






之前有一个基于 Vuepress 的博客,优点是配置简单、快速上手搭建;缺点是学不到太多东西,而且感觉千篇一律;刚好前一段时间比较闲,就动手搭建了这个项目。
什么是 No Server 的博客
no server 可以理解为无后端控制,只提供静态网站服务,这个概念是从 vuepress 那里学来的,因为缺乏后端相关的知识,所以网站一直部署在 Github Pages 中,搭建这个博客也希望能继续使用 github pages 进行网站部署。
vuepress 使用的路由模式是 History,history 模式下在其他页面刷新是会 404 的,因为没有对应的 html 文件,一般是后端配置所有的页面请求都响应为 index.html,但 github pages 只是一个静态托管平台,做不了这样的操作。vuepress 采取的方案是预渲染完整的 html,存在真实的 html 访问自然不会 404,且 SEO 也会更优秀。
vuepress 为每个预渲染的 html 注入主应用程序的 js 文件,在加载 html 后,将 html 和 Vue 实例进行水合,成为一个 SPA 程序,这样在享受到初始极速的加载体验后还能使用完整的 spa 程序特性。
通过上述两步操作,vuepress 实现了一个 no server 但体验不输 SSR 渲染的博客系统,而我们则参考这种思路完成自己的博客。
搭建项目架构
一些千篇一律的配置这里不展开介绍,只介绍自己认为学到了东西的工程配置。先说下基础的架构:Vite + PNPM + Typescript + React + MDX。
Browserslist
Browserslist 是让你能够配置项目运行的目标浏览器的工具,本身并不提供语法降级功能,那些是 Babel、PostCSS 的工作,而 browserslist 则告诉这些工具你的项目需要在哪些浏览器上工作,适配了 browserslist 规范的前端工具会自动为你完成降级。
我们可以通过在项目根目录中新建 .browserslistrc 并写入规则来实现,比如这个博客项目中写入了以下内容:
# Browsers that we support
Chrome >= 87
Firefox >= 78
Safari >= 14
Edge >= 88
Opera >= 80
defaults and fully supports es6-module
前面 5 个规则指定了对应的浏览器要大于等于什么版本,而最后一条规则指定了要运行在支持 es6 模块的浏览器之上。
UnoCSS
UnoCSS 是现在很火的原子化 css 构建工具,项目一开始使用了,简单讲一下配置。
// uno.config.ts
import {
defineConfig,
presetIcons,
presetAttributify,
presetTypography,
presetUno,
presetWebFonts,
transformerDirectives,
transformerVariantGroup,
transformerAttributifyJsx
} from 'unocss';
export default defineConfig({
// 组合多个预设
shortcuts: [
// ...
],
// 主题
theme: {
colors: {
// ...
}
},
presets: [
presetUno(),
// 支持以属性方式定义 uno 预设,<div text="xl"></div>
presetAttributify({
prefix: 'uno-', // 为了防止和 react 属性冲突,设置统一前缀 <div uno-text="xl"></div>
prefixedOnly: true // 始终以前缀开头
}),
// 图标解析,这里使用 @iconify-json/ph 图标集,pnpm add -D @iconify-json/ph
presetIcons({
prefix: 'icon-', 前缀,使用 <div uno-icon="iconName"></div>
extraProperties: {
display: 'inline-block',
'vertical-align': 'middle'
},
collections: {
// 导入图标集
ph: () => import('@iconify-json/ph/icons.json').then((i) => i.default)
}
}),
// 排版预设,文章类使用
presetTypography()
],
transformers: [
transformerAttributifyJsx(),
transformerDirectives(),
transformerVariantGroup()
]
});
我们知道原子化 css 比较不好的点就是容易在模板中堆积大量的类名,unocss 提出了一种解决方式:以属性的方式编写原子类;比如 <div className='mr-10px'></div> 可以写成 <div mr="10px"></div>,为了防止和 react jsx 属性冲突一般还会设置前缀,同时需要覆写默认的 ts 类型:
import type { AttributifyNames } from 'unocss/preset-attributify';
type Prefix = 'uno-'; // change it to your prefix
declare module 'react' {
interface HTMLAttributes
extends Partial<Record<AttributifyNames<Prefix>, string>> {}
}
另外需要注意,如果你的项目引入了 ESLint 且配置了 elint-plugin-react,那么 unocss 属性写法是会报 lint 错误的,因为检查到了非法的 dom 属性,要么关掉对应的规则,要么将所有 unocss 属性(2500 条左右)添加进忽略,比如下面这样:
/** @type {import('eslint').ESLint.ConfigData} */
module.exports = {
// other options in here...
rules: {
'react/no-unknown-property': [
'error',
{
ignore: [
'uno-container',
'uno-flex',
'uno-block',
// other property in here...
