






塈百日而求新,念三番未发,其一
集合
概念:对象的容器,定义了对多个对象进行操作的常用方法。可实现数组的功能。
和数组的区别:
- 数组长度固定,集合长度不固定
- 数组可以存储基本类型和引用类型,集合只能存储引用类型(集合想存储基本类型,需要进行"装箱"操作)
- 位置:java.util.*; 需导入
Collection体系

Collection父接口
特点:代表一组任意类型的对象,无序、无下标、不重复。
方法
- boolean add(Object obj) 添加
- boolean addAll(Collection c) 将一个集合中的所有对象添加到此集合中
- void clear()
- boolean contains(Object o) 检查此对象中是否包含o对象
- boolean equals(Object o)
- boolean isEmpty()
- boolean remove(Object o) 在此集合中移除o对象
- int size() 返回此集合中的元素个数
- Object[] toArray() 将此集合转换成数组
Collection使用
存储基本类型信息
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
public class CollectionDemo01 {
public static void main(String[] args) {
//创建集合 不能实例化接口,所以要用ArrayList
Collection collection = new ArrayList();
//①添加元素
collection.add("西瓜");
collection.add("榴莲");
collection.add("樱桃");
System.out.println("元素个数"+collection.size());
System.out.println(collection);
//②删除元素
collection.remove("榴莲"); //collection.clear(); 全部清除
System.out.println("删除之后元素的个数:"+collection.size());
//③遍历元素 重点
//第一种遍历方式,使用增强for 因为for循环需要下标,而增强for不需要下标
System.out.println("------使用增强for------");
for (Object o : collection) {
System.out.println(o);
}
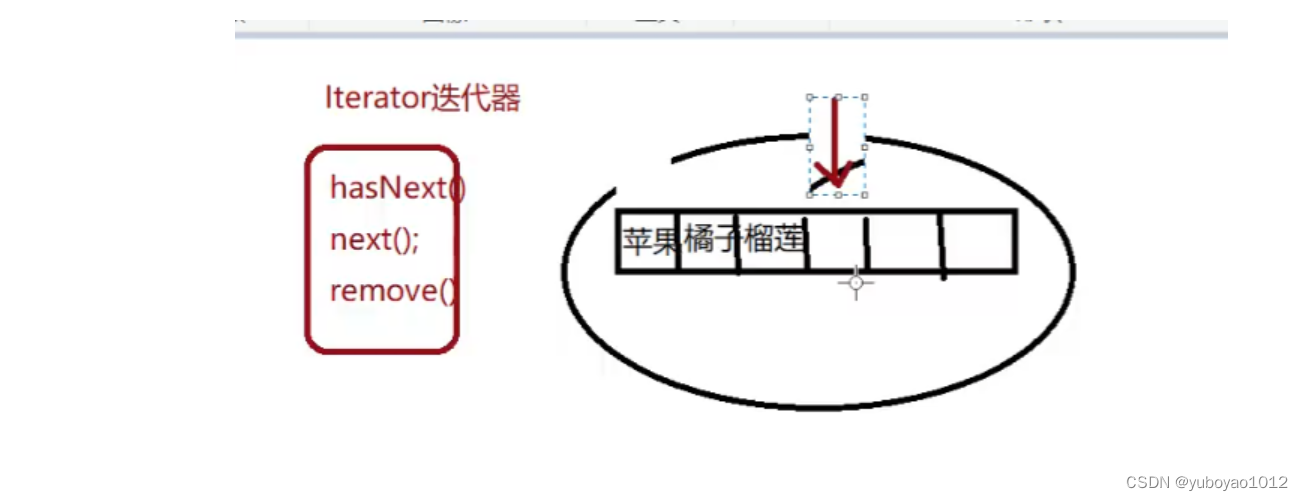
//第二种遍历方式,使用迭代器(迭代器是专门用来遍历集合的方式) 可以在JDK 11 中具体查看
//hasNext(); 有没有下一个元素
//next(); 获取下一个元素
//remove(); 删除当前元素
System.out.println("------使用迭代器Iterator------");
Iterator it = collection.iterator();
while(it.hasNext()){
String s = (String)it.next(); //已知是String类型,就顺便进行一下强制转换
System.out.println(s);
//在迭代过程中不能使用 collection.remove();方法,不能并发修改(正用着呢,不能修改)
it.remove(); //要想删除就用这个方法
}
System.out.println("迭代结束之后元素的个数为:"+collection.size());
//④判断
System.out.println(collection.contains("西瓜"));
System.out.println(collection.isEmpty());
}
}
结果:
元素个数3
[西瓜, 榴莲, 樱桃]
删除之后元素的个数:2
------使用增强for------
西瓜
樱桃
------使用迭代器Iterator------
西瓜
樱桃
迭代结束之后元素的个数为:0
false
true
Iterator的执行过程
存储类信息
先新建一个学生类
public class Student {
//学生类
private String name;
private int age;
//添加无参构造器 Alt+Ins→Constructor→Select None
public Student() {
}
//添加有参构造器 Alt+Ins→Constructor→选定两个参数
public Student(String name, int age) {
this.name = name;
this.age = age;
}
//添加 Getter and Setter
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
//为了打印好看,重写一下方法
//Alt+Ins→toString();
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
然后进行collection操作
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
public class CollectionDemo01 {
//存储学生信息
public static void main(String[] args) {
//新建collection对象
Collection collection = new ArrayList();
//①添加数据
Student s1 = new Student("张三",20);
Student s2 = new Student("张无忌",18);
Student s3 = new Student("王二",22);
collection.add(s1);
collection.add(s2);
collection.add(s3);
//因为实例化的是ArrayList,所以可以添加重复的元素
collection.add(s3);
System.out.println(collection.size());
//因为在Student类中重写了toString方法,所以打印结果比较直观
System.out.println(collection.toString());
//②删除
collection.remove(s3);
System.out.println(collection.size());
collection.remove(new Student("王二",22));//new出来的对象不在集合内,只是该对象的属性和本想删除的集合内的对象相同,但是无法删除
System.out.println(collection.size());
//collection.clear();
//System.out.println(collection.size());//集合和3个学生类的对象是同级的地位,将其添加到集合中是将3个地址添加到集合中,clear也只是清空集合中的三个地址,但是堆中的三个对象是没有消失的
//③遍历
System.out.println("------使用增强for------");
for (Object o : collection) {
Student s = (Student) o;
System.out.println(s);
}
System.out.println("------使用迭代器Iterator------");
Iterator it = collection.iterator();
while (it.hasNext()){
Student s = (Student) it.next();
System.out.println(s);
}
//④判断
System.out.println(collection.contains(s1));
System.out.println(collection.contains(new Student("张三",20)));
//⑤判断是否为空
System.out.println(collection.isEmpty());
}
}
结果:
4
[Student{name='张三', age=20}, Student{name='张无忌', age=18}, Student{name='王二', age=22}, Student{name='王二', age=22}]
3
3
------使用增强for------
Student{name='张三', age=20}
Student{name='张无忌', age=18}
Student{name='王二', age=22}
------使用迭代器Iterator------
Student{name='张三', age=20}
Student{name='张无忌', age=18}
Student{name='王二', age=22}
true
false
false
List子接口
特点:有序(添加顺序=遍历顺序),有下标,元素可以重复
方法
- void add(int index,Object o) //指定位置插入对象
- boolean addAll(int index,Collection c)
- Object get(int index)
- List sublist(int fromIndex,int toIndex) //返回子集合
