







写在前头:
这是小鱼上的网课整理来的笔记,希望可以帮助大家更好的理解编译原理这门课!
一、字母表
字母表 ∑ 是一个有穷符号集合
符号:字母、数字、标点符号、…
1️⃣乘积
∑1∑2 ={ab|a ∈ ∑1, b ∈ ∑2}
例:
{0, 1} {a, b} ={0a, 0b, 1a, 1b}
2️⃣n次幂
∑0 ={ ε }
∑n=∑n-1 ∑, n ≥ 1
例:
{0, 1}3 ={0, 1} {0, 1} {0, 1} ={000, 001, 010, 011, 100, 101, 110, 111}
字母表的n次幂:长度为n的符号串构成的集合
3️⃣正闭包
∑+ = ∑ ∪ ∑2 ∪ ∑3 ∪ …
例:
{a, b, c, d }+ = {a, b, c, d, aa, ab, ac, ad, ba, bb, bc, bd, …, aaa, aab, aac, aad, aba, abb, abc, …}
字母表的正闭包:长度正数的符号串构成的集合
4️⃣克林闭包
∑*= ∑0 ∪ ∑+ = ∑0 ∪ ∑ ∪ ∑2 ∪ ∑3 ∪ …
例:
{a, b, c, d }* = {ε, a, b, c, d, aa, ab, ac, ad, ba, bb, bc, bd, …, aaa, aab, aac, aad, aba, abb, abc, …}
字母表的克林闭包:任意符号串(长度可以为零)构成的集合
二、串
定义:设∑是一个字母表,vx∈∑*,x称为是∑上的一个串
串是字母表中符号的一个有穷序列
串s的长度,通常记作|s|,是指s中符号的个数
例:
|aab|=3
空串是长度为0的串,用 ε(epsilon)表示
|ε|= 0
1️⃣串上的运算——连接
定义:如果 x和y是串,那么x和y的连接是把y附加到x后面而形成的串,记作xy
例如,如果 x=dog且 y=house,那么xy=doghouse
空串是连接运算的单位元,即对于任 何串s都有,εs = sε = s
设x,y,z是三个字符串,如果 x=yz, 则称y是x的前缀,z是x的后缀
2️⃣串上的运算——幂
串s的幂运算
s0= ε
sn= sn-1s, n ≥1
s1 = s0s= εs = s , s2= ss , s3 = sss , …
串s的n次幂:将n个s连接起来
三、文法的形式化定义
我们看看下面这幅图,在英语中举例子

图中可以明显的看出哪部分是基本符号,哪部分是语法成分
G = (VT, VN , P , S )
VT:终结符集合(VT∩VN=Φ)
终结符是文法所定义的语言的基本符号,有时也称为token
例:
VT= { apple, boy, eat, little }
VN:非终结符集合
非终结符是用来表示语法成分的符号, 有时也称为“语法变量”
例:
VN= {<句子>, <名词短语>, <动词短语>, <名 词>, … }
P :产生式集合
产生式描述了将终结符和非终结符组合成串的方法产生式的一般形式
α→β
读作:α定义为β
α∈(VT∪VN)+,且α中至少包含VN中的一个元素:称为产生式的头 (head)或左部(left side)
β∈(VT∪VN)* :称为产生式的体(body)或右部(right side)
例:

S :开始符号
S∈VN,开始符号表示的是该文法中最大的 语法成分
例:
S=<句子>
写法:G =( { id, +, *, (, ) }, {E}, P, E )
P={ E → E + E ,
E → E * E ,
E → ( E ) ,
E → id }
约定:不引起歧义的前提下,可以 只写产生式
G : E → E + E
E → E * E
E → ( E )
E → id
产生式的简写
对一组有相同左部的α产生式
α→β1 | β2 | … | βn
读作:α定义为β1,或者β2,…,或者βn
β1,β2,…,βn称为α的候选式
四、符号约定
下述符号是终结符

下述符号是非终结符

字母表中排在后面的大写字母(如X、Y、Z) 表示文法符号(即终结符或非终结符)
字母表中排在后面的小写字母(主要是u、v、. . . 、z) 表示终结符号串(包括空串)
小写希腊字母,如α、β、γ,表示文法符号串(包括空串)
除非特别说明,第一个产生式的左部就是开始符号
五、推到和归约
给定文法G=(VT,VN , P , S ),如果 α→β ∈ P,那么 可以将符号串γαδ中的α替换为β,也就是说,将γαδ 重写(rewrite)为γβδ,记作 γαδ =>γβδ。此时,称文法中的符号串 γαδ 直接推导(directly derive)出 γβδ
如果α0=>α1,α1=>α2,α2=>α3,…,αn-1=>αn
称符号串 α0经过n步推导出αn,可简记为α0=>n αn
=>+表示“经过正数步推导”
=>*表示“经过若干(可以是0)步推导”
而归约则相反
六、句型和句子
如果 S =>* α,α∈(VT∪VN)*,则称α是G的一个句型
一个句型中既可以包含终结符,又可以包含非终结符,也可能是空串
如果 S =>* w,w ∈VT*,则称w是G的一个句子
句子是不包含非终结符的句型

七、语言的形式化定义
由文法G的开始符号S推导出的所有句子构成 的集合称为文法G生成的语言,记为L(G )
L(G )= {w | S =>* w,w∈ VT* }

图中可看出,L表示字母,D表示数字,T又有字母又有数字组成,为字母数字串,右边为推导式,该文法生成的语言是标识符
八、文法分类体系
1️⃣0型文法α → β (无限制文法/短语结构文法
)
∀α → β∈P, α中至少包含1个非终结符
a和β可以是任意的文法符号串,当然a不能是空字符串
2️⃣1型文法α → β
上下文有关文法
∀α → β∈P,|α|≤|β|
产生式的一般形式: α1Aα2 → α1βα2 ( β≠ε )
3️⃣2型文法α → β
上下文无关文法
∀α → β∈P,α ∈ VN
产生式的一般形式:A→β
4️⃣3型文法α → β
正则文法
右线性文法: A→wB 或 A→w
左线性文法: A→Bw 或 A→w
左线性文法和右线性文法都称为正则文法
九、四种文法之间的关系
1️⃣逐级限制
0型文法:α中至少包含1个非终结符
1型文法(CSG):|α|≤|β|
2型文法(CFG):α ∈ VN
3型文法(RG):A→wB 或 A→w (A→Bw 或A→w)
2️⃣逐级包含

十、CFG的分析树

根节点的标号为文法开始符号
内部结点表示对一个产生式A→β的应用,该结点的标号是此产生式左部 A 。该结点的子结点的标号从左到右构成了产生式的右部 β
叶结点的标号既可以是非终结符,也可以是终结符。从左到右排列叶节点得到的符号串称为是这棵树的产出或边缘
给定一个推导 S => α1=>α2=>…=> αn ,对于推导 过程中得到的每一个句型αi,都可以构造出一个 边缘为αi的分析树
十一、短语
给定一个句型,其分析树中的每一棵子树的边缘称为该句型的一个短语
如果子树只有父子两代结点,那么这棵子树的边缘称为该句型的一个直接短语

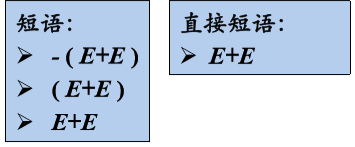
直接短语一定是某产生式的右部 但产生式的右部不一定是给定句型的直接短语
今天的学习笔记就分享到这里!!
PS:小鱼学习网站是中国大学MOOC(慕课)















 878
878











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









