






写在开头:
本文是博主学习自用,如有错误,请指出,谢谢
数据库操作练习
建库建表
#建立数据库
create database csdn_school;
#建立学生表 编号(主键) 学生姓名 生日 性别
CREATE TABLE student(
s_id int PRIMARY key auto_increment,
s_name VARCHAR(20) not null,
s_birthday VARCHAR(20) not null,
s_sex VARCHAR(20) not null
);
#建立课程表 编号(主键) 课程名 教师
CREATE TABLE course(
c_id int auto_increment,
c_name VARCHAR(20) not null,
t_id int not null,
PRIMARY KEY(c_id)
);
#建立教师表 编号(主键)教师姓名
CREATE TABLE teacher(
t_id int auto_increment PRIMARY key,
t_name VARCHAR(20) not null
);
ALTER TABLE teacher ADD CONSTRAINT pk_id PRIMARY key(t_id);
#建立成绩表 编号(主键) 课程编号(主键) 成绩
CREATE TABLE score(
s_id int ,
c_id int ,
s_score FLOAT(4,2),
PRIMARY KEY(s_id,c_id)
);
#插入学生表数据
INSERT INTO student VALUES(01 , '赵雷' , '1990-01-01' , '男');
INSERT INTO student VALUES(02 , '钱电' , '1990-12-21' , '男');
INSERT INTO student VALUES(03 , '孙风' , '1990-05-20' , '男');
INSERT INTO student VALUES(04 , '李云' , '1990-08-06' , '男');
INSERT INTO student VALUES(05 , '周梅' , '1991-12-01' , '女');
INSERT INTO student VALUES(06 , '吴兰' , '1992-03-01' , '女');
INSERT INTO student VALUES(07 , '郑竹' , '1989-07-01' , '女');
INSERT INTO student VALUES(08 , '王菊' , '1990-01-20' , '女');
#插入课程表数据
INSERT INTO course VALUES(01 , '语文' , '02');
INSERT INTO course VALUES(02 , '数学' , '01');
INSERT INTO course VALUES(03 , '英语' , '03');
#插入教师表数据
INSERT INTO teacher VALUES(01,'张三');
INSERT INTO teacher VALUES(02,'李四');
INSERT INTO teacher VALUES(03,'王五');
#插入成绩表数据
INSERT INTO score VALUES(01,01,80);
INSERT INTO score VALUES(01,02,90);
INSERT INTO score VALUES(01,03,99);
INSERT INTO score VALUES(02,01,70);
INSERT INTO score VALUES(02,02,60);
INSERT INTO score VALUES(02,03,80);
INSERT INTO score VALUES(03,01,80);
INSERT INTO score VALUES(03,02,80);
INSERT INTO score VALUES(03,03,80);
INSERT INTO score VALUES(04,01,50);
INSERT INTO score VALUES(04,02,30);
INSERT INTO score VALUES(04,03,20);
INSERT INTO score VALUES(05,01,76);
INSERT INTO score VALUES(05,02,87);
INSERT INTO score VALUES(06,01,31);
INSERT INTO score VALUES(06,03,34);
INSERT INTO score VALUES(07,02,89);
INSERT INTO score VALUES(07,03,98);
题目
#1、查询课程编号为“01”的课程比“02”的课程成绩高的所有学生的学号。
#2、查询平均成绩大于60分的学生的学号和平均成绩
#3、查询所有学生的学号、姓名、选课数、总成绩
#4、查询姓“张”的老师的个数
#5.查询没学过“张三”老师课的学生的学号、姓名(重点)
#6、查询学过“张三”老师所教的所有课的同学的学号、姓名
#7、查询学过编号为“01”的课程并且也学过编号为“02”的课程的学生的学号、姓名
#8、查询课程编号为“02”的总成绩
#9、查询所有课程成绩小于60分的学生的学号、姓名
#10、查询没有学全所有课的学生的学号、姓名
#11、查询至少有一门课与学号为“01”的学生所学课程相同的学生的学号和姓名
#12、查询和“01”号同学所学课程完全相同的其他同学的学号
#13.把“Score”表中“张三”老师教的课的成绩都更改为此课程的平均成绩
#14、查询和“02”号的同学学习的课程完全相同的其他同学学号和姓名(同12题)
#15、删除学习“张三”老师课的SC表记录
#16.检索"01"课程分数小于60,按分数降序排列的学生信息
#17、按平均成绩从高到低显示所有学生的“数据库”(c_id=‘04’)、“企业管理”(c_id=‘01’)、“英语”(c_id=‘06’)三门的课程成绩,按如下形式显示:学生ID,数据库,企业管理,英语,有效课程数,有效平均分
#18、查询各科成绩最高和最低的分:以如下的形式显示:课程ID,最高分,最低分(之前删除了张三老师的课程,所以不存在02课程)
#19、按各科平均成绩从低到高和及格率的百分数从高到低排列,以如下形式显示:课程号,课程名,平均成绩,及格百分数
#21、查询不同老师所教不同课程平均分从高到低显示
#23、使用分段[100-85],[85-70],[70-60],[<60]来统计各科成绩,分别统计各分数段人数:课程ID和课程名称
#24、查询学生平均成绩及其名次
#25、查询各科成绩前三名的记录
#26、查询每门课程被选修的学生数
#27、查询出只选修了两门课程的全部学生的学号和姓名
#28、查询男生、女生人数
#29、查询名字中含有“风”字的学生信息
#30、查询同名同姓学生名单并统计同名人数
#31、1990年出生的学生名单
#32、查询平均成绩大于85的所有学生的学号、姓名和平均成绩
#33、查询每门课程的平均成绩,结果按平均成绩升序排序,平均成绩相同时,按课程号降序排列
#34、查询课程名称为“数学”且分数低于60的学生姓名和分数
#35、查询所有学生的选课情况
#36、查询任何一门课程成绩在70分以上的姓名、课程名称和分数
#37、查询不及格的课程并按课程号从大到小排列
#38、查询课程编号为03且课程成绩在80分以上的学生的学号和姓名
#39、查询选了课程的学生人数
#40、查询选修“张三”老师所授课程的学生中成绩最高的学生姓名及其成绩
#41、查询各个课程及相应的选修人数
#42、查询不同课程成绩相同的学生的学生编号、课程编号、学生成绩
#43、查询每门课程成绩最好的前两名
#44、统计每门课程的学生选修人数(超过5人的课程才统计)。要求输出课程号和选修人数,查询结果按人数降序排序,若人数相同,按课程号升序排序
#45、查询至少选修两门课程的学生学号
#46、查询选修了全部课程的学生信息
#47、查询没学过“张三”老师讲授的任一门课程的学生姓名
#48、查询两门以上不及格课程的同学的学号及其平均成绩
#49、检索课程编号为“03”且分数小于60的学生学号,结果按按分数降序排列
#50、删除学生编号为“02”的课程编号为“01”的成绩
题目及答案
#1、查询课程编号为“01”的课程比“02”的课程成绩高的所有学生的学号。
SELECT s_id from score s1 inner join score s2 using(s_id)
where s1.s_id=s2.s_id and s1.c_id=‘01’ and s2.c_id=‘02’ and s1.s_score>s2.s_score;
#2、查询平均成绩大于60分的学生的学号和平均成绩
SELECT s_id,avg(s_score) 平均成绩 from score
GROUP BY s_id HAVING avg(s_score)>60;
#3、查询所有学生的学号、姓名、选课数、总成绩
SELECT s_id 学号,s_name 姓名,count(s_id) 选课数,sum(s_score) 总成绩 FROM student inner join score USING(s_id) GROUP BY s_id;
#4、查询姓“张”的老师的个数
SELECT count(t_id) from teacher where t_name like ‘张%’;
#5.查询没学过“张三”老师课的学生的学号、姓名(重点)
SELECT s_id,s_name from student where s_id not in
(SELECT s_id from score where c_id = (SELECT c_id from course inner join teacher USING(t_id) where t_name=‘张三’));
#6、查询学过“张三”老师所教的所有课的同学的学号、姓名
SELECT s_id,s_name from student where s_id in
(SELECT s_id from score inner join course USING(c_id) join teacher USING(t_id) WHERE t_name=‘张三’);
#7、查询学过编号为“01”的课程并且也学过编号为“02”的课程的学生的学号、姓名
SELECT s_id,s_name from student inner join score USING(s_id)
where s_id in(SELECT s_id from score left join course USING(c_id)
where c_id=‘01’) and c_id=‘02’;
#8、查询课程编号为“02”的总成绩
SELECT sum(s_score) 总成绩 from score where c_id=‘02’;
#9、查询所有课程成绩小于60分的学生的学号、姓名
SELECT s_id,s_name from student where s_id not in
(SELECT s_id from score GROUP BY s_id HAVING max(s_score)>=60);
#10、查询没有学全所有课的学生的学号、姓名
SELECT s_id,s_name from student join score USING(s_id)
GROUP BY s_id HAVING count(c_id) <(SELECT count(1) from course);
#11、查询至少有一门课与学号为“01”的学生所学课程相同的学生的学号和姓名
SELECT DISTINCT s_id,s_name from student join score USING(s_id)
where c_id in
( SELECT c_id from score where s_id=‘01’)
and s_id <>‘01’;
#12、查询和“01”号同学所学课程完全相同的其他同学的学号
SELECT s_id,count(score.c_id) from student sc join score USING(s_id) where c_id in
(SELECT c_id from score where s_id=‘01’) and
s_id<>‘01’ GROUP BY s_id HAVING count(1)=
(SELECT count(s_id) from score where s_id=‘01’) and
(SELECT count(1) from score where s_id=‘01’)=(SELECT count(1) from score where s_id=sc.s_id);
#13.把“Score”表中“张三”老师教的课的成绩都更改为此课程的平均成绩
update score a join
(select avg(s_score) t, Score.c_id from score
join course USING(c_id)
join teacher USING(t_id)
where t_name =‘张三’ group by c_id) b
USING(c_id)
set a.s_score= b.t;
#14、查询和“02”号的同学学习的课程完全相同的其他同学学号和姓名(同12题)
SELECT s_id,count(score.c_id) from student sc join score USING(s_id)
where c_id in
(SELECT c_id from score where s_id=‘02’) and
s_id<>‘02’ GROUP BY s_id HAVING count(1)=
(SELECT count(s_id) from score where s_id=‘02’) and
(SELECT count(1) from score where s_id=‘02’)=
(SELECT count(1) from score where s_id=sc.s_id);
#15、删除学习“张三”老师课的SC表记录
DELETE from score where c_id in
(SELECT c_id from course JOIN teacher USING(t_id) where t_name=‘张三’);
#16.检索"01"课程分数小于60,按分数降序排列的学生信息
SELECT * from student JOIN score USING(s_id)
where c_id=‘01’ and s_score<60
ORDER BY s_score desc
#17、按平均成绩从高到低显示所有学生的“数据库”(c_id=‘04’)、“企业管理”(c_id=‘01’)、“英语”(c_id=‘06’)三门的课程成绩,按如下形式显示:学生ID,数据库,企业管理,英语,有效课程数,有效平均分
select s_id as ‘学生ID’,
(case when c_id=‘04’ then s_score else NULL end) as ‘数据库’,
(case when c_id=‘01’ then s_score else NULL end) as ‘企业管理’,
(case when c_id=‘06’ then s_score else NULL end) as ‘英语’,
count(c_id) as 有效课程数,
avg(s_score) as 有效平均分
from Score
group by s_id
order by avg(s_score) DESC;
#18、查询各科成绩最高和最低的分:以如下的形式显示:课程ID,最高分,最低分(之前删除了张三老师的课程,所以不存在02课程)
SELECT c_id 课程ID,max(s_score) 最高分,min(s_score) 最低分 from score GROUP BY c_id;
#19、按各科平均成绩从低到高和及格率的百分数从高到低排列,以如下形式显示:课程号,课程名,平均成绩,及格百分数
SELECT c_id 课程号,c_name 课程名, avg(s_score) 平均成绩,
concat((SELECT count(1) from score b where a.c_id=b.c_id and s_score>=60)/count(*)*100,"%") 及格百分数
from score a join course USING(c_id)
GROUP BY c_id
ORDER BY avg(s_score)
#21、查询不同老师所教不同课程平均分从高到低显示
SELECT *,avg(s_score) 平均分 from score
join course USING(c_id)
join teacher USING(t_id)
GROUP BY t_id ORDER BY avg(s_score) desc
#23、使用分段[100-85],[85-70],[70-60],[<60]来统计各科成绩,分别统计各分数段人数:课程ID和课程名称
SELECT score.c_id 课程ID,c_name 课程名称,
sum(case when s_score BETWEEN 85 and 100 then 1 else 0 end) ‘[100-85]’,
sum(case when s_score>=70 and s_score<85 then 1 else 0 end) ‘[85-70]’,
sum(case when s_score>=60 and s_score<70 then 1 else 0 end) ‘[70-60]’,
sum(case when s_score<60 then 1 else 0 end) ‘[<60]’
from score join course USING(c_id) GROUP BY score.c_id,c_name;
#24、查询学生平均成绩及其名次
SELECT s_id 学号,avg,
@a:=@a+1 排名
from (SELECT *, avg(s_score) avg from score sc
GROUP BY s_id ORDER BY avg(s_score) desc) as a ,(SELECT @a:=0) as b;
#25、查询各科成绩前三名的记录
SELECT * from score s1 where
(SELECT count(1) from score s2
where s1.s_score<s2.s_score
and s1.c_id=s2.c_id)<=2
order by c_id ,s_score desc;
#26、查询每门课程被选修的学生数
SELECT count(1) from score
GROUP BY c_id;
#27、查询出只选修了两门课程的全部学生的学号和姓名
SELECT s_id,s_name from student where s_id in
(SELECT s_id from score GROUP BY s_id HAVING count(c_id)=2);
#28、查询男生、女生人数
SELECT s_sex,count(1) from student GROUP BY s_sex;
#29、查询名字中含有“风”字的学生信息
SELECT * from student where s_name like ‘%风%’;
#30、查询同名同姓学生名单并统计同名人数
SELECT s_name,count(1) from student a
where s_name in (SELECT s_name from student b where a.s_id<>b.s_id);
#31、1990年出生的学生名单
SELECT * from student where s_birthday like ‘1990%’;
#32、查询平均成绩大于85的所有学生的学号、姓名和平均成绩
SELECT student.*,avg(s_score) from student join score
USING(s_id) GROUP BY s_id HAVING avg(s_score)>85 ;
#33、查询每门课程的平均成绩,结果按平均成绩升序排序,平均成绩相同时,按课程号降序排列
SELECT avg(s_score) from score GROUP BY c_id ORDER BY avg(s_score),c_id desc;
#34、查询课程名称为“数学”且分数低于60的学生姓名和分数
SELECT s_name,s_score from student
join score USING(s_id)
join course USING(c_id)
where c_name=‘数学’ and s_score<60;
#35、查询所有学生的选课情况
SELECT DISTINCT s_id,s_name,c_id,c_name from student
join score USING(s_id)
join course USING(c_id);
#36、查询任何一门课程成绩在70分以上的姓名、课程名称和分数
SELECT s_name,c_name,s_score from student
join score USING(s_id)
join course USING(c_id)
where s_id in
(SELECT s_id from score where s_score>70);
#37、查询不及格的课程并按课程号从大到小排列
SELECT c_id,c_name,s_score from score
join course USING(c_id)
where s_score<60 ORDER BY c_id desc;
#38、查询课程编号为03且课程成绩在80分以上的学生的学号和姓名
SELECT s_id,s_name from student
join score USING(s_id)
WHERE c_id=‘03’ and s_score>80;
#39、查询选了课程的学生人数
SELECT count(DISTINCT s_id) from score ;
#40、查询选修“张三”老师所授课程的学生中成绩最高的学生姓名及其成绩
SELECT s_name,s_score from student
join score USING(s_id)
join course USING(c_id)
join teacher USING(t_id)
where t_name=‘张三’ and
s_id=(SELECT s_id from score ORDER BY s_score desc LIMIT 1)
#41、查询各个课程及相应的选修人数
SELECT c_name,count(1) 选课人数 from score join course USING(c_id) GROUP BY c_id;
#42、查询不同课程成绩相同的学生的学生编号、课程编号、学生成绩
SELECT DISTINCT s1.s_id, s1.c_id,s1.s_score from score s1
join score s2 USING(s_id)
where s1.c_id<>s2.c_id and s1.s_score=s2.s_score;
#43、查询每门课程成绩最好的前两名
SELECT * from score s1 where
(SELECT count(1) from score s2
where s1.c_id=s2.c_id and s1.s_score<s2.s_score)<=1
ORDER BY c_id;
#44、统计每门课程的学生选修人数(超过5人的课程才统计)。要求输出课程号和选修人数,查询结果按人数降序排序,若人数相同,按课程号升序排序
SELECT c_name,count(s_id) from score
join course USING(c_id)
GROUP BY c_id HAVING count(s_id)>5
ORDER BY count(s_id) desc,c_id;
#45、查询至少选修两门课程的学生学号
SELECT s_id from score GROUP BY s_id HAVING count(c_id)>=2;
#46、查询选修了全部课程的学生信息
SELECT *from student
join score USING(s_id)
GROUP BY s_id HAVING count(c_id)=
(SELECT count(c_id) from course);
#47、查询没学过“张三”老师讲授的任一门课程的学生姓名
SELECT * from student where s_id not in
(SELECT s_id from score
join course USING(c_id)
join teacher USING(t_id)
where t_name=‘张三’);
#48、查询两门以上不及格课程的同学的学号及其平均成绩
SELECT s_id,avg(s_score) from score
where s_score<60
GROUP BY s_id
HAVING count(c_id)>=2;
#49、检索课程编号为“03”且分数小于60的学生学号,结果按按分数降序排列
SELECT s_id from score where c_id=‘03’ and s_score<60
ORDER BY s_score desc;
#50、删除学生编号为“02”的课程编号为“01”的成绩
DELETE from score where s_id=‘02’ and c_id=‘01’;
认识MySQL
Mysql的概念
一个系统的几个部分
-
前端(页面: 展示,数据!)
-
后台 (连接点:连接数据库:jdbc,连接前端:SpringMVC,控制视图跳转和给前端传数据)JavaEE: 企业级开发 Web
-
数据库(存数据,Txt,Excel,word)
只会写代码,学好数据库,基本混饭吃;
操作系统,数据结构与算法!当一个不错的程序员了!
离散数学,数字电路,体系结构,编译原理。 + 实战经验 高级程序员
什么是数据库
数据库(DB,database)
概念:数据仓库,软件,安装在操作系统之上!
数据库语言:SQL,操作数据库的语句,可以存储大量的数据。500条的数据都可以存,500以上要做索引的优化,也可以存。
作用:数据库是用来存储数据,管理数据 。Excel和数据库是没什么区别的,只不过数据库是要用sql语句操作。
什么是表
数据库中最基本的单元是表:table 什么是表,为什么用表来存储数据?--存储数据的一种方式 数据库当中是以表格的形式表示数据。关系型数据库可以理解为表的集合 因为表比较直观。 任何一张表都有行和列: 行:row:被称为数据/记录。 列:column:被称为字段。每个字段都有数据类型。 字段名是一个普通的名字,见名知意就行。 数据类型:字符串,数字,日期等。 约束:唯一性约束,这种约束添加之后,该字段中数据不能重复。
为什么学习数据库
1、岗位需求
2、现在的世界,大数据时代~,得数据者得天下。
3、被迫需求:存数据
4、数据库是所有软件体系中最核心的存在 DBA: 数据库管理员
在国外,也有公司把DBA称作数据库工程师(Database Engineer),两者的工作内容基本相同,都是保证数据库服务7*24小时的稳定高效运转,但是需要区分一下DBA和数据库开发工程师DBD (Database Developer): 1) 数据库开发工程师的主要职责是: 设计和开发数据库管理系统和数据库应用软件系统,侧重于软件研发; 2) DBA的主要职责是运维和管理数据库管理系统,侧重于运维管理。
数据库分类
关系型数据库:Excel,行跟列。(SQL)
-
MySql,Oracle,SqlServer,DB2,SQLite,PG库
-
通过表与表之间,行和列之间关系进行数据的存储
非关系型数据库:{key: value}。(NoSql)Not only SQL
-
Redis,MongDB
-
对象存储,通过对象的属性来决定。
DBMS数据库关系系统
-
是一个数据库管理软件,科学有效的管理我们的数据。维护和获取数据;
-
MySql本质是数据库管理系统!
SQL分类
DQL:查询语言 select
DML:操作语言(对表中数据增删改)insert delete update,改表的数据
DDL:数据定义语言 create drop alter,操作表的结构,不是表数据
TCL:事务控制语言,包括事务提交,事务回滚
DCL:数据控制语言,授权 grant,撤销权限 revoke
MySql常用命令
--查看库 show databases; MySQL默认带了四个数据库 --查看表 show tables; --选择库 use test; --建库 create database bjpowernode; --退出 exit --查看建表语句 show create table tableName; --不看表中数据,只看表的结构,(如果要单论查询表结构,这个语句更直观) desc tableName --查看数据库版本号 select version(); --查看当前使用的哪个数据库; select database(); --终止语句执行,(这个在SQLyog里面用不了) \c
DQL (数据查询语言)
查询Oracle库里正在执行的任务
# 下面这段代码不用改,直接复制到dp平台就行 SELECT s.sid, s.serial#, s.username, s.machine, s.program, s.sql_id, t.sql_text FROM v$session s JOIN v$sql t ON s.sql_id = t.sql_id WHERE s.status = 'ACTIVE'; # 杀掉当前正在执行的SQL ALTER SYSTEM KILL SESSION '<sid>, <serial#>'; # 在上面的语句中,<sid>和<serial#>是正在执行任务的会话的SID(会话ID)和序列号。

输出按固定顺序排序
-
order by decode(字段,'字段值',顺序........)