List接口的使用
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.ListIterator;
public class Demo01 {
public static void main(String[] args) {
//创建集合对象
List list = new ArrayList<>();
//①添加元素
list.add("苹果");
list.add("小米");
list.add(0,"华为");
System.out.println(list.size());
System.out.println(list);
//②删除元素
//list.remove("苹果");
list.remove(0);
System.out.println("删除之后的长度为:"+list.size());
System.out.println(list);
//③遍历
//使用for 因为有下标
System.out.println("------①使用for循环遍历------");
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i)); //返回的是Object类型,如果想转成实际类型需要进行强制转换
}
System.out.println("------②使用增强for遍历------");
for (Object o : list) {
System.out.println(o);
}
System.out.println("------③使用迭代器遍历------");
Iterator iterator = list.iterator();
while(iterator.hasNext()){
Object m = iterator.next();
System.out.println(m);
}
//listIterator的不同:可以向前或者向后遍历,可以添加、删除、修改元素
System.out.println("------④使用列表迭代器从前往后遍历------");
ListIterator lit = list.listIterator();
while(lit.hasNext()){
System.out.println(lit.nextIndex()+":"+lit.next());
}
System.out.println("------⑤使用列表迭代器从后往前遍历------");
while (lit.hasPrevious()){
System.out.println(lit.previousIndex()+":"+lit.previous());
}
//④判断
System.out.println(list.contains("苹果"));
System.out.println(list.isEmpty());
//⑤获取位置
System.out.println(list.indexOf("华为"));
}
}
结果:
3
[华为, 苹果, 小米]
删除之后的长度为:2
[苹果, 小米]
------①使用for循环遍历------
苹果
小米
------②使用增强for遍历------
苹果
小米
------③使用迭代器遍历------
苹果
小米
------④使用列表迭代器从前往后遍历------
0:苹果
1:小米
------⑤使用列表迭代器从后往前遍历------
1:小米
0:苹果
true
false
-1
import java.util.ArrayList;
import java.util.List;
import java.util.ListIterator;
public class Demo04 {
public static void main(String[] args) {
//创建一个集合
List list = new ArrayList();
//①添加数值元素(自动装箱,因为集合不能保存基本类型数据,所以给了数值元素20之后就会被包装成包装类)
list.add(20);
list.add(30);
list.add(40);
list.add(50);
list.add(60);
System.out.println("元素个数为:"+list.size());
System.out.println(list);
//②删除
list.remove((Object)20); //默认是根据下标删除,所以不能直接写数字 除了这样之外还可以:list.remove(new Integer(20));
System.out.println("删除元素后集合的长度:"+list.size());
//③subList 返回子集合
List sublist = list.subList(1,3); //前包后不包
System.out.println(sublist);
}
}
结果:
元素个数为:5
[20, 30, 40, 50, 60]
删除元素后集合的长度:4
[40, 50]
List也可以添加类元素,和collection一样,就不重复记录了。
List实现类
- ArrayList 【重点】
- 在里面维护了一个数组结构,并且由于数组连续存储的特点,使得查询快、增删慢
- 效率快,不安全
- Vector
- 也采用了数组结构,查询快、增删慢
- 但是运行效率慢、线程安全
- LinkedList
- 采用链表结构实现,增删快,查询慢
ArrayList的使用
import java.util.ArrayList;
import java.util.Iterator;
import java.util.ListIterator;
public class Demo05 {
public static void main(String[] args) {
//创建集合
ArrayList arrayList = new ArrayList();
//①添加类元素
Student s1 = new Student("刘德华",20);
Student s2 = new Student("郭富城",22);
Student s3 = new Student("梁朝伟",18);
arrayList.add(s1);
arrayList.add(s2);
arrayList.add(s3);
System.out.println("元素个数为:"+arrayList.size());
System.out.println(arrayList);
//②删除元素
arrayList.remove(s1);
System.out.println("删除元素之后,个数为:"+arrayList.size());
//③遍历元素 重点
System.out.println("------①使用迭代器遍历------");
Iterator it = arrayList.iterator();
while (it.hasNext()){
Student s = (Student)it.next(); //将Object类型强制转换成Student类型
System.out.println(s);
}
System.out.println("------②使用列表迭代器从前往后遍历------");
ListIterator lit = arrayList.listIterator();
while (lit.hasNext()){
Student s = (Student)lit.next();
System.out.println(s);
}
System.out.println("------③使用列表迭代器从后往前遍历------");
while (lit.hasPrevious()){
Student s = (Student)lit.previous();
System.out.println(s);
}
//④判断 和删除一样,修改了equals()方法之后"new"格式也可以成功运行
System.out.println(arrayList.contains(s1));
System.out.println(arrayList.contains(new Student("郭富城",22)));
//⑤查找
System.out.println(arrayList.indexOf(s2));
System.out.println(arrayList.indexOf(new Student("梁朝伟",18)));
}
}
结果:
元素个数为:3
[Student{name='刘德华', age=20}, Student{name='郭富城', age=22}, Student{name='梁朝伟', age=18}]
删除元素之后,个数为:2
------①使用迭代器遍历------
Student{name='郭富城', age=22}
Student{name='梁朝伟', age=18}
------②使用列表迭代器从前往后遍历------
Student{name='郭富城', age=22}
Student{name='梁朝伟', age=18}
------③使用列表迭代器从后往前遍历------
Student{name='梁朝伟', age=18}
Student{name='郭富城', age=22}
false
true
0
1
小问题
如果将删除操作更改成:
arrayList.remove(new Student("刘德华",20));
(即不是同一个对象),是否还能成功删除指定元素呢?