]
}
]
}
}
这个项目最终是将 unocss 移除掉的,倒不是不好用,只是不适合;对于自己的项目比较看重代码可读性,原子化 css 需要在 jsx 编写大量的 css 类,还是会有点影响;而且对于主题切换不是很友好,感觉在 css 中定义变量的方式对于主题切换更方便一点。
MDX
MDX 是号称让 Markdown 步入组件时代的工具,允许我们在 markdown 中编写 jsx 代码并嵌入组件。
我是希望能够继承 vuepress 模式的,即一个 markdown 代表一个路由页面;最开始的想法是通过 markdown-it 在编译时构建生成页面,但研究过程中发现了 mdx,便转为了这个库来实现。
mdx 提供了 Rollup 的插件包,在 vite 中插件配置如下:
import mdx from '@mdx-js/rollup';
import remarkFrontMatter from 'remark-frontmatter';
import remarkMdxFrontmatter from 'remark-mdx-frontmatter';
import remarkGfm from 'remark-gfm';
import remarkBraks from 'remark-breaks';
import remarkEmoji from 'remark-emoji';
import { remarkMdxToc } from 'remark-mdx-toc';
import rehypePrism from '@mapbox/rehype-prism';
import type { ConfigEnv, UserConfig } from 'vite';
export default ({ command, mode }: ConfigEnv): UserConfig => {
return defineConfig({
plugins: [
{
enforce: 'pre',
...mdx({
remarkPlugins: [
[remarkFrontMatter, 'yaml'],
remarkBraks,
remarkEmoji,
remarkMdxFrontmatter,
remarkGfm,
// @ts-expect-error this is normal, it's just a mismatch in the type definitions
remarkMdxToc
],
rehypePlugins: [
// @ts-expect-error this is normal, it's just a mismatch in the type definitions
[rehypePrism, { ignoreMissing: true, alias: { shell: 'sh' } }]
],
providerImportSource: '@/viewer/Provider.tsx'
})
},
// other plugins in here...
]
})
}
主要依赖了一系列的插件进行 markdown 功能增强,可以去对应的插件官网查看。
上述配置中我们通过 providerImportSource 替换默认的渲染元素,达到自定义的效果;providerImportSource 对应的路径应该是一个模块,且导出一个 useMDXComponents hooks:
import type { MDXComponents } from 'mdx/types';
export const useMDXComponents = (): MDXComponents => {
return {}
}
假设我们在 markdown 中有一个一级标题,那对应的 html 元素就是 h1,可以通过编写如下代码来替换默认的 h1 元素:
import type { MDXComponents } from 'mdx/types';
export const useMDXComponents = (): MDXComponents => {
return {
h1(props) {
return <h2 {...props}></h2>;
}
}
}
字体
一开始使用 阿里巴巴普惠体2.0,防止字体文件过大,只使用了 400 和 700 字重,可以通过以下的样式来控制只在必要的时机加载对应的字体:
@font-face {
