






学习目标:
利用gensim包分析文档相似度
使用jieba进行中文分词
了解TF-IDF模型
环境:
Python 3.6.0 |Anaconda 4.3.1 (64-bit)
工具:
Geany
引言:
任务:从excel中读取文件,保存为列表,然后建立词库,给定一个keyword从词库中检索,计算相似度,当相似度达一定程度后,将内容打印出来。
并不是一片小白文,如需了解基础请参考博文:参考
步骤:
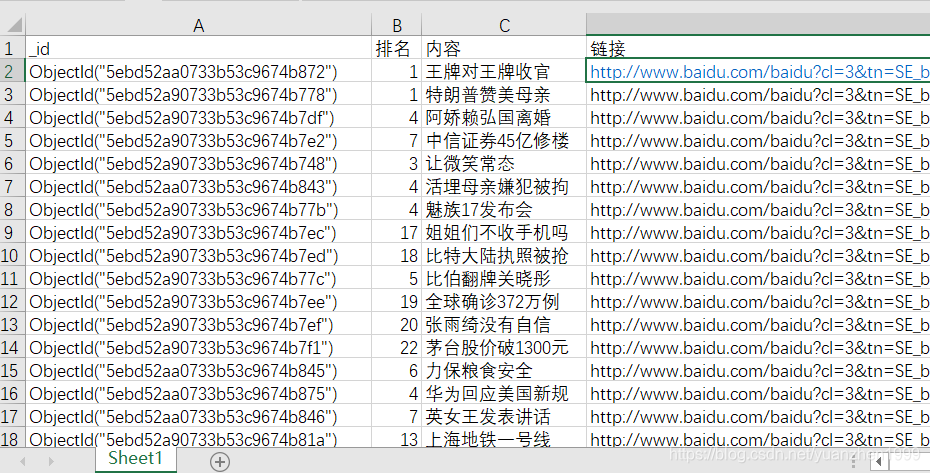
1.文档内容
2.引入相关库:
import xlrd
import jieba
from gensim import corpora,models,similarities
from jieba import lcut
from gensim.similarities import SparseMatrixSimilarity
from gensim.corpora import Dictionary
from gensim.models import TfidfModel
3.读取文件内容
def read_xlrd(excelFile): #读取文件内容
data = xlrd.open_workbook(excelFile,encoding_override='utf-8')
table = data.sheet_by_index(0)
return table.col_values(2)
4.分词并制作语料库
def read():
io_baidu = r"D:/python3-网络爬虫开发实战/baidu_hot.xlsx" #原始数据位置
baidu_data = read_xlrd(io_baidu) #从excel读取文件内容
del baidu_data[0] #删除列标题
#print(baidu_data)
keyword ='姚明' #检索词
#keyword = input()
doc_list = [lcut(word) for word in baidu_data] #分词
dictionary = Dictionary(doc_list) #生成词典
num_features = len(dictionary.token2id)
#print('词典(字典):', dictionary.token2id)
corpus = [dictionary.doc2bow(text) for text in doc_list] #生成词库
kw_vector = dictionary.doc2bow(jieba.lcut(keyword))#将检索词也分词并且生成二元组的向量
tfidf = TfidfModel(corpus) #使用TF-IDF模型对语料库建模
tf_texts = tfidf[corpus] #此处将【语料库】用作【被检索文本】
tf_kw = tfidf[kw_vector]
sparse_matrix = SparseMatrixSimilarity(tf_texts, num_features)#相似度计算
similarities = sparse_matrix.get_similarities(tf_kw)
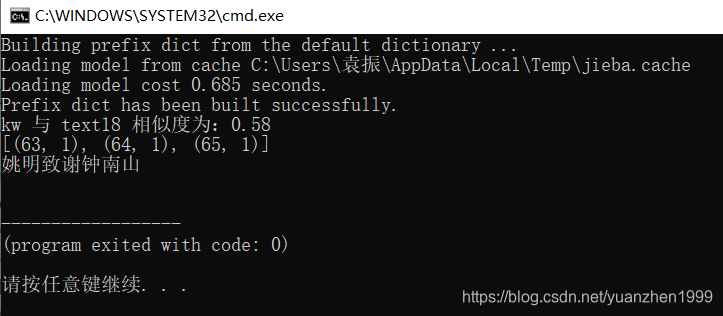
for e, s in enumerate(similarities, 0):
if s > 0.5:
print('kw 与 text%d 相似度为:%.2f' % (e, s))
print(corpus[e])
print(baidu_data[e])
#print('语料库:', corpus)
5.结果














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