需要使用equals()方法,首先在Student类中重写equals()方法:
//equals+Enter
@Override
public boolean equals(Object o) {
//①判断是否是同一个对象
if (this == o) return true;
//②判断是否为空
if(o == null){
return false;
}
//③判断o是否是Student类型,如果不是就返回false;如果是,就进行强制转换。
if (!(o instanceof Student)) return false;
Student student = (Student) o;
//④比较属性 和视频中的写法不同
//视频中的写法: if(this.name.equals(s.getName())&&this.age == s.getAge()){retuen true;}
return getAge() == student.getAge() && Objects.equals(getName(), student.getName());
}
然后回到集合类中来:
arrayList.remove(new Student("刘德华",20));
结果:
删除元素之后,个数为:2
就可以成功删除元素。
原理就是重写equals()方法之后,比较的东西从是否是同一个对象变成了对象的属性(name,age)是否相同。
ArrayList源代码解析
- 默认容量为10(10是向集合添加元素之后的默认容量,如果没有向集合中添加任何元素时,容量就是0)
DEFAULT_CAPACITY = 10;
- 存放元素的数组
Object[] elementData;
- 实际元素个数
int size;
- 添加元素add

点击进入ensureCapacityInternal();方法
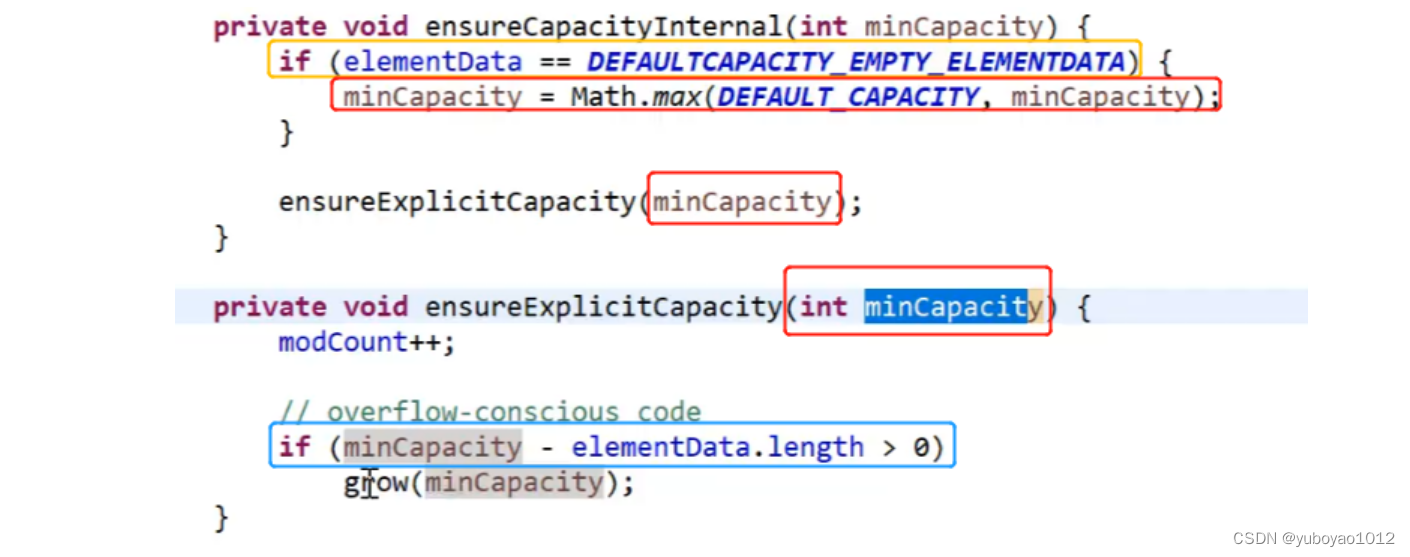
如上图所示:
黄:创建数组的时候将后者赋予给前者了,所以相等
红:在前者10和后者0中选取最大值,将其赋值给minCapacity并将其带入到后面当中
蓝:10-0>0→点击进入grow();方法
如下图所示:
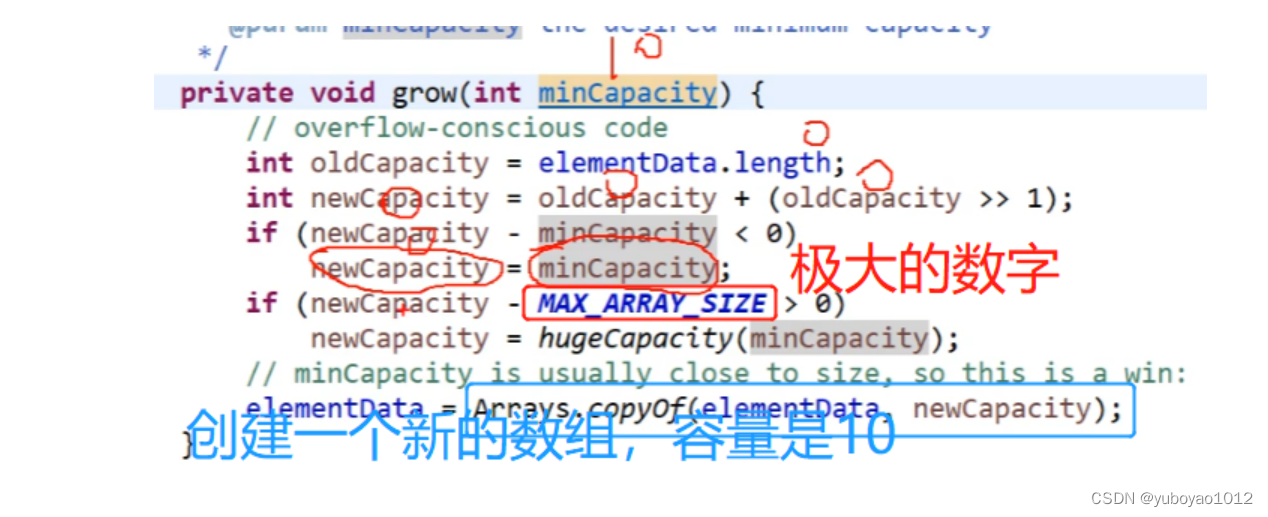
所以添加任意一个元素之后,容量就扩容为10。
再想,如果添加第11个元素之后会怎样执行?如下图所示:
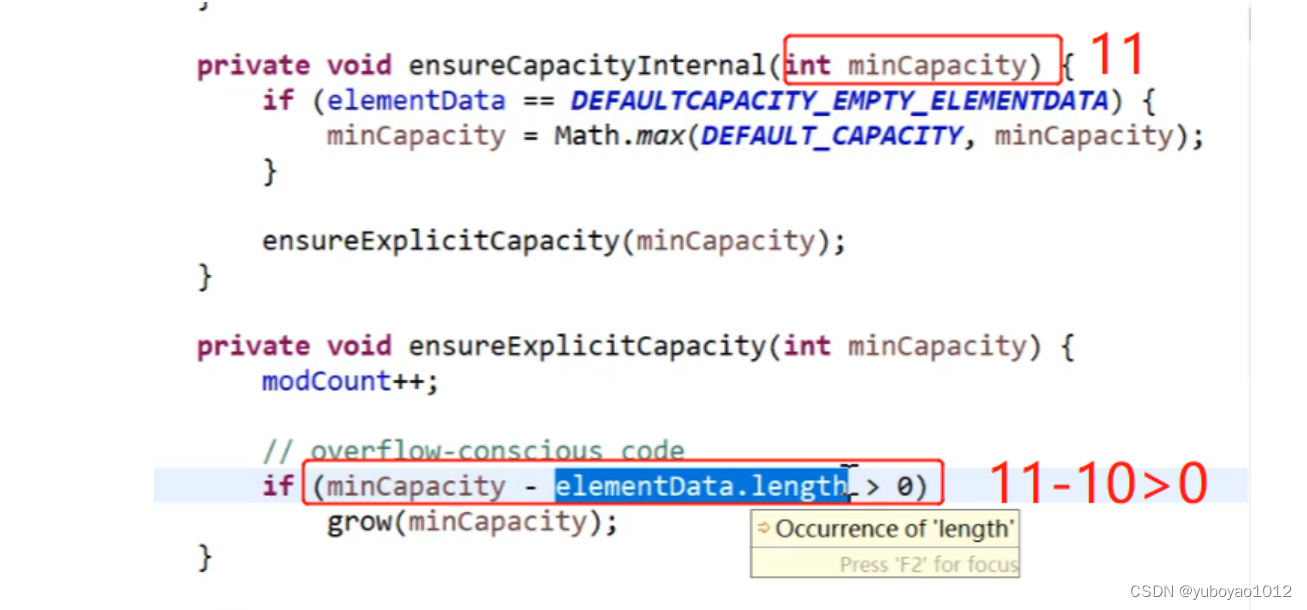
(11-10)满足>0的条件,执行grow。如果不满足就不执行grow,就直接放入数组了。
然后进入gorw();方法:
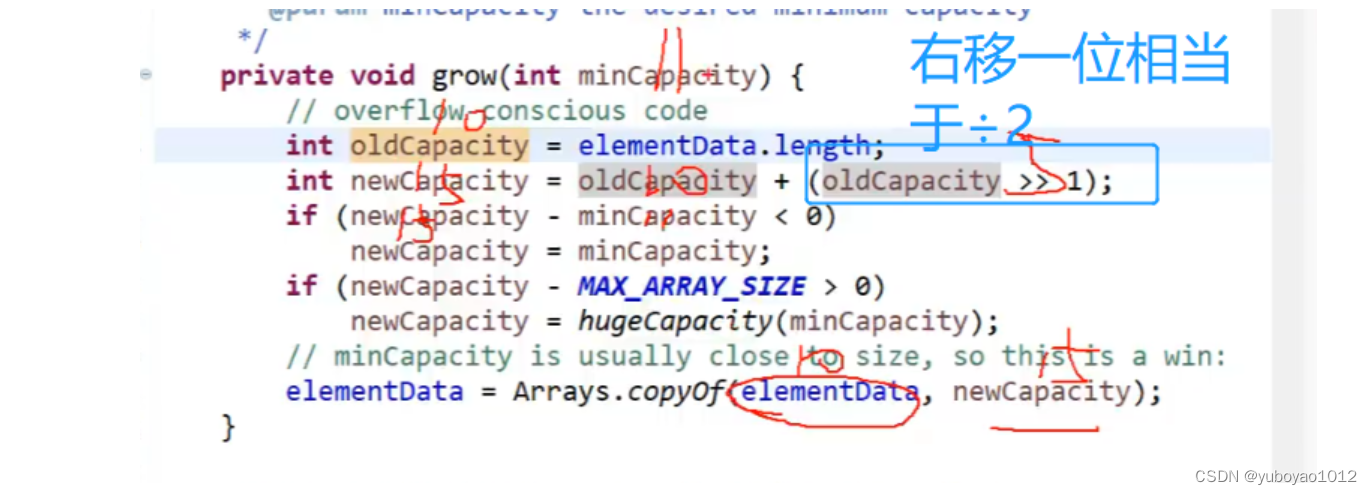
