






一:概要
spark sql是一个用于结构化数据处理的spark模块。不像是spark RDD API,Spark SQL提供的接口提供了数据的结构和计算相关的信息。内部来说,spark sql使用这些额外的信息来执行优化工作。和spark sql交互有以下方式:SQL语句,dataframe的API,datasets的API。当你运算一个结果的时候,使用的是相同的计算引擎,和使用的语言和API无关。这意味着,开发者可以简单的切换不同的API,选择最支持的语言/方式来实现功能。
本文中所有例子都可以使用spark-shell或者sparkRshell来运行。
SQL
spark sql可以使用基本的SQL语法,或者HiveQL来执行SQL查询。SAPRK SQL还可以用来从存在的hive中读取数据。当在另外的语言中执行SQL的结果就是DataFrame。你可以使用./spark-sql来和SQL交互或者使用JDBC/ODBC。
DataFrame
dataframe是一种分布式数据集,以命名的行来组织。这和关系型数据库中的表非常像,或者和python/R中的数据帧很像,但是是优化了很多的版本。data frames可以从多种数据源构建,比如:结构化数据文件,hive中的表,外部的数据库,或者存在的RDD。
Datasets
dataset是spark 1.6中添加的实验性接口,提供RDD的特性,还有spark sql优化的执行引擎。一个dataset可以从JVM对象中构建,然后使用转换函数来操作(map,filter,等等)
统一的dataset API可以使用scala来。
二:开始学习
spark sql的函数入口是SQL Context类,或者她的子类。要创造SQLContext,需要sparkContext。

除了基本的SQLContext,你也可以创建一个HiveContext,提供了基本的SQLContext的函数式子集。额外的功能包括,使用更完整的HiveQL解析器,访问Hive UDFs,从Hive 表中读取数据。为了使用HiveContext,你不需要有个装好的hive,还有SQLContext可以访问的数据源。HiveContext分别打包,是为了避免spark build中和hive的依赖关系问题。未来的spark版本会专注于把sqlcontext提升到和hiveContext对等的特性。
sql为了解析查询的变种也可以使用spark.sql.dialect。这个参数可以使用SQLContext.setConf方法来设置,或者使用SET key=value命令在SQL中。对于SQLContext来说,唯一可用的语言是SQL,spark sql提供一个简单的sql解析器。在hive Context中,默认的语言是hiveql,sql也是可用的。因为hive中的hiveql解析器更完整。
创建dataframes
应用可以使用SQLContext来从存在的RDD中创建dataframes,或者hive 表,或其他数据源。
例子,从json文件中创建dataframe
DataFrame操作
dataframe提供了一种语言来操作结构化数据,以下是例子
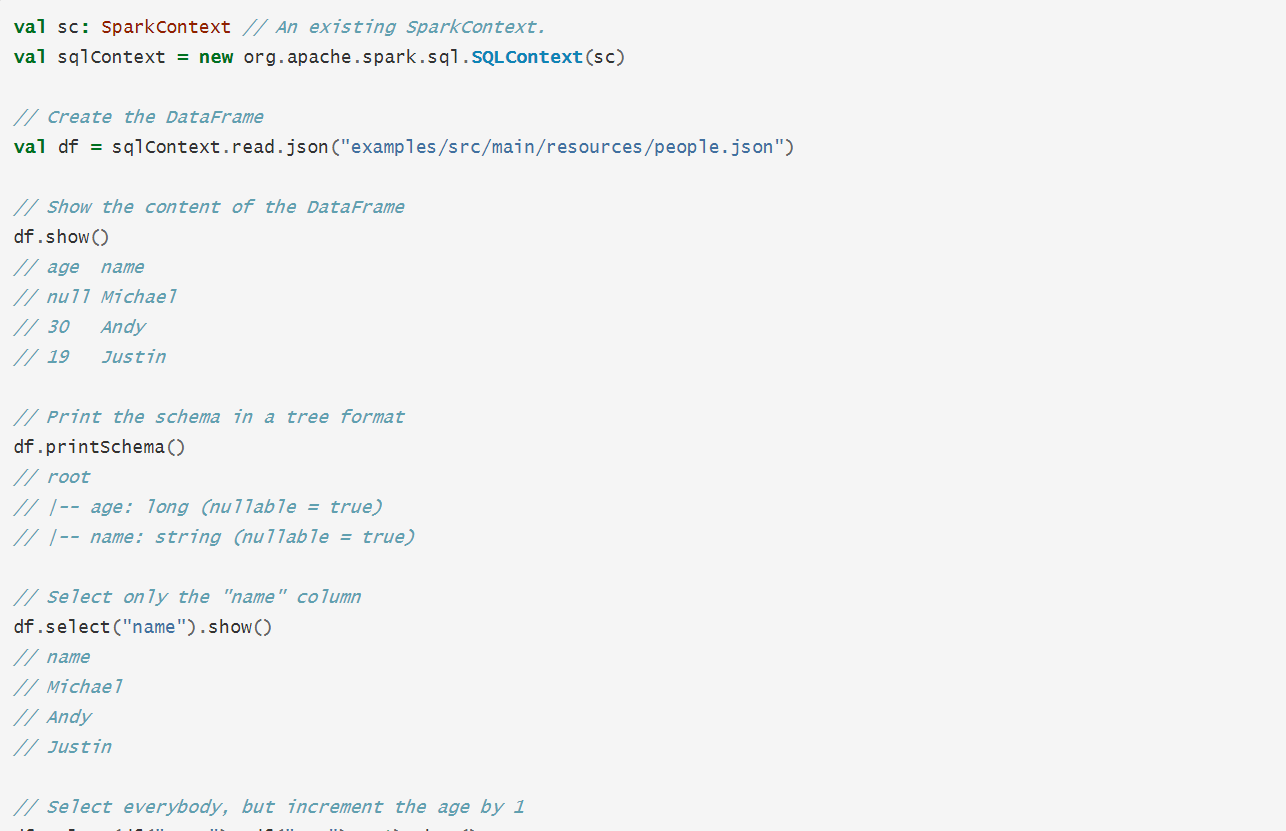