输出顺序固定按照上城,西湖。。。。这样往下排。
select * from temp_qlxq_okr_res order by decode (分公司,'上城',1,'西湖',2,'拱墅',3,'钱塘',4,'滨江',5,'萧山',6,'富阳',7,'余杭',8,'临平',9,'建德',10,'淳安',11,'桐庐',12,'临安',13);
列参与数学运算
MySQL中列可以进行四则运算:相加,相减,相乘,相除。还可以进行聚合,拼接等操作。
-- 相加 SELECT id+pc_id FROM `ODS_CZT_TJJ_SJBD_QYXX_DA`; -- 相乘 select ename,sal*12 from emp;
子查询几种类型
-
概念:select语句中嵌套select语句,被嵌套的select 语句称为子查询
-
可出现位置:select,from,where后面都可以
select ..(select..) from ..(select..) join ..(select..) where ..(select..)
公用表达式with as
1.可以让子查询重用相同的with查询块,并在select查询块中直接引用,一般如果在select查询块会多次使用某个查询SQL时,会把这个SQL放在with as中作为公用的表达式,通过别名的方式在主查询中重复使用。 with as的用法可以通俗点讲是,将需要频繁执行的slq片段加个别名放到全局中,后面直接调用就可以,这样减少调用次数,优化执行效率。


1. CTE后面必须直接跟使用CTE的SQL语句(如 select 、 insert 、 update 等),否则,CTE将失效。如下面的SQL语句将无法正 常使用CTE: with cr as ( select CountryRegionCode from person.CountryRegion where Name like 'C%' ) select * from person.CountryRegion -- 应将这条SQL语句去掉 -- 使用CTE的SQL语句应紧跟在相关的CTE后面-- select * from person.StateProvince where CountryRegionCode in ( select * from cr)
必须要分组,但查询结果不出现分组字段的处理
-
要对哪个字段进行group by,可以先对字段所在那张表但对group by,把这张表写成子查询
需求:按订单数量分组,查询单次购买商品总价大于1000的顾客姓名和总价
--写法一:
select cust_name,
sum(a.item_price*a.quantity) as total_price
from OrderItems a
join Orders b on a.order_num =b.order_num
join Customers c on c.cust_id=b.cust_id
group by cust_name
having total_price>=1000
order by total_price;
--写法二:
SELECT c.cust_name,tb.total_price
FROM
Customers c
JOIN Orders o ON c.cust_id = o.cust_id -- o表在这里起一个把c表和tb表关联起来的作用,它里面什么列也不查
JOIN( -- join后面也可以接子查询
SELECT
order_num,
SUM(item_price*quantity) AS total_price --SUM(item_price*quantity) 不要忘了前面的sum
FROM OrderItems
GROUP BY order_num -- 对下单数量进行分组
HAVING total_price >= 1000
) tb
ON tb.order_num = o.order_num
ORDER BY tb.total_price ASC;
-- 上述这两种写法效果相同
-- 写法三:最棒的写法,用row_nowmber
-- 需求:szx.D_EOMS_BA_WR_ZXDLKT_D_20230206 这个表只对对crmid分组,按createtime进行排序,拿每个组第一条的全量字段
select
ORDERID
,CRMID
,CREATETIME
,CUSTOMNAME
,PRODUCTNAME
,CITYNAME
,STATUS
,STATE
,CURRENTSTEP
,CUSTOMNO
,GROUPBILLINGNUMBER
,P_DAY
from (
SELECT a.*
,row_number() over(partition by crmid order by CREATETIME desc ) as rank -- 对crmid分组,按createtime进行排序
FROM szx.D_EOMS_BA_WR_ZXDLKT_D_20230206 a
)
where rank = 1 -- 取第一条
and crmid in ('7120221030113716E17528787','7120220916170445E17062829');
关于连接
左连接保留那部分数据的问题
-- 假设:t1和t2表数据没有重复 select t1.* from t1 left join t2 on (t1.a=t2.a) -- 此时:保留t1表所有字段 select t1.* from t1 left join t2 on (t1.a=t2.a) where t1.b > 10; -- 此时,依旧保留t1表所有数据,只不过会在关联后,把满足t1.b > 10 的数据去掉。 select t1.* from t1 left join t2 on (t1.a=t2.a) where t2.b > 10; -- 此时,不会保留t1所有数据,只保留满足t1和t2的a字段能匹配上的数据,因为首先left关联后,t2表关联不上的数据所有列为null,接着对t2.b限制了>10,null自然不满足,所以b表为null的a表关联的数据也删掉了,所以起到的是inner join的效果。
-
外健约束对多表查询一点影响也没有!
Oracle左连接、右连接、全外连接
https://blog.csdn.net/djrm11/article/details/114539374
-
左外连接(关联时对左边的表不加限制)
-
右外连接(关联时对右边的表不加限制)
-
全外连接(关联时对两边的表都不加限制)
外连接的含义:在左连接和右连接时,都会以一张A表为基础表,该表的内容会全部显示,然后加上和B表匹配的全部内容。如果A表的数据在B表中没有记录,那么相关联的结果集行中列的数据为空值(null)。
Oracle(+)号用法
对于外连接,也可以用(+)来表示 1.(+)操作符只能出现在where子句中,并且不能跟outer join语法同时使用。 2.当使用(+)操作符执行外连接时,如果where子句中包含多个条件,则必须在所有条件中都包含(+)操作符。 3.(+)只适用于列,不能用在表达式上【这个是啥意思,没太懂】。 4.(+)操作符不能和or和in操作符一起使用。 5.(+)操作符只能用于实现左外连接和右外连接,不能用于实现完全外连接。
-- 下面这3条语句等价 select * from t_A a left join t_B b on a.id = b.id; 或 select * from t_A a left outer join t_B b on a.id = b.id; 或 Select * from t_A a,t_B b where a.id=b.id(+); -- 用(+)来实现, 这个+号可以这样来理解: + 表示补充,即哪个表有加号,这个表就是匹配表。如果加号写在右表,左表就是主表,全部显示,所以是左连接。
连接类型
-
交叉连接cross join
语法:select * from A, B 或 select * from A cross join B
说明:就是不加任何限制条件的连接,会产生笛卡尔积,实际就是将两张表的数据相乘,就是用一张表的每一行去匹配另一张表的每一行
select a.序号,b.姓名,a.班级,a.年龄,b.语文,b.数学,b.地理,b.历史 from Table_4 as b cross join Table_5 as a -- from Table_4 as b , Table_5 as a where a.序号=b.序号;
-
内连接inner join
--隐式内连接(sql92标准):select * from A,B where 条件;
--显示内连接(sql99标准):select * from A inner join B on 条件;
join等价于inner join内连接,是返回两个表中都有的符合条件集合。
--1.查询研发部和销售部的所属员工
select *
from dept a
join emp b on a.depton=b.dept_id and name in ('研发部','销售部')
--2.查询每个部分的员工数,并升序排序
select a.deptno,count(1)
from dept a
join emp b on a.deptno=b.dept_id
group by a.deptno
order by a.deptno;
--思考,查询字段出现部门名可不可以呢???
select a.name,a.deptno,count(1)???? --如果部门名和部门号是一一对应的,那是可以的,但如果部门号对应多个部门名,机器识别不了,就会报错,比如:select b.age,a.deptno,count(1)
-
外连接outer join
-
左(外)连接 left join
先查询出左表,以左表为主,然后查询右表,右表满足条件的显示出来,不满足条件的显示null
-
左连接,左表数据量增量的情况
CREATE TABLE student_table( id INT(8), NAME VARCHAR(20), birth VARCHAR(20), sex VARCHAR(4) ); INSERT INTO student_table(id,NAME,birth,sex)VALUES ('1004' , '张三' ,'2000-08-06' , '男'); INSERT INTO student_table(id,NAME,birth,sex)VALUES ('1009' , '李四', '2000-01-01', '男'); INSERT INTO student_table(id,NAME,birth,sex)VALUES ('1010' , '李四', '2001-01-01', '男'); INSERT INTO student_table(id,NAME,birth,sex)VALUES ('1006' , '王五', '2000-08-06' , '女'); INSERT INTO student_table(id,NAME,birth,sex)VALUES ('1008' , '张三', '2002-12-01', '女'); INSERT INTO student_table(id,NAME,birth,sex)VALUES ('1012' , '张三', '2001-12-01', '女'); INSERT INTO student_table(id,NAME,birth,sex)VALUES ('1011' , '李四', '2002-08-06' , '女'); SELECT t1.*,t2.* FROM (SELECT * FROM student_table WHERE sex = '男') t1 -- 左表此时3条数据 LEFT JOIN (SELECT * FROM student_table WHERE sex = '女') t2 ON t1.name = t2.name ;查询结果(注意张三出现了两次)

左连接数据变多的原因: 首先左连接, 左表内容全部出现, 没有问题. 张三出现两次只因为关联条件是name, 因为张三在右表有两个, 所以和左表关联了两次, 所以就出现了两次。 总结:就是左表的关联条件在右表有多条的时候,那么左表的这条数据在关联后就会变成右表的条数。
-
关于left join后能不能接where的问题
SELECT t1.*,t2.* FROM (SELECT * FROM student_table WHERE sex = '男') t1 LEFT JOIN (SELECT * FROM student_table WHERE sex = '女') t2 ON t1.name = t2.name WHERE MONTH(t1.birth) = 1;
一旦使用了left join,没有where条件时,左表table1会显示全部内容
使用了where,只有满足where条件的记录才会显示(左表显示部分或者全部不显示)
so。。。。
left join的困惑:一旦加上where条件,则显示的结果等于inner join
-
右连接 同上相反
-
--又分为左外(left join),右外,全外连接(full outer join) select * from A left join B on 条件; --left join左连接,是返回左表中所有的行及右表中符合条件的行,(左表中所有的记录以及右表中连接字段相等的记录)如果右侧没有返回null,返回行数与左边想同。 --注意:oracle里面有full join,可是在mysql里面对full join支持的不好,可以通过union实现。
-
子查询 select的嵌套
-
自关联(将一张表当做多张表来用)


-
左连接要注意
select a.资源点,b.地址,b.补充地址b.覆盖区域,c.ADDRESS_DESC,c.覆盖区域名称 from t1 a left join t2 b on (a.BILL_ID=b.账号) left join t3 c on (a.BILL_ID=c.bill_id) -- 注意: 如果a表和b表,a表和c表都是left join,那么可以保证a表的数据不减少,至于a表会不会增多,则要看b表和c表同时和a表其中一条数据能匹配的情况。 如果要保证a的数据不能增加,也不能减少,就要确保b,c和a的关联字段要唯一。 但如果,a表和b表左连接,a和c是join,那么,如果a表和c表关联不上的数据依旧会不显示。 select a.资源点,b.地址,b.补充地址b.覆盖区域,c.ADDRESS_DESC,c.覆盖区域名称 from t1 a left join t2 b on (a.BILL_ID=b.账号) join t3 c on (a.BILL_ID=c.bill_id) -- 只保留a和c的交集
外连接
内连接的特点:把完全能匹配上on这个连接条件的数据查出来 什么时候用外连接: 左外连接left join: 将左表的全部数据展示,右表和左表关联条件相同的展示出来,匹配不上的,不展示。 全外连接full join: 将左表和右表全部的数据进行展示, 匹配不上的, 显示为空
全外连接和union all的区别: (MySQL里不支持全连接,会报错) 全外连接有个两表匹配的过程, 而union all没有这个过程. [SQL]select * from t_user t1 full outer join t_role t2 on t1.id = t2.id; [Err] 1064 - You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'full outer join t_role t2 on t1.id = t2.id' at line 1 :mysql中可以使用union all加左右连接实现full join的效果 -- mysql的full join:返回左右表中所有的记录和左右表中连接字段相等的记录。 select * from t_user t1 left join t_role t2 on t1.id = t2.id union all select * from t_user t1 right join t_role t2 on t1.id = t2.id where t1.id is null
表关联后on的位置在哪里的问题
题目:有表OrderItems代表订单商品信息表,prod_id为产品id;Orders表代表订单表有cust_id代表顾客id和订单日期order_date;Customers表含有cust_email 顾客邮件和cust_id顾客id
select c.cust_email from Customers c inner join Orders b inner join OrderItems a on c.cust_id=b.cust_id --on写在这里是错的 on b.order_num=a.order_num --on写在这里是错的 where prod_id='BR01' select c.cust_email from Customers c inner join Orders b on c.cust_id=b.cust_id --on写在这里是对的 inner join OrderItems a on b.order_num=a.order_num --on写在这里是对的 where prod_id='BR01'
-
总结:
on的关联条件必须紧跟在join的后面,不能把所有join都写完再一起写on,那样会报下面的错(不知道字段): SQL_ERROR_INFO: "Unknown column 'c.cust_id' in 'on clause'"
连接时表示在30-40之间
BETWEEN 30 AND 40;
关于连接数据笛卡尔激增
说明:join 和 left join一样,都会发生
当A表关联B表,C表等表时,如果A表的B表的关联字段(如col1)是没有数据重复,左关联后,结果表数据量以左表为主,内关联数据量为两表的交集。
当A表的col1数据无重复,B对应col1有多(比如3)条,关联后的结果表将是3条,如果A的col1是两条,B的3条,结果表就是2*3,变成6条。
可见:在进行数据关联的时候,关联字段的数据唯一是多么重要!!!
关于查询
子查询
-
不相关子查询
-- 子查询不会引用父查询中的列 select * from t1 where t2.x in (select y from B);
-
相关子查询(推荐)
-- 子查询会引用父查询中的列 select * from t1 where exists (select 1 from t2 where t1.x=t2.y)
备注:上面两个查询结果一样,但是用相关子查询效率高!
基本的子查询
-
就是将查询结果当成一个表进行二次运用,就是进行
无限的嵌套 -
子查询因为自己形成一张临时表,所以一定要给起别名
-
注意:如果关联查询和子查询同时可用的情况下,关联查询效率较高
子查询中的关键字
-
子查询中,有一些常用的逻辑关键字,可以给查询提供更丰富的功能,关键字如下:
1、all关键字:表示查询的条件必须满足这所有的条件
-
格式
select ... from ...where C > all(查询语句) -- 等价于 select ... from ...where c > result1 and c > result2 and c > result3
-
特点
1. all:与子查询返回的所有值比较都为true,则返回true 2. all表示指定列中的值必须大于子查询集的每一个值,即需要大于查询集的最大值;反之小于最小值。
-
操作
-- 查询年龄大于'1003'部门所有年龄的员工信息 select * from emp3 where age > all(select age from emp3 where dept_id = '1003'); -- 查询不属于任何一个部门的员工信息 select * from emp3 where dept_id != all(select deptno from dept3);
2、any和some关键字:表示满足任何一个条件即可,它两作用一样
-
格式
select ... from ... where c > any(查询语句) -- 等价于 select ... from ... where c > result1 or c > result2 or c > result3
-
特点
1. any或some与子查询的返回值比较,只有一个为true,则返回true 2. 表示大于子查询集中的最小值,小于最大值
-
操作
-- 查询年龄大于‘1003’部门任意一个其他部门的员工年龄的员工信息(意思就是查emp3这张表,只要这里面的员工年龄大于1003部门最小年龄的员工,那你就给我显示出来) select * from emp3 where age > any(select age from emp3 where dept_id = '1003') and dept_id != '1003';
4、in关键字:
5、exists关键字
-- 子查询会引用父查询中的列 select * from t1 where exists (select 1 from t2 where t1.x=t2.y)
对表某些字段去重,查询该表所有字段(自关联实现)
-
因为disticnt去重只能放在最左边有问题,这么好像去不了重
truncate table DM_KNOWLEDGEGRAPH_INDEX_VALUE_QI; -- truncate会锁整表,尽量不要用,delete from是锁行 insert into DM_KNOWLEDGEGRAPH_INDEX_VALUE_QI SELECT NULL,m.index_id,t.indicatorname,m.cur_total,t.unitname,t.timecode,t.provincename,t.cityname FROM ( SELECT indicatorname,unitname,timecode,provincename,cityname FROM temp_DM_KNOWLEDGEGRAPH_INDEX_VALUE_QI GROUP BY indicatorname,unitname,timecode,provincename,cityname )t LEFT JOIN temp_DM_KNOWLEDGEGRAPH_INDEX_VALUE_QI m ON t.indicatorname=m.indicatorname AND t.timecode=m.timecode AND t.cityname=m.cityname
-
用开窗函数啊!!!!!!!!!!!详见下面的开窗函数中的写法
select a.*, row_number(partition by colA,colB order by colC) as rn from table a -- 这样就实现了,对A,B字段分组,对C字段排序的作用
oracle库查询表的字段类型和字段长度
select column_name,data_type,DATA_LENGTH From all_tab_columns
where table_name=upper('temp_ziyuandian_allaaa')

查询MySQL的进程
show processlist;
查询的时候过滤空行、判空

SELECT DISTINCT index_name,provincename,cityname FROM `DM_KNOWLEDGEGRAPH_INDEX_QI_TMP` WHERE (provincename IS NOT NULL OR cityname IS NOT NULL); -- 不能用and WHERE (provincename IS NOT NULL and cityname IS NOT NULL); -- 这么查出来是空的
-
关于用is null或is not null对空行不起作用的问题
原因很有可能是该字符里面并不是空,而是一个空格,这样用is null就没法筛选出来了。
查询按想要的结果排序decode
select 。。 order by decode (分公司,'上城',1 ,'西湖',2 ,'拱墅',3 ,'钱塘',4 ,'滨江',5 ,'萧山',6 ,'富阳',7 ,'余杭',8 ,'临平',9 ,'建德',10 ,'淳安',11 ,'桐庐',12 ,'临安',13)
查询的顺序
(122条消息) 关于SQL语句的执行顺序vito99的博客-CSDN博客sql执行顺序
首先,要清楚在select语句中都会用到哪些关键字: 1.-----------from:笛卡尔积 2.-----------on:主表保留 3.-----------join:不符合on逻辑表达式也添加 4.-----------where:无法聚合,无法使用别名(子查询的能跟) 5.-----------group by 改变表的引用 6.-----------(max,min,count,sum...)聚合计算 7.-----------with_Rollup或withcube 8.-----------having:仅用于分组后 9.-----------select:选择列,起别名 10.----------distinct:行去重 11.----------order by:无法引用表达式 12.----------limit 其次,要知道每执行一步就会生成一个对应的虚拟表:
关联条件放在on和where后面的区别
首先说明,这两段代码的SQL执行结果是不同的,第一段代码行数多。
select a.*,b.* from TableA a join TableB b on (a.city_id = b.city_id and a.s_time ='2023-04-30') ; -- on后跟的条件只是决定哪些数据参与join, -- 上文的on后面的意思指,a表和b表的city_id拿出来,并且只要a表s_time为2023-04-30的数据进行join
select a.*,b.* from TableA a join TableB b on (a.city_id = b.city_id) where a.s_time ='2023-04-30' -- where后面跟的条件是筛选出符合要求的条件
查询是拼一个汇总行
如果汇总行需要用到不止一张表,需要先把用到的表先join起来写在一个子查询里,然后再从这个子表sum
drop table qs_攻坚_okr; create table qs_攻坚_okr as select c.*,'20230523' as p_day from qs_攻坚_20230523 c union select '总计' as 分公司, sum(a.入户难小区数) as 入户难小区数, sum(a.户数_万) as 户数_万, sum(a.最终宽带数_万) as 最终宽带数_万, round(sum(a.最终宽带数_万)/sum(a.户数_万)*100,2)||'%' as 当前占有率, round((sum(a.最终宽带数_万)/sum(a.户数_万)-sum(a.上月最终宽带数_万)/sum(a.上月户数_万))*100,2)||'%' as 占有率月环比, sum(a.月累有效进驻小区) as 月累有效进驻小区, round(sum(a.当月有效进驻场次)/sum(a.入户难小区数)*100,2)||'%' as 进驻小区占比, sum(a.月竣工) as 月竣工, round((sum(a.月竣工)/07/(sum(a.上月月竣工)/30)-1)*100,2)||'%' as 日均竣工量月环比, sum(a.月受理) as 月受理, round((sum(a.月受理)/07/(sum(a.上月月受理)/30)-1)*100,2)||'%' as 日均受理量月环比, round((sum(a.月竣工)/sum(a.月受理+0.00001))*100,2)||'%' 受竣比, round((sum(a.月竣工)/sum(a.月受理)-0.642)*100,2)||'%' as 受竣比基准提升, sum(a.厅店覆盖小区) as 厅店覆盖小区, round((sum(a.厅店覆盖小区)/sum(a.入户难小区数))*100,2)||'%' 厅店覆盖率, sum(a.总结算) as 总结算, sum(a.达标小区) as 达标小区, sum(a.达标小区应得结算) as 达标小区应得结算, sum(a.达标小区实际结算) as 达标小区实际结算, sum(a.扣罚小区) as 扣罚小区, sum(a.扣罚小区应得) as 扣罚小区应得, sum(a.扣罚小区扣罚结算) as 扣罚小区扣罚结算, sum(a.扣罚小区实际结算) as 扣罚小区实际结算, sum(a.未启动小区数) as 未启动小区数, round((sum(a.未扣罚小区数量)/sum(a.入户难小区数)*100),2)||'%' 未启动小区占比, '--' as 受竣比基准值, '20230523' as p_day from ( select a.*, b.当前占有率 as 上月当前占有率, b.最终宽带数_万 as 上月最终宽带数_万, b.户数_万 as 上月户数_万, b.月竣工 as 上月月竣工, b.月受理 as 上月月受理, c.当月有效进驻场次, c.未扣罚小区数量 from qs_攻坚_20230523 a join ( select * from qs_攻坚_20230430 ) b on (a.分公司=b.分公司) join ( select 分公司, sum(nvl(当月有效进驻场次,0)) as 当月有效进驻场次, sum(case when 是否扣罚 is null then 1 else 0 end) 未扣罚小区数量 from temp_攻坚_20230523 group by 分公司 )c on (a.分公司=c.分公司) ) a ;
查重语法
-- 按某个字段查重 -- 语法:select COL_1 from TABLE group by COL_1 having COUNT(COL_1)>=2 SELECT id FROM DM_KNOWLEDGEGRAPH_INDEX_QI GROUP BY id HAVING COUNT(id)>=2; -- 查重多条重复数据(这个语法是以name,age为例) SELECT index_name,cityname,COUNT(1) FROM DM_KNOWLEDGEGRAPH_INDEX_QI GROUP BY index_name,cityname