所以当输入第11个元素时,capacity扩容为15。
也就是说,当容量不够时每次都扩容为原来的1.5倍。
Vector的使用
- 数组结构,查询快、增删慢
- JDK1.0版本,运行慢、线程安全
演示Vector集合的使用:
package com.qf.chapter12_2;
import java.util.Enumeration;
import java.util.Vector;
public class Demo01 {
public static void main(String[] args) {
//创建集合
Vector vector = new Vector();
//①添加元素
vector.add("草莓");
vector.add("芒果");
vector.add("西瓜");
System.out.println("元素个数:"+vector.size());
//②删除
//vector.remove("西瓜");
//vector.clear();
//③遍历
//因为有脚标,所以for、增强for、迭代器都可以,下面介绍特有的遍历方法:
//使用枚举器
Enumeration en = vector.elements();
while(en.hasMoreElements()){
String o = (String)en.nextElement();//Object o = en.nextElement();
System.out.println(o);
}
//④判断
System.out.println(vector.contains("西瓜"));
System.out.println(vector.isEmpty());
//⑤Vector其它的方法
//firstElenment、lastElement、elementAt;
}
}
结果:
元素个数:3
草莓
芒果
西瓜
true
false
LinkedList的使用
- 链表结构实现,增删快、查询慢
package com.qf.chapter12_2;
import java.util.Iterator;
import java.util.LinkedList;
import java.util.ListIterator;
public class Demo02 {
public static void main(String[] args) {
//创建集合
LinkedList linkedList = new LinkedList();
//①添加元素
Student2 s1 = new Student2("张三",20);
Student2 s2 = new Student2("张无忌",18);
Student2 s3 = new Student2("王二",22);
