







Spark学习笔记No.03(StandAlone HA与YARN模式)
1、StandAlone HA
Standalone集群存在Master故障(SPOF) 那么如何解决呢?
解决方案:
1.基于文件系统的单点恢复(Single-Node Recovery with Local File System)–只能用于开发或测试环境。2.基于zookeeper的Standby Masters(Standby Masters with ZooKeeper)–可以用于生产环境。
2.ZooKeeper提供了一个Leader Election机制,利用这个机制可以保证虽然集群存在多个Master,但是只有一个是Active的,其他的都是Standby。当Active的Master出现故障时,另外的一个Standby Master会被选举出来。由于集群的信息,包括Worker, Driver和Application的信息都已经持久化到文件系统,因此在切换的过程中只会影响新Job的提交,对于正在进行的Job没有任何的影响。加入ZooKeeper的集群整体架构如下图所示
1.1 zookeeper
在大型企业的开发中,服务的数量是十分庞大的。如果我们想要添加一个服务的话,那么就需要对文件进行重新覆盖,把整个容器重启。这样导致的结果是就是:波及影响太大,维护十分困难。
此时,便需要一个能够动态注册服务和获取服务信息的地方,来统一管理服务,这个地方便称为称为服务配置中心。而zookeeper不仅实现了对cusumer和provider的灵活管理,平滑过渡功能,而且还内置了负载均衡、主动通知等功能,使我们能够几乎实时的感应到服务的状态。能够很好的帮我们解决分布式相关的问题,至今仍是市面上主流的分布式服务注册中心技术之一。
分布式进程是分布在多个服务器上的, 状态之间的同步需要协调,比如谁是master,谁是worker.谁成了master后要通知worker等, 这些需要中心化协调器Zookeeper来进行状态统一协调
(base) [smith@hadoop103 bin]$ ./zkServer.sh start
