







原创不易,转载请注明出处
前言
在《美团开源分布式ID服务Leaf简单使用》一文中简单的介绍了一下leaf,包括它的配置与安装,使用起来还是非常简单的,在介绍leaf的时候,说过它有两种生成id的模式,一种是号段模式,一种是snowflake模式,
接下来该文就介绍一下号段模式的实现原理,进行源码剖析。
1.实现原理推演
关于号段模式,感觉很奇怪,当然这是与id生成原理有关的,我们在介绍号段模式配置的时候,需要配置mysql,同时需要在mysql中创建一个表。
既然它生成id与mysql有关,我们就介绍下mysql生成分布式ID的各种方法。
1.1 基于mysql最简单分布式ID实现
mysql自带自增主键功能,我们可以建一个表,主键id设置成自增,然后需要获取id,就往该表中插入一条数据,获取一下新增id即可。
这种方式优点就是简单。
缺点也很明显
- 随着时间推移,表中数据越来越多,毕竟获得一个id就要插入一条数据。
- 所有获取id的都去请求这个数据库,很显然,高并发场景下单机会很乏力。
1.2 flickr分布式id解决方案
针对1.1基于mysql实现的分布式id各种缺点,flickr公司提出了一种基于mysql生成分布式id的解决方案。
我们先看下它是怎么做的
先创建一个表。
CREATE TABLE `Tickets64` (
`id` bigint(20) unsigned NOT NULL auto_increment,
`stub` char(1) NOT NULL default '',
PRIMARY KEY (`id`),
UNIQUE KEY `stub` (`stub`)
) ENGINE=MyISAM
该表有2个字段,id就是bigint类型的mysql自增主键,stub,桩的意思,这里你可以把他用作业务key。
每次获取分布式id的时候,根据业务id执行下面这两条sql就可以了。
REPLACE INTO Tickets64 (stub) VALUES (‘a’);
SELECT LAST_INSERT_ID();
REPLACE INTO Tickets64 (stub) VALUES (‘a’);这行,就是更新a这条数据的主键id
可以测试下,比如说我现在表中有这么一条数据。

执行: REPLACE INTO Tickets64 (stub) VALUES (‘a’);

如果这个stub存在a的话,就更新一下这个id。
不存在就新插入一条

SELECT LAST_INSERT_ID();就是获取当前connection最新插入的id。
到这里,1.1方案 缺点1 数据量越来越多的问题就解决了。
对于缺点2,单机高并发问题,它也提出来解决方案。
那就是多机器部署。使用多台mysql数据库,通过设置自增步长与起始id 达到多台数据库协调生成分布式id。
我们来看下它是怎样实现的。
假设我们使用2台mysql,分别有一张Tickets64 表。
这个时候,设置表的自增主键步长是2,mysql-01表中的其实id是1 ,mysql-02表中的id起始是2。这样他们的id就搓开了。
mysql-01:
auto-increment-increment = 2
auto-increment-offset = 1
mysql-02:
auto-increment-increment = 2
auto-increment-offset = 2
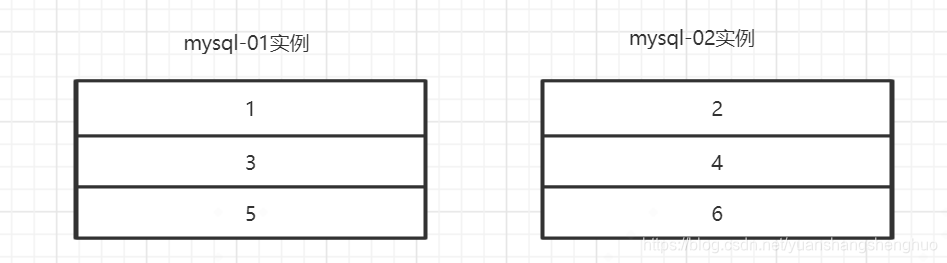
不同mysql实例生成的id就是这个样子。
这样就完美解决了单机高并发乏力的问题。
但是问题又来了!!!