更多的操作类型,请看dataframe的API:
http://spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.sql.DataFrame
除了例子中简单的表达式,dataframe也拥有一个丰富的函数库,包括字符串操作,日期算法,普通数学操作。
程序性执行SQL查询
SQLContext的sql方法可以让应用执行sql查询,返回dataframe类型的结果。

创建Datasets
datasets和RDD类似,但是datasets使用特殊Encoder来序列化对象,让对象通过网络传播。encoder和标准化序列化都负责把对象转化成字节流,encoder自身是代码动态生成的,使用一种格式
允许spark执行多个操作,比如hashing,filter,sort不需要把字节反序列化到对象。

和RDD交互操作
spark sql支持两种方法,把RDD转换成为dataframes。第一种方法是是用映射来推断RDD的模式,RDD中包含特定的对象类型。这个映射基于更精确的代码,当你知道模式,编写spark应用时。
第二个方法是:通过程序式接口来创建dataFrames。允许你创建一个schema,然后应用到RDD中。这种方法更冗长,因为除非执行的时候,你并不知道column和类型。
使用映射推断schema
spark sql的scala接口自动把包含case class的RDD自动转换成dataFrame。case class定义表的schema。case class中变量的名称使用映射,会变成column的名称。case 类也能被嵌入到数组序列中。
这种RDD可以被隐式转换为dataframe,然后注册成一张表。表就可以用在分布式SQL语句中。

