






FP-Growth算法
Apriori算法与FP-Growth算法比较:
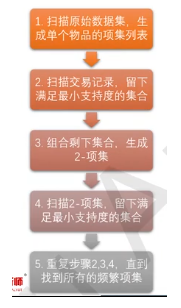
Apriori算法挖掘频繁项集的步骤
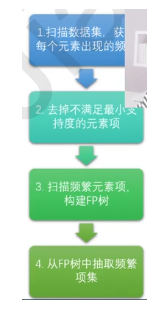
FP-Growth算法挖掘频繁项集的步骤
Apriori算法最大的缺点是频繁项集发现的速度太慢;
FP-Growth算法是在Apriori算法基础上进行了优化得到的算法;
FP-Growth算法只需要对数据库进行两次扫描,而Apriori算法对于每个潜在的频繁项集都会扫描数据集判定给定模式是否频繁,因此FP-Growth算法的速度要比Apriori算法快。
对FP-Growth算法需要注意的有:
1.该算法采用了与Apriori算法完全不同的方法来发现频繁项集
2.该算法虽然可以能更高效的发现频繁项集,但是不能用于发现关联规则;
FP-Growth算法步骤:
1.构建FP树
2.从FP树中挖掘频繁项集
FP树
FP是频繁模式(Frequent Pattern)的缩写。FP-Growth算法将数据存储在一种称为FP树的紧凑的数据结构中,并直接从该结构中提取频繁项集。一个FP树的结构如下图,和其他树结构不同之处是FP树通过
链接(link)来连接相似元素,被连接起来的元素项可以看成一个链表。可以说,FP树是一种用于编码数据集的有效方式。
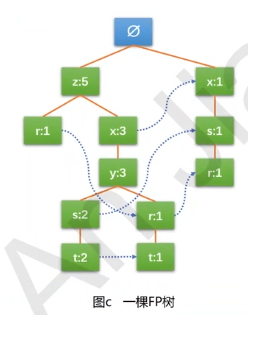
FP树特点:
- 一个元素项可以在一棵FP树中出现多次
- 项集以路径+频率的方式存储在FP树中
- 树节点中的频率表示的是集合中单个元素在其序列中出现的次数
- 一条路径表示的是一个事务,如果事务完全一致,则路径可以重合
- 相似项之间的链接即为节点链接(link),主要是用来快速发现相似项的位置
为了快速访问树中的相同项,还需要维护一个连接具有相同项的节点的指针列表(headTable),每个列表元素包括:数据项、该项的全局最小支持度、指向FP树中该项链表的表头的指针。

构建FP树的过程
例:下表的数据集是用于生成上图中FP树的原始数据集
| 事务ID | 事务中的元素项 |
|---|---|
| 001 | r,z,h,j,p |
| 002 | z,y,x,w,v,u,t,s |
| 003 | z |
| 004 | r,x,n,o,s |
| 005 | y,r,x,z,q,t,p |
| 006 | y,z,x,e,q,s,t,m |
步骤一:统计原始事务集中各元素项出现的频率
这一步的主要作用是生成FP树的树节点,统计好的元素项及其频率即为所需要的树节点;
统计结果:
| 元素项 | 出现频率 |
|---|---|
| r | 3 |
| z | 5 |
| h | 1 |
| j | 1 |
| p | 2 |
| y | 3 |
| x | 4 |
| w | 1 |
| v | 1 |
| u | 1 |
| t | 3 |
| s | 3 |
| n | 1 |
| o | 1 |
| q | 2 |
| e | 1 |
| m | 1 |
步骤二:支持度过滤
上表计算出来的所有树节点并非全部是所需要的树节点,构建FP树的目的是为了挖掘频繁项集,所以为了减少后续的计算量,在这一步可以把不满足最小支持度的元素项剔除。
设最小支持度为3,过滤后的元素项为:
| r | 3 |
|---|---|
| z | 5 |
| y | 3 |
| x | 4 |
| t | 3 |
| s | 3 |
步骤三:排序
根据频率大小,将支持度过滤后的元素项(频繁项集)进行排序,并根据排序后的元素项,将原始数据也进行排序。这样做是因为,构建的FP树中,相同项只会出现一次,但是集合是无序的,对于集合{x,y,z}和集合{z,y,x}是一样的,但对于FP树来说,它会把这两个集合当作两个不同的集合,然后生成两条路径。为了解决这样的问题,需要将集合进行降序排序。
| z | 5 |
|---|---|
| x | 4 |
| r | 3 |
| y | 3 |
| t | 3 |
| s | 3 |
注:事务集在重排序时,进行了两步操作:
1.按照频率大小对元素项进行排序
2.对于相同频率的元素项,则对关键字进行降序排列
步骤四:构建FP树
对事务集过滤和重排序后,就可以构建FP树了。首先从空集{ }开始,向其中不断添加频繁项集。如果树中已存在现有元素,则增加现有元素的值。如果不存在,则向树中添加一个分支。
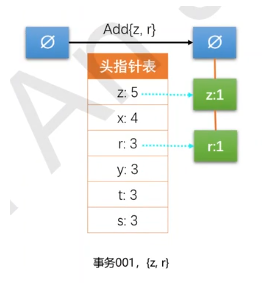
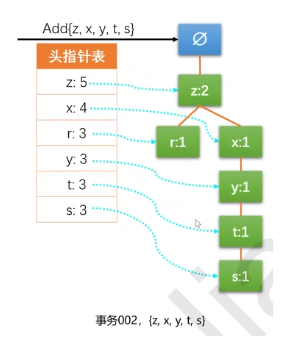
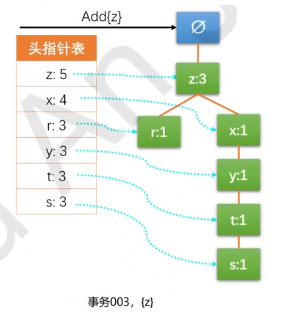