我一开始要搞几台mysql实例来用作分布式id生成,一开始业务量小,搞多了资源浪费,搞少了后期大流量的时候,还是扛不住,到时候再想加机器,就得调整自增步长,起始id,就会非常麻烦,非常麻烦,扩展性非常差。
虽然flicker解决方案存在扩展性问题,但是一般公司还是可以使用的。
1.3 号段+mysql
到这里我们看看leaf是怎样基于号段+mysql实现的分布式id生成的。
CREATE TABLE `leaf_alloc` (
`biz_tag` varchar(128) COLLATE utf8_unicode_ci NOT NULL DEFAULT '',
`max_id` bigint(20) NOT NULL DEFAULT '1',
`step` int(11) NOT NULL,
`description` varchar(256) COLLATE utf8_unicode_ci DEFAULT NULL,
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`biz_tag`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci;
biz_tag :就是业务标识
max_id:既是起始id也是最大id
step:步长或者是段长
description:描述,这个不用管
update_time:更新时间,这个不用管
比如说我要整一个订单id生成的,这个时候插入一条数据即可

这个时候我就要生成id。
leaf是这样做的。
- 先去判断内存中 有没有这个biz_tag对应的atomicInteger,没有就执行这两个sql
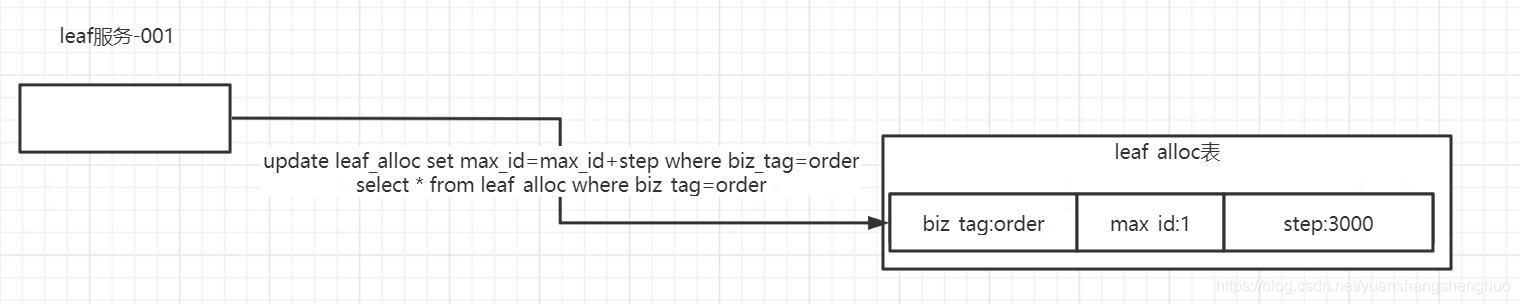

可以看到,这个时候数据库中的max_id就变成了3001,同时他还将 max_id 与step 查到leaf服务内存中。将max_id与step相加之前的那个值设置到一个原子类中。将现在的max_id设置到一个max变量中。
- 下次再来获取order的分布式id,一看 atomicInteger中的数值小于max 值,直接就拿atomicInteger 进行累加了。
直到atomicInteger大于max ,这个时候再重复执行一次步骤1。
你会发现,大部分的生成id都是在leaf服务中完成的,只有很少请求是在数据库完成的,而且step数值越大,对mysql压力就会越小,因为都是在leaf服务中完成的自增长。
而且leaf 支持集群部署,mysql行锁保证多leaf实例更新同一条数据不会出现问题,同时扩展由mysql 转向了leaf服务,保证高并发,多数leaf服务内存完成id生成,保证高性能,集群部署,保证高可用。
好了。leaf的号段模式原理我们就介绍完了,接下来分析一下源码,源码实现其实比上面的原理更加巧妙,我们一起分析下。
2.源码剖析
这个时候需要我们去github(地址:https://github.com/Meituan-Dianping/Leaf)上面,将源码clone下来,然后导入到idea中
可以看到,分为了leaf-core与leaf-server两个module,id生成核心逻辑在core中,然后这个server其实就是充当服务的意思,对外提供生成id的http接口,是基于springboot写的。
既然是提供http服务,我们顺着controller往下找即可。
LeafController#getSegmentID
@RequestMapping(value = "/api/segment/get/{key}")
public String getSegmentID(@PathVariable("key") String key) {
return get(key, segmentService.getId(key));
}
一看很熟悉,哈哈哈。
它调用的是segmentService 的getId方法。
这个SegmentService是个service。
2.1初始化
我们需要看下他的构造,spring创建实例bean的时候会触发。
public SegmentService() throws SQLException, InitException {
Properties properties = PropertyFactory.getProperties();
boolean flag = Boolean.parseBoolean(properties.getProperty(Constants.LEAF_SEGMENT_ENABLE, "true"));
if (flag) {
// Config dataSource
dataSource = new DruidDataSource();
dataSource.setUrl(properties.getProperty(Constants.LEAF_JDBC_URL));
dataSource.setUsername(properties.getProperty(Constants.LEAF_JDBC_USERNAME));
dataSource.setPassword(properties.getProperty(Constants.LEAF_JDBC_PASSWORD));
dataSource.init();
// Config Dao
IDAllocDao dao = new IDAllocDaoImpl(dataSource);
// Config ID Gen
idGen = new SegmentIDGenImpl();
((SegmentIDGenImpl) idGen).setDao(dao);
if (idGen.init()) {
logger.info("Segment Service Init Successfully");
} else {
throw new InitException("Segment Service Init Fail");
}
} else {
idGen = new ZeroIDGen();
logger.info("Zero ID Gen Service Init Successfully");