-- 方法一: select * from t1 where t1.id not in ( -- 查数量不是多于一条的ID,即只查询那些id只有一条的对应的id select id from t1 group by id having count(1)>1 -- 对id进行分组,把id数量大于1条的对应id筛选出来 ); 疑问:这种去重方法会不会把重复的这条数据一条也不保留,直接全去掉了?? 优化:需要结合其他字段,比如结合日期,保留最新的的一条 select * from t1 left join ( select id,max(date) as dt from t1 group by id ) t2 on t1.id=t2.ID and t1.日期=t2.日期; -- 方法二:distinct select distinct col from demo; -- 对col列去重 -- 方法三:不去重的列加聚合函数如max --加入有5列,只对前3列里去重,剩下的后2列不做要求 select c1,c2,c3,max(c4),max(c5) from demo -- mysql中max也可以换成min或者any_value()表示随机取一个 group by c1,c2,c3 -- 方法四:用开窗函数:详见开窗函数部分
聚合查询(count,sum,max,group by,avg)
-
如果查询字段只有聚合函数,可以不用group by
SELECT SUM(score),COUNT(score),AVG(score),MIN(score) res FROM `exam_record`
聚合查询是纵向查询,是对一列的值进行计算,然后返回一个单一的值;另外聚合函数会忽略空值。
| 聚合函数 | 作用 |
|---|---|
| count() | 统计指定列不为null的记录行数 |
| sum() | 计算指定列的数值和,如果该列类型不是数值类型,计算结果为0 |
| max() | 计算指定列的最大值,如果该列是字符串类型,则使用字符串排序计算 |
| min() | 计算指定列的最小值,如果该列是字符串类型,则使用字符串排序计算 |
| avg() | 计算指定列的平均值,如果该列不是数值类型,则计算结果为0 |
-
avg函数
语法:AVG([ALL|DISTINCT] expression)
如果使用ALL关键字,AVG函数将获取计算中的所有值。 默认情况下,无论是否指定,AVG函数都使用ALL。 如果明确指定DISTINCT关键字,AVG函数将仅在计算中采用唯一值。 例如,有一组数据集(1,2,3,3,4)并将AVG(ALL)应用于此集合,AVG函数将执行以下计算: (1+2+3+3+4)/5 = 2.6 SQL 但是,如果指定:AVG(DISTINCT)将按如下方式处理: (1+2+3+4)/4 = 2.5
-
对null值的处理
1.count函数对null值的处理 如果count(*),则统计所有记录的个数,null这行也统计,count(1)和它的效果一样。 如果是count(x列),则统计不含null值的所有记录。 2.sum和avg对null的处理 这两个函数忽略null的存在,就像含null的这条记录不存在一样。avg的中的分母是不算null这行的。 3.max和min对null的处理 这两个函数同样忽略null的存在。

如果想把null这行的数据也要考虑,可以在建表的时候,对会出现null这里的字段后面跟个 default 0;
拼接查询
union:对两个表做行拼接,同时,自动删除重复的行
union all:对两个表做行拼接,保留重复的行
使用union或union all对多个表拼接时,每个表不用起别名,另外每个表后可以直接跟where条件,因为union是在最后执行
条件查询
查询出符合条件的
注意:在数据库中null不能使用等号进行衡量,需要使用is null -- <>或者!=:不等于 -- and:并且 -- or:或者,(注意同条件下,or的包含范围要比and包含范围大) select empno,ename,job from emp where job = 'manager' or job = 'salesman' -- between and..:位于两个值之间 -- is null:为null。(is not null 不为空) -- in:包含,相当于多个or(not in 不在这个范围中) -- like:模糊查询,支持%和_匹配 -- %:匹配任意个字符 -- _:一个下划线只匹配一个字符
-
and和or同时出现,and优先级比or高。如果想让or先执行,需要加()
-
开发中如果不确定优先级,加()就行了,不懂得话看如下语句:
--找出工资大于2500和编号为10的员工 或者 找到编号为20的员工 select * from emp where sal>2500 and deptno=10 or deptno =20; --找出工资大于2500的并且编号为10或者编号为20的员工 select * from emp where sal>2500 and (depno=10 or deptno =20);
in的用法
-
后面跟具体的值,不是范围
-
一般后面跟()
--查询工作岗位是manager和salesman的员工,下面两种写法的效果一样
1.select empno,ename,job from emp
where job ='manager' or job='salesman';
2.select empno,ename,job from emp
where job in('manager','salesman');
模糊查询
模糊查询某个字段
-
like '%colName%'
select * from ODS_YTB_VIEW_DATA_INDICATOR2_DA WHERE TEMPLETNAME like '%贸易方式B002%';
--找出名字字段中含有O的 select ename from emp where ename like '%O%'; --找出名字以K开始的 select ename from emp where ename like 'K%' -- 这个很常用 --找出名字以T结尾的 select ename from emp where ename like '%T'; --以『牛客』开头『号』结尾 like '牛客%号' -- 只需在中间写一个%就行,它起控制开头和结尾两个作用 --从 Products 表中查询产品名称(prod_name)和产品描述(prod_desc)字段,返回产品描述字段中同时出现 toy 和 carrots 的产品。 -- 方法一:这里是既匹配到这两个单词,又是按顺序的,是先carrots再toy select prod_name,prod_desc from Products where prod_desc like '%carrots%toy%' -- 方法二: --where prod_desc like '%toy%' and prod_desc like '%carrots%'
-
_
---和_一起用,表示后面只跟一个字符 like '李_' -- 表示找李某,而不是找李某某 --找出第二个字母是A的 select ename from emp where ename like '_A%'; --找出第三个字母是R的 select ename from emp where ename like '__R%'; --找出名字有_的 select name from t_student where name like '%\_%'; --\表示转义
模糊查询想要的表名
select * from all_tables where table_name like '%你要查的表名%';
查询时非空判断
= null 和 is null的区别
= 是个比较字符,null值不能与其他值进行比较,包括它自身。即使用colName = null 进行比较,也不会返回预期结果。 因此为了判断一个值是否为空,应该用is null。
条件查询时不能使用 =null 或!=null 进行比较,必须使用is null/is not null 分组排序时,null视为相等的分为一组 1,GROUP BY会把所有NULL值分到一组。 2,ORDER BY会把所有NULL值排列在一起。
查询关键字
group by
-
如果group by 某个字段 相当于: 在查询语句中按这个字段进行分组;如果没有group by,相当于对全局进行查询
-
在带有group by子句的查询语句中,在select列表中指定的列要么是group by字句中指定的列,要么包含聚组函数。但如果查询的只有聚合字段,后面可以不跟group by
-
反过来理解就是聚合函数可以不要求出现在group by里面。
-
group by后面可以跟别名。
-- 聚合函数 count(),返回指定列中数据的个数 sum(),返回指定列中数据的总和 avg(),返回指定列中数据的平均值 min(),返回指定列中数据的最小值 max(),返回指定列中数据的最大值
-
怎么实现查询某个字段
-- 错误写法 select device_id,university,min(gpa) from user_profile group by university -- 正确写法 select device_id,university,gpa from user_profile where (university,gpa) in ( select university,min(gpa) from user_profile group by university ) order by university -- 第二个select语句的子句列表中只包含university和聚集函数,因此不会报错,在查询到GPA最小值及学校后,再次进行查询即可增加device_id列。 -- 再来一个(牛客sql必知必会,97题) select cust_name,o.order_num,t.OrderTotal from Customers c join Orders o on c.cust_id=o.cust_id join( select order_num,sum(quantity*item_price) OrderTotal from OrderItems group by order_num )t -- 这个子查询就是先对order_num进行分组 on o.order_num=t.order_num order by cust_name,o.order_num
-
有个常见需求:统计每个月的活跃用户【count(distinct...)】
--正确写法: SELECT DATE_FORMAT(start_time,'%Y%m') AS start_month, -- 每个月 COUNT(DISTINCT uid) AS mau #月活用户 -- count(distinct...) 这个可以实现对另外一个字段的去重统计 FROM exam_record GROUP BY start_month; --错误写法: SELECT DATE_FORMAT(start_time,'%Y%m') AS start_month, uid, COUNT(1) FROM exam_record GROUP BY start_month,uid
-
group by和count(distinct)的区别
在传统关系型数据库中,group by与count(distinct)都是很常见的操作。count(distinct colA)就是将colA中所有出现过的不同值统计出现的次数,相信只要接触过数据库的同学都能明白什么意思。 count(distinct colA)的操作也可以用group by的方式完成,具体代码如下: :select count(distinct colA) from table1; :select count(1) from (select colA from table1 group by colA) a; 这两者最后得出的结果是一致的,但是具体的实现方式,有什么不同呢? 上面两种方式本质就是时间与空间的权衡。 distinct需要将colA中的所有内容都加载到内存中,大致可以理解为一个hash结构,key自然就是colA的所有值。因为是hash结构,那运算速度自然就快。最后计算hash中有多少key就是最终的结果。 那么问题来了,在现在的海量数据环境下,需要将所有不同的值都存起来,这个内存消耗,是可想而知的。所以如果数据量特别大,可能会out of memory。。。 group by的实现方式是先将colA排序。排序大家都不陌生,拿最见得快排来说,时间复杂度为O ( n l o g n ) O(nlogn)O(nlogn),而空间复杂度只有O ( 1 ) O(1)O(1)。这样一来,即使数据量再大一些,group by基本也能hold住。但是因为需要做一次O ( n l o g n ) O(nlogn)O(nlogn) 的排序,时间自然会稍微慢点。。。 总结起来就是:count(distinct)吃内存,查询快;group by空间复杂度小,在时间复杂度允许的情况下,可以发挥他的空间复杂度优势。
with rollup或with cube
【移动dm平台用不了】
with rollup,这个函数是对聚合函数再次进行求和,相当于下面再加个汇总行。
-- 例1 select name,count(id),sum(score) from score group by name with rollup; --就是下面的第三行(NULL)的效果,如果没有with rollup,则只有前两行 -- 例2 SELECT LEVEL,COUNT(DISTINCT id) FROM user_info GROUP BY LEVEL WITH ROLLUP;

having
having的使用: -- 区分where和having 1. where子句将单个行过滤到查询结果中,而having子句将分组过滤到查询结果中 2(重要). having子句中的列名必须出现在group by子句列表中,或包括在聚集函数中!!! 3. having子句的条件运算必须包括一个聚集函数,否则可以把查询条件移到where字句中来过滤单个行(注意聚集函数不可以用在where子句中) -- 正确写法: select cust_name, sum(item_price * quantity) total_price from OrderItems oi join Orders o on oi.order_num = o.order_num join Customers c on c.cust_id = o.cust_id (where total_price >= 1000) -- 这个是错误写法,where后面不能跟聚合过滤条件 group by c.cust_name having total_price >= 1000 -- 这个是聚合函数,只能写在having后面,因为where是单行聚合 order by total_price
distinct
-
distinct去重的原理
去重原理是通过先对要去重的数据进行分组操作,然后从分组后每组数据中取一条返回给客户端。
-
对查询到的字段去重处理
-- 对col1,col2,col3三个字段一起进行去重处理 select distinct col1,col2,col3 from table -- distinct不可以放在第一个字段之后
-
对所有字段进行去重
select distinct * from user; -- 等价于 select distinct id,name,age,sign from user
-
和group by的比较
-- 相同 二者返回的结果式样相同 -- 不同 1. group by必须在查询结果中包含一个聚合函数,而distinct不用 2. distinct是对查询的全部字段去重,group by可以针对查询字段的部分字段去重。 3. 性能上来看,因为distinct主要是对数据进行两两比较,需要遍历整个表。group by分组类似先建立索引再查索引,因此当数据量很大时,group by速度由于distinct
-
count和distinct的联合使用
-- 实现对templetname字段的去重统计 -- 写法一;这个简单 SELECT COUNT(DISTINCT templetname) FROM `dm_fa_smart_hub_metrics_information_ma_1` -- 写法二: SELECT COUNT(1) FROM ( SELECT DISTINCT templetname FROM `dm_fa_smart_hub_metrics_information_ma_1` ) a
order by
-
升序 asc【低到高】,降序desc【高到低】
-- 默认升序 select ename,sal from emp order by sal [如果不写就默认asc]; -- 降序 select ename,sal from emp order by sal desc;
-
排序的位置:排序要写在最后,不能先排序,再拼接
如果要把order by写在每个单独的语句后面怎么写?
-- 就是把每个自语句再写个select查询给包起来 SELECT * FROM ( SELECT exam_id AS tid,COUNT(DISTINCT uid) uv,COUNT(exam_id) pv FROM exam_record GROUP BY exam_id ORDER BY uv DESC,pv DESC ) t1 UNION SELECT * FROM ( SELECT question_id AS tid,COUNT(DISTINCT uid) uv,COUNT(question_id) pv FROM practice_record GROUP BY question_id ORDER BY uv DESC,pv DESC ) t2;
-
可以对union all后的语句进行排序
SELECT prod_id,quantity FROM OrderItems WHERE quantity='100' UNION ALL SELECT prod_id,quantity FROM OrderItems WHERE prod_id=SUBSTR(prod_id,1,4) ORDER BY prod_id -- 将两个字段名不相同的,也可以拼一起排序,拼成后的字段名以前一个表的字段名命名 SELECT cust_name FROM Customers a UNION ALL SELECT prod_name FROM Products ORDER BY cust_name
-
order by后面可以跟聚合函数吗: 可以
select id2,sum(num1) from table1 where id1 = '123' group by id2 order by sum(num1)
-
多字段如何排序:直接在order by后面写要进行排序的字段
-
order by A,B
--查询员工名字和薪资,要求按照薪资升序,如果薪资一样,再按照名字降序序排列 select ename,sal from emp order by sal asc,ename desc; -- 对多个字段都使用降序排列(需要在每个字段后都加desc) select ename,sal from emp order by ename desc,sal desc;
-
根据查询字段位置排序:order by 字段位置;
select ename,sal from emp order by 2; --根据第二列排序,了解即可,开发中不建议这么写
-
order by 字段后+数字的含义
order by 字段+随意一个数字就会按照1,2,3,的阿拉伯数字顺序排序。如果排序字段后不加数字的话,如果这个字段里如果是数字,就会以先1,11,12,。。。19,2,21,22,。。。,3,31这样开始。结论:加个数字是为了将改字段进行强制转换成数值类型看。
-
order by 后面可以跟字段的别名吗?
可以!!
关于函数
控制流函数
if
-
if 函数在Oracle中用不了!!!!
IF(contion,return1,return2) # 如果contion是TRUE (expr1 <> 0和expr1 <> NULL),则IF() 返回expr2。否则,它返回expr3。 SELECT a.device_id, university, count(question_id) as question_cnt, sum(if(b.result = 'right',1,0)) as right_question_cnt FROM user_profile a LEFT JOIN question_practice_detail b ON a.device_id = b.device_id AND MONTH(`date`)=8 WHERE university = "复旦大学" GROUP BY b.device_id;
case when
-
注意:case when 的then后面,不能写判断是,比如等于,直接写结果
SELECT USER_ID,BILL_ID,PLAN_ID,ORDER_NAME,LL_PROD_ID,YUEFEI_LL,月份,超套金额, case when 超套金额/100 <=15 then 超套流量 = 超套金额/100/5 -- 这么写是错误的,then后面不能写等式 when 超套金额/100 > 15 then (超套金额/100-15)/3+3 -- 这么写是对的 else 0 end as 超套流量 FROM temp_llcttf1;
-
嵌套case when
-- 算超套流量(user_id,BILL_ID,PLAN_ID,order_name,LL_PROD_ID,YUEFEI_LL,月份,超套金额)
alter table temp_llcttf1 add 超套流量 number;
drop table temp_llcttf2;
create table temp_llcttf2 as
SELECT
USER_ID,BILL_ID,PLAN_ID,ORDER_NAME,LL_PROD_ID,YUEFEI_LL,超套金额,月份,
case
when YUEFEI_LL<=50 then
round(超套金额/100/10,4) -- 如果流量套餐费用小于等于50,每G/10块
when YUEFEI_LL > 50 then
(case when 超套金额/100 <=15 then round(超套金额/100/5,4) -- 超套金额是1000的话表示超套流量是2G,上面如果月费小于50,2G就要20
when 超套金额/100 > 15 then round((超套金额/100-15)/3+3,4)
else 0 end)
end as 超套流量G
FROM temp_llcttf1;
-- 刷:日均竣工量月环比
-- 日均竣工量月环比:本月日均竣工量 vs 上月日均竣工量
merge into qs_攻坚_${taskid} a
using(
select c.分公司,
case when 上月日均竣工量>0 then round(((本月日均竣工量-上月日均竣工量)/上月日均竣工量)*100,2)||'%' end 日均竣工量月环比
from (
select a.分公司,本月日均竣工量,上月日均竣工量
from (
select 分公司,round(月竣工/${cur_dd},2) 本月日均竣工量
from qs_攻坚_${taskid}
) a
left join (
select 分公司,round(本月宽带竣工量/${lm_days},2) 上月日均竣工量
from temp_攻坚_${lm_mtaskid}_okr
) b on (a.分公司=b.分公司)
) c
) b on (a.分公司=b.分公司)
when matched then update set
a.日均竣工量月环比=b.日均竣工量月环比;