font-family: 'AlibabaPuHuiTi-2';
font-weight: 400;
src:
url('/fonts/AlibabaPuHuiTi-2-45-Light/AlibabaPuHuiTi-2-45-Light.woff2')
format('woff2'),
url('/fonts/AlibabaPuHuiTi-2-45-Light/AlibabaPuHuiTi-2-45-Light.woff')
format('woff'),
url('/fonts/AlibabaPuHuiTi-2-45-Light/AlibabaPuHuiTi-2-45-Light.ttf')
format('ttf'),
url('/fonts/AlibabaPuHuiTi-2-45-Light/AlibabaPuHuiTi-2-45-Light.otf')
format('opentype'),
url('/fonts/AlibabaPuHuiTi-2-45-Light/AlibabaPuHuiTi-2-45-Light.eot')
format('eot');
}
@font-face {
font-family: 'AlibabaPuHuiTi-2';
font-weight: 700;
src:
url('/fonts/AlibabaPuHuiTi-2-75-SemiBold/AlibabaPuHuiTi-2-75-SemiBold.woff2')
format('woff2'),
url('/fonts/AlibabaPuHuiTi-2-75-SemiBold/AlibabaPuHuiTi-2-75-SemiBold.woff')
format('woff'),
url('/fonts/AlibabaPuHuiTi-2-75-SemiBold/AlibabaPuHuiTi-2-75-SemiBold.ttf')
format('ttf'),
url('/fonts/AlibabaPuHuiTi-2-75-SemiBold/AlibabaPuHuiTi-2-75-SemiBold.otf')
format('opentype'),
url('/fonts/AlibabaPuHuiTi-2-75-SemiBold/AlibabaPuHuiTi-2-75-SemiBold.eot')
format('eot');
}
这样当页面上渲染了 400 字重的文字时,就会去加载 font-weight: 400; 的字体。
最终是移除了中文的字体文件,毕竟中文实在是太多了,考虑到字重、斜体这些因素,一个完整的常见中文的字体文件可能有几百 MB 大小。
Icon
项目中一般都会需要一些图标来提升感官,基本是字体图标或 svg 图标,在使用 unocss 的过程中发现了 Iconify 这个项目,也希望在这个项目中用起来,以离线的方式。
将 svg 图标下载到本地,使用 vite-plugin-svg-icons 来简化引用 svg 图标的方式,vite-plugin-svg-icons 会将指定目录下的 svg 图标管理起来,并生成类似如下的 dom 结构:
<svg id="__svg__icons__dom__" xmlns="http://www.w3.org/2000/svg" xmlns:link="http://www.w3.org/1999/xlink">
<!-- 一个 symbol 标签就是一个图标 -->
<symbol viewBox="0 0 24 24" id="my-icon">
<path fill="currentColor" d="xxx"></path>
</symbol>
<!-- other symbol in here... -->
</svg>
symbol 标签类似一个类,类名为 my-icon,本身是不呈现在页面中的,我们可以通过 use 标签来实例化这个类:
<svg aria-hidden="true">
<use xlink:href="#my-icon" />
</svg>
这样就能在对应的 dom 位置中展示 my-icon 这个 svg 图标。
自定义路由
为什么要自定义路由而不使用 React Router?因为我想实现自己的路由页面切换逻辑,在看了大致的 react router 源码后我感觉他是做不到的。
之前我写了一个 react + react router 的演示项目,个人感觉页面切换时体验不好的点在于:
- 进入一个新的页面时,因为使用了