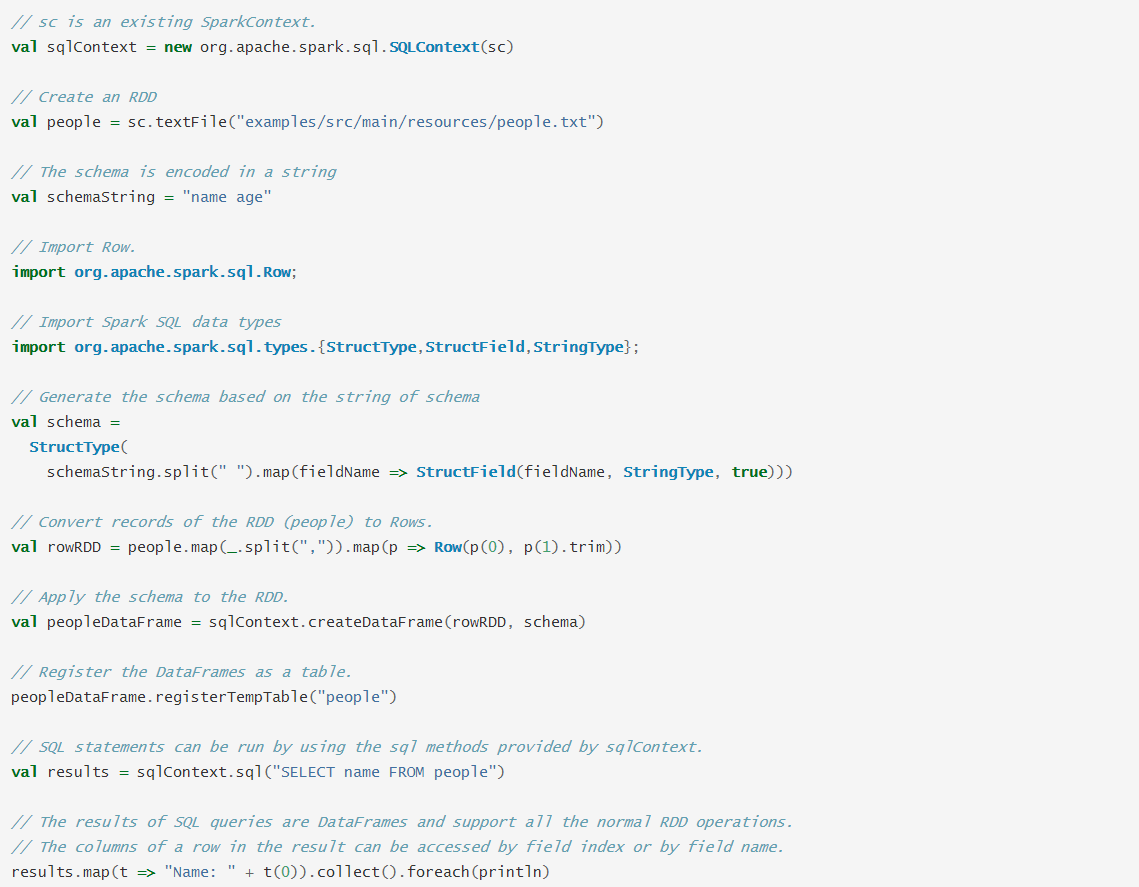
程序式指定schema
当case class不能被提前定义一样(比如:记录结构被编码在字符串中,或者说文本数据集被解析,字段投射到不同用户是不同的),一个dataframe可以被编程以三个步骤创造。
1:从原始RDD中创建行的RDD
2: 创建一个匹配第一步的RDD行的由structType的schema
3:使用SQLContext提供的createDataFrame方法把schema应用到RDD row中去。
例子如下:
三:数据源
spark sql支持使用DataFrame接口来在多种数据源上操作。一个DataFrame可以作为正常RDD操作,也可以注册成临时表。把DataFrame注册为表可以让你在数据上执行SQL查询。这个部分描述了常用的从数据源中加载,保存数据的方法,然后介绍特别的方法。
普通的加载/保存函数
最简单的形式,默认的数据源的操作

手动指定选项
你可以手动指定数据源的类型。你可以指定数据源的全名,比如org.apache.spark.sql.parquet,但是内嵌的数据源可以用简写json。任何类型的DataFrame可以使用语法转换成其它类型。

直接在文件中使用SQL
你可以使用API来读一个文件到DataFrame中,执行查询。
也可以直接使用SQL来查询。
valdf=sqlContext.sql("SELECT * FROM parquet.`examples/src/main/resources/users.parquet`")
保存模式
保存的操作可以选择选项 SaveMode,指定如果存在的话如何处理存在的数据。这些保存模式并不会利用任何非原子化的锁。另外,当执行Overwrite的时候,数据会被删除掉,在新数据写入之前。