-
case when的when后面跟的条件可以不是同一列
case when可以对多列条件进行判断
create table temp_mzmc_0131_qd as -- 5213 select a.GHSJHM, case when TRAVEL_PLACE is null then '杭州' when TRAVEL_PLACE = '571' then '杭州' when TRAVEL_PLACE = '570' then '衢州' when TRAVEL_PLACE = '574' then '宁波' when TRAVEL_PLACE = '577' then '温州' when TRAVEL_PLACE = '575' then '绍兴' when TRAVEL_PLACE = '572' then '湖州' when TRAVEL_PLACE = '573' then '嘉兴' when TRAVEL_PLACE = '579' then '金华' when TRAVEL_PLACE = '576' then '台州' when TRAVEL_PLACE = '578' then '丽水' when TRAVEL_PLACE = '580' then '舟山' when TRAVEL_TYPE = 2 then '出省' -- 注意看,这里的case when可以不是同一列 when TRAVEL_TYPE = 3 then '出国' else TRAVEL_PLACE end as 目的地 , TRAVEL_PLACE, b.TRAVEL_TYPE,b.TRAVEL_DAYS,b.TRAVEL_TIMES,b.TRAVEL_DATES,b.P_DAY from qs_opid_10_20_26 a -- 5207 left join ( select * from szx.A_TPOS_TRAVEL_20230130 where p_day = 20230130 and travel_dates like '%20230130%' ) b on a.GHSJHM=b.BILL_NO;
case when 这形成的是一个列
select [*,] --[]表示可选项 case expression when condition1 then result1 --如果c1满足,则执行r1 when condition2 then result2 --如果c2满足,则执行r2 ... when conditionN then resultN --如果cN满足,则执行rN else result --上面都不满足,则执行else后面的语句 end as info --结束,可以在末尾再给这个列起个别名 [from table] --注:会逐条进行判断,当有个条件满足时,后面的就不执行了 --写法一: select case 6 when 1 then '你好' when 2 then 'hello' when 6 then 'correct' else '其他' end as info; --写法二:(这个相当于写在一列里进行条件判断) select case --这也可以不加东西,直接在when后面跟判断条件 when 2>1 then 'nihao' --条件已经满足,执行到此为止 when 2<1 then 'hello' when 3>2 then '正确' --虽然这个条件也满足,但是因为第一条已经满足,所以就不在往下执行 else '其他' end as info;
-
在表里直接判断的写法
-- 情况介绍 select * from V2 -- 这张表的时,发现areaid部分为-1,同时areaname部分为null -- 此时我需要将areaid为-1的转为‘863300000000000’,areaname为空的,转为‘浙江’。我之前的做法时,在最后再加个SQL组件,用update语法: UPDATE DWD_FT_DT_INDUSTRY_SERVICE_TRADE_ZHEJIANG_MA SET areaid=863300000000000 WHERE areaid='-1'; UPDATE DWD_FT_DT_INDUSTRY_SERVICE_TRADE_ZHEJIANG_MA SET areaname='浙江' WHERE areaname is null; -- 但是上面这个要耗费MySQL查询资源,此时直接可以在查询的时候,用case when直接查询即可 -- 下面这个(mysql语法) SELECT templetcode,templetname, CASE WHEN areaid = '-1' THEN '863300000000000' ELSE areaid -- 其他情况统统用表中原值替代,我之前写的when areaid != '-1' then areaid,这种写法不好!! END AS areaid, CASE WHEN areaname IS NULL THEN '浙江' ELSE areaname -- 其他情况统统用表中原值替代 END AS areaname, CONCAT(indicatorid,'&',member1id) AS indicatorid,CONCAT(indicatorname,'&',member1name) AS indicatorname, timecode,unitname, SUM(CASE WHEN calcname ='累计' THEN `value` END) as total, SUM(CASE WHEN calcname ='累计增长' THEN `value` END) as total_growth FROM ODS_YTB_VIEW_DATA_INDICATOR2_DA WHERE templetname = '浙江分行业服务贸易统计表(累计)' GROUP BY templetcode, templetname, areaid,areaname, indicatorid,indicatorname, member1id,member1name, timecode,unitname;
-
case when里面有and或者or怎么写
-- and SELECT (CASE sex WHEN 0 THEN '男' ELSE '女' END) AS 性别 ,SUM(CASE address WHEN '北京' THEN 1 ELSE 0 END) AS 北京总人数 ,SUM(CASE WHEN (address ='北京' AND is_retire = 1) THEN 1 ELSE 0 END) AS 北京退休人数 ,SUM(CASE address WHEN '上海' THEN 1 ELSE 0 END) AS 上海总人数 ,SUM(CASE WHEN (address ='上海' AND is_retire = 1) THEN 1 ELSE 0 END) AS 上海退休人数 ,SUM(CASE address WHEN '天津' THEN 1 ELSE 0 END) AS 天津总人数 ,SUM(CASE WHEN (address ='天津' AND is_retire = 1) THEN 1 ELSE 0 END) AS 天津退休人数 FROM USER GROUP BY 性别; -- or SELECT (CASE sex WHEN 0 THEN '男' ELSE '女' END) AS 性别 ,SUM(CASE WHEN (address ='北京' OR address ='上海') THEN 1 ELSE 0 END) AS 北京上海总人数 ,SUM(CASE WHEN (address ='上海' OR address ='天津') THEN 1 ELSE 0 END) AS 上海天津总人数 ,SUM(CASE WHEN (address ='天津' OR address ='北京') THEN 1 ELSE 0 END) AS 北京天津人数 FROM USER GROUP BY 性别; -- 我自己写的case when里有or的 SELECT indicatorname, (CASE WHEN areaname='浙江' THEN areaname END) AS province, (CASE WHEN (areaname LIKE '%__市%' OR areaname LIKE '%__区%') THEN areaname END) AS city FROM DM_FA_SMART_HUB_METRICS_INFORMATION_MA GROUP BY indicatorname,indicatorid,province,city;
温馨提醒
--上面的 select case 6 when 1 then '你好' when 2 then 'hello' when 6 then 'correct' else '其他' end as info; -- 和下面的 SELECT (CASE sex WHEN 0 THEN '男' ELSE '女' END) AS 性别 -- 第一列 ,SUM(CASE address WHEN '北京' THEN 1 ELSE 0 END) AS 北京总人数 -- 第二列 ,SUM(CASE WHEN (address ='北京' AND is_retire = 1) THEN 1 ELSE 0 END) AS 北京退休人数 -- 第三列 ,SUM(CASE address WHEN '上海' THEN 1 ELSE 0 END) AS 上海总人数 -- 第四列 ,SUM(CASE WHEN (address ='上海' AND is_retire = 1) THEN 1 ELSE 0 END) AS 上海退休人数 -- 第五列 ,SUM(CASE address WHEN '天津' THEN 1 ELSE 0 END) AS 天津总人数 -- 第六列 ,SUM(CASE WHEN (address ='天津' AND is_retire = 1) THEN 1 ELSE 0 END) AS 天津退休人数 -- 第七列 FROM USER GROUP BY 性别;
-
这两个不一样,第一个是在一列里对数据进行判断,更像if
-
第二个是多列,每一个逗号都是一列!!!!!
decode() 条件判断函数
这个函数在查询章类似于if函数 DECODE(expression, search1, result1, [search2, result2, ...], [default]) 参数说明: expression:要比较的表达式。 search1, search2, ...:要与expression进行比较的值。 result1, result2, ...:如果expression等于search值,则返回对应的结果。 default:可选参数,如果expression与所有search值都不匹配,则返回default值。如果未提供default值,则返回NULL。

窗口函数
MySQL8.0新增窗口函数(开窗函数,也叫非聚合函数,一次只会处理一行数据),窗口函数是相对于聚合函数来说的。聚合函数是对一组数据计算后返回单个值(即分组聚合后,每一组里面最后只剩下一条数据),而窗口聚合函数在其窗口范围内的每一行数据聚合的同时,还完整的保留每一行的原始数据,并不改变行数。
说白了,窗口函数可以做到,既显示聚集前的数据,又显示聚集后的数据。即在每一行的最后一列添加j聚合函数的效果。


开窗聚合函数:既有开窗函数的特点,又有聚合函数的特点
--窗口函数语法结构: window_function(expr) over( partition by ... order by ... frame_clause ) --window_function:窗口函数的名称;expr是参数,有些函数不需要参数,over子句包含三个选项。 --partition by: 用于指定按哪个字段进行分区,类似聚合函数里的group by,如果省略partition by,则所有的数据将作为一个组进行计算 --order by:用于指定分区内的排序方式,与order by的作用相似 --frame_clause: 用于在当前分组制定一个计算窗口,也就是与当前行相关的一个数据子集
打序号函数@row_number()|rank()|dense_rank() over(...)
-
开窗函数可以实现对某几个(一般是一到两个字段进行分组,对分组或者其他字段排序的功能)
-
这三个函数可以实现分组排序,并给分组排序后的数据每一个行加上一个序号
-
()小括号里面不加东西
-
oracle库里必须要跟order by,知道移动dm平台里要这样
--格式: row_number()|rank()|dense_rank() over( partition by ... order by ... ) as otherName --三个函数的区别 row_number的序号是完全自增的,就算排序字段出现重复值,序号依旧自增 rank的序号不是连续的,如果排序字段出现重复值,序号会出现隔断 dense_rank的序号是连续的,字段出现重复值,序号也会重复,比如出现并列第N --案例 1.对每个部门(dname)的员工按照薪资(salary)排序,并给出排名 select dname,ename,salary row_number() over(partition by dname order by salary desc) as rn from employee; 2.求出每个部门薪资排在前三的员工 --错误写法: select dname,ename,salary, dense_rank() over(partition by dname order by salary desc) as rn from employee where rn<=3 --错误原因:因为where的执行顺序在开窗函数之前,当where rn<=3时,还没有select dense_rank() --正确写法: select * from ( select dname,ename,salary, dense_rank() over(partition by dname order by salary desc) as rn from employee )t where t.rn<=3 --正确原因:from最先执行,所以此时临时表t的结果已经查询出来了,此时dense_rank()是肯定存在的 3.求整个公司的薪资的第一名 --去掉partition by就是全局排序 select * from ( select dname,ename,salary, dense_rank() over(order by salary desc) as rn from employee )t where t.rn<=1 -- 牛客136 -- 找到每类试卷得分的前3名,如果两人最大分数相同,选择最小分数大者,如果还相同,选择uid大者 -- 第一步:获取各个科目每个用户得分的最大值和最小值 SELECT b.tag,a.uid,max(a.score),min(a.score) FROM exam_record a LEFT JOIN examination_info b ON a.exam_id=b.exam_id GROUP BY b.tag,a.uid; -- 第二步:如果两人最大分数相同,选择最小分数大者,如果还相同,选择uid大者 ROW_NUMBER()OVER(PARTITION BY tag ORDER BY max(a.score)DESC,min(a.score)DESC,a.uid DESC) ranking -- 第三步:把上面两步拼接 SELECT b.tag,a.uid,max(a.score),min(a.score),/*这里写max(a.score)和min(a.score)是为了帮助理解窗口函数里的ORDER BY 后面的内容*/ ROW_NUMBER()OVER(PARTITION BY tag ORDER BY max(a.score)DESC,min(a.score)DESC,a.uid DESC) ranking FROM exam_record a LEFT JOIN examination_info b ON a.exam_id=b.exam_id GROUP BY b.tag,a.uid; -- 第四步:完整代码组装 select tag as tid,uid,ranking from ( select tag,uid,max(score),min(score), row_number() over(partition by tag order by max(score) desc,min(score) desc,uid desc) as ranking from exam_record a left join examination_info b on a.exam_id = b.exam_id group by tag,uid )t where ranking<=3; -- 这个一定要写在外面,因为where条件比select执行早,写在group by上面的时候,还没有生成ranking
开窗聚合函数@sum()|avg()|min()|max() over(...)
当开窗函数和聚合函数一起使用,可以实现累加,累减,累计求平均,累计求最小值,累计求最大值
在窗口中每条记录动态的应用聚合函数(sum(),avg(),max(),min(),count()),可以动态计算在指定的窗口内的各种函数的聚合函数值
sum(): 1.sum()over(order by ...):有order by是从第一行累计到当前行 2.sum()over():没有order by是默认把分组内的所有数据进行sum操作,没有累加的效果 select dname,ename,salary, sum(salary) over(partition by dname order by hiredate) as c1 --按部门进行分组,按入职日期进行排序,对每个部门的工资进行累加 from employee; --rows between..and..控制聚合的范围 1.从当前行的前三行开始,累加到当前行 select dname,ename,salary, sum(salary) over(partition by dname order by hiredate rows between 3 preceding and current row) as c1 from employee; 2.从当前行的前三行开始,向后一行,(包括当前行)进行累加 select dname,ename,salary, sum(salary) over(partition by dname order by hiredate rows between 3 preceding and 1 following) as c1 from employee; -- max(A) over(partition by B order by C) 根据B分组,组内通过C排序,取A最大值作为这个字段的值。 avg()|max()|min(): select dname,ename,salary, avg|max|min(salary) over(partition by dname order by hiredate rows between 3 preceding and 1 following) as c1 from employee;
分布函数@cume_dist(),percent_rank()
cume_dist():
用途:分组内小于、等于当前rank值的行数/分组内总行数
场景:查询小于等于当前薪资的比例
select dname,ename,salary, cume_dist() over(order by salary) as rn1, cume_dist() over(partition by dname order by salary) as rn2 from employee;

前后函数@lead,lag
说明:开窗函数可以和group by结合着使用
SELECT device_id,`date`, lead(`date`,1,'0000') over(PARTITION BY device_id ORDER BY `date`) AS lea FROM `question_practice_detail` a GROUP BY device_id,`date`
用途:返回位于当前行的前n行(lag(expr,n))或后n行(lead(expr,n))的expr的值
场景:查询前一名同学的成绩和当前同学成绩的差值
lag(): 表示新的这一列要把lag(原来这列)集体往下挪num个单位 select dname,ename,salary,hiredate, lag(hiredate,1,'2000-01-01') over(partition by dname order by hiredate) as time1, --第三个参数表示如果前一行没有值,填这个赋的值,该参数可以不写,不写默认为空 lag(hiredate,2) over(partition by dname order by hiredate) as time2 from employee;

lead(): 表示新的这一列要把lead(原来这列)集体往上挪num个单位 select dname,ename,salary, lead(hiredate,1) over(partition by dname order by hiredate) as time1, --第三个参数表示如果前一行没有值,填这个赋的值,该参数可以不写,不写默认为空 lead(hiredate,2) over(partition by dname order by hiredate) as time2 from employee;

头尾函数@ first_value(),last_value()
用途:返回第一个first_value(expr)或最后一个last_value(expr)的值
场景:截止到当前,按照日期排序查询第一个入职和最后一个入职的员工的工资
--注意:如果不指定order by,则排序混乱,会出现错误的结果 select dname,ename,hiredate,salary, --求每一个部门第一个入职的员工的薪资 first_value(salary) over(partiton by dname order by hiredate) as first, --求每一个部门最后一个入职的员工的薪资,last表示当目前为止本行 last_value(salary) over(partition by dname order by hiredate) as last from employee;
其他函数@nth_value(),ntile()
nth_value:
-
用法:
返回窗口中第n个expr的值。expr可以是表达式,可以是列名。
--案例 1.查询每个部门截止目前入职日期,薪资排在第二和第三的员工信息 select dname,ename,hiredate,salary nth_value(salary,2) over(partition by dname order by hiredate) as second_salary, nth_value(salary,3) over(partition by dname order by hiredate) as third_salary from employee;
字符串操作函数
拼接||,截取substr,查找instr ,替换replace
拼接 || ,concat
-
||
一、拼接字符串
1、使用“||”来拼接字符串:
select '拼接'||'字符串' as Str from student;
2、使用concat(param1,param2)函数实现:
select concat('拼接','字符串') as Str from student;
注:oracle的concat()方法只支持两个参数,如果拼接多个参数,可以嵌套concat():
select concat(concat('拼接','字符串'),'ab') as Str from student;
-
concat
-- 语法:
concat(s1,s2,s3...sn)
-- 效果:
将s1,s2,...,sn多个字符串合并为一个字符串
-- 示例:
select concat("sql ","is ","very ","useful ","language");
>>>
sql is very userful language
-- 三个字段拼接
select concat(concat(concat(concat(b.大类, '-'),b.中类),'-'), b.小类) as fj
from tab_region_info b
指定分隔符拼接 concat_ws
-- concat_ws()函数
功能:一次性指定分隔符
语法:concat_ws(separator,str1,str2,...)
说明:第一个参数指定分隔符 分隔符不能为空 如果为NULL 则返回值NULL
select concat_ws('-','hello','world');
>>>
hello-world
分组拼接 group_concat()
-- 这篇说的也很不错 https://blog.csdn.net/weixin_46544385/article/details/120563650?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522166738633216800182133231%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=166738633216800182133231&biz_id=0&utm_medium=distribute.pc_chrome_plugin_search_result.none-task-blog-2~all~top_positive~default-1-120563650-null-null.nonecase&utm_term=group_concat&spm=1018.2226.3001.4187

-
该函数用来实现行的合并(列转行)
该函数会首先根据group by指定的列进行分组,并用分隔符分隔,将同一个分组的值连接起来,返回一个字符串的效果
--语法: group_concat([distinct] 字段名 [order by 排序字段 asc/desc][separator '分隔符']) --(1)可以使用distinct排除重复值 --(2)如果需要对结果中的值进行排序,可以使用order by子句 --(3)separator是一个字符串值,默认为逗号 下面这段是云龙写的: SELECT a.templetName,GROUP_CONCAT(a.calcname) FROM ( SELECT templetName,calcname FROM ODS_YTB_VIEW_DATA_INDICATOR2_DA GROUP BY templetName,calcname ) a GROUP BY templetName ORDER BY templetName
-
案例1
--实现单行的列转行 --将所有员工的名字合并成一行 select group_concat(emp_name) from emp; --按不同部门实现人员名字的拼接,按薪资排序 select department, group_concat(emp_name order by salary desc separator ';') from emp group by department;
-
案例2
原数据

select brand_name, group_concat(distinct brand_classify separator '-') as brand_classify from tb_brand_classify group by brand_name;
用SQL实现后

截取 substr
在Oracle中可以使用instr函数对某个[字符串]进行判断,判断其是否含有指定的字符。在一个字符串中查找指定的字符,返回被查找到的指定的字符的位置。
-- substr(string,a,[b]),获取子字符串
string:源字符串
a:开始位置,当a等于0或1时,都是从第一位开始截取
b:字符串的长度[可选],这个参数不写表示默认截取到末尾
substr("ABCDEFG", 0); //返回:ABCDEFG,截取所有字符
substr("ABCDEFG", 2); //返回:CDEFG,截取从C开始之后所有字符
substr("ABCDEFG", 0, 3); //返回:ABC,截取从A开始3个字符
substr("ABCDEFG", 0, 100); //返回:ABCDEFG,100虽然超出预处理的字符串最长度,但不会影响返回结果,系统按预处理字符串最大数量返回。
substr("ABCDEFG", -3); //返回:EFG,注意参数-3,为负值时表示从尾部开始算起,字符串排列位置不变。
-- 请找出员工名字第一个字母是A的员工信息?
第一种方式:模糊查询
select ename from emp where ename like 'A%';
第二种方式:substr
select ename from emp where substr(ename,1,1) = 'A';
-- 将员工名字全部首字母大写
select concat(upper(substr(name,1,1)),substr(name,2,length(name)-1)) as result
from t_student;
-- substr(name,2,length(name)-1)从第二位截到最后一位
-- concat(str1,str2):将str1和str2拼接在一起
-- 截取字符串最后一位
-- 将'漏覆盖,资源满,' --> '漏覆盖,资源满'
update temp_wgh_xq_list set 网络问题 = substr(网络问题,1,length(网络问题)-1) where 网络问题 like '%,';
-- 将',漏覆盖,资源满' --> '漏覆盖,资源满'
update temp_wgh_xq_list set 网络问题 = substr(网络问题,1,1) where 网络问题 like ',%';
-- 将'漏覆盖,,资源满' --> '漏覆盖,资源满'
update temp_wgh_xq_list set 网络问题 = replace(网络问题,',,',',');
-
截取经纬度
select SUBSTR(场景百度坐标中心点, 1, INSTR(场景百度坐标中心点, ',')-1) as BDLON, SUBSTR(场景百度坐标中心点, INSTR(场景百度坐标中心点, ',')+1) AS BDLAT from ...
查找 instr
instr(string,subString,position,ocurrence) 查找字符串位置
instr('源字符串' , '目标字符串' ,'开始位置','第几次出现')
-- 注意:
destString代表要从源字符串中查找的子串;
开始位置,可选,默认为1,如果值为负数,则代表从右往左进行查找;
第几次出现,可选, 默认为1;
返回值:查找到的字符串的位置。如果没有查找到,返回0。
-- 举例:
select instr('abcd','a',1,1) from dual; ---1
select instr('abcd','c',1,1) from dual; ---3
select instr('abcd','e',1,1) from dual; ---0
select INSTR('CORPORATE FLOOR','OR', 3, 2) as loc from dual
... on instr(a.补充地址,b.name) > 0 -- 这段代码的意思就是判断b里面的地址是否在a里面出现过,出现则关联
... on instr(b.投诉内容,a.精准小区名称)>0
drop table tab_tjcj_20230602_2;
create table tab_tjcj_20230602_2 as
select
type,
sort,
网格,
街道,
substr(SCENE_TYPE,1,instr(SCENE_TYPE,'-',1,1)-1) as 一级场景,
substr(
SCENE_TYPE, -- 源字符串
instr(SCENE_TYPE,'-',1,1)+1, -- 截取起始位置
(instr(SCENE_TYPE,'-',instr(SCENE_TYPE,'-',1,1)+2,1) - instr(SCENE_TYPE,'-',1,1))-1 -- 截取到位置
) as 二级场景,
name,
owner,
owner_phone,
indicator as 推荐指标,
indicator_value||'%' as 上月渗透率,
crowd as 上月新增用户,
crowd_count as 场景用户量
from tab_tjcj_20230602_1;
替换 replace
replace(strSource, str1, str2) 将strSource中的str1替换成str2
strSource:源字符串
str1:要替换的字符串
str2:替换后的字符串
select '替换字符串' as oldStr, replace('替换字符串', '要替换', '修改为') as newStr from dual;
select 宽带占有率,replace(宽带占有率,'%','') as rep
from temp_sqd_yy
where replace(宽带占有率,'%','') <=40;
-
各个地市诸如5711,571A的编码转成中文分公司名称。
pub_tool.area_name(区县编码)
select 区县编码, pub_tool.area_name(区县编码)||'_' 区县名称 from SG_XY_SCENES_571_M_08