1.2 StandAlone HA
杀死进程(jps Master前的数据为61471)
kill -9 61471
1.3 StandAlone HA的原理
基于Zookeeper做状态的维护, 开启多个Master进程, 一个作为活跃,其它的作为备份,当活跃进程宕机,备份Master进行接管
2、Spark on Yarn
Spark on Yarn无需部署Spark,只要找到一个服务器,充当Spark的客户端。
2.1本质
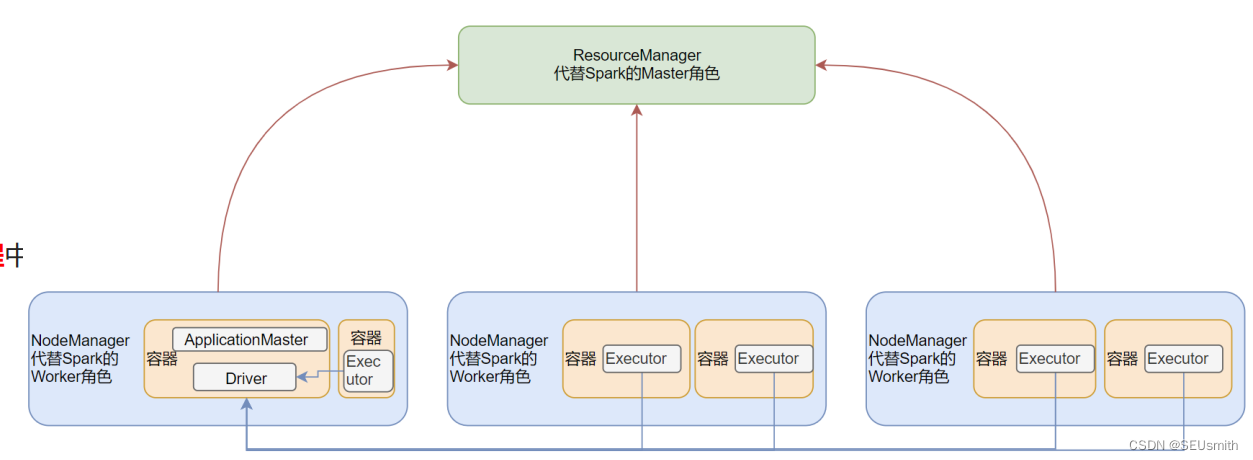
Maste角色由YARN的ResourceManager担任
Worker角色由YARN的NodeManager担任
Driver角色运行在YARN容器里,或者提交任务的客户端进程
真正干活的Executor运行在YARN提供的容器里
2.2 运用测试
(base) [smith@hadoop103 spark]$ bin/pyspark --master yarn
2.3 两种部署模式
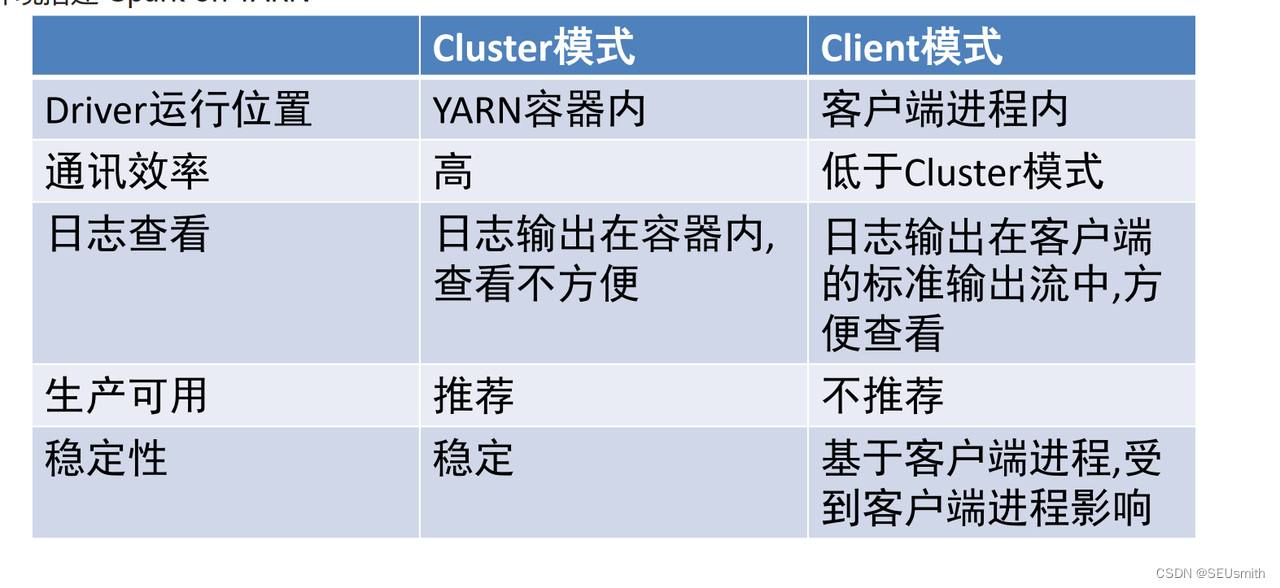
Cluster(集群)模式:Driver运行在YARN容器内部, 和ApplicationMaster在同一个容器内
Client模式:Driver运行在客户端进程中, 比如Driver运行在spark-submit程序的进程中,而ApplicationMaster在容器里
客户端模式
(base) [smith@hadoop102 spark]$ bin/spark-submit --master yarn --deploy-mode client --derver-memory 512m --executor-momory 256m --num-executors 3 --total-executor-cores 3
集群模式