保存到persistent的表中
当使用HiveContext的时候,DataFrame也可以使用saveAsTable命令保存成persistent的表。不像是registerTempTable命令,saveAsTable会实体化dataframe的内容,创造一个指针,指向HiveMetastore的指针。持续的表甚至在spark程序重启之后还会存在,只要你保持元数据仓库的连接。使用SQLContext的table方法来创造一个为dataframe的持续表。
但是saveAsTable会创建一个管理的表,意味着数据的地址会被metastore控制。管理的表也会自动保存删除的数据。
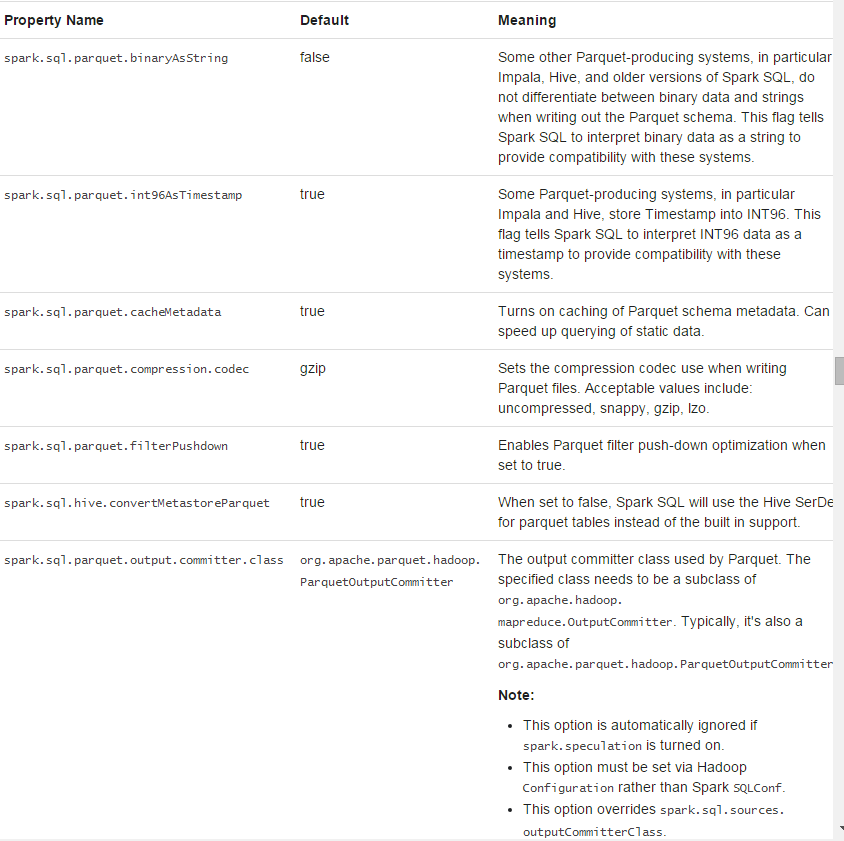
parquet文件
parquet是一中多个数据处理系统支持的格式。spark sql支持读写parquet文件,自动保持源数据的schema。当写parquet文件的时候,所有的column都会自动转换成空的为了兼容。
加载数据
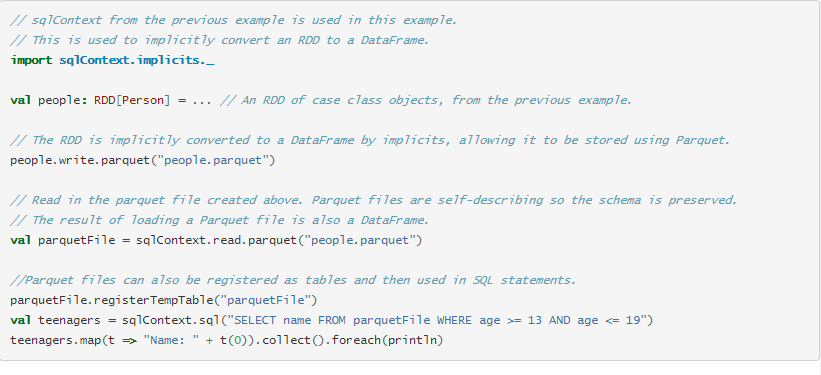
分区发现
表分区是系统中常用的优化方法。在一个分区表中,数据经常存储在不同的目录下,分区的列的值编码在每一个分区目录下。parquet数据源现在可以发现,引用分区信息。比如,我们可以存储所有之前用过的人口信息到一个分区表中,使用以下的列:
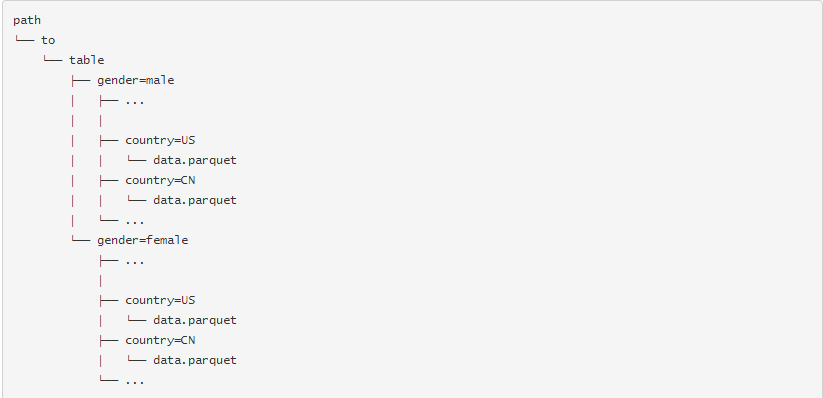
传递path/to/table给SQLContext.read.parquet或者SQLContext.read.load,Spark sql会自动从path中提取分区信息。现在返回的DataFrame的schema变成如下内容:

注意到分区的数据类型会自动推理。当前数据类型和字符串类型是支持的。有时用户不想要自动推理分区column的数据类型。对于这些情况下,自动的类型推导可以使用spark.sql.sources.partitionColumnTypeInference.enabled来配置,默认为真,当disable之后,默认的分区列类型为string类型。
从spark 1.6开始,分区发现默认之发现给定目录的分区。对于以上的例子,如果用户把path/to/table/gender=male发送给SQLContext.read.parquet或者SQLContext.read.load.gender,将不会被考虑为一个分区列。如果用户想要指定基于分区发现的目录,在数据源选项中设置basepath。例如:当path/to/table/gender=male是数据的目录,用户设置path/to/table,gender将会是分区列。
schema 合并
像是avro,parquet也支持schema的升级。用户可以开始写一个简单的schema,逐渐添加column给schema。这样的话,最终会有多个parquet和不同的兼容的schema。parquet数据源现在支持自动检查,然后合并schema。
由于schema合并是一个相当昂贵的操作,大多数情况下不必须,我们默认关闭,要开启这个功能:
1:在读取parquet文件的时候设置选项mergeSchema为 true
2:设置全局的sql选项spark.sq.parquet.mergeSchema为true。

hive metastore parquet 表转换
当从hive metastore table中读取和写入时,sparksq会试着使用自己的parquet支持,而不是hive SerDe为了更好的性能。这个选项配置如下:spark.sql.hive.convertMetaStoreParquet,默认是开启的。
hive/parquet schema 调和
hive和parquet从表模式处理来看有两处不同
1:hive是区分大小写的,parquet不是
2:hive考虑所有的列都是nullable,而parquet不是。
由于这些原因,我们必须调解hive metastore schema和parquet schema,当转换一个hive metastore表到spark sqlparquet表的时候。调解规则如下:
1:拥有相同名字的字段在schema中必须有相同的数据类型。所以nullable是支持的
2:调解的schema包含hive metastore schema的所有字段
任何只存在于parquet的schema字段会被删除
任何只存在于hive metastore schema的字段会以nullable字段加入
元数据刷新
spark sql缓存parquet的元数据来提升性能。当hive metastore parquet表转换启动之后,这些转换的表的元数据也被缓存。如果这些表被hive或者其他外部工具更新,你需要手动刷新这些元数据。
sqlContext.refreshTable("my_table")
配置
parquet的配置工作可以使用SQLContext.setConf方法来做,执行SET key=value命令
JSON数据集
spark sql可以自动推导出JSON数据集的schema,加载成为dataframe。这个转变使用SQLContext.read.json()方法来实现。
注意此处的json文件并不是一个典型的JSON文件。每一行必须要包含一个分别得,自我包含的valid json对象。结果是,通畅的JSON文件会执行失败。