Lazy Component,react 要求必须渲染一个fallback元素,这会卸载掉原来的页面组件。 - 在加载新的页面之前一直展示
fallback元素,用户观感不好,也无法操作原有页面。
所以我一直在找可以不渲染 fallback 元素,让当前页面在下一个页面准备好之前始终存在的方式,而在研究时发现通过一种骚操作可以实现我想要的效果:
import { lazy } from 'react';
import { createBrowserRouter } from 'react-router-dom';
const Layout = lazy(() => import('./viewer/Layout.tsx'));
const router = createBrowserRouter([
{
path: '/',
element: <Layout />
}
]);
const navigate = router.navigate;
const navigateProxy: typeof router.navigate = async function navigateProxy(
to,
options
) {
if (typeof to === 'string') {
await import(to);
} else if (typeof to === 'object' && to?.pathname) {
await import(to.pathname);
}
return navigate(to, options);
};
router.navigate = navigateProxy;
本质就是利用浏览器缓存模块的特色,在加载前不真正执行路由跳转逻辑,在模块加载完成后再放行,此时 react 在内部去加载模块就不需要什么时间了,从而达到了目的。这种方式过于抽象,且没有可靠性,故放弃。
另一种想法是基于 Suspense 的工作原理来实施的,我们知道 Suspense 会获取到内部组件抛出来的 Promise,获取到 Promise 时会挂载 fallback,Promsie 决议时会还原,使用如下代码可以测试:
const Await = () => {
if (Math.random() > 0.5) {
throw new Promise((resolve) => setTimeout(() => resolve(''), 3000));
}
return <div>loaded</div>;
}
const App = () => {
return (
<Suspense fallback="loading...">
<Await />
</Suspense>
);
}
我的最初构想是通过高阶组件来捕获到 lazy 组件抛出的 Promise,如下:
const Layout = lazy(() => import('./viewer/Layout.tsx'));
const App = () => {
try {
const p = <Layout />;
} catch(err) {
console.log(err);
}
}
实际并没有效果,查看 lazy 函数的源码可以发现他只是做了一层标记,也并没有在 render 阶段抛出 Promise,所以想法半路被折断。
看了 《React 全家桶》 之后对路由页面切换的方式有一点了解,最终决定以自定义路由的方式来实现我的目的,这里我只讲大概的逻辑,很多东西只有自己去做了才能体会其中的细节。
假设我们有两个根页面 ViewLayout 和 CoderLayout,有一个包裹组件 Outlet,Outlet 可以通过路线来判断当前需要渲染哪个页面:
import ViewLayout from './ViewLayout';
import CoderLayout from './CoderLayout';
function Outlet() {
if (window.location.pathname === '/viewer') {
return <ViewLayout />
}
if (window.location.pathname === '/coder') {
return <CoderLayout />;
}
return null;
}
这其实就是路由切换的本质了,但真正实现起来是很多细节的,以我在这个项目中的自定义路由来说,大概实现了以下功能:
- 中心路由对象 router,以此为基准对外提供 API
- 可配置,类似 react router 的
createBrowserRouter - RouterProvider,通过 react context 提供 router 对象
- useHistory,编程式导航的 hook
- useLocation,获取当前路线及其他状态的 hook
- useRoutes,获取所有路线映射的 hook
- useScrollStore,滚动恢复的 hook
- Link,路由导航组件
- Outlet,消费路线的组件
在这个路由系统中,导航的过程是这样的:
- 导航 navigate
- 匹配路线 match route
- 加载路线对应的组件模块 load component (这个阶段不会去卸载原页面,体验会更好)
- 消费路线 consumption route
在每段路线中只能匹配一个组件,不可能一段路线匹配到了两个组件,比如 /viewer/articles 可以分为 /viewer 和 articles,他们是父子级的关系,即:
/* /viewer */
<Outlet>
{/* articles */}
<Outlet></Outlet>
</Outlet>
另外在父 Outlet 没有匹配到对应的组件时是不会去加载子 Outlet 的模块的,每个 Outlet 只需要关注自己需要消费的路线,不必关注后代路线。
Store
写前端项目基本离不开三件套:视图库、路由库、状态管理库;这里我选择使用 Zustand 作为项目的状态管理,因为确实简单方便,比 redux/toolkit 更容易上手。
这里不讲它的配置,大概说下 Store 如何与视图库进行交互的。以 redux 举例,我们知道他提供了 subscribe 方法,通过这个方法可以获取到状态变更的通知:
store.subscribe(() => {
// dosomething
});
在类组件中我们可以通过 this.forecUpdate() 方法来触发组件重渲染:
import store from './store';
class A extends PureComponent {
listener = () => {
this.forceUpdate();
};
unListener = () => void 0;
componentDidMount(): void {
this.unListener = store.subscribe(this.listener);
}
componentWillUnmount(): void {
this.unListener();
}
render(): ReactNode {
return <>{store.state.name}</>;
}
}
在函数式组件中 react 提供了 useSyncExternalStore hooks:
import store from './store'
function A() {
const state = useSyncExternalStore(store.subscribe, store.getState);
return <>{state.name}</>
}
useSyncExternalStore 会在内部调用 subscribe 方法并传入处理函数,当外部 store 状态变化时会调用处理函数,react 会自动为我们重渲染组件。
File System
这个项目我不光是想作为一个博客来开发的,还希望有一定的功能,第一个开发的功能就是利用 File System API 和 Origin private file system 实现的在线文件管理系统:
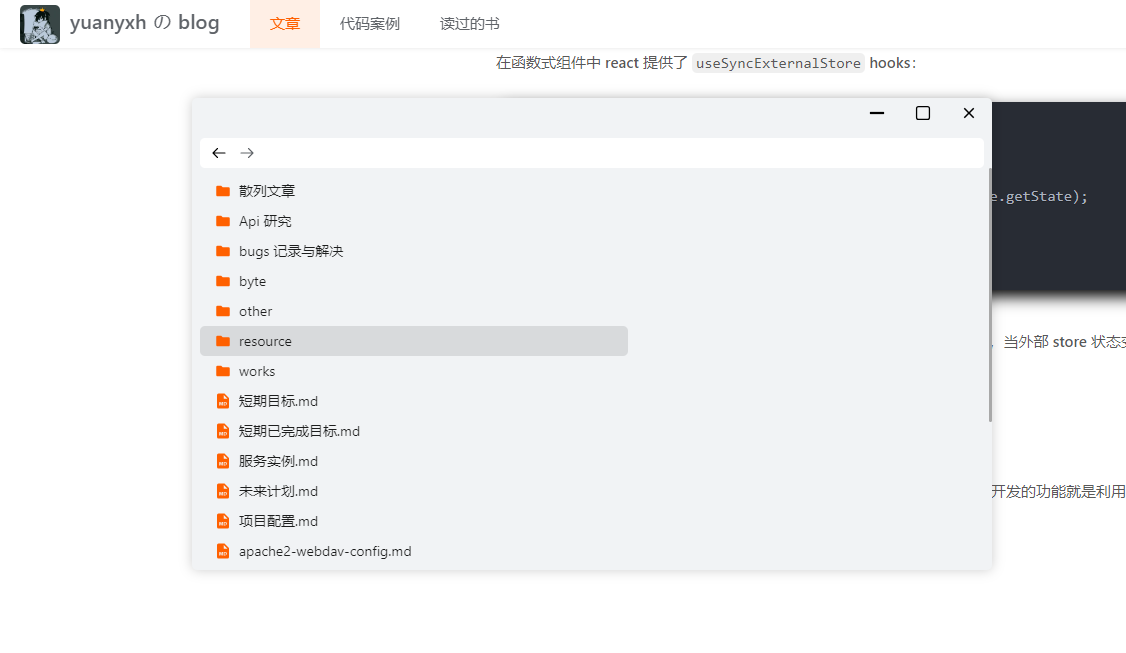
目前只带有简单的增删查功能,但可以在这个系统之上构建不同的文件处理程序,比如目前实现了一个在线的类 Typora 的 markdown 即时编辑器:
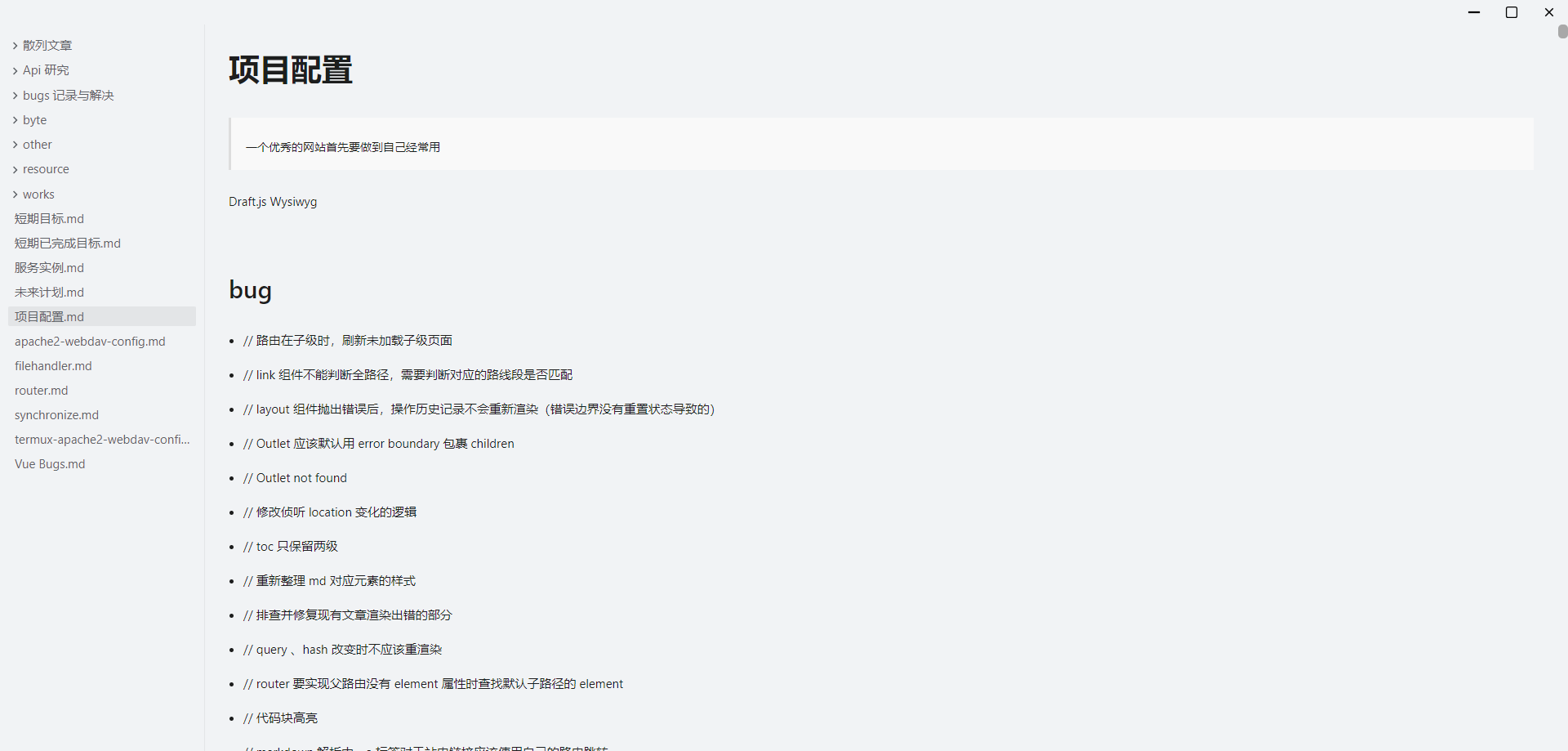
主要通过 Milkdown 这个库来实现,目前测试还有一些小的 bug,但整体可用。
这里重点介绍下对于远程文件的适配,我本身是有一个用于同步文档的 webdav 服务器的,我希望这个文件系统中也能够支持 webdav 协议并挂载远程目录。支持 webdav 协议使用 webdav 这个库可以做到,但如何适配代码呢?使用硬编码来支持的话那未来要如何扩展?