(base) [smith@hadoop102 spark]$ bin/spark-submit --master yarn --deploy-mode cluster --derver-memory 512m --executor-momory 256m --num-executors 3 --total-executor-cores 3
两者最本质的区别是Driver程序运行在哪里
Client模式:学习测试时使用,生产不推荐(要用也可以,性能略低,稳定性略低)
1.Driver运行在Client上,和集群的通信成本高
2.Driver输出结果会在客户端显示
Cluster模式:生产环境中使用该模式
1.Driver程序在YARN集群中,和集群的通信成本低
2.Driver输出结果不能在客户端显示
3.该模式下Driver运行ApplicattionMaster这个节点上,由Yarn管理,如果出现问题, yarn会重启ApplicattionMaster(Driver)
2.3.1 Client模式
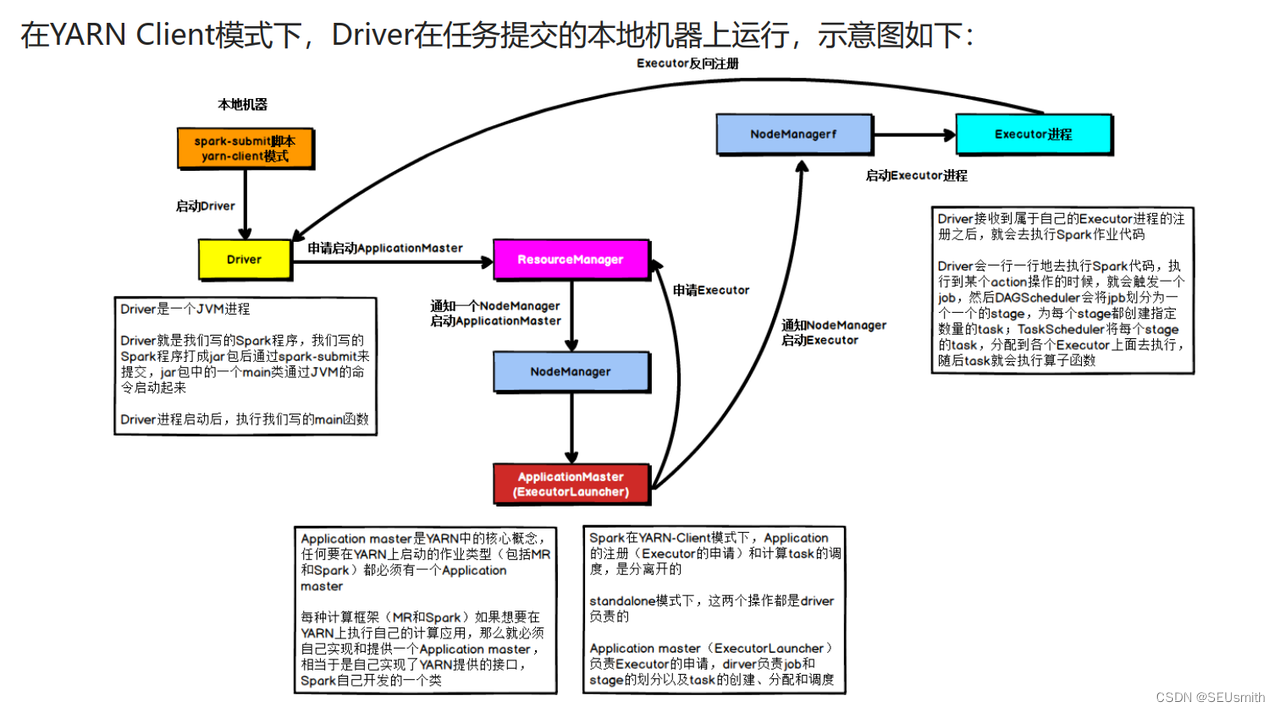
具体流程步骤如下:
1、Driver在任务提交的本地机器上运行, Driver启动后会和ResourceManager通讯申请启动ApplicationMaster ; 2、随后ResourceManager分配Container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster的功能相当于一个ExecutorLaucher,只负责向ResourceManager申请Executor内存;
3、 ResourceManager接到ApplicationMaster的资源申请后会分配Container,然后ApplicationMaster在资源分配指定的NodeManager上启动Executor进程;
4、Executor进程启动后会向Driver反向注册, Executor全部注册完成后Driver开始执行main函数;
5、之后执行到Action算子时,触发一个Job,并根据宽依赖开始划分Stage,每个Stage生成对应的TaskSet,之后将Task分发到各个Executor上执行。