}
}
首先是看看配置参数leaf.segment.enable是否要启用号段模式,可以看到默认是true,如果是true,就会根据你配置的数据配置信息创建数据源,然后创建一个dao,这里不用管,你就当做平常开发使用的dao一样就可以。
接着是创建SegmentIDGenImpl 对象,然后将dao赋值给他,最后调用init方法
如果是没有开启号段模式,也就是leaf.segment.enable 是false的话,就会创建ZeroIDGen 对象,这个玩意生成的key就是0。
接下来看看SegmentIDGenImpl的init初始化方法。
@Override
public boolean init() {
logger.info("Init ...");
// 确保加载到kv后才初始化成功
updateCacheFromDb();
initOK = true;
// 启动延时任务,然后每分钟执行一次
// 主要还是每分钟从数据库中更新cache
updateCacheFromDbAtEveryMinute();
return initOK;
}
第一步是从mysql中加载biz_tag,然后更新到缓存
第二步就是启动延时任务,每分钟执行一次第一步,确保mysql新增的biz_tag能够被缓存初始化。
这里我们看下updateCacheFromDb 就行了。
private void updateCacheFromDb() {
// 获取数据库中所有的 biz_tag
List<String> dbTags = dao.getAllTags();
if (dbTags == null || dbTags.isEmpty()) {
return;
}
// 本地缓存里面的
List<String> cacheTags = new ArrayList<String>(cache.keySet());
// db里面的
List<String> insertTags = new ArrayList<String>(dbTags);
//本地缓存
List<String> removeTags = new ArrayList<String>(cacheTags);
//db中新加的tags灌进cache,这里就是将所有
insertTags.removeAll(cacheTags);
for (String tag : insertTags) {
SegmentBuffer buffer = new SegmentBuffer();
buffer.setKey(tag);
Segment segment = buffer.getCurrent();
segment.setValue(new AtomicLong(0));
segment.setMax(0);
segment.setStep(0);
cache.put(tag, buffer);
logger.info("Add tag {} from db to IdCache, SegmentBuffer {}", tag, buffer);
}
//cache中已失效的tags从cache删除
removeTags.removeAll(dbTags);
for (String tag : removeTags) {
cache.remove(tag);
logger.info("Remove tag {} from IdCache", tag);
}
}
这里其实就是获取一下表中所有的biz_tag,然后更新一下本地的缓存,没有的加进去,失效的或者删除的从缓存中删除
缓存就是个ConcurrentHashMap
private Map<String, SegmentBuffer> cache = new ConcurrentHashMap<String, SegmentBuffer>();
好了,到这里初始化就完事了
2.2 生成id
生成id就是调用的SegmentIDGenImpl#get方法。
public Result get(final String key) {
if (!initOK) {
return new Result(EXCEPTION_ID_IDCACHE_INIT_FALSE, Status.EXCEPTION);
}
if (cache.containsKey(key)) {
// 从缓存中获取对应key的SegmentBuffer
SegmentBuffer buffer = cache.get(key);
// 如果没有初始化ok
if (!buffer.isInitOk()) {
synchronized (buffer) {
if (!buffer.isInitOk()) {
try {
// 从数据库中加载key
updateSegmentFromDb(key, buffer.getCurrent());
logger.info("Init buffer. Update leafkey {} {} from db", key, buffer.getCurrent());
//初始化成功
buffer.setInitOk(true);
} catch (Exception e) {
logger.warn("Init buffer {} exception", buffer.getCurrent(), e);
}
}
}
}
// 获取id 从segmentBuffer中
return getIdFromSegmentBuffer(cache.get(key));
}
return new Result(EXCEPTION_ID_KEY_NOT_EXISTS, Status.EXCEPTION);
}
显示看看缓存有没有这个key对应的SegmentBuffer ,这个SegmentBuffer 非常有意思。缓存中没有这个buffer的话,就会返回异常了
如果有就从缓存中获取这个SegmentBuffer ,判断SegmentBuffer 有没有初始化,如果是leaf服务刚启动的话,肯定是没有初始化的,这个时候加锁,double check 调用updateSegmentFromDb(key, buffer.getCurrent()); 方法来初始化buffer。