插入 stuff
该函数用于删除指定长度 的字符,并可以在指定的起点处插入另一组字符。
如果开始位置或长度值是负数,
-- stuff(string1,参数1,参数2,string2)
string1:源字符串
参数1:表示从第几个位置开始
参数2:删除几个元素
string2:要插入的字符串
select STUFF('abcdefg',1,0,'1234') --1,0。1表示字符串第一个位置,0表示不替换原来的字符串,只将后面的字符串插入,结果为'1234abcdefg'
select STUFF('abcdefg',1,1,'1234') --1,1。第一个1表示在原字符串的第一个位置插入,后一个1表示删除原字符串的第一个元素,结果为'1234bcdefg'
select STUFF('abcdefg',2,1,'1234') --2,1。2表示第二个元素后插入,1表示删除1个元素,结果为'a1234cdefg'
select STUFF('abcdefg',2,2,'1234') --结果为'a1234defg'
字符串长度 char_length(s)
-- 作用
返回字符串s的字符数
-- 示例:
select char_length('mysql') as len_Str;
>>>
5
返回对应位置 field(s,s1,s2,s3...)
-- 作用
返回字符串 s 在后面s1,s2,s3..sn列表中第一次出现的位置,从1开始
-- 示例:
select field('aaa','aaa','bbb','ccc');
>>>
1
去空格/去字符串 trim()
-
leading函数的作用:
select trim(leading 'x' from 'xxxbarxxx'); --返回 ‘xxxbarxxx’ 中前缀不含 ‘x’ 的部分。前缀即字段的左边。 -- 重刷场景类型 update temp_bd_202308_1a set 场景类型=null; update temp_bd_202308_1a a set 场景类型 = ( select 大类||'-'||中类||'-'||小类 from tab_region_info b where trim(a.场景id) = trim(b.场景id) -- 将两个表去空格后进行匹配 ) ; select distinct a.* from qs_cq_qlxq_dt_1 a,carrier.temp_攻坚小区@to_midway b where a.分公司 = b.分公司 and trim(leading '#' from a.精准小区名称) = trim(leading '#' from b.精准小区名称) -- 返回精准小区名称中前缀不带#的部分 and a.p_day='20230520';
-
both
mysql> select trim(both 'x' from 'xxxbarxxx'); -- 返回'xxxbarxxx' 中前后缀都不带‘x’的部分 -> 'bar'
-
trailing
mysql> select trim(trailing 'xyz' from 'barxxyz'); -- 返回'xxxbarxxx' 中前后缀都不带‘xyz’的部分 -> 'barx'
保留一位小数并拼上%号
to_char(round(sum(a.本月宽带竣工量)/sum(a.本月宽带受理量+0.000001)*100,2),'fm9999999999999990.0')||'%' as 受竣比,
转换函数
空值转换函数
nvl函数
例如NVL(string1,replace_with)中: 当第一个参数(string1)为空时,返回第二个参数(replace_with); 当第一个参数(string1)不为空时,则返回第一个参数(string1)。
小数转字符串
https://blog.csdn.net/l690781365/article/details/97272933
-
将查询到的字符进行类型转换
cast(value as type)
-
就是CAST(xxx AS 类型)
-- 字符串转整数,方式一:
select cast('sdf222222' as signed);
-- 字符串转整数,方式二:字符串+0会将字符串转成整数
select EXT4+0 from TEMP_WW_ZHENGQIZAITU;
SELECT '123'+0;
-- 浮点转字符串
select cast(23423423.2323 as char );
-- 浮点转字符串并且取别名
select cast(23423423.2323 as char ) as sss;
convert(value, type)
-
就是CONVERT(xxx,类型)
-- 浮点转字符串并且取别名
select convert(23423423.2323, char) as sss;
-- 浮点转整数
select convert(23423423.2222, signed);
-- 字符串转整数
select convert('234sssss2', signed);
decode函数
https://blog.csdn.net/qichangjian/article/details/88975499?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522167403653516800188549832%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=167403653516800188549832&biz_id=0&utm_medium=distribute.pc_chrome_plugin_search_result.none-task-blog-2~all~top_positive~default-1-88975499-null-null.nonecase&utm_term=decode%E5%87%BD%E6%95%B0&spm=1018.2226.3001.4187
-
形式一:decode(条件,值1,返回值1,值2,返回值2,…值n,返回值n,缺省值)
该函数的含义如下:
IF 条件=值1 THEN RETURN(返回值1) ELSIF 条件=值2 THEN RETURN(返回值2) ...... ELSIF 条件=值n THEN RETURN(返回值n) ELSE RETURN(缺省值) END IF
-
形式二:decode(字段或字段的运算,值1,值2,值3)
这个函数运行的结果是,当字段或字段的运算的值等于值1时,该函数返回值2,否则返回值3,相当于case when 当然值1,值2,值3也可以是表达式,这个函数使得某些sql语句简单了许多
select * from temp_wtxq_500 where ( (decode(宽带占比最差300,null,'0',宽带占比最差300)) +(decode(近2月退单最差300,null,'0',近2月退单最差300)) +(decode(近2月XC最差300,null,'0',近2月XC最差300)) +(decode(三季度有线投诉最差300,null,'0',三季度有线投诉最差300)) )>=2; -- (decode(宽带占比最差300,null,'0',宽带占比最差300)这段代码中: 判段 宽带占比差300 是否为null,如果是,将结果转为‘0’;如果不是,保留该字段原样。
-
形式三:
select * from temp_wtxq_500 order by decode ( a.分公司, '上城',1,'西湖',2,'拱墅',3,'钱塘',4, '滨江',5,'萧山',6,'富阳',7,'余杭',8, '临平',9,'建德',10,'淳安',11,'桐庐', 12,'临安',13 );
存在、包含判断函数
charindex() 是否存在并判断其位置@
在后一个字符中找到前一个字符的位置,默认从1开始
--简单用法
select charindex('test','this Test is Test') --结果为6,空格也算一个字符
--增加开始位置
select charindex('test','this Test is Test',7) --结果为14,7表示从第7个位置开始查
exists() 是否存在,如果存在则
关于求什么什么存在的需求, 如果存在干什么的需求
--题目 在MySQL中,现有评分表evaluate(包含班级编号cid和分数point字段),有班级表grade(包含班级编号cid等字段), 查询evaluate 表中有没有班级均分大于等于80分的,如果有,则查询显示grade表按cid由大到小排名的前五行记录 --解答 SELECT * FROM grade --班级表 WHERE EXISTS ( SELECT cid,AVG(point) AS avg FROM evaluate --评分表 GROUP BY cid --班级编号 HAVING avg>=80) ORDER BY grade.cid DESC LIMIT 5 ;
时间函数
to_date
作用:将字符类型按一定格式转化为日期类型
select to_date(第一个参数时间,'yyyy-mm-dd HH24:mi:ss') from hzywzc.temp_xj_hzk@to_raptor >>>得到具体的时间,格式为date select to_date(第一个参数时间,'yyyy-mm-dd') from hzywzc.temp_xj_hzk@to_raptor >>>得到对应的日期,格式为date
说明:第一个参数时间 是字符串格式
oracle中两个时间字段相减
-
求两个时间段中间间隔多少个小时(这个能用,里面的时间格式不用改!!!!)
select a.USER_ID,create_date,comm_first_use_date, round((comm_first_use_date-create_date)*24*60,2) 相差分钟 FROM hzjx_yk_check_00a a;
-
oracle里,如果两个字段都是2008-05-02 00:00:00,这种格式,可以直接相减或比较大小
select colA - colB from tableA select colA < colB from tableA
select ceil((To_date('2008-05-02 00:00:00' , 'yyyy-mm-dd hh24-mi-ss') - To_date('2008-04-30 23:59:59' , 'yyyy-mm-dd hh24-mi-ss')) * 24) 相差小时 FROM DUAL;
-
求两个时间段中间间隔多少个分钟
select ceil((To_date('2008-05-02 00:00:00' , 'yyyy-mm-dd hh24-mi-ss') - To_date('2008-04-30 23:59:59' , 'yyyy-mm-dd hh24-mi-ss')) * 24 * 60) 相差分钟 FROM DUAL;
-
求两个时间段中间间隔多少个小时
select ceil(
(
To_date('2008-05-02 00:00:00' , 'yyyy-mm-dd hh24-mi-ss') - To_date('2008-04-30 23:59:59' , 'yyyy-mm-dd hh24-mi-ss')
) * 24
) as diff_hours FROM DUAL;
日期时间提取函数集
选取日期时间的各个部分:日期、时间、年、季度、月、日、小时、分钟、秒、微秒
set @dt = '2008-09-10 07:15:30.123456'; select date(@dt); -- 2008-09-10 日期 select time(@dt); -- 07:15:30.123456 时间 select year(@dt); -- 2008 年 select quarter(@dt); -- 3 季度 select month(@dt); -- 9 月 select week(@dt); -- 36 周 select day(@dt); -- 10 日 select hour(@dt); -- 7 小时 select minute(@dt); -- 15 分钟 select second(@dt); -- 30 秒 select microsecond(@dt); -- 123456 微秒 select date_format(@dt,'%Y%m'); -- 200809,这个很常用 -- 示例 insert into exam_record_before_2021(uid, exam_id, start_time, submit_time, score) select uid,exam_id,start_time,submit_time,score from exam_record where YEAR(submit_time) <= '2021'
date_format() 函数,这个在hive中是好使
-
这个拉钩电商数仓说是MySQL的时间格式转换
-
DATE_FORMAT(createTime,'%Y-%m-%d %H')
-- 这篇说明文档写的不错 https://blog.csdn.net/qq_39390545/article/details/110846666?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522166744185116782417064313%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=166744185116782417064313&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-110846666-null-null.142^v62^pc_search_tree,201^v3^add_ask,213^v1^control&utm_term=date_format%E5%87%BD%E6%95%B0&spm=1018.2226.3001.4187
to_char() 日期转换为字符串,这个在oracle中最好使!!!(强推这个)
-
这个函数的第二个参数带'-'和不带'-'都能用
-
如果该字段本身就是字符串,不能使用该函数
select to_char(a.竣工时间,'yyyymmdd') 竣工时间 from tmp_zsr_宽带新装${mtaskid}_3
select to_char(COMPLETE_DATE,'yyyy-MM-dd') as time_code
from szx.D_EBU_RP_PBOSS_DETAIL_20230228
select * from QS_CQ_QLXQ_DT_1 where 小区编号=100002 and p_day = '20230521' and to_char(insert_time,'yyyy-MM-dd HH24') = '2023-05-22 16'
getdate() 获取当前日期
-- getdate()函数 SELECT getdate() AS CurrentDateTime --结果如下所示: CurrentDateTime 2008-11-11 12:45:34.243 --注释:上面的时间部分精确到毫秒。 SELECT NOW() SELECT CURDATE() select today()
datediff() 得到两个日期间的差值(得到天数)
-
语法:DATEDIFF(date1,date2)
datediff函数对时间差值的计算方式为date1-date2的差值。
-- datediff()函数,用于返回两个日期的天数,返回date1 - date2的计算结果。如果一个有时分秒,一个没有,不影响。正常相减。
SELECT DATEDIFF('2022-04-30','2022-04-29');
-- 1
SELECT DATEDIFF('2022-04-30','2022-04-30');
-- 0
SELECT DATEDIFF('2022-04-29','2022-04-30');
-- -1
SELECT DATEDIFF('2022-04-30','2022-04-30 14:00:00');
-- 0
SELECT DATEDIFF('2022-04-30 13:00:00','2022-04-29 14:00:00');
-- 1
SELECT DATEDIFF('2017-06-25 09:34:21', '2017-06-15');
-- 10
说明:这个函数结合lead函数可以用作算用户第n天接着做某事概率
SELECT AVG(IF(DATEDIFF(lea,DATE)=1,1,0)) FROM ( SELECT device_id,`date`,lead(`date`,1,NULL) over(PARTITION BY device_id ORDER BY `date`) AS lea FROM `question_practice_detail` a GROUP BY device_id,`date` ) a
timestampdiff() 得到两个日期间的差值(得到的分钟)
-
timestampdiff(时间参数,datetime1,datetime2)
timestampdiff函数对日期差值的计算方式为:datetime2-datetime1的差值。
时间参数 FRAC_SECOND。表示间隔是毫秒 SECOND。秒 MINUTE。分钟 HOUR。小时 DAY。天 WEEK。星期 MONTH。月 QUARTER。季度 YEAR。年
-- 牛客115 delete from exam_record where timestampdiff(minute,start_time,submit_time)<5 and score<60;
unix_timestamp 时间戳转换函数 (hive也能用)
需求:把日期格式转为字符串格式
select from_unixtime(unix_timestamp(),'yyyy-MM-dd HH:mm:ss') 先把时间转成时间戳,再转回字符串格式
select
user_id,
bill_no,
county_id,
create_chl_id, -- 入网渠道ID
create_date -- 办卡时间
from dwfu_hive_db.a_usoc_user_attr_d -- 个人社会属性表,在ns2里可以查到
where p_day='${taskid}'
and city_id='571' and cust_state=2 -- 在网
and user_state=1
and length(bill_no)=11 and bill_no like '1%'
and from_unixtime(unix_timestamp(create_date),'yyyyMM') = '${l3m_mtaskid}'
;
插入当前时间
data_sub()当前日期+n或-n天
-- 当前日期增加一天 SELECT DATE_SUB(CURDATE(),INTERVAL -1 DAY) -- interval表示减少的意思 -- 当前日期减少一天 SELECT DATE_SUB(CURDATE(),INTERVAL 1 DAY)
dayofweek返回某个日期在当年,当月,当周的位置
-- dayofweek(time)函数:返回日期的工作日索引值,即星期日为1,星期一为2,星期六为7。
-- dayname(time)函数:返回工作日的名称
SELECT DAYNAME('2012-12-01'), DAYOFWEEK('2012-12-01');
-- dayofmonth(time):返回此日期在它当月属于第几天
SELECT DAYOFMONTH('2012-12-01');
-- dayofyear(time):返回此日期在它当年属于第几天
SELECT DAYOFYEAR('2012-12-01');
其他函数
greatest
1.1 取多列最大值
select greatest(-99, 0, 73) --73
1.2 存在 null 或者字符串
select greatest(-99, 0, 73, null) --null
select greatest(-99, 0, 73, 'string') --null
只要GREATEST的expr有一个为NULL,都会返回NULL。
DML (数据操作语言)
给表名列和指标名列各添加一列uuid列
-- 后面要加新的表就主要是在第2步,临时表里加小表 第3步的主要是选select对应的字段,另外就是concat一些维表里的uuid 1.--建正式表 drop table DM_FA_SMART_HUB_METRICS_INFORMATION_MA; create table if not EXISTS DM_FA_SMART_HUB_METRICS_INFORMATION_MA( investment_division varchar(255) comment '投资处', fixed_asset_system varchar(255) comment '报表制度', templetcode varchar(255) comment '表id', templetname varchar(255) comment '表名', areaid varchar(255) comment '地区id', areaname varchar(255) comment '地区名', indicatorid varchar(255) comment '指标id', indicatorname varchar(255) comment '指标名', timecode varchar(255) comment '数据时间', unitname varchar(16) comment '计量单位', cur_last decimal(20,2) comment '去年同期', cur_last_total decimal(20,2) comment '去年同期累计', cur_total decimal(20,2) comment '本期', cur_growth decimal(20,2) comment '本期增长', total decimal(20,2) comment '累计', total_growth decimal(20,2) comment '累计增长', cur_last_growth decimal(20,2) comment '去年同期累计增长', proportion decimal(20,2) comment '比重' )character set utf8 collate utf8_general_ci; 2.--建临时表 drop table if exists temp_DM_FA_SMART_HUB_METRICS_INFORMATION_MA; create table temp_DM_FA_SMART_HUB_METRICS_INFORMATION_MA select investment_division, fixed_asset_system, templetcode, templetname, areaid, areaname, indicatorid, indicatorname, timecode, unitname, cur_last, cur_last_total, cur_total, cur_growth, total, total_growth, cur_last_growth, proportion from ( select -- 1成功 investment_division, fixed_asset_system, templetcode, templetname, areaid, areaname, indicatorid, indicatorname, timecode, unitname, cur_last, '-1' as cur_last_total, cur_total, cur_growth, total, '-1' as total_growth, '-1' as cur_last_growth, '-1' as proportion from mysql_dp_dwd.DWD_FA_REE_DIV_PRODUCT_DEVELOP_ZHEJIANG_MA union all select -- 2成功 investment_division, fixed_asset_system, templetcode, templetname, areaid, areaname, indicatorid, indicatorname, timecode, unitname, '-1' as cur_last, '-1' as cur_last_total, cur_total, cur_growth, total, total_growth, '-1' as cur_last_growth, '-1' as proportion from mysql_dp_dwd.DWD_FA_FAS_INVESTMENT_COUNTY_MA union all select -- 3成功 investment_division, fixed_asset_system, templetcode as 'templetcode', templetname as 'templetname', areaid as 'areaid', areaname as 'areaname', indicatorid as 'indicatorid', indicatorname as 'indicatorname', timecode as 'timecode', unitname as 'unitname', '-1' as cur_last, cur_last_total, '-1' as cur_total, '-1' as cur_growth, total, total_growth, '-1' as cur_last_growth, '-1' as proportion from mysql_dp_dwd.DWD_FA_REE_DEVELOP_INVESTMENT_CITIES_MA union all select -- 4成功 investment_division, fixed_asset_system, templetcode, templetname, areaid, areaname, indicatorid, indicatorname, timecode, unitname, ................... ................. cur_last_total, cur_total, cur_growth, total, total_growth, cur_last_growth, proportion from mysql_dp_dm.DM_FT_SMART_HUB_METRICS_INFORMATION_MA )A; 3.--将临时表的数据插入正式表 truncate table DM_FA_SMART_HUB_METRICS_INFORMATION_MA; insert into DM_FA_SMART_HUB_METRICS_INFORMATION_MA SELECT a.investment_division, a.fixed_asset_system, c.uuid AS templetcode, a.templetname, a.areaid, a.areaname, b.uuid,a.`timecode`, a.indicatorname, timecode, unitname, cur_last, cur_last_total, cur_total, cur_growth, total, total_growth, cur_last_growth, proportion FROM mysql_dp_dm.temp_DM_FA_SMART_HUB_METRICS_INFORMATION_MA a JOIN mysql_dp_dim.`GENERAL_OFFICE_INDICATORNAME_UUID` b ON a.indicatorname=b.`indicatorname` AND a.templetname=b.`templetname` JOIN mysql_dp_dim.`GENERAL_OFFICE_TEMPLETNAME_UUID` c ON a.templetname=c.templetname; 4.--修改临平和钱塘两个地区的id UPDATE `DM_FA_SMART_HUB_METRICS_INFORMATION_MA` SET areaId=863301140000000 WHERE areaname='钱塘区'; UPDATE `DM_FA_SMART_HUB_METRICS_INFORMATION_MA` SET areaId=863301130000000 WHERE areaname='临平区'; 4.--查询一下数据量 SELECT COUNT(1) FROM ( SELECT a.investment_division, a.fixed_asset_system, c.uuid AS templetcode, a.templetname, a.areaid, a.areaname, CONCAT(b.uuid,a.`timecode`), a.indicatorname, timecode, unitname, cur_last, cur_last_total, cur_total, cur_growth, total, total_growth, cur_last_growth, proportion FROM mysql_dp_dm.temp_DM_FA_SMART_HUB_METRICS_INFORMATION_MA a JOIN mysql_dp_dim.`GENERAL_OFFICE_INDICATORNAME_UUID` b ON a.indicatorname=b.`indicatorname` AND a.templetname=b.`templetname` JOIN mysql_dp_dim.`GENERAL_OFFICE_TEMPLETNAME_UUID` c ON a.templetname=c.templetname ) t
添加字段
-
给字段起别名不能加单引号
-
MySQL和oracle同样语法
--在已有字段的表的在末尾添加一列 alter table 表名 add 新字段 varchar(255) not null; -- 非空 alter table 表名 add 新字段 number default 0; -- 默认为0 --在已有字段的表的指定字段位置(column_name)添加一列,oracle中不支持 alter table table_name add new_column_name varchar(255) not null after column_name; --在已有字段的表的第一列位置添加一列 alter table table_name add new_column_name varchar(255) not null first; --在已有字段的表的末尾添加一列时间字段 alter table table_name add 'createtime' datetime dafault current_timestamp;
删除字段
-
MySQL和Oracle语法相同
--alter table 表名 drop column 字段名; alter table car_evidence drop column unit_name;
删除主键约束
alter table Person dorp primary key;
修改字段
修改字段名称
ALTER TABLE 表名 CHANGE [column] 旧字段名 新字段名 新数据类型; -- 举例: ALTER TABLE GENERAL_OFFICE_INDICATORNAME_UUID CHANGE indicatorname VARCHAR(32); -- oracle语法 alter table temp_xj_xqgbxq rename column 十月底宽带到达 to 十一月底宽带到达;
修改字段类型
-
将orcle汇总长度大于4000的字段改为clob的操作方法
第一步,清空该字段数据(如有数据不能进行表结构的修改)
SQL> Truncate Table SYS_CATEGORY;
第二步,先将操作的表中DESCRIPT字段,转换成LONG, 再将LONG类型转成CLOB类型(不知为何不能直接转成CLOB类型)
ALTER TABLE SYS_CATEGORY MODIFY DESCRIPT LONG; ALTER TABLE SYS_CATEGORY MODIFY DESCRIPT CLOB;
alter table 表名 modify column 字段名 类型(长度); -- 将varchar类型改为text类型 ALTER TABLE student_table MODIFY COLUMN `name` TEXT; -- 将text改为varchar类型 ALTER TABLE student_table MODIFY COLUMN `name` VARCHAR(20); -- oracle中修改语法 alter table tableName modify (colName varchar2(500)); -- 改之前必须先清空该字段 ALTER TABLE table_name MODIFY(column_name NUMBER(10,2)); -- 查看修改后的表结构 SHOW CREATE TABLE student_table; -- 牛客119 -- 请在用户信息表,字段level的后面增加一列最多可保存15个汉字的字段school;并将表中job列名改为profession,同时varchar字段长度变为10;achievement的默认值设置为0。 alter table user_info add school varchar(15) after level; ALTER TABLE user_info CHANGE job profession varchar(10); alter table user_info modify column achievement int(11) DEFAULT 0;
-
或者有个更简单的方法
直接在SQLyog里,右键点这张表,选择`改变表`,然后把字段类型改了就行