我们需要知道使用 File System API 常用的几个接口,外部操作这几个接口就可以满足大部分的文件操作:
- FileSystemHandle:文件系统的基类
- FileSystemDirectoryHandle:目录句柄,提供操作目录的 API
- FileSystemFileHandle:文件句柄,提供操作文件的 API
- FileSystemWritableFileStream: writeable 文件写入的 API
既然这四个接口可以满足大部分的文件操作,那其实我们可以使用适配器模式,将 webdav 的文件操作对这四个接口进行适配,这样就不用改动已有代码,未来添加其他协议时也只需要关注自身进行适配就好了,不必在大改原来的逻辑。这里贴一下最终我完成的 webdav 适配接口:
import { isEqual } from 'lodash-es';
import type { FileStat, WebDAVClient } from 'webdav';
import { AuthType, createClient } from 'webdav';
import { FilePathNotExistsError, FileTypeError } from './utils/error';
import { FileType } from './utils/fileManager';
class WebdavFileSystemWritableFileStream
implements FileSystemWritableFileStream
{
locked: boolean = false;
private webdav: WebDAVClient;
private fullPath: string;
private setFile: (buffer: ArrayBuffer) => void;
constructor(
webdav: WebDAVClient,
fullPath: string,
setFile: (buffer: ArrayBuffer) => void
) {
this.webdav = webdav;
this.fullPath = fullPath;
this.setFile = setFile;
}
seek(): Promise<void> {
throw new Error('Method not implemented.');
}
truncate(): Promise<void> {
throw new Error('Method not implemented.');
}
abort(): Promise<void> {
throw new Error('Method not implemented.');
}
getWriter(): WritableStreamDefaultWriter<any> {
throw new Error('Method not implemented.');
}
async write(data: FileSystemWriteChunkType): Promise<void> {
if (data instanceof Blob) {
data = await data.arrayBuffer();
}
await this.webdav.putFileContents(this.fullPath, data as string);
this.setFile(data as ArrayBuffer);
}
async close(): Promise<void> {
return void 0;
}
}
class WebdavFileSystemHandle implements FileSystemHandle {
kind: FileSystemHandleKind;
name: string;
private _fullPath: string;
private _webdav: WebDAVClient;
private _webdavInfo: WebdavInfo;
constructor(
kind: FileSystemHandleKind,
name: string,
fullPath: string,
webdavClient: WebDAVClient,
webdavInfo: WebdavInfo
) {
this.kind = kind;
this.name = name;
this._fullPath = fullPath;
this._webdav = webdavClient;
this._webdavInfo = webdavInfo;
}
get fullPath() {
return this._fullPath;
}
get webdav() {
return this._webdav;
}
get webdavInfo() {
return this._webdavInfo;
}
isSameEntry(other: WebdavFileSystemHandle): Promise<boolean>;
isSameEntry(arg: WebdavFileSystemHandle): boolean;
isSameEntry(handle: WebdavFileSystemHandle): boolean | Promise<boolean> {
try {
if (
handle instanceof WebdavFileSystemHandle &&
isEqual(this.webdavInfo, handle.webdavInfo) &&
this._fullPath === handle._fullPath
) {
return Promise.resolve(true);
}
} catch (err) {
return Promise.resolve(false);
}
return Promise.resolve(false);
}
queryPermission(): Promise<PermissionStatus> {
throw new Error('Method not implemented.');
}
requestPermission(): Promise<PermissionStatus> {
throw new Error('Method not implemented.');
}
remove(): Promise<undefined> {
throw new Error('Method not implemented.');
}
}
class WebdavFileSystemFileHandle
extends WebdavFileSystemHandle
implements FileSystemFileHandle
{
readonly kind = 'file';
private file: File | null = null;
constructor(
webdav: WebDAVClient,
fullPath: string,
name: string,
webdavInfo: WebdavInfo
) {
super('file', name, fullPath, webdav, webdavInfo);
}
createSyncAccessHandle(): Promise<FileSystemSyncAccessHandle> {
throw new Error('Method not implemented.');
}
async getFile() {
if (this.file) {
return this.file;
}
const data = (await this.webdav.getFileContents(this.fullPath, {
format: 'binary'
})) as ArrayBuffer;
this.file = new File([data], this.name);
return this.file;
}
async createWritable(
options?: FileSystemCreateWritableOptions | undefined
): Promise<FileSystemWritableFileStream> {
options;
const { webdav, fullPath } = this;
return new WebdavFileSystemWritableFileStream(
webdav,
fullPath,
(buffer) => (this.file = new File([buffer], this.name))
);
}
}
class WebdavFileSystemDirectoryHandle
extends WebdavFileSystemHandle
implements FileSystemDirectoryHandle
{
readonly kind = 'directory';
constructor(
webdav: WebDAVClient,
fullPath: string,
name: string,
webdavInfo: WebdavInfo
) {