在初始化buffer之前我们要先介绍下SegmentBuffer 结构了。
public SegmentBuffer() {
// 创建Segment数组,就2个元素
segments = new Segment[]{new Segment(this), new Segment(this)};
// 当前位置是0
currentPos = 0;
nextReady = false;
initOk = false;
threadRunning = new AtomicBoolean(false);
// 读写锁
lock = new ReentrantReadWriteLock();
}
这是SegmentBuffer 构造,可以看到,上来就创建了2个元素的segments 。这个玩意非常重要, currentPos 当前处于哪个Segment 。
接着看看Segment 里面都有啥
private AtomicLong value = new AtomicLong(0);
private volatile long max;
private volatile int step;
private SegmentBuffer buffer;
接着回到updateSegmentFromDb ,初始化SegmentBuffer
public void updateSegmentFromDb(String key, Segment segment) {
StopWatch sw = new Slf4JStopWatch();
SegmentBuffer buffer = segment.getBuffer();
LeafAlloc leafAlloc;
if (!buffer.isInitOk()) {
leafAlloc = dao.updateMaxIdAndGetLeafAlloc(key);
// 设置step
buffer.setStep(leafAlloc.getStep());
buffer.setMinStep(leafAlloc.getStep());//leafAlloc中的step为DB中的step
} else if (buffer.getUpdateTimestamp() == 0) {
leafAlloc = dao.updateMaxIdAndGetLeafAlloc(key);
buffer.setUpdateTimestamp(System.currentTimeMillis());
buffer.setMinStep(leafAlloc.getStep());//leafAlloc中的step为DB中的step
} else {
// 距离上次更新数据隔了多长时间
long duration = System.currentTimeMillis() - buffer.getUpdateTimestamp();
int nextStep = buffer.getStep();
// 如果是小于15分钟的话
if (duration < SEGMENT_DURATION) {
if (nextStep * 2 > MAX_STEP) {
//do nothing
} else {
// 重新设置步长。是原来步长的2倍,但是不能超过1000000
nextStep = nextStep * 2;
}
// 小于 30分钟
} else if (duration < SEGMENT_DURATION * 2) {
//do nothing with nextStep
} else {
// 大于30分钟
// 缩短步长
nextStep = nextStep / 2 >= buffer.getMinStep() ? nextStep / 2 : nextStep;
}
logger.info("leafKey[{}], step[{}], duration[{}mins], nextStep[{}]", key, buffer.getStep(), String.format("%.2f",((double)duration / (1000 * 60))), nextStep);
LeafAlloc temp = new LeafAlloc();
temp.setKey(key);
temp.setStep(nextStep);
leafAlloc = dao.updateMaxIdByCustomStepAndGetLeafAlloc(temp);
buffer.setUpdateTimestamp(System.currentTimeMillis());
buffer.setStep(nextStep);
buffer.setMinStep(leafAlloc.getStep());//leafAlloc的step为DB中的step
}
// must set value before set max
// 计算出来 设置step之前的值
long value = leafAlloc.getMaxId() - buffer.getStep();
//设置到segment的atomicInteger中
segment.getValue().set(value);
// 设置最大值 为现在的max_id
segment.setMax(leafAlloc.getMaxId());
// 设置step
segment.setStep(buffer.getStep());
sw.stop("updateSegmentFromDb", key + " " + segment);
}
这个方法很长,其实如果是buffer没有初始化过的话,就走
if (!buffer.isInitOk()) {
leafAlloc = dao.updateMaxIdAndGetLeafAlloc(key);
// 设置step
buffer.setStep(leafAlloc.getStep());
buffer.setMinStep(leafAlloc.getStep());//leafAlloc中的step为DB中的step
}
.....