Hive 表
spark也支持读写apache hive中的数据。然而,hive有非常多的依赖关系,这不在原生的spark中。hive支持使用-Phive,-Phive-thriftserver来添加spark。这些命令创建一个包含hive的JAR包。注意hive组装的jar包必须要在工作节点中存在,她们需要访问hive的序列化和反序列化资源库来访问存储在hive中的数据。
配置文件是hive-site.xml,core-site.xml,hdfs-site.xml。注意当在YARN集群中执行查询的时候,datanucleus的jar包在lib目录下的,和在conf目录下的hive-site.xml文件需要在驱动中时可用的,还有yarn集群中所有的算子。简单的方式是在spark-submit命令中添加--jars和--file选项。
当和hive一起工作的时候,必须拥有一个hiveContext,继承与SQLContext,添加了在metastore中寻找表和使用HiveQL编写查询的支持。用户没有一个存在的hive,仍然可以创建一个HiveContext。hive-sites.xml默认自动在当前目录创建metastore_db,hiveconf会自动创建warehouse目录,默认的目录是/usr/hive/warehouse。注意你需要给用户赋予/usr/hive/warehouse读写的权限。

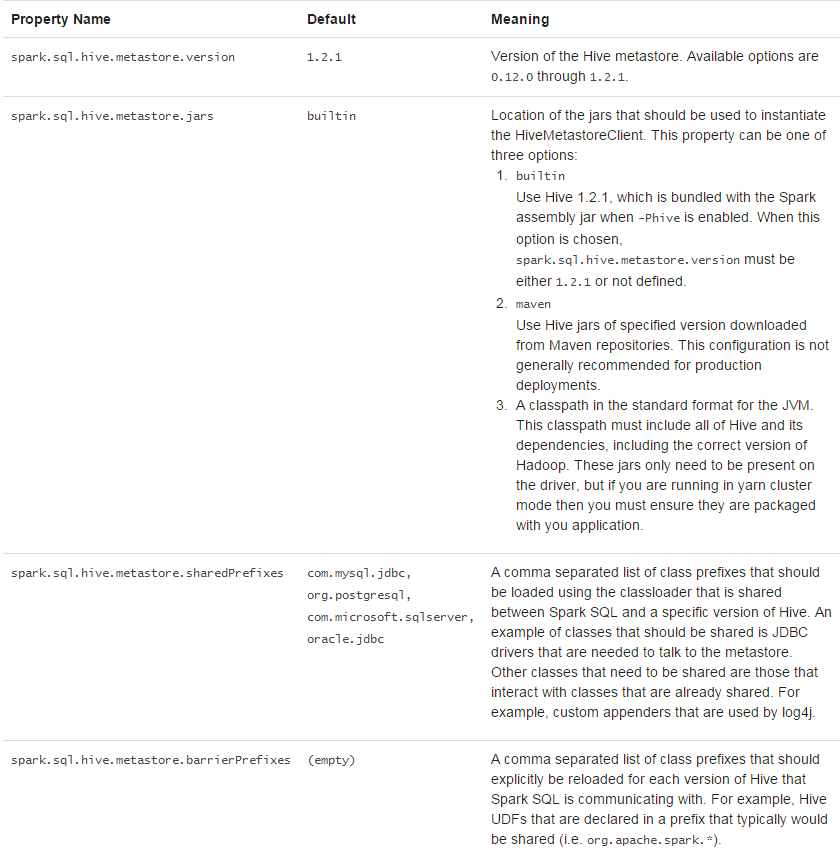
和不同版本的hive metastore交互
spark sql对hive的支持很重要的一点是与hive metastore的交互,这可以让spark sql访问hive 表中的元数据。从spark 1.4开始,一个简单的二进制spark sql可以用来查询不同版本的hive metastores,使用如下的配置。注意hive独立的版本正在用来和metastore对话,内部的spark sql会编译hive 1.2.1,用这些类来执行。
这些选项可以用来配置用来检索元数据的hive版本
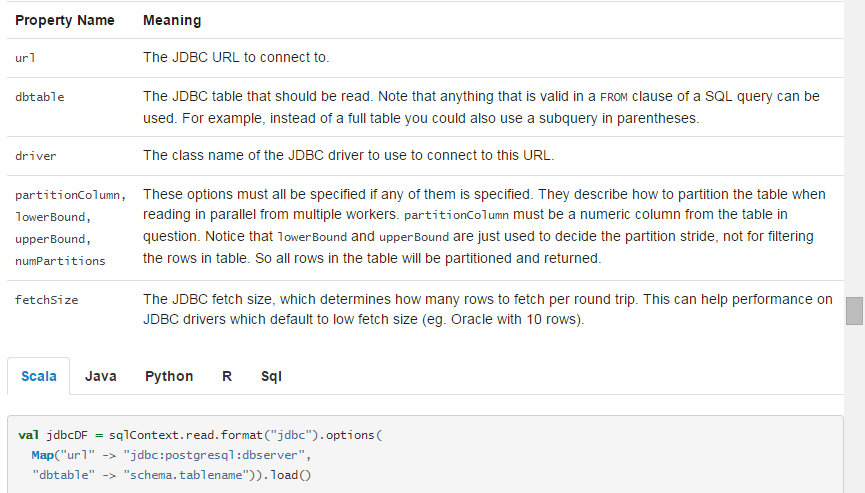
连接其他数据库的JDBC
spark sql也包括可以从其他数据库读数据的数据源。实现的函数是JdbcRDD。这是因为结果以dataframe返回,可以被spark sql处理或者和其他数据源join.JDBC数据源也比Java和python更好用,也不需要使用者提供classTag。
开始的话,你需要把JDBC驱动加载到spark classpath中。例子:你需要从spark-shell中访问postgres,执行下面的命令:

外部数据库的表可以以dataframe的形式加载,或者以spark sql 临时表的形式,支持以下特性。
troubleshooting
JDBC驱动类必须对于client session和所有算子上原生的类加载器是可见的。这是因为Java的驱动管理类会进行安全管理,导致他会让所有类对于原生的类加载器都是不可见的。修改方式:修改compute_classpath.sh在所有工作节点。
有一些数据库比如H2,会把所有名字改成大写,需要在spark sql中注意这一点。
四:性能调优
对于一些工作,可以提升性能。或者缓存数据在内存中,或者修改参数。
在内存中缓存数据
spark sql可以调用sqlContext.cacheTable(表名)或者dataFrame.cache()来缓存表在内存中。spark sql将会扫描需要的列,自动压缩占用内存大小和垃圾回收。在内存中删除的方法sqlContext.uncacheTable(表名)。
配置内存缓存使用SQLContext的setConf方法,或者在SQL中执行命令SET key=value

五:分布式SQL引擎
运行thrift JDBC/ODBC服务器
thrift jdbc/odbc服务器实现方法和hiveServer2很像。你可以使用beeline脚本来测试jdbc服务器。
启动jdbc/odbc服务器,执行spark目录的下面命令
./sbin/start-thriftserver.sh

现在你可以使用beeline来测试thrift JDBC/ODBC服务器。
./bin/beelinebeeline> !connect jdbc:hive2://localhost:10000
beeline会要求用户名和密码。
hive的配置文件在hive-site.xml,core-site.xml,hdfs-site.xml
你也可以使用hive的beeline脚本。
thrift jdbc服务器也支持发送thrift RPC信息使用HTTP传输。配置文件:hive-site.xml。

测试,使用beeline来在http模式下连接JDBC/ODBC服务器

执行spark sql CLI
spark sql cli是一个简便的工具,用来执行hive metastore服务在本地模式下,在命令行下执行查询。注意spark sql不能和thrift jdbc服务器对话。















 3050
3050

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