super('directory', name, fullPath, webdav, webdavInfo);
}
resolve(possibleDescendant: FileSystemHandle): Promise<string[] | null>;
resolve(possibleDescendant: FileSystemHandle): Promise<string[] | null>;
resolve(): Promise<string[] | null> {
throw new Error('Method not implemented.');
}
keys(): AsyncIterableIterator<string> {
throw new Error('Method not implemented.');
}
values(): AsyncIterableIterator<
FileSystemFileHandle | FileSystemDirectoryHandle
> {
throw new Error('Method not implemented.');
}
entries(): AsyncIterableIterator<
[string, WebdavFileSystemDirectoryHandle | WebdavFileSystemFileHandle]
> {
let i = 0;
const { webdav, fullPath, webdavInfo } = this;
const p = webdav.getDirectoryContents(fullPath, {
includeSelf: false
}) as Promise<Array<FileStat>>;
return {
[Symbol.asyncIterator]() {
return this;
},
async next() {
const values = await p;
const curr = values[i++];
if (!curr) {
return { value: undefined, done: true };
}
return {
value: [
curr.basename,
createWebdavFileSystemHandle(
curr,
webdav,
fullPath + curr.basename,
webdavInfo
)
],
done: false
};
}
};
}
async getDirectoryHandle(
name: string,
options?: FileSystemHandleCreateOptions
): Promise<WebdavFileSystemDirectoryHandle> {
const { create = false } = options || {};
const subFullPath = this.fullPath + name;
const isNotExists = await this.webdav.exists(subFullPath);
if (isNotExists === false) {
if (create === false) {
throw new FilePathNotExistsError(subFullPath);
} else {
await this.webdav.createDirectory(subFullPath);
}
} else {
const stat = (await this.webdav.stat(subFullPath)) as FileStat;
if (stat.type !== 'directory') {
throw new FileTypeError(stat.basename);
}
}
return new WebdavFileSystemDirectoryHandle(
this.webdav,
subFullPath + '/',
name,
this.webdavInfo
);
}
async getFileHandle(
name: string,
options?: FileSystemHandleCreateOptions
): Promise<WebdavFileSystemFileHandle> {
const { create = false } = options || {};
const subFullPath = this.fullPath + name;
if (!(await this.webdav.exists(subFullPath))) {
if (create === false) {
throw new FilePathNotExistsError(subFullPath);
} else {
await this.webdav.putFileContents(subFullPath, '');
}
} else {
const stat = (await this.webdav.stat(subFullPath)) as FileStat;
if (stat.type !== 'file') {
throw new FileTypeError(stat.basename);
}
}
return new WebdavFileSystemFileHandle(
this.webdav,
subFullPath,
name,
this.webdavInfo
);
}
async removeEntry(name: string): Promise<undefined> {
const subFullPath = this.fullPath + name;
await this.webdav.deleteFile(subFullPath);
return void 0;
}
}
CORS
跨域是前端老生常态的问题了,因为引用了 webdav 协议的缘故,简单的设置 Access-Control-Allow-Origin "*" 并不能解决跨域问题,因为 webdav 协议请求的方法很多,也有额外的请求头参数,所以要解决跨域问题需要使用以下配置(apache2 配置):
DavLockDB /var/www/DavLock
<VirtualHost *:80>
ServerAdmin webmaster@localhost
DocumentRoot /var/www/html
LogLevel info
ErrorLog ${APACHE_LOG_DIR}/error.log
CustomLog ${APACHE_LOG_DIR}/access.log combined
RewriteEngine On
RewriteCond %{REQUEST_METHOD} OPTIONS
RewriteRule ^(.*)$ $1 [R=200,L]
Alias /notes /var/www/webdav
Header always set Access-Control-Allow-Origin "*"
Header always set Access-Control-Allow-Headers "Authorization,DNT,X-CustomHeader,Keep-Alive,User-Agent,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type,X-Accept-Charset,X-Accept,origin,accept,if-match,destination,overwrite,Depth"
Header always set Access-Control-Expose-Headers "ETag"
Header always set Access-Control-Allow-Methods "GET, HEAD, POST, PUT, OPTIONS, MOVE, DELETE, COPY, LOCK, UNLOCK, PROPFIND, MKCOL"
Header always set Access-Control-Allow-Credentials "true"
<Directory /var/www/webdav>
DAV On
AuthType Basic
#AuthType Digest
AuthName "your auth name"
AuthUserFile /etc/apache2/webdav.password
Require valid-user
</Directory>
</VirtualHost>
注意需要将浏览器的 OPTIONS 请求重写响应为 200,因为 OPTIONS 请求是不会携带验证参数的,也就导致请求会失败,OPTIONS 请求失败了浏览器就会认为跨域,导致无法正常使用。
Service Worker
Service Worker 可以理解为一个代理层,能够捕获到作用域内的网络请求并修改响应。目前比较常见的作用可能就是缓存资源了,但功能不止如此,毕竟相当于一个小型服务器。
service worker 对于缓存策略主要有以下几种:
- 缓存优先,先缓存后网络
- 网络优先,先网络,失败后回退缓存
- 始终验证,从缓存中取,但每次都向服务器询问是否有变更
- 仅缓存
- 仅网络
