









昨天开了一天无聊的会,忘了写日志了,今天一并写了。
昨天开会的时候开小差,把所需要的模型进行了简单的实例化的,没什么实质性的进展。
今天上午继续看了前天那篇论文,根据那篇论文的算法,结合我们的模型,我也通过矩阵(二维数组)来列出了任务所需文件数量及大小在各数据中心上的对应关系。但是因为任务所需的文件是随机生成的。当文件数量过多时,采用随机生成之后任务与数据中心的关联度逐渐趋于平均,改为无差别,需要单独采用其他偏好算法(固定每个任务所需文件的最大值)。决定明天和老师商量一下,看一下实际的情况如何,逐渐改进。
下面是程序运行时的截图:默认四个数据中心。
当文件为10个,任务为5个时:
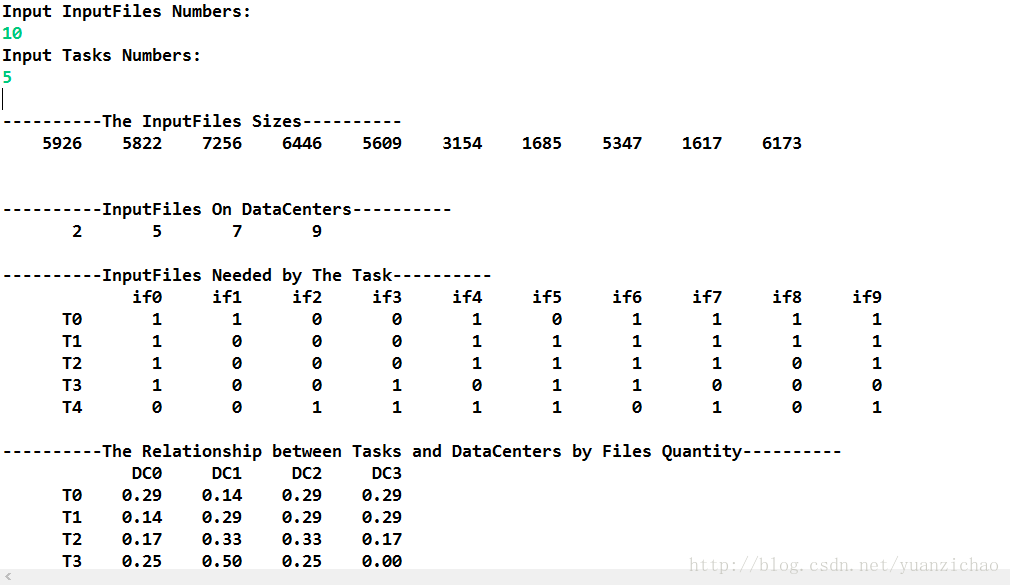

当文件为200,任务为5时:
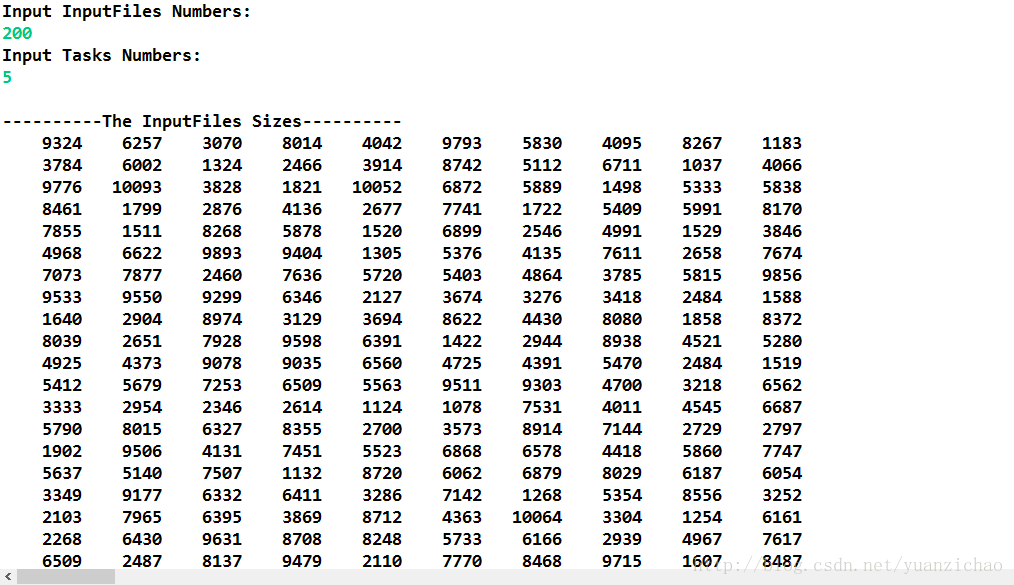
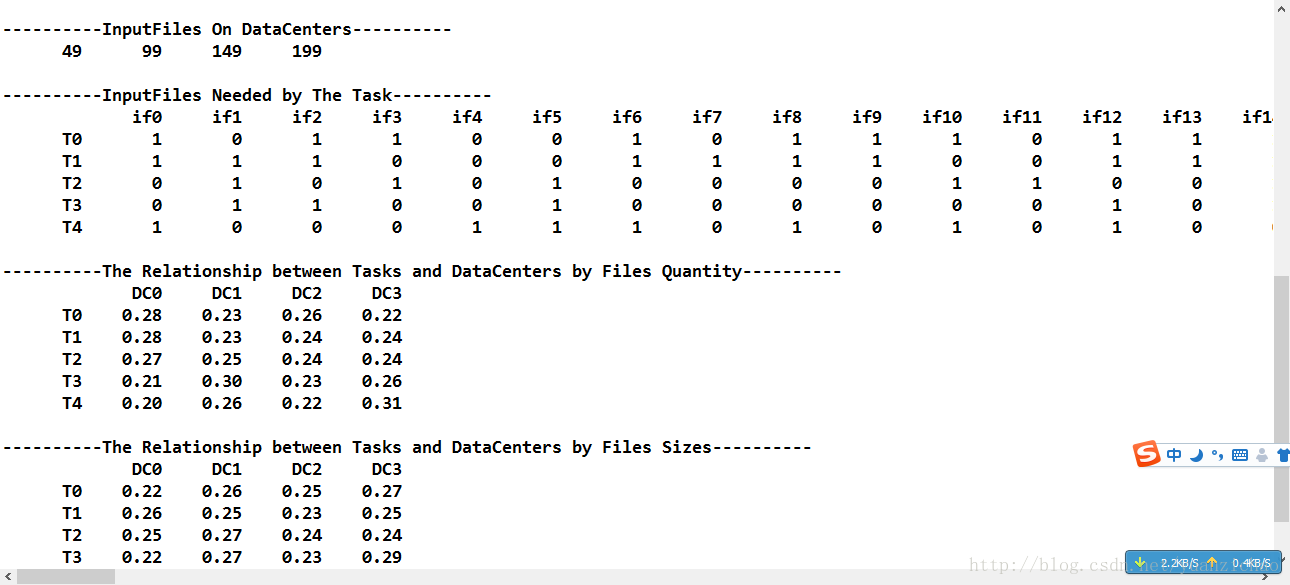















 245
245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









