










一、JSON简介
JSON (JavaScript Object Notation) 是一种轻量级的数据交换格式。它基于 ECMAScript 的一个子集,易于人阅读和编写
JSON用来存储和交换文本信息,比xml更小/更快/更易解析,易于读写,占用带宽小,网络传输速度快的特性,适用于数据量大,不要求保留原有类型的情况。。
二. JSON语法规则
名称必须用双引号(即:" ")来包括
值可以是双引号包括的字符串、数字、true、false、null、JavaScript数组,或子对象
数据在name/value中
数据见用逗号分隔
花括号保存对象
方括号保存数组
三、Python3 JSON 数据解析
Python 中可以使用 json 模块来对 JSON 数据进行编解码,它包含了两个函数:
json.dumps(): 将 Python 对象编码成 JSON 字符串
json.loads(): 将已编码的 JSON 字符串解码为 Python 对象
在json的编解码过程中,Python 的原始类型与 json 类型会相互转换,具体的转化对照如下:
1、Python 编码为 JSON 类型转换对应表:
Python | JSON |
dict | object |
list, tuple | array |
str, unicode | string |
int, long, float | number |
True | true |
False | false |
None | null |
2、JSON 解码为 Python 类型转换对应表:
JSON | Python |
object | dict |
array | list |
string | str |
number (int) | int |
number (real) | float |
true | True |
false | False |
null | None |
四、JSON中常用的方法
python在使用json这个模块前,首先要导入json库:import json.
方法 | 描述 |
json.dumps() | 将 Python 对象编码成 JSON 字符串 |
json.loads() | 将已编码的 JSON 字符串解码为 Python 对象 |
json.dump() | 将Python内置类型序列化为json对象后写入文件 |
json.load() | 读取文件中json形式的字符串元素转化为Python类型 |
注意:不带s的是序列化到文件或者从文件反序列化,带s的都是内存操作不涉及持久化。
五、json.dumps 与 json.loads 实例
1、json.dumps()
# coding=utf-8
import json
data = {'name': 'Tom', 'age': 3}
# 将Python对象编码成json字符串
print(json.dumps(data))
执行结果:
{"name": "Tom", "age": 3}注: 在这里我们可以看到,原先的单引号已经变成双引号了
2、json.loads()
# coding=utf-8
import json
data = {'name':'Tom','age':3}
# 将Python对象编码成json字符串
# print(json.dumps(data))
# 将json字符串解码成Python对象
a = json.dumps(data)
print(json.loads(a))执行结果:
{'name': 'Tom', 'age': 3}元组和列表的例子:
# coding=utf-8
import json
data = (1,2,3,4)
data_json = [1,2,3,4]
#将Python对象编码成json字符串
print(json.dumps(data))
print(json.dumps(data_json))
#将Python对象编码成json字符串
a = json.dumps(data)
b = json.dumps(data_json)
#将json字符串编码成Python对象
print(json.loads(a))
print(json.loads(b))执行结果:
[1, 2, 3, 4]
[1, 2, 3, 4]
[1, 2, 3, 4]
[1, 2, 3, 4]可以看到,元组和列表解析出来的均是数组。
在编码过程中,Python中的list和tuple都被转化成json的数组,
而解码后,json的数组最终被转化成Python的list的,无论是原来是list还是tuple。
3、json.dump()
将Python内置类型序列化为json对象后写入文件:
# coding=utf-8
import json
data = {
'nanbei':'haha',
'a':[1,2,3,4],
'b':(1,2,3)
}
with open('json_test.txt','w+') as f:
json.dump(data,f)json_test.txt文件
{"name": "haha", "a": [1, 2, 3, 4], "b": [1, 2, 3]}4、json.load()
读取文件中json形式的字符串元素转化为Python类型:
# coding=utf-8
import json
with open('json_test.txt','r+') as f:
print(json.load(f))执行结果:
{'name': 'haha', 'a': [1, 2, 3, 4], 'b': [1, 2, 3]}5、dump和dumps:
# coding=utf-8
import json
# dumps可以格式化所有的基本数据类型为字符串
data1 = json.dumps([]) # 列表