有两种缓存方式:
- 预缓存,在项目编译打包阶段将需要的静态资源添加至预缓存列表,在 service worker 被安装时会在后台请求预缓存资源,博客文档这类以 html 为主的网站用的比较多。
- 运行时缓存,从网络中获取时,将响应添加进缓存,这种方式适用于运行时才能确定是否需要的资源,比如腻子脚本,字体和图片。
service worker 有三个阶段:
- 安装阶段,此阶段可以获取预缓存资源
- 等待激活阶段,此阶段表示 service worker 已安装但未激活,没有实际控制当前页面
- 激活阶段,此阶段 service worker 已可用
使用 service worker 时需要注意数据的新鲜度,浏览器通过对 service worker 文件的字节对比来判断是否有更新,当浏览器认为存在更新时会执行安装阶段,我们可以侦听 service worker 的 statechange 事件,当状态变为 installed 时则表示安装成功,可以提示用户刷新并立即启用新的 service worker。
对于 service worker 的使用较为繁琐,Google 开发团队提供了一个开箱即用的 service worker 库 Workbox,可以集成在构建工具中。
另外 PWA 也依赖于 service worker 来做离线访问,除了 service worker 外,pwa 相关的技术还有很多,有些已可用有些仍在实验阶段,比如 后台同步、后台请求、共享 等等。
VS Code 图片上传插件开发
Prerender
预渲染是文章开头提到的一种技术,具体的做法是通过无头浏览器的自动化测试功能,在指定的路线中导航,在页面加载完成后获取到对应路线的完整 html 并输出。因为每个 html 都引用了主应用程序的 js 文件,在浏览器中 html 加载完成后,由视图库对组件实例和预渲染的 html 进行水合,此时程序被视图库控制,变为了一个 spa 程序。
在 vite 中我们可以通过 vite-plugin-prerender 来实现,这里直接贴上我的配置:
import { resolve } from 'node:path';
import selfVitePrerender from 'vite-plugin-prerender';
export interface PostProcessParam {
originalRoute: string;
route: string;
html: string;
outputPath?: string;
}
const Renderer = selfVitePrerender.PuppeteerRenderer;
async function vitePrerender(mode: string) {
if (mode !== 'build') return void 0;
// prerender route:https://www.npmjs.com/package/vite-plugin-prerender
return selfVitePrerender({
// 要渲染的路由
routes: ['/', '/articles', '/coder'],
// 输出目录
staticDir: resolve('./build'),
// compression
minify: {
collapseBooleanAttributes: true,
collapseWhitespace: true,
decodeEntities: true,
keepClosingSlash: true,
sortAttributes: true
},
renderer: new Renderer({
// 无头,设置为 false 会弹出浏览器窗口,方便调试
headless: true,
// 在指定事件之后完成渲染,通过 window.document.dispatchEvent(new Event('pageReadyed'));
renderAfterDocumentEvent: 'pageReadyed'
}),
// 每次渲染时触发,可以在此修改输入路径、输入的 html
postProcess(renderedRoute: PostProcessParam) {
renderedRoute.outputPath = 'build' + renderedRoute.originalRoute;
renderedRoute.html = renderedRoute.html.replace(
'<html lang="en"',
'<html lang="zh-CN"'
);
renderedRoute.html = renderedRoute.html.replace(
/alignItems/g,
'align-items'
);
const route = detailsRoutes.find(
(route) => route.fullPath === renderedRoute.originalRoute
);
return renderedRoute;
}
});
}
export default vitePrerender;
要注意的是这个插件内部使用了 require 且无法被 vite 转换,会导致错误,需要使用 pnpm patch、yarn patch 等技术进行补丁。
一般来说要渲染路由的完整 html 才能有不输 ssr 的加载体验,但有两个坑点暂时无法解决,所以我只对每个路由渲染基础的骨架 html。这两个坑点是这样的:
- 使用 React.createRoot 方式,React 会卸载已加载的 html,再重新挂载上去,部分情况下会偶现闪烁白屏。
- 使用 React.hydrateRoot 方式,React 无法水合组件实例和已加载的 html,因为我的组件是
Lazy Component,初始生成的组件实例无法和已加载的 html 对应上,会导致 React 跳过水合步骤。
SEO
也没做太多的东西,主要就是跑一下 Chrome 的 Lighthouse,跑出来的问题很多暂时都无法解决,比如初始加载的主应用程序包过大,未使用的字节过多。
主要做了这些方向的优化:添加适当的元数据、添加富媒体内容、添加开放图谱协议、添加语义标签、添加站点地图。
- https://ogp.me/
- https://www.zhangxinxu.com/wordpress/2019/06/html-a-link-rel/
- https://blog.jipai.moe/add-structured-data-for-your-site/
另外还使用 Google Index API 对站点的 url 进行自动提交。
Github Deploy
使用 Github Actions 工作流进行自动化部署。配置如下:
# 将静态内容部署到 GitHub Pages 的简易工作流程
name: Deploy static content to Pages
on:
# 仅在推送到默认分支时运行。
push:
branches: ['master']
# 这个选项可以使你手动在 Action tab 页面触发工作流
workflow_dispatch:
# 设置 GITHUB_TOKEN 的权限,以允许部署到 GitHub Pages。
permissions:
contents: read
pages: write
id-token: write
# 允许一个并发的部署
concurrency:
group: 'pages'
cancel-in-progress: true
jobs:
# 单次部署的工作描述
deploy:
environment:
name: github-pages
url: ${{ steps.deployment.outputs.page_url }}
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v4
- name: Set up Node
uses: actions/setup-node@v4
with:
node-version: 20
cache: 'npm'
cache-dependency-path: 'pnpm-lock.yaml'
- name: set up pnpm
run: npm install pnpm -g
- name: Install dependencies
run: pnpm install
- name: Build
run: pnpm run build
- name: Setup Pages
uses: actions/configure-pages@v4
- name: Upload artifact
uses: actions/upload-pages-artifact@v3
with:
# Upload dist folder
path: './build'
- name: Deploy to GitHub Pages
id: deployment
uses: actions/deploy-pages@v4
最后贴一下博客和 github 的链接:
– end


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