// 计算出来 设置step之前的值
long value = leafAlloc.getMaxId() - buffer.getStep();
//设置到segment的atomicInteger中
segment.getValue().set(value);
// 设置最大值 为现在的max_id
segment.setMax(leafAlloc.getMaxId());
// 设置step
segment.setStep(buffer.getStep());
这一小段,如果是已经初始化过了,就会走下面那段带有自适应步长的那段代码,那段代码其实也很简单,就是根据上次更新数据库时间来自适应步长。
看下这个updateMaxIdAndGetLeafAlloc方法,对应sql就是这两条
UPDATE leaf_alloc SET max_id = max_id + step WHERE biz_tag = #{tag}
SELECT biz_tag, max_id, step FROM leaf_alloc WHERE biz_tag = #{tag}
获得biz_tag对应的数据之后,设置到segment中,max 就是max_id, AtomicLong对应的就是max_id-step
到这里SegmentBuffer 就初始化完事了。
接着就是获取生成id
// 获取id 从segmentBuffer中
return getIdFromSegmentBuffer(cache.get(key));
看看是怎样从SegmentBuffer获取id的
public Result getIdFromSegmentBuffer(final SegmentBuffer buffer) {
while (true) {
try {
buffer.rLock().lock();
// 获取segment
final Segment segment = buffer.getCurrent();
// 如果下个segment处于不可切换状态 && 这个segment剩余的 id 小于了 90% && 线程运行状态是false
if (!buffer.isNextReady() && (segment.getIdle() < 0.9 * segment.getStep()) && buffer.getThreadRunning().compareAndSet(false, true)) {
// 提交任务
service.execute(new Runnable() {
@Override
public void run() {
// 切换下一个segment
Segment next = buffer.getSegments()[buffer.nextPos()];
boolean updateOk = false;
// 这里就是初始化另一个segment
try {
updateSegmentFromDb(buffer.getKey(), next);
updateOk = true;
logger.info("update segment {} from db {}", buffer.getKey(), next);
} catch (Exception e) {
logger.warn(buffer.getKey() + " updateSegmentFromDb exception", e);
} finally {
if (updateOk) {
buffer.wLock().lock();
buffer.setNextReady(true);
buffer.getThreadRunning().set(false);
buffer.wLock().unlock();
} else {
buffer.getThreadRunning().set(false);
}
}
}
});
}
// 使用atomicInteger的自增长
long value = segment.getValue().getAndIncrement();
// 如果是小于的max_id的话,就可以直接返回了
if (value < segment.getMax()) {
return new Result(value, Status.SUCCESS);
}
} finally {
buffer.rLock().unlock();
}
// 等待 后台线程 更新下一个segment完事
waitAndSleep(buffer);
try {
// 写锁
buffer.wLock().lock();
final Segment segment = buffer.getCurrent();
long value = segment.getValue().getAndIncrement();
if (value < segment.getMax()) {
return new Result(value, Status.SUCCESS);
}
// 如果下一个segment准备妥了 ,切换pos。其实是切换segment
if (buffer.isNextReady()) {
buffer.switchPos();
buffer.setNextReady(false);
} else {
logger.error("Both two segments in {} are not ready!", buffer);
return new Result(EXCEPTION_ID_TWO_SEGMENTS_ARE_NULL, Status.EXCEPTION);
}
} finally {
buffer.wLock().unlock();
}
}
}
这里太长,就不一行一行介绍代码了,代码其实也很好理解,就是上来先加个读锁。拿到当前的Segment ,然后拿到atomicLong进行自增长,看看那个值是否比max小,如果小的话,直接返回就行了,如果大于的话,就获取写锁,进行Segment 切换,切换成另一个Segment 。
这里还有很重要的点就是,它发现
下个segment处于不可切换状态 && 这个segment剩余的 id 小于了 90% && 线程运行状态是false
条件满足的时候,往线程池中扔一个任务,提前对下一个Segment 进行获取。
这段切换segment的代码非常有意义。
// 如果下一个segment准备妥了 ,切换pos。其实是切换segment
if (buffer.isNextReady()) {
buffer.switchPos();
buffer.setNextReady(false);
} else {
logger.error("Both two segments in {} are not ready!", buffer);
return new Result(EXCEPTION_ID_TWO_SEGMENTS_ARE_NULL, Status.EXCEPTION);
}
其实就是将pos变成 另个segment上面的索引值
(currentPos + 1) % 2;
好了,到这里我们源码分析就完事了,代码很是巧妙,思路很清晰。
总结
本文主要介绍了基于mysql各种分布式id生成方案演进过程,然后引出美团leaf号段模式,最后深度解析leaf号段模式实现原理,双Segment
缓冲设计很是巧妙,leaf基于服务内存的增长,保证了高性能,基于mysql的行锁,可实现多leaf服务并发修改同一条数据场景下不会出现问题,支持集群部署,保证高并发,同时扩展由mysql转向服务本身,保证高扩展性,只能说巧妙,要说它的缺点,就是leaf服务宕机,会出现id不连续的情况,某段id丢失,集群部署获取id的时候,同一时刻会出现忽大忽小的情况,但是整体是呈现增长趋势的。


















 2412
2412

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