修改字段长度
ALTER TABLE 表名 MODIFY 字段名 数据类型(修改后的长度) -- 实际案例: ALTER TABLE qs_C_Market_202306 MODIFY 集团证件开户最集中单位 varchar2(3999);
MySQL删除数据
删除部分数据:
DELETE FROM <表名> [WHERE <条件>; -- 复杂的删除 SELECT * FROM `DM_KNOWLEDGEGRAPH_INDEX_QI` WHERE id NOT IN -- 3.再查指标值表里哪些ID是不在指标表里的 ( SELECT DISTINCT index_id FROM `DM_KNOWLEDGEGRAPH_INDEX_VALUE_QI` WHERE index_id IN ( SELECT id FROM `DM_KNOWLEDGEGRAPH_INDEX_QI` ) ) -- 3222 /* 定义: 父表:指标表 子表:指标值表 */ delete from knowledgegraph_index -- 在父表里查自己id哪些不在子表里,然后干掉 where id not in ( select distinct index_id -- 这个地方有个去重要注意 from knowledgegraph_index_value -- 2.在子表里查它的父节点id哪些在父表里(因为有可能父id不在父表里的,当时是因为把一些子表里value为空的去掉了,id也就没了) where index_id in ( select id from knowledgegraph_index -- 1.先在父表里查父节点id ) )
删除全部数据:
truncate table 在功能上,与不带where字句的delete语句相同;
二者均删除表中的全部行,但truncate table 比delete速度更快,且使用的系统和事务日志资源少。truncate会清空表并且会保留源表结构,但会重置自增主键。
truncate 删除表中的所有行,但表的结构及其列,约束,索引等保持不变。新行标识所用的技术值重置为该列的种子。如果想保留标识计数值,轻盖拥delete 。
如果要删除表定义及其数据,请使用drop table 语句。
truncate table <表名>
按一定条件删除数据
-- 牛客116 -- 请删除exam_record表中未完成作答 或 作答时间小于5分钟整的记录中,开始作答时间最早的3条记录。 delete from exam_record where score is null or timestampdiff(minute,start_time,submit_time)<5 order by start_time limit 3;
多字段重复数据去重
-- 这篇帖子写的十分通俗易懂 https://blog.csdn.net/shark_pang/article/details/125440416?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522166367074416781432988103%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=166367074416781432988103&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-2-125440416-null-null.142^v48^pc_rank_34_queryrelevant25,201^v3^add_ask&utm_term=mysql%20%E5%A4%9A%E5%AD%97%E6%AE%B5%E5%8E%BB%E9%87%8D&spm=1018.2226.3001.4187 --MySQL多字段去重复实际上是单字段去重复的衍生,原理就是把多字段数据通过子查询合并为单字段的数据表,再通过单字段数据group by 进行汇总,用 having把 count(字段) > 1的数据都显示出来,最后把查找到的重复数据 用min方法或者max方法获取最小id或者最大id来选择删除。 1,多字段转单字段,这里需要把id显示出来,后面有用到 SELECT id,CONCAT(`host`,path,params) AS uuid FROM static_url; 2,把多字段合并为单字段的查询结果放入子查询,查找存在重复的数据,并显示重复数 SELECT COUNT(a.id),a.uuid FROM ( SELECT id,CONCAT(`host`,path,params) AS uuid FROM static_url )a GROUP BY a.uuid HAVING COUNT(a.id) > 1 3,将查询到的重复id,来获取重复数据里最小的id SELECT min(a.id) FROM ( SELECT id,CONCAT(`host`,path,params) AS uuid FROM static_url )a GROUP BY a.uuid HAVING COUNT(a.id) > 1 4,将获取到重复数据最小的id值放入 IN内作为删除数据的条件(先把5看完再执行) DELETE FROM static_url WHERE id IN( SELECT min(a.id) FROM ( SELECT id,CONCAT(`host`,path,params) AS uuid FROM static_url )a GROUP BY a.uuid HAVING COUNT(a.id) > 1 ) 5,bug补充 如果直接执行步骤4的代码时,MySQL会卡住,会卡住,卡住,卡住!!! 虽然逻辑上来说没问题,但执行的时候嵌套过多子查询,就会出现问题,所以要把子查询数据拎出来再放入删除语句内 DELETE FROM static_url WHERE id IN( 91383,26240,26256,26269,26129,26108,26029,26067,26095,26309,26595,51805,37459,32493,32417 ) 6,将步骤4的代码多执行几次,直到执行结果显示没有删除到数据的时候才停止,因为重复数据不一定只重复一次,很可能重复好几次,每一次执行只能删除重复数据的最小id,不是只保留最大id
删表时限制两个字段
delete from qs_Cj_qd_20230607 a where exists ( select 1 from ( select d.场景ID as r1,d.重点场景类型 as r2 from ( select c.*,row_number() over(partition by 场景ID order by flag) as rn from ( select b.*, case when 重点场景类型 = '小区' then 1 when 重点场景类型 = '村社' then 2 when 重点场景类型 = '集团' then 3 else 4 end as flag from ( select * from qs_Cj_qd_20230607 where 场景ID in ( select a.场景ID from ( -- 244 select 场景ID,count(1) from qs_Cj_qd_20230607 where 是否重点场景 = '是' group by 场景ID having count(1) >1 ) a ) ) b ) c ) d where d.rn !=1 ) e where a.场景ID = e.r1 and a.重点场景类型 = e.r2 );
MySQL删表
-- 删除多张表 DROP TABLE IF EXISTS exam_record_2011, exam_record_2012, exam_record_2013, exam_record_2014;
merge into
-
学习路径
https://blog.csdn.net/lanxingbudui/article/details/123126895?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522166805463716782429714085%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=166805463716782429714085&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-1-123126895-null-null.142^v63^control,201^v3^add_ask,213^v2^t3_esquery_v3&utm_term=oracle%E4%B8%ADmerge%20into%E7%94%A8%E6%B3%95&spm=1018.2226.3001.4187
-
用途
可以同时从1个或者多个源表对目标表进行更新、插入、删除数据,经常用于操作大量的数据,即对于大批量的数据更新、插入时效率极高。
-
语法
merge into table_name alias1 --目标表 可以用别名 using (table|view|sub_query) alias2 --数据源表 可以是表、视图、子查询 on (join condition) --关联条件 when matched then --当关联条件成立时 更新,删除,插入的where部分为可选 --更新 update table_name set col1=colvalue where…… --删除 delete from table_name where col2=colvalue where…… --可以只更新不删除 也可以只删除不更新。 --如果更新和删除同时存在,删除的条件一定要在更新的条件内,否则数据不能删除。 when not matched then --当关联条件不成立时 --插入 insert (col3) values (col3values) where…… when not matched by source then --当源表不存在,目标表存在的数据删除 delete;
-
示例
alter table temp_grfb_202208_qd add 交房时间 varchar(500); alter table temp_grfb_202208_qd add 交房时间类型 varchar(500); merge into temp_grfb_202208_qd a using( select * -- 这要写全,要不on后面关联不到 from temp_jfxqqd_1114 ) b on (a.county_name=b.区县 and a.region_name =b.小区名称) when matched then update set a.交房时间 = b.交房时间 , a.交房时间类型 = b.类型; --这的每个条件中间是,不是and
-
注意
1、只会操作“操作表”,源表不会有任何变化。 2、不一定要把update,delete,insert 操作都写全,可以根据实际情况。 3、merge into效率很高,强烈建议使用,尤其是在一次性提交事务中,可以先建一个临时表,更新完后,清空数据,这样update锁表的几率很小了。 4、Merge语句还有一个强大的功能是通过OUTPUT子句,可以将刚刚做过变动的数据进行输出。我们在上面的Merge语句后加入OUTPUT子句。 5、可以使用TOP关键字限制目标表被操作的行,如图8所示。在图2的语句基础上加上了TOP关键字,我们看到只有两行被更新。 6、merge into后面的on条件,一定要带'()',不带会显示miss keyword
MySQL修改数据
清空某列数据
UPDATE TEMP_XYXS_GMFHQK_20230209 SET 通信在杭11月拍照 = NULL;
修改某些内容的格式为:
UPDATE 表名 SET 列名=值表达式 [<列名>=<值表达式>]... WHERE ... -- 把null的列填充上数据(注意null不能用=,要用is) UPDATE `DM_KNOWLEDGEGRAPH_INDEX_QI` SET provincename = '浙江' WHERE provincename IS NULL -- 更改知识图谱台州的数据 UPDATE ODS_EXCL_ECONOMIC_SITUATION_DI_1 SET NODE_val_FOURTH = '22.6' WHERE NODE_FOURTH='销售产值' AND dt=202109 AND city_name='台州市' AND node_val_fourth='21.0' UPDATE mysql_dp_ods.`ODS_EXCL_ECONOMIC_SITUATION_DI` SET node_val_fourth='3.1' WHERE city_name='黄岩区' AND dt='202206' AND node_val_fourth='3..1'
查询替换某些数据
mysql查询replace用法详解_mysql_HD243608836-DevPress官方社区 (csdn.net)
1、准备实验环境
1.1 创建表:
CREATE TABLE `test_tb` ( `id` int(10) unsigned NOT NULL auto_increment COMMENT '主键自增', `name` char(30) default NULL COMMENT '姓名', `address` char(60) default NULL COMMENT '地址', `country` char(200) default NULL COMMENT '国家', PRIMARY KEY (`id`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8 COMMENT='测试表'
1.2 插入数据:
insert into test_tb(name,address,country) values
('zhangsan','北京 朝阳区','中国'),
('lisi','上海 浦东区','中国'),
('wangwu','郑州金水区','中国'),
('zhaoliu','香港九龙','中国香港'),
('Q7','加州牛肉','美国'),
('wangba','新九州岛','日本')
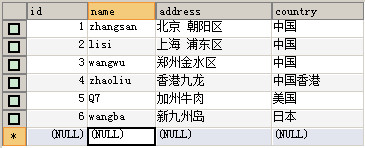
2、场景一:查询替换
2.1 将address字段里的 “区” 替换为 “呕” 显示(不是全部替换,全部替换可以直接使用语句 select id, name, 无人区 as address from test_db*),如下
select *,replace(address,'区','呕') AS rep from test_tb
2.2 将address字段里的 “九” 替换为 “十” 显示,如下
select *,replace(address,'九','十') AS rep from test_tb where id in (4,6)

总结:
联想到前面有讲过 使用IF(expr1,expr2,expr3) 及 CASE...WHEN...THEN...END 可以实现查询结果的别名显示,但区别是:这两者是将查询结果值做整体的别名显示,而replace则可以对查询结果的局部字符串做替换显示(输出)。
3、场景二:更新替换
3.1 将address字段里的 “东” 替换为 “西” ,如下
update test_tb set address=replace(address,'东','西') where id=2
总结:对字段中局部字符串做更新替换。
4、场景三:插入替换
4.1 将id=6的name字段值改为wokou
replace into test_tb VALUES(6,'wokou','新九州岛','日本')
同时修改两个条件
注意,两个字段之间是逗号
update exam_record set submit_time = '2099-01-01 00:00:00', score =0 -- 中间是',',不是and where start_time<'2021-09-01' and score is null;
批量替换
-
oracle也能用
-- 替换不同字段 将数据库的-1替换为null -- 1.替换cur_last UPDATE dm_fa_smart_hub_metrics_information_ma_test SET cur_last =NULL WHERE cur_last=-1 -- 2.替换cur_last_total UPDATE dm_fa_smart_hub_metrics_information_ma_test SET cur_last_total =NULL WHERE cur_last_total=-1 -- 如果要反过来替换为空,就要写is null -- 批量替换同一字段 update qs_list_宽带新装_0801_0916a set 路街 = replace(replace(replace(replace(replace(replace(replace(replace(路街,'(沿街商铺)-',''),'(沿街商铺)-','') ,'(沿街商铺)-',''),'(沿街商铺)-',''),'(沿街商铺)-',''),'(沿街商铺)—',''),' (沿街商铺)-','') ,'(沿街商铺)-','') where 路街 like '%沿街商铺%'; -- 批量替换同一字段 update qs_list_宽带新装_0801_0916a set 路街 = replace(replace(replace(replace(路街,'杭州市滨江区',''),'长河街道',''),'沿街商铺',''),'浦沿镇','');
update修改某列数据
update qs_dbxqjy set 审批原因 = ( -- 这个括号要加,不用写select from,直接写select里面的字段就行
concat(
concat(concat('竣工:',竣工),',竣工比:'),
rtrim(to_char(round(竣工/受理,2),'fm9999999990.9999'),'.')
)
)
where 受理 !=0
;
-- rtrim(to_char(round(竣工/受理,2),'fm9999999990.9999'),'.')
这个函数是把字符转换为数值,同时保留4位小数
-
攻坚小区okr新版(where后面要写在括号外面)
-- 刷:是否扣罚
alter table temp_攻坚_${taskid} add 是否扣罚 varchar2(10);
update temp_攻坚_${taskid} set 是否扣罚 =(
case
when 本月宽带竣工量 >0 and 本月宽带竣工量 / 本月宽带受理量>=0.85 then '否'
when 本月宽带受理量 >0 and 本月宽带竣工量 >=0 and 本月宽带竣工量/本月宽带受理量<0.85 then '是'
else null
end
)
where 本月宽带受理量>0
;
-
将某列数据替换为空行
update hj_cq_kd_zone_sta set 套餐5g = null;
update修改某行数据
1.--先删除这行数据 UPDATE mysql_dp_dm.`DM_FA_SMART_HUB_METRICS_INFORMATION_MA` SET indicatorid = NULL; 2.--插入查询到的这行 INSERT INTO DM_FA_SMART_HUB_METRICS_INFORMATION_MA(indicatorid) SELECT UUID FROM mysql_dp_dim.`GENERAL_OFFICE_INDICATORNAME_UUID` a JOIN mysql_dp_dm.DM_FA_SMART_HUB_METRICS_INFORMATION_MA b ON a.indicatorname=b.indicatorname
需判断某个字段在另一个表中update写法
-
in写法:where colA in (select colB ...)
update temp_wtxq_500 set 近2月XC最差300 = 1 where 精准小区名称 in( select 精准小区名称 from( select 精准小区名称,小区本月XC用户数量+小区上月XC用户数量 as 近2月XC from qs_cq_qlxq_m where 小区本月XC用户数量+小区上月XC用户数量 is not null and 小区本月XC用户数量+小区上月XC用户数量 >=3 order by 近2月XC desc ) );
-
exists写法:
update temp_cq_qlxq_m_202307 a set a.是否省内 = 1 where EXISTS ( select 1 from temp_cq_20230815 b where a.bill_id = b.bill_id );
update某列值依赖另一张表写法
(只适用MySQL,不适用Oracle)
-
错误写法
update oss_system_user t set t.departmentGroupId = ( select b.refGroupId from oss_system_user a join oss_system_department b on a.department = b.id where a.loginId = 'admin' ) where t.loginId = 'admin';
-
正确写法
update oss_system_user a inner join ( select id, refGroupId from oss_system_department ) b on a.department = b.id set a.departmentGroupId = b.refGroupId;
适用于oralce的
程序名:三进升千兆
-- 刷累计点亮次数 update qs_Cj_qd_20230626 set 累计点亮次数 = '否'; update qs_Cj_qd_20230626 a set a.累计点亮次数=( select case when (d.普通业务+d.低资费+d.副卡_飞享8+d.专项客户攻坚+ d.有效4升5+d.千兆高套新装+d.千兆升级+d.当日裸宽新增+ d.当日融合新增+d.当日裸宽转裸宽+d.当日裸宽转融合+ d.FTTR+d.看家+d.组网+d.VIP包+d.健康三宝+ d.高价值权益+d.彩铃+d.云盘) / 40 >1 then '是' else '否' end 是否点亮 from qs_sanjin_count_202306 d -- 注意这个表里不要有重复值 where a.场景ID=d.场景ID ) where exists( select 1 from qs_sanjin_count_202306 d where a.场景ID=d.场景ID ) ; update qs_Cj_qd_20230706 a set a.累计点亮次数=( select 累计点亮次数 from temp_6_7_dl b where a.场景ID=b.场景ID ) where exists( select 1 from temp_6_7_dl b where a.场景ID=b.场景ID ); -- 报错:single-row subquery returns more than one row 报错的原因是temp_6_7_dl表里,场景ID有重复值
merge into 替换
-
如果有限制条件where,where写在最后,如下:
merge into SG_XY_SCENES_571_M a using ( select distinct 乡镇街道编码,乡镇街道名称 from SG_XY_SCENES_571_202305 ) b on (a.乡镇街道名称 = b.乡镇街道名称) when matched then update set a.乡镇街道编码=b.乡镇街道编码 where 区县编码 is null; -- 注意这里
-
merge into的替换,如果using里面的B表的on字段对应多个值,赋值给A表时,会报错;但如果是B表on的字段对应的额值唯一,A表on的字段有多个值,则会把on字段对应的这个多个值都刷上去。
MySQL中给某个字段加密
-
建表时用encode加密
DROP TABLE student;
CREATE TABLE student(
sid VARCHAR(15) PRIMARY KEY, -- 这个字段只是用来标识密码的编号
spass BLOB -- 这个用来存储敏感信息,比如电话号码
);
-- 加密插入
INSERT INTO student VALUES('01',ENCODE('13261816201','abc'))
INSERT INTO student VALUES('02',ENCODE('15090839267','abc'))
-- 解密查询
SELECT sid,DECODE(spass,'abc') AS spass FROM student WHERE sid != '03'
在notepad++中替换空行
' \r\n'全部替换成空

MySQL插入数据
插入一行/多行格式
-
注意:oracle和MySQL中,into 后面没有table关键字,Hive后有table
insert into table_name(id,name,birth,sex) values('1014','zhangsan','20022-01-26','男');
--into后面没有table
--table_name后面要跟列名
-- 同时插入两行数据
INSERT INTO exam_record (uid, exam_id, start_time, submit_time, score) VALUES
(1001, 9001, '2021-09-01 22:11:12', '2021-09-01 23:01:12', 90),
(1002, 9002, '2021-09-04 07:01:02', NULL, NULL);
查询插入随机数
INSERT INTO 表名 SELECT CAST(RAND()*10 AS SIGNED) AS RAND;
oracle中随机抽数据插入新表
select * from ( select * from temp_cl_jm_qd_08 where 是否升级千兆宽带 is null order by dbms_random.value ) where rownum<=10;
将查到的数据插入新表 inset into select
语法:
insert into table1(field1,field2,...) select v1,v2,.... from table2 WHERE ...; 或者 insert into table1 select * from table2 WHERE ...; 注意:要求目标表table1必须存在,所以你必须提前先建表
关于原表有自增字段怎么插入到新表
-
关键点:自增字段设为null
--建表阶段 create table if not exists T_DATA_TRANSFER_33 ( ID int(32) primary key auto_increment, -- id为原表主键,自增 templetcode varchar(120), templetName varchar(120), indicatorId varchar(120), indicatorName varchar(120), ... UPDATE_TIME datetime, -- 时间字段就给 datetime ); --插入阶段 insert into T_DATA_TRANSFER_33 select null, --主键写null就行,这是本题的关键 templetcode, templetName, indicatorId, indicatorName, ... from mysql_dp_ods.`ODS_YTB_VIEW_DATA_INDICATOR2_DA`
空行(null)怎么插入
select -- 4成功 templetcode, templetname, areaid, areaname, indicatorid, indicatorname, timecode, unitname, null as 'cur_last', -- 看这里 null as 'cur_last_total', -- 看这里 cur_total, cur_growth, total, total_growth, null as cur_last_growth, -- 看这里 null as 'proportion' -- 看这里 from mysql_dp_dwd.DWD_FT_CAT_TRAVELERS_DATA_ZHEJIANG_MA
刷数据 merge into
如果有where过滤条件,把过滤条件写在最后
update SG_CZ_SCENES_571_M set 乡镇街道名称 = null; update SG_CZ_SCENES_571_M set 场景类型 = null; merge into SG_CZ_SCENES_571_M a using ( select * from tab_region_info ) b on (substr(a.场景编码,1,length(场景编码)-1)=b.场景ID) when matched then update set a.边界=b.场景百度坐标边界, a.场景类型=concat(concat(concat(concat(b.大类,'-'),b.中类),'-'),b.小类), a.乡镇街道名称=b.街道 where a.边界 is null ;
replace into的用法
replace into 跟 insert into功能类似,不同点在于:replace into 首先尝试插入数据到表中, 1.如果发现表中已经有此行数据(根据主键或者唯一索引判断)则先删除此行数据,然后插入新的数据;否则,直接插入新数据。 2.要注意的是:插入数据的表必须有主键或者是唯一索引!否则的话,replace into 会直接插入数据,这将导致表中出现重复的数据。 -- 牛客:sql112 REPLACE into examination_info values (null,9003,'SQL','hard',90,'2021-01-01 00:00:00') -- 第一个null是主键
DDL (数据定义语言)
把EXCEL中表结构拼接成建表语句