2.3.2Cluster模式
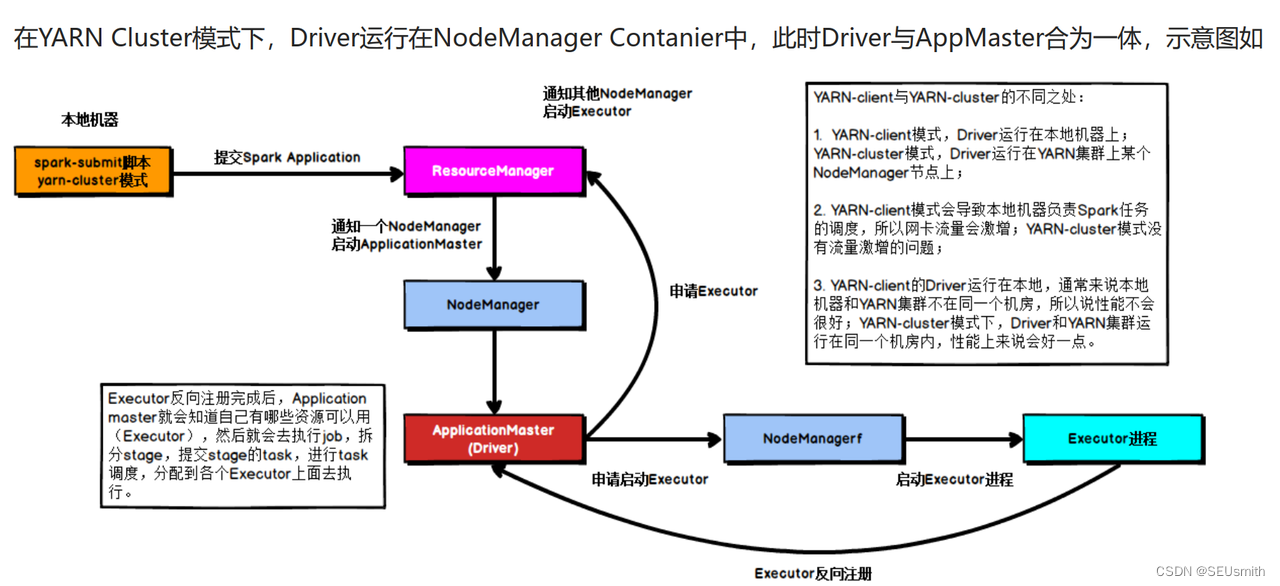
具体流程步骤如下:
1、任务提交后会和ResourceManager通讯申请启动ApplicationMaster;
2、随后ResourceManager分配Container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster就是Driver;
3、 Driver启动后向ResourceManager申请Executor内存, ResourceManager接到ApplicationMaster的资源申请后会分配Container,然后在合适的NodeManager上启动Executor进程;
4、Executor进程启动后会向Driver反向注册;
5、Executor全部注册完成后Driver开始执行main函数,之后执行到Action算子时,触发一个job,并根据宽依赖开始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor上执行;
2.4 总结回顾
Spark On Yarn的本质
Master由ResourceManager代替
Worker由NodeManager代替
Driver可以运行在容器内(Cluster模式)或客户端进程中(Client模式)
Executor全部运行在YARN提供的容器内
Why Spark On Yarn?
提高资源利用率,在已有YARN的场景下让Spark场景下让Spark收到YARN的调度,可以更好地管控资源,提供利用率并且方便管理。
3、PySpark
PySpark是一个python的类库,可以提供Spark的操作API
bin/pyspark是一个交互式的程序,可以提供交互式编程并执行Spark计算















 8191
8191











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









