之前,客户端请求的超定时器超时重传
4.客户端发送另一个请求,然后收到第一个请求的回应
5.假如数据传输也超时重传,那么客户端部分已经结束,但是服务器端还收到了客户端的另一个建立请求,处于虚假连接状态接收数据,耗费资源
TCP三次握手:
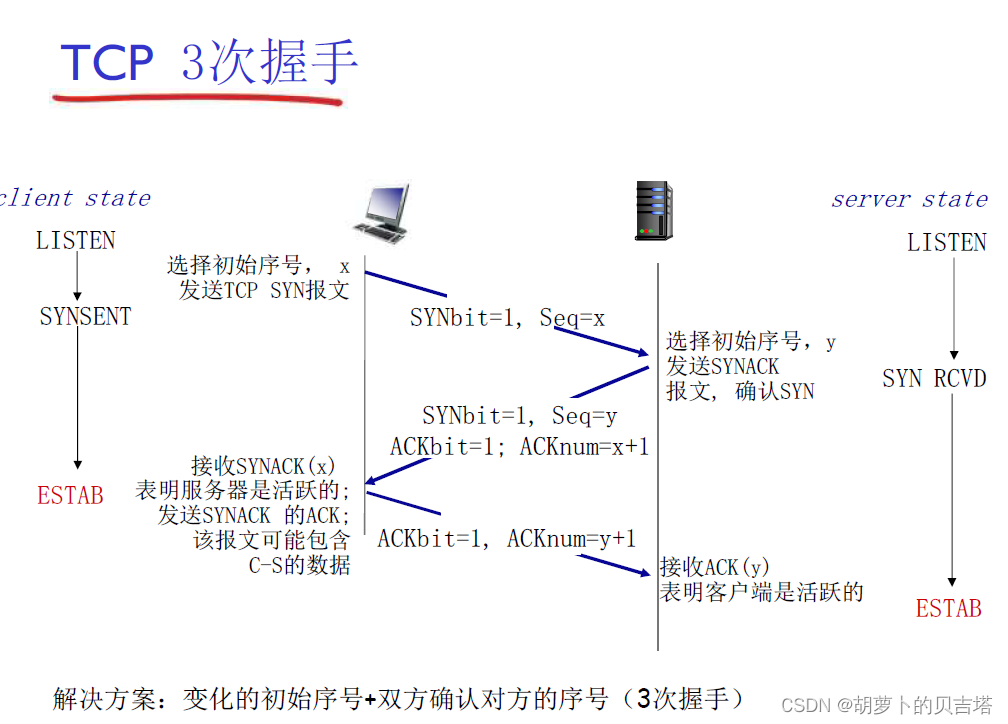
1.客户端发送连接建立请求,并且发送初始位序号
2.服务器接收请求并发出连接建立确认,同时捎带自己的初始位序列号
3.客户端接收序列号并确认,同时开始第一次数据传输
TCP关闭连接:
两个方向连接对称拆除
但是TCP连接释并不完美,即最后一次的确认(红兵、白兵、山谷)
3.6 拥塞控制原理
拥塞的表现:分组丢失(路由器缓冲区溢出)、分组经历比较长的延迟(排队)
拥塞的代价:
1.为了达到有效的输出,网络需要付出更多代价(重传)
2.网络中存在一些没有必要的重传,链路中包含多个分组的拷贝(排队中超时的分组)
如果不加控制,重传机制会使网络堵塞程度进一步加深
3.如果分组丢失,就浪费了这个分组上游传输能力(路由的前几跳)
拥塞控制方法:
1.端到端拥塞控制
TCP的方法
没有来自网络的显示反馈
端系统根据延迟和丢失事件推断是否有拥塞
2.网络辅助的拥塞控制
路由器提供给端系统反馈信息
案例:ATM ABR(available bit rate)拥塞控制
一直弹性服务
如果发送端路径轻载,那么可以使用可用宽带
如果发送端路径拥塞,其发送速率会被限制在最小保障速率
3.7 TCP拥塞
机制
TCP是典型的端到端的网络拥塞控制
路由器不向主机反馈拥塞相关的信息--路由器负荷较轻、网络核心结构简单
端系统根据自身得到的信息判断是否发生拥塞,从而采取行动
拥塞控制的问题:
如何检测拥塞?
轻微拥塞/拥塞?
控制策略?
发生拥塞时如何动作、降低速率?
缓解拥塞时如何动作、增加速率?
拥塞感知
发送端如何探测拥塞?
1.某个段超时(丢失事件):
到了超时时间,而某个段的确认没有来
原因1.网络拥塞导致路由器缓冲区满,被丢弃(此时需要降低发送速度)
原因2.由于出错,校验未通过被丢弃(此时降低速度反而导致效率低)
原因1比原因2概率大得多,有超时就认为拥塞,虽然可能误判,但总体概率和方向都是对的
2.某个段出现3个冗余ACK(轻微拥塞)
网络此时还能够进行一定量的传输,因为乱序的也到达了
拥塞控制策略
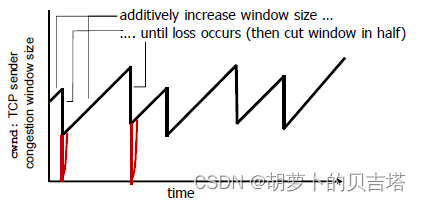
概述:慢启动、线性增,乘性减、超时事件后的保守策略
控制发送端发送速率:
其中
congestwindow:发送方在对方未确认的情况下,可以往网络中注入的字节
RRT:往返延迟
粗略的控制发送方注入网络的速率
发生超时时候:
congwin降为1MSS,进入慢启动状态,每过一个RTT,congwin加倍到原congwin/2(加倍增加),随后每个RTT加1(线性增加)
收到3个冗余ACK:
congwin降为之前的一半,随后每个RTT加1(线性增加)
通常,拥塞控制和流量控制一起作用,发送端发送,但是未确认的量不能超过接收窗口,以满足流量控制的要求。即:取congwin和rewin的最小值
注意:为什么是降到congwin/2,因为congwin是加倍增长的,直到发生拥塞,此时的安全值是拥塞前的一个RTT内的值,即congwin/2
因为慢启动状态是指数增长,需要的时间很短可以忽略不计,宏观上可以认为congwin的数量是呈锯齿状
TCP的公平性:
如果K个TCP会话,分享一个链路带宽为R的瓶颈链路,每一个会话的有效带宽为
这是由TCP拥塞控制,慢启动和线性增长导致的
(前提是TCP的RTT都差不多,否则RTT小的慢启动快,会抢带宽)
第三章结束于2023/8/24















 4543
4543











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