=CONCAT(A2," ",C2,"(",D2,") comment '",B2,"',")
建表
-
建表:
建表的集中方式 CREATE TABLE [IF NOT EXISTS] tb_name -- 不存在才创建,存在就跳过 (column_name1 data_type1 -- 列名和类型必选 [ PRIMARY KEY -- 可选的约束,主键 | FOREIGN KEY -- 外键,引用其他表的键值 | AUTO_INCREMENT -- 自增ID | COMMENT comment -- 列注释(评论) | DEFAULT default_value -- 默认值 | UNIQUE -- 唯一性约束,不允许两条记录该列值相同 | NOT NULL -- 该列非空 ], ... ) [COMMENT '表注释'] [CHARACTER SET charset] -- 字符集编码 default charset=utf8 [COLLATE collate_value] -- 列排序和比较时的规则(是否区分大小写等) -- 样例展示【移动这边oracle的dm平台】 CREATE TABLE temp_xq_zhaungji_qd ( 区县 varchar(255) NOT NULL, 小区 varchar(255) NOT NULL, 小区清单 varchar(255) NOT NULL, 督办编号 varchar(255) NOT NULL, x0131进度 varchar(255) NOT NULL, x0209进度 varchar(255) NOT NULL, 是否解决 varchar(255) NOT NULL, 十二月受理数量 number NOT NULL, 十二月竣工数量 number DEFAULT NULL, 一月受理数量 number DEFAULT NULL, 一月竣工数量 number DEFAULT NULL ) ;
-
从另一张表复制表结构创建表:
CREATE TABLE tb_name LIKE tb_name_old
-
3.从另一张表的查询结果创建表:
CREATE TABLE tb_name AS SELECT * FROM tb_name_old WHERE options
-
4.复制另一张表的表结构的形式建表
create table QS_XJ_XQGBXQ1_RESERVE as select * from temp_xj_xqgbxq1 where 1=2
复制表
-
实际业务中,为了数据安全起见,可以把要操作的表先提前做个备份,操作其中一张表,万一操作有误,可以拿另一张表做恢复。
rename 旧表名 to 新表名; -- 这样就把表暂时复制一份了 也可以 CREATE TABLE tb_name AS SELECT * FROM tb_name_old
修改表名
alter table old_tablename rename to/as new_tablename;
创建视图
-
关键是这个as,创建表也可以用下面这种语法
CREATE VIEW <视图名> AS <SELECT语句> CREATE VIEW v_students_info (s_id,s_name,d_id,s_age,s_sex,s_height,s_date) AS SELECT id,name,dept_id,age,sex,height,login_date FROM tb_students_info;
以查询的其他表的方式建表
-
create table new_table_name as select 字段... from old_table_name;
-
以查询old table的表的结构建new_table(可以是old_table的部分字段,也可以是全部字段)
--示例: create table mysql_dp_dm.`TEMP_NODE_INDUSTRY_ENTERPRISE_20220805` AS select NODE_NAME ,INDUSTRY_NAME ,ENTERPRISE_NAME ,ENTERPRISE_ADDRESS ,ROUND(BUSINESS_INCOME,2) ,ROUND(INCOME_GROWTH_RATE,2) ,ROUND(PROFIT_GROWTH_RATE,2) ,ROUND(TOTAL_PROFIT,2) ,DATA_TIME ,CREATETIME from mysql_dp_dm.`NODE_INDUSTRY_ENTERPRISE`;
建表时添加两列时间字段
DROP TABLE IF EXISTS `mytesttable`; CREATE TABLE `mytesttable` ( `id` int(11) NOT NULL, `name` varchar(255) DEFAULT NULL, `createtime` datetime DEFAULT CURRENT_TIMESTAMP, --default current_timestamp为关键字,表示默认当前时间 `updatetime` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`id`) --指定主键为id字段 ) ENGINE=InnoDB DEFAULT CHARSET=gbk; --datetime为时间类型,和int,varchar类型一样
建表后添加注释
ALTER TABLE DM_IS_IND_INDIV_COMMER_INDU_DA COMMENT '个体工商户'; ALTER TABLE DM_PE_OBE_EXPRESS_DELIVERY_DA COMMENT '快递表'; ALTER TABLE DM_PE_OBE_XYT_TAKE_OUT_CLERK_INFO_DA COMMENT '骑手表'; ALTER TABLE DM_PE_OBE_RIDE_HAILING_DA COMMENT '网约车'; ALTER TABLE DM_PE_POP_LOW_INCOME_HOUSEHOLD_DA COMMENT '低收入人群户主表'; ALTER TABLE DM_PE_PER_GRADUATES_DA COMMENT '大学生情况表'; ALTER TABLE `dm_fa_smart_hub_metrics_information_ma` COMMENT '固定资产投资指标信息'; ALTER TABLE `dm_fa_smart_association_ma` COMMENT '固定资产投资指标关联表'; ALTER TABLE dm_mlk_business_directory_ma COMMENT '企业名录表'; ALTER TABLE dm_tzh_view_carbon_card_da COMMENT '碳中合能耗企业明细数据'; ALTER TABLE dm_tzh_view_carbon_data_indicator_da COMMENT '碳中合能耗综合数据';
建表后添加外键
alter table second_tableName add constraint constraintname foreign key(secondtablename.foreignkeycolumnname) --由于外键在两表的名称一致,需要指定aid的来源表 reference firsttablename (columnname) --案例展示 alter table manuscript add constraint fk_aid foreign key (manuscript.aid) --由于外键在两表的名称一致,需要指定aid的来源表 references author (aid)
建表后添加主键
-
并将主键添加在第一行
ALTER TABLE DM_KNOWLEDGEGRAPH_INDEX_QI ADD COLUMN ID INT(14) PRIMARY KEY AUTO_INCREMENT FIRST;
建表时添加入库时间字段@now()
insert into table_1 select ziduan_1,zudaun_2,now() --入库时间 from table_2
建表时关于double通常给多少精度问题
create table if not exists T_DATA_TRANSFER_33 ( unitName varchar(90), `value` double(10,2), -- double一般给10,2 INPUTDATETIME datetime, ... );
DCL (数据控制语言)
地市库 create table qs_xq_mobile_county_result_new as select * from qs_xq_mobile_county_result; create table qs_xq_mobile_city_result_new as select * from qs_xq_mobile_city_result; create table qs_xq_mobile_zone_result_new as select * from qs_xq_mobile_zone_result; create table qs_xq_mobile_city_list_new as select * from qs_xq_mobile_city_list; hzywzc grant all on qs_xq_mobile_county_result_new to develop_sysa; grant all on qs_xq_mobile_county_result_new to develop_sysb; grant all on qs_xq_mobile_city_result_new to develop_sysa; grant all on qs_xq_mobile_city_result_new to develop_sysb; grant all on qs_xq_mobile_zone_result_new to develop_sysa; grant all on qs_xq_mobile_zone_result_new to develop_sysb; grant all on qs_xq_mobile_city_list_new to develop_sysa; grant all on qs_xq_mobile_city_list_new to develop_sysb;
授予查询权限
use 数据库 go grant select on 表名 to user1;
授予登录权限
grant usage on ... to grant usage on *.* to 'nkw'@'%'; grant all on qs_xq_mobile_city_result_new to develop_sysa; -- 赋予所有用户查询权限 grant all on qs_IotAntiFraud3_20230524 to public; --授权语句 GRANT 权限 ON 库名.表名 to '用户名'@'允许的ip(所有%)' IDENTIFIED BY '用户密码'; --所有数据库 *.* TO --某个数据库所有的权限 ALL 后面+ PRIVILEGES GRANT ALL PRIVILEGES ON 库名.* to '用户'@'%' IDENTIFIED BY '密码'; // *代表所有表, %代表所有IP --某个数据库 特定的权限 权限后面没有 PRIVILEGES 所有的数据库权限- *.* GRANT select,update,insert,delete ON 库名.* to '用户名'@'%' IDENTIFIED BY '用户密码'; -- 这个表示授予mirror这个用户对 qs_list_宽带受理 这张表的查询权限 grant select on qs_list_宽带受理 to mirror;
收回查询权限
use 数据库 go revoke select on 表名 from user1;
MySQL中较少见的函数
1.substring_index(参数str,参数delim,参数count)
该函数的作用:选取某个固定分隔符中特定位置的内容
--假如我这里有一个字符串 str=www.Geekerjun.com str就像数据库中的一个字段 substring_index(str,'.',1) 结果是:www substring_index(str,'.',2) 结果是:www.Geekerjun 也就是说,如果count是正数,那么就是从左往右数,第N个分隔符的左边的全部内容! 相反,如果是负数,那么就是从右边开始数,第N个分隔符右边的所有内容,如: substring_index(str,'.',-2) 结果为:Geekerjun.com**2、round函数**
2.round函数
该函数作用:用来四舍五入
ROUND(...,1) :表示保留1位
3.with rollup函数
使用 WITH ROLLUP,此函数是对聚合函数进行求和,注意 with rollup是对 group by分组后的基础上,再做一次汇总统计,类似就是每次学校表里最后一行的`合计`。 详情参考: https://blog.csdn.net/qq_31960623/article/details/115917641?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522166677664516782417053618%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=166677664516782417053618&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-115917641-null-null.142^v62^pc_search_tree,201^v3^add_ask,213^v1^control&utm_term=WITH%20ROLLUP&spm=1018.2226.3001.4187
4.vlookup函数
VLOOKUP 4个参数表示: =VLOOKUP(查找的内容、要查找的位置、包含要返回的值的范围内的列号、返回表示为 1/TRUE 或 0/FALSE 的近似或精确匹配项)。 -- 第一个参数是选单元格,不是选一列!!! -- 一般最后一个参数都选0,表示精准匹配的意思
MySql中变量的使用
--注意在变量前要加@ SET @value=1; SELECT @value >>>1 SET @dahua ='真帅'; SELECT @dahua; >>>真帅 SET @a=1; SET @b=2; SET @avg=(@a+@b)/2; SELECT @avg; >>>1.5000000
-
MySQL中@的用法
MySQL中符号@的作用Mysql脚本之家 (jb51.net)
常见字段类型总结
varchar
1.用于存入固定长度的字符,最多65535个字符 2.varchar可直接创建索引,text创建索引要指定前多少个字符。 3.varchar查询速度快于text,在都创建索引的情况下,text的索引似乎不起作用。
-
关于varchar的一些事项
1.经常变化的字段用varchar 2.知道固定长度的用char 3.尽量用varchar 4.超过255字节的只能用varchar或者text 5.能用varchar的地方不用text
decimal
-- 和浮点数不同的是,decimal是定点数 1.浮点型在数据库中存放的是近似值,而定点类型在数据库中存放的是精确值 2.当我们需要存储小数,并且有精度要求,比如存储金额时,通常会考虑使用DECIMAL字段类型 3.列的声明语法是DECIMAL(M,D): M是最大位数(精度),范围是1到65。可不指定,默认值是10。 D是小数点右边的位数(小数位)。范围是0到30,并且不能大于M,可不指定,默认值是0。 -- 例如字段 salary DECIMAL(5,2),能够存储具有五位数字和两位小数的任何值,因此可以存储在salary列中的值的范围是从-999.99到999.99。
double
和float都是浮点数,一般建表有需要小数的时候可以用它,但不推荐,因为它的精度不准确,要精度准确的推荐用decimal double(m,d) 双精度浮点型 16位精度(8字节) m总个数,d小数位
blob
1.概念: BLOB (binary large object)二进制大对象,是一个可以存储二进制文件的容器。 在计算机中,BLOB常常是数据库中用来存储二进制文件的字段类型。 BLOB是一个大文件,典型的BLOB是一张图片或一个声音文件,由于它们的尺寸,必须使用特殊的方式来处理。 2.MySQL的四种BLOB类型: MySQL中BLOB是个类型系列,包括:TinyBlob、Blob、MediumBlob、LongBlob,这几个类型之间的唯一区别是在存储文件的最大大小上不同。 --类型 大小(单位:字节) TinyBlob 最大255 Blob 最大65K MediumBlob 最大16M LongBlob 最大4G
索引
索引是存储引擎用来快速查找记录的一种数据结构,按照实现的方式,可以分为Hash索引和B+Tree索引
索引在关系型数据库中,也叫键,它是一个特殊的文件,保存着表里所有记录的位置信息。更通俗的说,数据库索引好比一本书前面的目录,能加快数据库的查询速度。
索引的分类
Hash索引
在索引列会每一行生成一个数字,然后会把每一行的数据放到该数字对应的位置,找这行的时候直接找这个数字,再通过其对应的位置,就可以找到对应的数据

B+Tree索引
B+树索引的原理是将数据按照键值排序,分层存储在多叉树结构中,通过平衡操作保持树的平衡性,提高查询效率。


索引的操作
索引的介绍
-
单列索引:一个索引只包含单个列,但一个表可以包含多个单列索引
-
普通索引:MySQL中的基本索引类型,没有什么限制,允许在定义索引的列中插入重复值和空值,纯粹为了查询数据更快一点
-
唯一索引:和普通索引类似,不同的是索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。
-
主键索引:每张表一般都有自己的主键,建表时MySQL会自动在主键列建一个主键索引。主键索引唯一且不为空。
-
组合索引:也叫复合索引,指我们在建立索引时使用多个字段,同样可以建立为普通索引或唯一索引。组合索引符合最左原则。
索引创建
----------------------------------普通索引-------------------------------------- - (下面这几种方式加的索引都是B+Tree) - 表中的主键,数据库会自动对其创建索引 1.建表时创建索引 create table student( sid int primary key, card_id varchar(20), name varchar(20), ... index index_name(name) --给name列创建索引,后面如果根据name列查询,效率会比较高 ) 2.建表后创建索引 create index index_gender on student(gender); --student表 index_gender索引名,在gender列加索引 3.建表后添加索引(这个在表查询慢的时候常用!!) alter table student add index index_age(age); --student表 index_age索引名 --一般索引列加在大表上,小表可加可不加 --加好索引之后,再用两个表各加过索引的列去关联就好了 ----------------------------------唯一索引-------------------------------------- 比如人名,性别,年龄,出生年月等这些会有重复值的这些字段就不能用唯一索引。手机号,身份证号倒是可以。 -- 方式一:建表的时候直接指定 create table student2( sid int primary key, card_id varchar(20), ... unique index_card_id(card_id) --给card_id列创建索引 ) -- 方式二:建表后创建唯一索引 CREATE UNIQUE INDEX uniq_idx_exam_id ON examination_info(exam_id); -- 方式三:建表后添加唯一索引 -- alter table 表名 add unique [索引名](列名) alter table student2 add unique index_phone_num(phone_num) ----------------------------------全文索引-------------------------------------- CREATE FULLTEXT INDEX full_idx_tag ON examination_info(tag); ----------------------------------组合索引-------------------------------------- -- 组合索引 例如可以同时使用身份证和手机号建立符合索引。 --创建索引基本语法 create index 索引名 on 表名(column1(length),column2(length)); --举例 create index index_phone_name on student(phone_num,name)
删除索引
-
注意:删除索引不管是普通索引,唯一索引,全文索引,都是一个语句,把索引名换一下就行
--语法 drop index 索引名 on 表名 --或 alter table 表名 drop index 索引名 --示例 drop index index_card_id on student2 --or alter table student2 drop index index_phone_num
查看索引
--语法:show index from table_name show index from student;
联合索引
又叫符合索引,即一个索引文件覆盖两个或多个字段,适用于多个字段一起查询的时候。
create table teacher( id int not primary key auto_increment, name varchar(10), age int ) -- 创建联合索引 alter table teacher add index(name,age); -- 不加索引的名字,索引名默认为一个字段名 -- 查看索引 show create table teacher;
联合索引的好处
-
减少磁盘空间开销,因为没创建一个索引,其实就是常见了一个索引文件,会增加磁盘开销。