linkedList.add(s1);
linkedList.add(s2);
linkedList.add(s3);
linkedList.add(s3);
System.out.println("元素个数:"+linkedList.size());
System.out.println(linkedList);
//②删除
//linkedList.remove(new Student2("刘德华",20)); //需要在Student2中重写equals();方法就可以成功删除
//System.out.println("删除后:"+linkedList.size());
//inkedList.clear();
//③遍历
//for遍历
System.out.println("------①使用for遍历------");
for (int i = 0; i < linkedList.size(); i++) {
System.out.println(linkedList.get(i));
}
//增强for
System.out.println("------②使用增强for遍历------");
for (Object o : linkedList) {
Student2 s = (Student2) o;
System.out.println(s);
}
//③使用迭代器
System.out.println("------③使用迭代器遍历------");
Iterator it = linkedList.iterator();
while (it.hasNext()){
Student2 s = (Student2) it.next();
}
//④使用listiterator遍历
ListIterator lit = linkedList.listIterator();
while (lit.hasNext()) {
Student2 s = (Student2) lit.next();
System.out.println(s);
}
//⑤判断
System.out.println(linkedList.contains(s1));
System.out.println(linkedList.isEmpty());
//⑥获取
System.out.println(linkedList.indexOf(s1));
}
}
结果:
元素个数:4
[Student{name='张三', age=20}, Student{name='张无忌', age=18}, Student{name='王二', age=22}, Student{name='王二', age=22}]
------①使用for遍历------