把六个事务项添加进去之后,FP树就建立好了。和原始图不同的原因:对频率相同的元素进行了关键字降序的处理。说明,对项的关键字排序将影响FP树的结构,进而影响后续发现频繁项的结果。
FP树的python实现
1.创建FP树的数据结构
由于FP树比之前建立的决策树复杂,所以创建一个类来保存树的每一个节点,类中包含用于存放节点名字的变量和1个计数值,nodelink变量用于链接相似的元素项,parent变量用于指向当前父节点,空字典变量用于存放节点的子节点。
类中包含的两个方法:
1.inc()功能:对count变量增加给定值
2.disp()功能:将树以文本形式显示,主要是方便调式;
2.创建简单的数据集
def loadSimpDat():
"""数据集"""
simpDat = [['r', 'z', 'h', 'j', 'p'],
['z', 'y', 'x', 'w', 'v', 'u', 't', 's'],
['z'],
['r', 'x', 'n', 'o', 's'],
['y', 'r', 'x', 'z', 'q', 't', 'p'],
['y', 'z', 'x', 'e', 'q', 's', 't', 'm']]
return simpDat
3.创建FP树
函数1:数据格式化
得到数据集后,遍历每一条交易数据,并把它们变成固定格式(frozenset)。使用了setdefault函数。
功能:返回指定键的值,如果键不在字典中,将添加键并将值设置为一个指定值,默认为None,该函数与get()函数功能类似,不同的是setdefault()返回的键如果不在字典中,会添加键(更新字典),而get函数不会添加键。
def createInitSet(dataSet):
"""数据格式化"""
retDict = {}
for trans in dataSet:
# print(trans)
fset = frozenset(trans)
# print(fset)
retDict.setdefault(fset, 0) #返回指定键的值,如果没有则添加一个键
# print(retDict)
retDict[fset] += 1
# print(retDict)
return retDict
函数2:更新头指针表
updateHeader()函数的功能是确保节点链接指向树中该元素的每一个实例。从头指针表的nodeLink开始,一直沿着nodeLink直到到达链表末尾。
def updateHeader(nodeToTest, targetNode):
while (nodeToTest.nodeLink != None):
nodeToTest = nodeToTest.nodeLink
nodeToTest.nodeLink = targetNode
函数3:FP树的生长函数
功能:让树生长。首先测试事务中第一个元素项是不是子节点,如果是,则更新count参数;如果不是,则创建一个新的treeNode作为子节点添加到树中。此时,头指针表也要跟着更新以指向新的节点,这个更新需要调用updateHeader()函数,如果item中不止一个元素项的话,则将剩下的元素项作为参数进行迭代。
注:迭代时每次调用会去掉列表中的第一个元素。
def updateTree(items, myTree, headerTable, count):
if items[0] in myTree.children: myTree.children[items[0]].inc(count)
else:
myTree.children[items[0]] = treeNode(items[0], count, myTree)
if headerTable[items[0]][1] == None:
headerTable[items[0]][1] = myTree.children[items[0]]
else:
updateHeader(headerTable[items[0]][1], myTree.children[items[0]])
if len(items) > 1:
updateHeader(items[1:], myTree.children[items[0]], headerTable, count)
函数4:创建FP树
功能:创建FP树,树构建过程会遍历数据集两次,第一次遍历数据集并统计每个数据集出现的次数。这些信息被存储在头指针列表中。接下来扫描头指针表,删除不满足最小支持度的元素项。在头指针表中增加一列,用来存放指向每种类型第一个元素项的指针,然后创建只包含空集合的根节点。第二次遍历数据集,此次只考虑频繁项集,对频繁项集进行排序,最后调用updateTree()让树生长。
python的filter()函数:
用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。
该函数接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给参数进行判断;
然后返回Ture 或False,最后将返回Ture的元素放到新列表中。
filter(function, iterable)
function ----- 判断函数
iterable ------ 可迭代对象
注:在python3中,最后返回的对象是迭代器对象,如果要转换为列表,可以使用list()来转换;
def createTree(dataSet, minSup=3):
headerTable = {}
# 第一次遍历数据集,记录每个数据项的支持度
for trans in dataSet:
for item in trans:
headerTable[item] = headerTable.get(item, 0) + 1
# 根据最小支持度过滤
lessThanMinsup = list(filter(lambda k : headerTable[k] < minSup, headerTable.keys())) for k in lessThanMinsup:
del(headerTable[k])
freqItemSet = set(headerTable.keys()) # 如果所有数据都不满足最小支持度,返回None,
if len(freqItemSet) == 0:
return None,None
for k in headerTable:
headerTable[k] = [headerTable[k], None]
myTree = treeNode('∅', 1, None)
第二次遍历数据集,构建 FP-Tree
for tranSet,count in dataSet.items():
# 根据最小支持度处理一条训练样本,key:样本中的一个样例,value:该样例的全局支持度
localD = {}
for item in tranSet:
if item in freqItemSet:
localD[item] = headerTable[item][0]
if len(localD) > 0:
# 根据全局频繁项对每个事务中的数据进行排序,等价于 order by p[1] desc ,p[0] desc orderedItems = [v[0] for v in sorted(localD.items(), key=lambda p:(p[1], p[0]), reverse=True)]
updateTree(orderedItems, myTree, headerTable, count)
return myTree,headerTable















 1010
1010











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