print(data1, type(data1))
data2 = json.dumps(2) # 数字
print(data2, type(data2))
data3 = json.dumps('3') # 字符串
print(data3, type(data3))
dict = {"name": "Tom", "age": 3} # 字典
data4 = json.dumps(dict)
print(data4, type(data4))
with open("test.json", "w", encoding='utf-8') as f:
# indent 超级好用,格式化保存字典,默认为None,小于0为零个空格
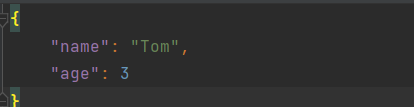
f.write(json.dumps(dict, indent=4))
json.dump(dict, f, indent=4) # 传入文件描述符,和dumps一样的结果得到的输出结果如下:格式化所有的数据类型为str类型:
[] <class 'str'>
2 <class 'str'>
"3" <class 'str'>
{"name": "Tom", "age": 3} <class 'str'>test.json中的内容:
6、load和loads
# coding=utf-8
import json
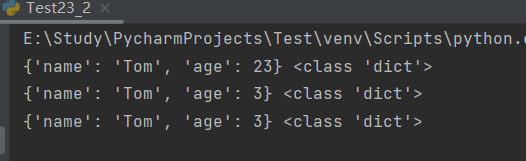
dict = '{"name": "Tom", "age": 23}' # 将字符串还原为dict
data1 = json.loads(dict)
print(data1, type(data1))
with open("test.json", "r", encoding='utf-8') as f:
data2 = json.loads(f.read()) # load的传入参数为字符串类型
print(data2, type(data2))
f.seek(0) # 将文件游标移动到文件开头位置
data3 = json.load(f)
print(data3, type(data3))运行结果:
7、参数详解
dumps(obj,skipkeys=False, ensure_ascii=True, check_circular=True,
allow_nan=True, cls=None, indent=None, separators=None,
default=None, sort_keys=False, **kw):函数作用: 将Python对象转变成JSON对象,便于序列化内存/文件中。
参数:
skipkeys: 如果为True的话,则只能是字典对象,否则会TypeError错误, 默认False
ensure_ascii: 确定是否为ASCII编码
check_circular: 循环类型检查,如果为True的话
allow_nan: 确定是否为允许的值
indent: 会以美观的方式来打印,呈现,实现缩进
separators: 对象分隔符,默认为,
encoding: 编码方式,默认为utf-8
sort_keys: 如果是字典对象,选择True的话,会按照键的ASCII码来排序
对于dump来说,只是多了一个fp参数:
简单说就是dump需要一个类似文件指针的参数(并不是真正的指针,可以称之为文件对象),与文件操作相结合,即先将Python文件对象转化为json字符串再保存在文件中。
dump(obj, fp, skipkeys=False, ensure_ascii=True, check_circular=True,
allow_nan=True, cls=None, indent=None, separators=None,
default=None, sort_keys=False, **kw)
Serialize ``obj`` as a JSON formatted stream to ``fp`` (a``.write()``-supporting file-like object).
六、JSON反序列化为对象
JSON反序列化为类对象或者类的实例,使用的是loads()方法中的object_hook参数:
# coding=utf-8
import json
# 定义猫类
class Cat(object):
def __init__(self, name, age):
self.name = name
self.age = age
# 实例化一个对象
cat = Cat('Tom', 3)
# 定义JSON转换Python实例的函数
def jsonToClass(cat):
return Cat(cat['name'], cat['age'])
# 定义一个json字符串(字典)
json_str = '{"name": "baimao", "age": 5}'
cat = json.loads(json_str, object_hook=jsonToClass)
print(cat)
print(cat.name)
print(cat.age)
七、总结
json.dumps 将 Python 对象编码成 JSON 字符串
json.loads 将已编码的 JSON 字符串解码为 Python 对象
json.dump和json.load,需要传入文件描述符,加上文件操作。
json内部的格式要注意,一个好的格式能够方便读取,可以用indent格式化。
















 842
842











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