Student{name='张三', age=20}
Student{name='张无忌', age=18}
Student{name='王二', age=22}
Student{name='王二', age=22}
------②使用增强for遍历------
Student{name='张三', age=20}
Student{name='张无忌', age=18}
Student{name='王二', age=22}
Student{name='王二', age=22}
------③使用迭代器遍历------
Student{name='张三', age=20}
Student{name='张无忌', age=18}
Student{name='王二', age=22}
Student{name='王二', age=22}
LinkedList源码分析
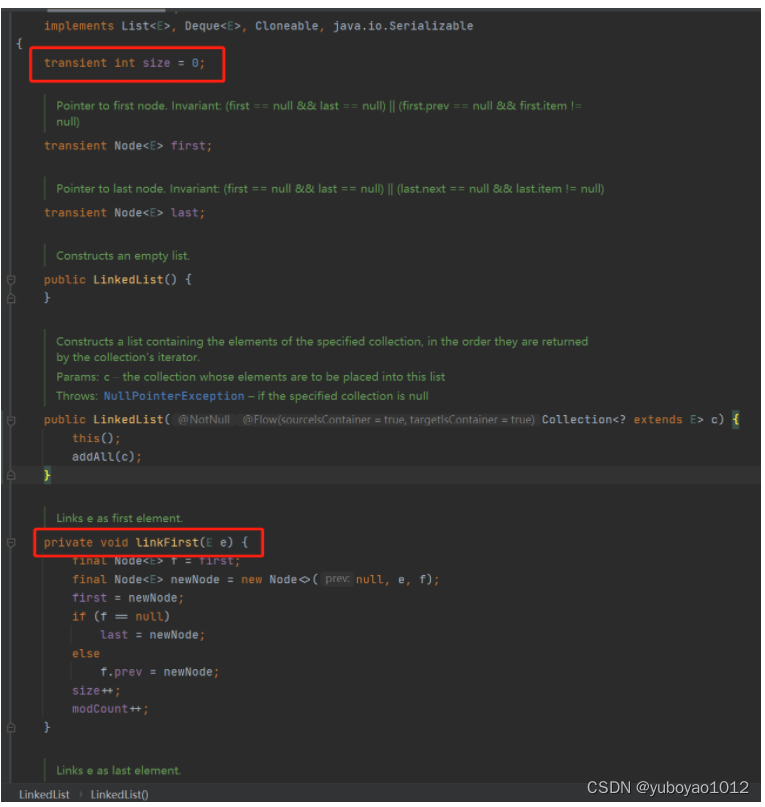
查看LinkedList源码会发现初始大小size=0,以及头结点和尾结点first和last,如下图所示:
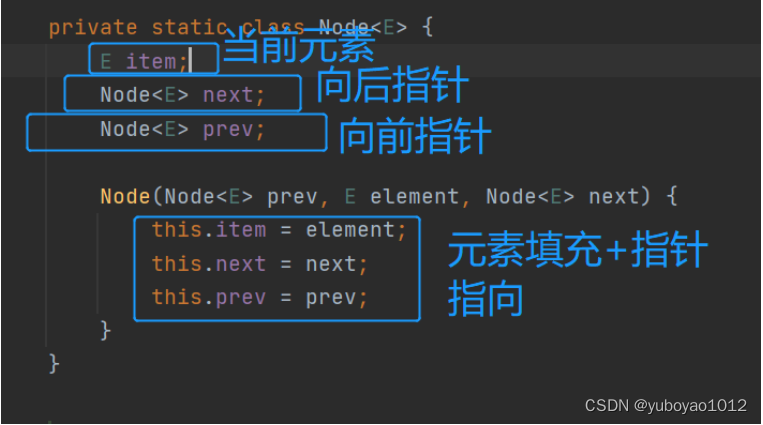
节点结构:
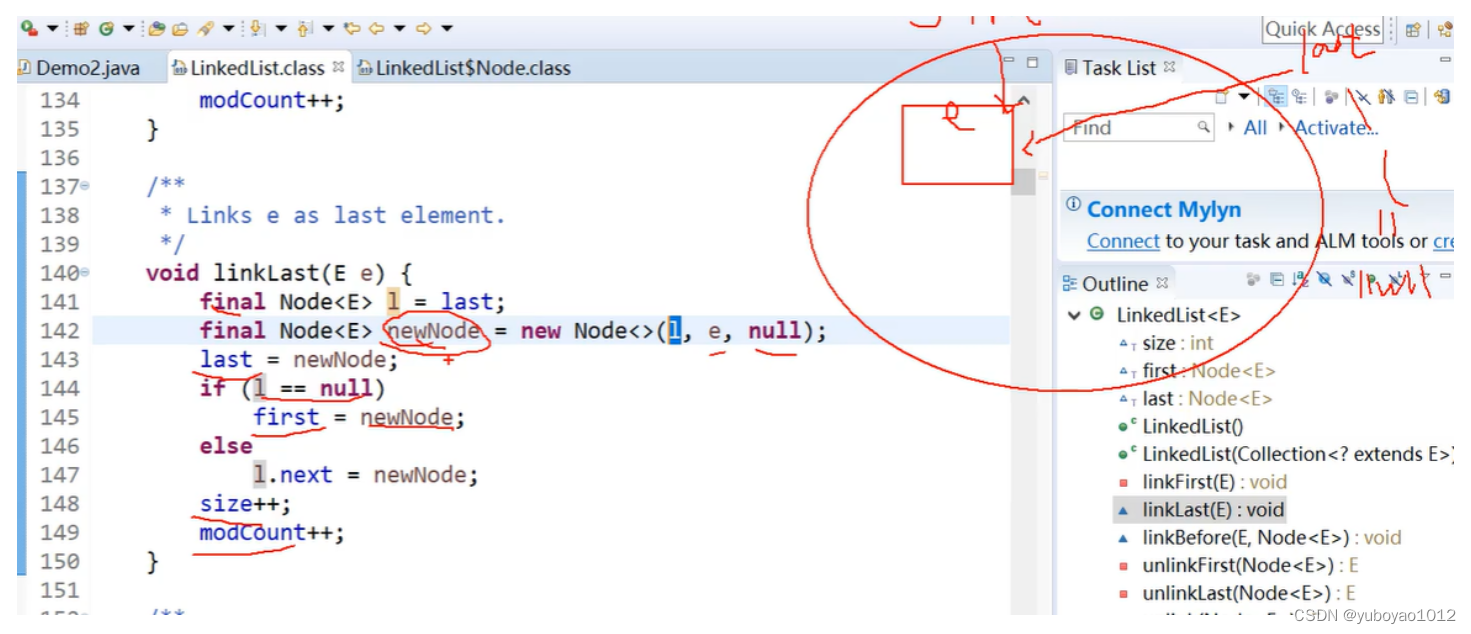
添加元素的过程:
ArrayList和linkedList区别
实现结构不同:一个连续存储空间;一个靠指针索引
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MFJSCCao-1661860251234)(C:\Users\86156\AppData\Roaming\Typora\typora-user-images\image-20220516110404825.png)]](https://img-blog.csdnimg.cn/f9eb88c8fa10480482d2138fce05a03e.png)
泛型概述
- 本质:参数化类型(和方法不同,传递的不是数据,是数据类型)
- 常用形式:
- 泛型类
- 泛型接口
- 泛型方法
- 语法:<大写字母,…> 大写字母为类型占位符,表示一种引用类型
- 好处:
- 提高代码的重用性
- 防止类型转换异常,提高代码安全性
泛型类
创建Generic类
package com.qf.chapter12_2;
import javax.swing.*;
public class MyGeneric <T,E,k>{
//语法: 类名<T,E,K>
//使用这个泛型T可以:
//①创建变量: 但是不可以实例化:T t1 = new T(); 因为T的类型不确定,如果是私有类型就会报错
T t;
E e;
//②作为方法的参数