索引的优缺点

存储过程:
概述
方法的介绍:
什么是方法(函数):方法也叫函数,是为了实现某个功能写的一组程序代码。这一组代码可能由一句或者多句组成,最后由一个专门的符号括起来,外面再套一个方法名就成了一个方法。以后每次要实现某个功能的时候,就调用这个方法名就可。 方法的好处:提高了代码的复用性,减少了重复操作。
存储过程的介绍:
存储过程类似Java中的方法。是多句SQL集合起来实现的某个功能,用一个存储过程名包起来,后面想要实现某个SQL功能的时候,调用这个存储过程名就可以,提高了SQL的复用性,减少了重复操作。
存储过程使用语法:
-- 创建 delimiter 自定义结束符号,一般$$ create procedure 存储过程名(参数列表) begin sql语句 --就是一组合法的sql语句 end 自定义的结束符号,一般$$ delimiter; --- 以后直接粘贴这里就行 delimiter $$ create procedure proc_0X() begin end $$ delimiter; -- 调用 call 存储过程名(); -- 删除 DROP PROCEDURE proc_16;
入门案例
-- 01 delimiter $$ create procedure proc01() begin select exam_id from exam_record; end $$ delimiter ; call proc01();
注意:
1. 参数列表包含三部分: 参数模式, 参数名,参数类型 举例: IN stuName VARCHAR(20) 参数模式: IN :该参数作为输入,表示调用方需要在存储过程里写入的值 OUT:该参数作为输出,也就是可以作为返回值 INOUT: 既可以作为输入,也可以作为输出.既可以传入值,又可以返回值 2. 如果存储过程仅仅只有一句话,BEGIN END 可以省略 3. 存储过程体中每条sql语句结尾必须加分号 4. 存储过程结尾可以使用DELIMITER重新设置 语法: DELIMITER 结束表示 案例 DELIMITER $
移动案例
call tab_to_pdbraptor('qs_xq_mobile_county_result_new');
call tab_to_pdbraptor('qs_xq_mobile_city_result_new');
call tab_to_pdbraptor('qs_xq_mobile_zone_result_new');
call tab_to_pdbraptor('qs_xq_mobile_city_list_new');
上述四条语句是数据库中执行存储过程的语句。这个语句调用了名为 tab_to_pdbraptor 的存储过程,并传递了参数 'qs_xq_mobile_city_list_new'。
存储过程的具体实现会根据数据库系统和存储过程定义而有所不同。一般来说,这个存储过程的目的是将名为 'qs_xq_mobile_city_list_new' 的表转换为适用于 PDB Raptor 的格式或进行相应的处理。
局部变量
顾名思义,在局部范围内起作用。需要用户自定义,在begin/end块中有效
语法:声明变量 declare var_name type [default var_value]; 举例:declare nickname varchar(32);
delimiter $$ create procedure proc02() begin declare var_name01 varchar(20) default 'aaa'; set var_name01 = 'zhangsan'; -- set是定义变量 select var_name01; -- select是输出变量 end $$ delimiter; -- 调用存储过程 call proc02() >>> zhangsan
-
MySQL中还有另外一种给变量赋值的方式 select into
delimiter $$ create procedure proc03() begin declare my_uid varchar(20); select uid into my_uid from exam_record where empno>=1001; -- 这个地方是错的,一个变量不能同时赋多个值 select uid into my_uid from exam_record where empno=1001; -- 这么写也是错的,因为empno=1001有多个 select uid into my_uid from exam_record where id=1; -- 这么写是对的 select my_uid; end $$ call proc03() >>> 1001
用户变量
不仅在begin和end中间起作用,而是在当前会话(连接)都起作用,类似Java中的成员变量。
delimiter $$ create procedure proc04() begin set @var_name01 = 'zs'; -- 不要声明,直接赋值就可以 end $$ delimiter ; -- 这一步是把结束符还原到正常状态 call proc04(); select @var_name01 -- 可以看到效果
系统变量
系统变量又分为全局变量和会话变量。
全局变量在MySQL启动的时候由服务器自动将他们初始化为默认值,这些默认值可以通过更改my.ini这个文件夹来更改。
会话变量在每次建立一个新的连接的时候,由MySQL来初始化。MySQL会将当前所有全局变量的值复制一份,来作为会话变量。
也就是说,在建立会话以后,没有手动更改过的会话变量的值,和全局变量的值,都是一样的。
全局变量和会话变量的区别就在于,对全局变量的修改会影响到整个服务器,但是对会话变量的修改,只会影响到当前会话(即当前数据库的连接)。
有些系统变量的值可以利用语句来动态进行更改,对于这些值我们可以通过set语句进行更改,但是有些系统变量的值却是只读的。
-
全局变量
-- 查看全局变量 show global variables; -- 查看某全局变量 select @@global.auto_increment_increment; -- 修改全局变量的值 set global sort_buffer_size = 40000; set @@global.sort_buffer_size = 40000;
-
会话变量
-- 查看会话变量 show session variables; -- 查看某会话变量 select @@session.auto_increment_increment; -- 修改会话变量的值 set session sort_buffer_size = 50000; set @@session.sort_buffer_size = 50000;
参数传递
参数in
-- 02:根据传入的部门uid,匹配表中对应uid的行
delimiter $$
create procedure proc06(in param_uid int)
begin
select * from exam_record where uid =param_uid;
end $$
delimiter ;
call dec_param01(1001);
-- 03:封装有参数的存储过程,可以通过传入的部门名和薪资,查询指定部门且薪资大于指定值的员工信息
delimiter $$
create procedure proc07(in param_dept varchar(20),in param_sal decimal(7,2))
begin
select * from dept a, emp b where a.deptno=b.deptno and a.dname=param_dept and sal>param_sal;
end $$
delimiter ;
call proc07('学工部',20000);
参数out
out表示 从存储过程内部传值给调用者
-- 案例:传入员工编号uid,返回考试编号exam_id delimiter $$ create procedure proc08(in in_uid int,out out_exam_id int) begin select exam_id into out_exam_id from exam_record where uid=in_uid; end $$ delimiter ; call proc08(1003,@o_exam_id); -- @o_exam_id使用来接受变量传出来的值,且不能接收返回多行的值 select @o_exam_id;
-
返回多个参数的情况
-- 案例:传入员工编号uid,返回考试编号exam_id delimiter $$ create procedure proc09(in in_uid int,out out_exam_id int,out out_start_time varchar(100)) begin select exam_id,start_time into out_exam_id,out_start_time from exam_record where uid=in_uid; end $$ delimiter ; call proc09(1003,@o_exam_id,@o_start_time); -- @o_exam_id使用来接受变量传出来的值,且不能接收返回多行的值 select @o_exam_id; select @o_start_time;
参数inout
inout表示从外部传入的参数经过修改后,还可以返回出来的变量,既可以使用传入值使用,也可以修改变量的值(即使函数执行完)
-- 案例: -- 传入一个数字,传出这个数字*10倍后的值 delimiter $$ create procedure proc10(inout num int) begin set num = num * 10; end $$ delimiter ; set @var=2; call proc10(@var); select @var; >>> 20
-- 案例:传入一个exam_id,传出exam_id拼接难度级别,传入一个duration分数,传出*50的总成绩 drop procedure proc11; delimiter $$ create procedure proc11(inout io_exam_id varchar(50),inout io_duration int) begin select concat(exam_id,difficulty) into io_exam_id from examination_info where exam_id=io_exam_id; set io_duration = io_duration *50; end $$ delimiter ; set @io_exam_id = 9001; set @io_duration=12; call proc11(@exam_id,@inout_duration); -- 里面这两个参数,在存储过程转了一圈,又出来了 select @exam_id; select @io_duration;

流程控制--分支语句
if
-- 语法 if 判断条件1 then 执行语句1 [elseif 判断条件2 then 执行语句2]... [else 执行语句n] end if
-
案例1
-- 输入用户年龄,判断其在大几 age=18 大一 age=19 大二 age=20 大三 USE test; DELIMITER $$ CREATE PROCEDURE proc_if(IN age INT) BEGIN IF age=18 THEN SELECT '大一'; ELSEIF age=19 THEN SELECT '大二'; ELSE SELECT '大三'; END IF; END $$ DELIMITER; CALL proc_if(18); -- 每一条if语句后面都要写个;号,包括最后的end if,后面也要写;
-
案例2
delimiter $$ create procedure proc_if_score(in score int) begin if score < 60 and 0 =< score then select '不及格'; -- 60<score这么写是错的 elseif 60 =< score and score <80 then select '及格'; elseif score>=80 and score < 100 then select '良好'; elseif score=100 then select '优秀'; else select '成绩错误'; end if; end $$ delimiter ; set @sc=80; call proc_if_score(@sc); -- if语句里,变量要写在比较符号的左边
case
-
语法一
delimiter $$ create procedure proc_case(in pay_type int) begin case pay_type when 1 then select '微信支付'; when 2 then select '支付宝支付'; when 3 then select '银行卡支付'; else select '其他方式支付'; end case; end $$ delimiter ; call proc_case(1); >>> 微信支付
-
语法二
delimiter $$ create procdure proc_case(in score int) begin case when score<60 then select '不及格'; when score<80 then select '及格'; when score>=90 and score<=100 then select '优秀'; else select '成绩错误'; end case; end $$ delimiter ;
流程控制--循环语句
while循环
-
语句
【标签:】while 循环条件 do 循环体 end while 【标签】; -- 备注:标签可以省略,但如果开始写了,结束标签也要写
repeat循环
loop循环
游标cursor
异常处理-句柄
练习,总结,操作
心得:
-
以后可以把我写的固定的select语句写成存储过程,后面每次调用这个存储过程就可以了
正则表达式
移动dm平台不支持
-
学习地址
https://www.runoob.com/regexp/regexp-syntax.html
-
概念
正则表达式,就是一个字符串,这个字符串定义了一个规则,可以用来匹配其他字符串。
-
.+?*
.表示匹配任意一个字符 +号标识前面的字符(注意是字符,不是前面整个字符串)至少出现一次(1次,n次)。 *号标识前面的字符可以出现,也可以不出现(0次,1次,n次) ?号表示前面的字符最多出现一次(0次或1次)
-
说明
runoo+b,可以匹配 runoob、runooob、runoooooob 等,+ 号代表前面的字符必须至少出现一次(1次或多次)。 runoo*b,可以匹配 runob、runoob、runoooooob 等,* 号代表前面的字符可以不出现,也可以出现一次或者多次(0次、或1次、或多次)。 colou?r 可以匹配 color 或者 colour,? 问号代表前面的字符最多只可以出现一次(0次或1次)。
-
格式



-
正则表达式写在where的后面
select * from product where pname regexp '^海';
-
我自己的库里
SELECT * FROM examination_info WHERE tag REGEXP '^S'; >>> id exam_id tag difficulty duration release_time 1 9001 SQL hard 60 2020-01-01 10:00:00 2 9002 SQL hard 80 2020-01-01 10:00:00 SELECT * FROM user_info WHERE nick_name REGEXP '号$'; >>> id uid nick_name achievement level job register_time 2 1002 牛客2号 2500 6 算法 2020-01-01 10:00:00 10 104 牛客4号 3200 7 算法 2022-11-08 14:24:21 11 105 牛客5号 3200 7 算法 2022-11-08 14:24:21 12 106 牛客6号 3200 7 算法 2022-11-08 14:24:21 13 107 牛客7号 3200 7 算法 2022-11-08 14:24:21 14 108 牛客8号 3200 7 算法 2022-11-08 14:24:21 15 109 牛客9号 3200 7 算法 2022-11-08 14:24:21
| *字符* | *说明* |
|---|---|
| . | 匹配任意字符 |
| \ | 将下一字符标记为特殊字符、文本、反向引用或八进制转义符。例如,"n"匹配字符"n"。"\n"匹配换行符。序列"\\"匹配"","\("匹配"("。 |
| ^ | 匹配字符串开始。如果设置了 *RegExp* 对象的 *Multiline* 属性,^ 还会与"\n"或"\r"之后的位置匹配。 |
| $ | 匹配字符串结尾。如果设置了 *RegExp* 对象的 *Multiline* 属性,$ 还会与"\n"或"\r"之前的位置匹配。 |
| * | * 前面的字符可有可无。例如,zo* 匹配"z"和"zoo"。* 等效于 {0,}。 |
| + | 一次或多次。例如,"zo+"与"zo"和"zoo"匹配,但与"z"不匹配。+ 等效于 {1,}。 |
| ? | 零次或一次。例如,"do(es)?"匹配"do"或"does"中的"do"。? 等效于 {0,1}。 |
| {n} | n 是非负整数。正好匹配 n 次。例如,"o{2}"与"Bob"中的"o"不匹配,但与"food"中的两个"o"匹配。 |
| {n,} | n 是非负整数。至少匹配 n 次。例如,"o{2,}"不匹配"Bob"中的"o",而匹配"foooood"中的所有 o。"o{1,}"等效于"o+"。"o{0,}"等效于"o*"。 |
| {n,m} | M 和 n 是非负整数,其中 n <= m。匹配至少 n 次,至多 m 次。例如,"o{1,3}"匹配"fooooood"中的头三个 o。'o{0,1}' 等效于 'o?'。注意:您不能将空格插入逗号和数字之间。 |
| ? | 当此字符紧随任何其他限定符(*、+、?、{n}、{n,}、{n,m})之后时,匹配模式是"非贪心的"。"非贪心的"模式匹配搜索到的、尽可能短的字符串,而默认的"贪心的"模式匹配搜索到的、尽可能长的字符串。例如,在字符串"oooo"中,"o+?"只匹配单个"o",而"o+"匹配所有"o"。 |
| . | 匹配除"\r\n"之外的任何单个字符。若要匹配包括"\r\n"在内的任意字符,请使用诸如"[\s\S]"之类的模式。 |
| (pattern) | 匹配 pattern 并捕获该匹配的子表达式。可以使用 *9* 属性从结果"匹配"集合中检索捕获的匹配。若要匹配括号字符 ( ),请使用"("或者")"。 |
| (?:pattern) | 匹配 pattern 但不捕获该匹配的子表达式,即它是一个非捕获匹配,不存储供以后使用的匹配。这对于用"or"字符 (|) 组合模式部件的情况很有用。例如,'industr(?:y|ies) 是比 'industry|industries' 更经济的表达式。 |
| (?=pattern) | 执行正向预测先行搜索的子表达式,该表达式匹配处于匹配 pattern 的字符串的起始点的字符串。它是一个非捕获匹配,即不能捕获供以后使用的匹配。例如,'Windows (?=95|98|NT|2000)' 匹配"Windows 2000"中的"Windows",但不匹配"Windows 3.1"中的"Windows"。预测先行不占用字符,即发生匹配后,下一匹配的搜索紧随上一匹配之后,而不是在组成预测先行的字符后。 |
| (?!pattern) | 执行反向预测先行搜索的子表达式,该表达式匹配不处于匹配 pattern 的字符串的起始点的搜索字符串。它是一个非捕获匹配,即不能捕获供以后使用的匹配。例如,'Windows (?!95|98|NT|2000)' 匹配"Windows 3.1"中的 "Windows",但不匹配"Windows 2000"中的"Windows"。预测先行不占用字符,即发生匹配后,下一匹配的搜索紧随上一匹配之后,而不是在组成预测先行的字符后。 |
| x|y | 匹配 x 或 y。例如,'z|food' 匹配"z"或"food"。'(z|f)ood' 匹配"zood"或"food"。 |
| [xyz] | 字符集。匹配包含的任一字符。例如,"[abc]"匹配"plain"中的"a"。 |
| [^xyz] | 反向字符集。匹配未包含的任何字符。例如,"abc"匹配"plain"中"p","l","i","n"。 |
| [a-z] | 字符范围。匹配指定范围内的任何字符。例如,"[a-z]"匹配"a"到"z"范围内的任何小写字母。 |
| [^a-z] | 反向范围字符。匹配不在指定的范围内的任何字符。例如,"a-z"匹配任何不在"a"到"z"范围内的任何字符。 |
| \b | 匹配一个字边界,即字与空格间的位置。例如,"er\b"匹配"never"中的"er",但不匹配"verb"中的"er"。 |
| \B | 非字边界匹配。"er\B"匹配"verb"中的"er",但不匹配"never"中的"er"。 |
| \cx | 匹配 x 指示的控制字符。例如,\cM 匹配 Control-M 或回车符。x 的值必须在 A-Z 或 a-z 之间。如果不是这样,则假定 c 就是"c"字符本身。 |
| \d | 数字字符匹配。等效于 [0-9]。 |
| \D | 非数字字符匹配。等效于 0-9。 |
| \f | 换页符匹配。等效于 \x0c 和 \cL。 |
| \n | 换行符匹配。等效于 \x0a 和 \cJ。 |
| \r | 匹配一个回车符。等效于 \x0d 和 \cM。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等。与 [ \f\n\r\t\v] 等效。 |
| \S | 匹配任何非空白字符。与 \f\n\r\t\v 等效。 |
| \t | 制表符匹配。与 \x09 和 \cI 等效。 |
| \v | 垂直制表符匹配。与 \x0b 和 \cK 等效。 |
| \w | 匹配任何字类字符,包括下划线。与"[A-Za-z0-9_]"等效。 |
| \W | 与任何非单词字符匹配。与"A-Za-z0-9_"等效。 |
| \xn | 匹配 n,此处的 n 是一个十六进制转义码。十六进制转义码必须正好是两位数长。例如,"\x41"匹配"A"。"\x041"与"\x04"&"1"等效。允许在正则表达式中使用 ASCII 代码。 |
| **num** | 匹配 num,此处的 num 是一个正整数。到捕获匹配的反向引用。例如,"(.)\1"匹配两个连续的相同字符。 |
| **n** | 标识一个八进制转义码或反向引用。如果 **n** 前面至少有 n 个捕获子表达式,那么 n 是反向引用。否则,如果 n 是八进制数 (0-7),那么 n 是八进制转义码。 |
| **nm** | 标识一个八进制转义码或反向引用。如果 *nm** 前面至少有 nm 个捕获子表达式,那么 nm 是反向引用。如果 *nm前面至少有 n* 个捕获,则 n 是反向引用,后面跟有字符 m。如果两种前面的情况都不存在,则 *nm** 匹配八进制值 nm,其中 n 和 m 是八进制数字 (0-7)。 |
| \nml | 当 n 是八进制数 (0-3),m 和 l 是八进制数 (0-7) 时,匹配八进制转义码 nml。 |
| \un | 匹配 n,其中 n 是以四位十六进制数表示的 Unicode 字符。例如,\u00A9 匹配版权符号 (©)。 |
notepad++ 替换空行
\r\n\r\n ---->>>> \r\n
公共表达式
在SQL中,WITH语句(也称为公共表表达式)用于创建临时表或视图,这些临时表或视图可以在查询中被引用,从而简化复杂的查询操作。
-- 例1
WITH employees_cte AS (
SELECT employee_id, first_name, last_name
FROM employees
WHERE department = 'IT'
)
SELECT *
FROM employees_cte
WHERE last_name LIKE 'Smith%';
-- 例2
'''需求:
1个表里面记录了上海队、北京队、广州队等球队,只有这一个列
给这些队伍安排对战比赛,如上海队VS北京队
注意:
上海队VS北京队 和 北京队VS上海队 是重复的 2选1即可
'''
DROP TABLE team;
CREATE TABLE team (
NAME VARCHAR(23)
);
INSERT INTO team VALUES ('北京'),('上海'),('广州'),('深圳');
WITH t1 AS (
SELECT a.*,row_number() over(ORDER BY NAME) AS rn
FROM team a
)
SELECT a.name,a.rn,b.name,b.rn
FROM t1 a
JOIN t1 b
WHERE a.rn<b.rn;
SQL优化
-
概念
在应用的开发过程中,由于初期数据量小,开发人员写SQL更重视功能上的实现,但是当应用系统正式上线后,随着生产数据量的急剧增长,很多SQL语句逐渐展露出性能问题,对生产的影响也越大,所以要优化
-
优化方式
1.从设计上优化,选择合适的存储引擎 2.从查询上优化,优化查询语句 3.从索引上优化,就是加索引,还可以对索引内部继续优化 4.从存储上优化,比如选择pg库或者oracle库或HBase库等等
查询参数
-
/+parallel(a,16)/ 这个参数表示用于使用 16 个并行线程进行并行处理,以提高查询性能。
select /*+parallel(a,16)*/city_id,'3',count(*) from dwfu_hive_db.A_USOC_USER_ATTR_M
笛卡尔积
定义:
第一个集合的所有对象,遍历第二个集合的所有对象。
当连接查询时:
-
如果没加on条件,会出现全部笛卡尔积。
-
当on后跟的条件是不止一个字段时,会出现局部笛卡尔积。
-
当on后跟的是唯一字段时,不会出现笛卡尔积
SQL慢查询定位
-
查看SQL执行频次
MySQL客户端连接成功后,通过show [session|global] status命令可以查看服务器的状态信息。 show session status like 'Com_______'; -- 查看当前会话统计结果 show global status like 'Com_______'; -- 查看自数据库上次启动至今统计结果 -- Com后面_的长度不一样,查出来的结果不一样 show status like 'Innodb_rows_%'; -- 查看针对Innodb引擎的统计结果


-
定位低效率执行SQL
可以通过如下两种方式定位执行效率低的SQL语句:
1.慢查询日志方式:通过慢查询日志定位执行效率底的SQL语句。
-- 查看慢日志配置信息 show variables like '%slow_query_log%'; -- 慢日志位置 D:\MySQL\DATA\DESKTOP-9LUO43A-slow.log -- 开启慢日志查询 set global slow_query_log=1; -- 查看慢日志记录SQL的最低阈值时间(秒) show variables like '%long_query_time%'; select sleep(12); -- 休眠12秒 -- 修改慢日志记录SQL的最低阈值时间 set global long_query_time=4; 上面这些操作只是在会话中修改,要想永久修改,得进入到my.ini文件修改
定位低效率执行SQL
show processlist; -- 该命令可以查看MySQL正在执行的线程,包括线程的状态,是否锁表等,可以实时查看SQL的执行情况,同时对所表操作进行优化


Explain分析执行计划
语法:explain SQL语句
explain select * from user where age=19;


备注:如果是多表联查,id的顺序就是每张表被加在的顺序。ID的数值越大,加载优先级越高。
优化的时候可以从type入手
字段说明:
type: explain select * from user where uname = '张飞'; 如果type里出现的是ALL;说明查询的这个字段没有索引,意味着这个查询需要将这个表全部扫描一遍,才能找到你要的这个值。 extra: 表示额外的信息
Explain之select_type
表示select的类型,常见的取值如下:

SQL优化
order by优化
-
order by后面的多个排序字段,要求尽量排序方式相同。并且要和组合索引字段顺序一致。
-
排序的时候,尽量不要写*,而是写索引字段。
-
适当调大max_length_for_sort_data和sort_buffer_size的值
MySQL中有一次扫描(内存)和两次扫描(内存+磁盘)算法,一次扫描是一次性取出满足条件的所有字段,然后在排序区sort buffer中排序后直接输出结果集。该算法排序时内存开销较大,但效率高。 show variables like 'max_length_for_sort_data'; -- 4096 show variables like 'sort_buffer_size'; -- 262144
-
两种排序方式
第一种是通过对返回数据进行排序,也就是说的filesort排序,所有不是通过索引直接返回排序结果的排序都叫FileSort排序。 第二种是通过有序索引顺序扫描直接返回有序数据,即为using index,不需要额外排序,操作效率高。
子查询优化
先说结论:能用Join表关联,就不要写子查询(子查询需要在内存中建一个临时表)。子查询效率比表关联慢很多。是因为Mysql中不需要在内存中创建临时表来完成这个逻辑上需要两个步骤的查询工作
查询效率:system>const>eq_ref>ref>range>index>ALL
大批量数据插入优化
大批量数据不用insert,太慢
-
主键顺序插入
因为InnoDB类型的表是按照主键顺序保存的,所以将导入的数据按照主键顺序排列,可以有效提高倒入数据的效率。如果你自己建的这个表没有主键,可以给表再额外创建一个主键,来提高倒入的效率。

-
加载命令
-- 先查看local_infile状态 show global variables like 'local_infile'; set global local_infile=1; -- 打开,变为可加载模式 load data local infile '文件位置(注意是\\这个分隔符)' into table 表名 fields terminated by ',' -- 字段间分隔符 lines terminated by '\n'; -- 换行符
-
关闭唯一性校验
这个如果开着的话,插入的每条数据会进行唯一性校验,看看这条数据存不存在。
在导入数据前,执行set unique_checks=0,执行结束后执行set unique_checks=1,恢复唯一性校验,可提高导入效率。
set unique_checks=0; set unique_checks=1;



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