public void show(T t){
System.out.println(t);
}
//③使用泛型作为方法的返回值
public E getE(){
return e;
}
}
测试类:
package com.qf.chapter12_2;
public class TestGeneric {
public static void main(String[] args) {
//使用泛型类创建对象 要给引用类型
MyGeneric<String,String,String> myGeneric = new MyGeneric<String,String,String>();
myGeneric.t = "hello";
myGeneric.e = "beach";
myGeneric.show("大家好,加油");
String string = myGeneric.getE();
System.out.println(string);
MyGeneric<Integer,Integer,Integer> myGeneric1 = new MyGeneric<Integer,Integer,Integer>();
myGeneric1.t = 100;
myGeneric1.e = 200;
myGeneric1.show(200);
Integer integer = myGeneric1.getE();
System.out.println(integer);
}
}
结果:
大家好,加油
beach
200
200
注意:
- 泛型只能使用引用类型
- 不同泛型类型对象之间不能相互赋值(Integer类型不能赋值给String类型)
泛型接口
先创建一个接口类:
-
如果已经确定了泛型接口的类型,先写接口和其实现类:
-

然后在测试类中进行尝试和输出:
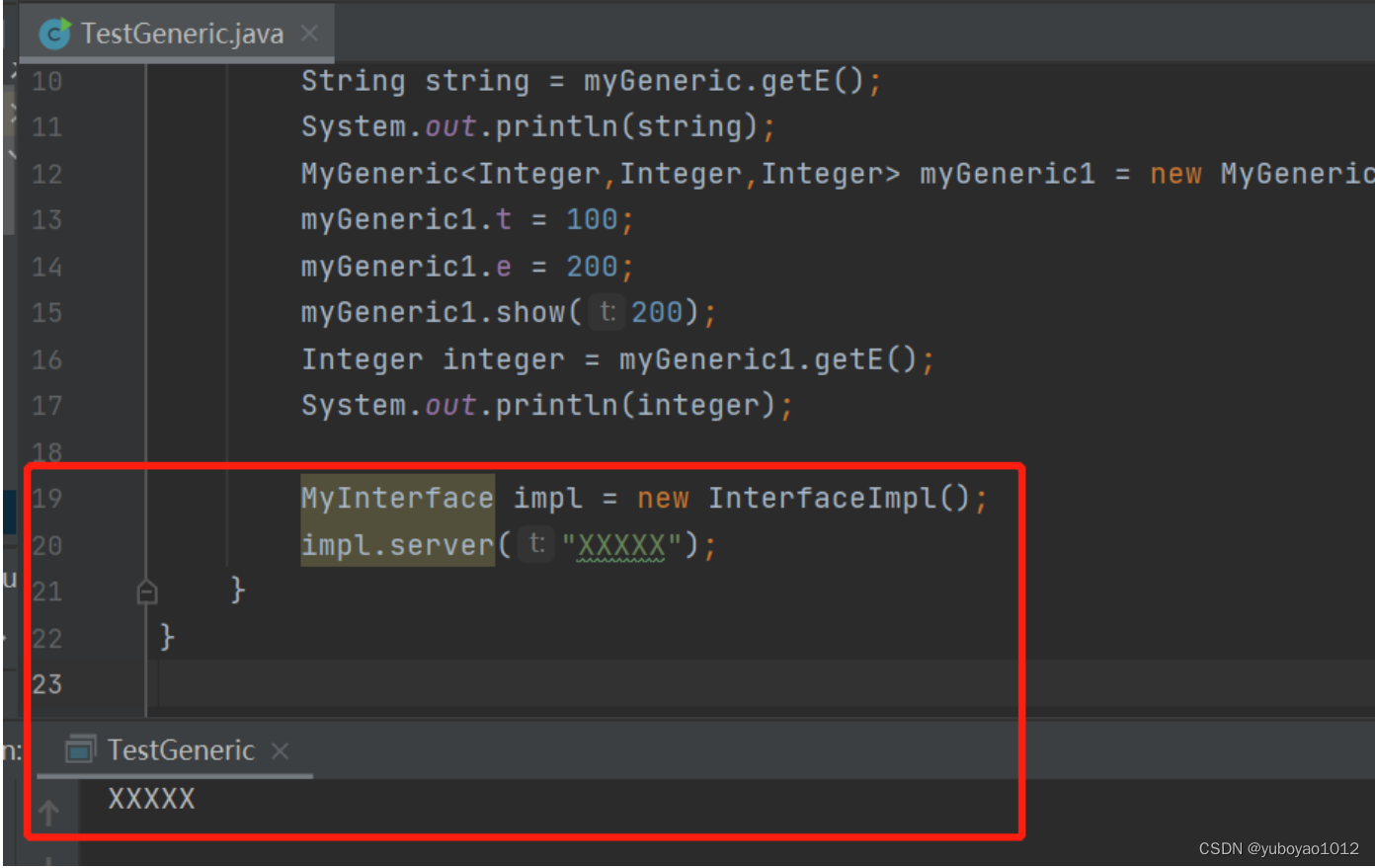
-
如果不确定泛型接口实现的引用类型:
-

然后在实现类里实现:
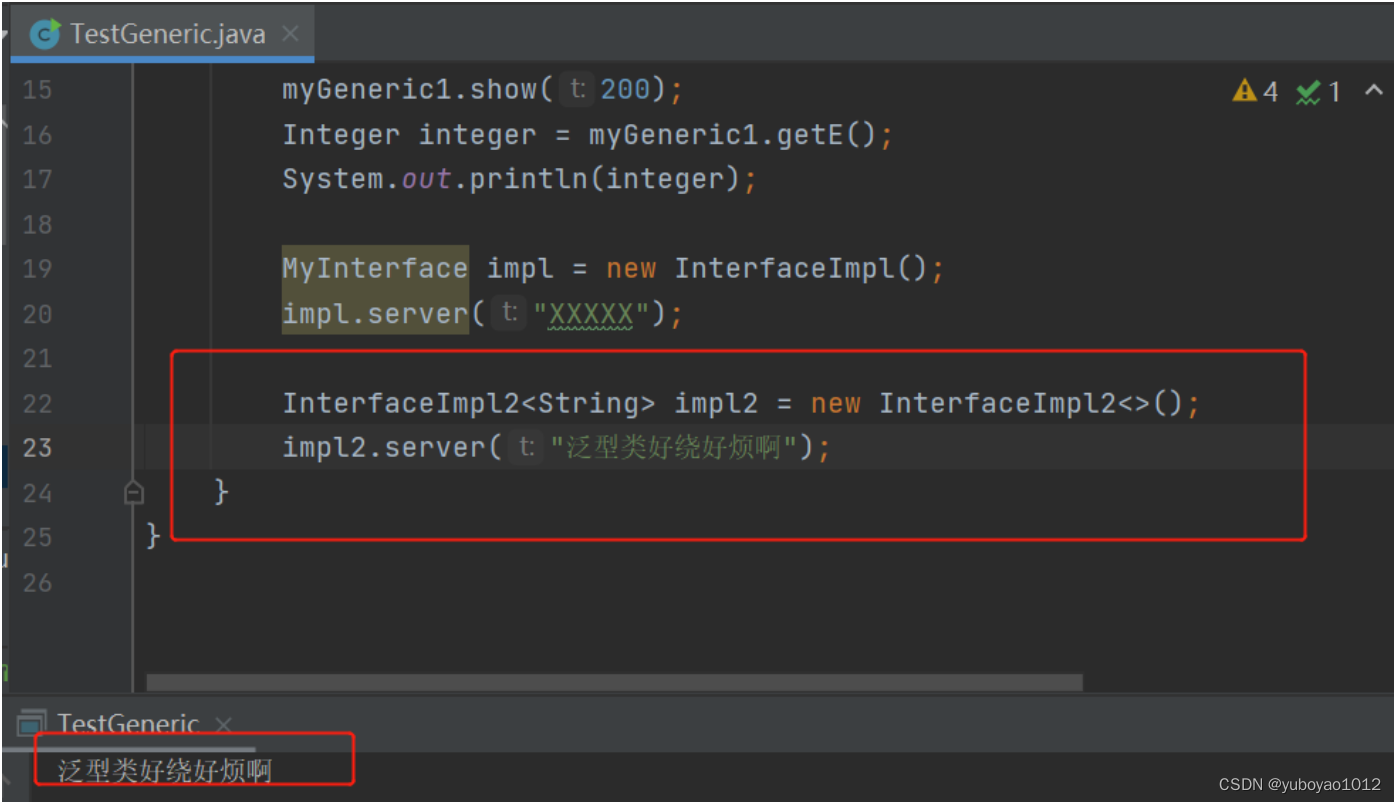
泛型方法
先写泛型方法类
package com.qf.chapter12_2;
//语法:<T>返回值类型
public class MyGenericMethod {
public <T> void show(T t){
T t2;
System.out.println("泛型方法");
}
//在其他的方法里面不能使用T
public void haha(){ }
}
然后在测试类中调用
//调用泛型方法时,根据传入的数据决定类型,不需要自己指定
MyGenericMethod myGenericMethod = new MyGenericMethod();
myGenericMethod.show("中国加油");
myGenericMethod.show(200);
myGenericMethod.show(3.1415927);
泛型好处
- 提高代码的重用性
- 防止类型转换异常,提高代码安全性
泛型集合
LinkedList linkedList = new LinkedList();
上述代码本来是泛型类,没有限制类型,默认是Object类,可以是可以,但是所有添加的元素都变成Object类,在遍历获取的时候,所有的类又都要强转成原来的类,容易出现错误。所以Java中使用泛型集合来对此进行限制。
- 概念:参数化类型、类型安全的集合,强制集合元素的类型必须一致
- 特点:
- 编译时可以检查,而非运行时抛出异常
- 访问时不必类型转换(拆箱)。
- 不同泛型之间引用不能相互赋值,泛型不存在多态
如果不判断一下之前是什么类型,在类型转换的时候会出现错误。
出错举例:
package com.qf.chapter12_2;
import java.util.ArrayList;
public class Demo03 {
public static void main(String[] args) {
ArrayList arrayList = new ArrayList();
arrayList.add("xxx");
arrayList.add("yyy");
arrayList.add(10);
arrayList.add(20);
for (Object o : arrayList) {
String str = (String)o;
System.out.println(str);
}
}
}
结果:
//错误原因:Integer不能转成String
Exception in thread "main" java.lang.ClassCastException: java.lang.Integer cannot be cast to java.lang.String
at com.qf.chapter12_2.Demo03.main(Demo03.java:13)
改进:
package com.qf.chapter12_2;
import java.util.ArrayList;
import java.util.Iterator;
public class Demo03 {
public static void main(String[] args) {
ArrayList<String> arrayList = new ArrayList<String>();//泛型集合强制元素都为String,就避免了强制类型转换失败的错误
arrayList.add("xxx");
arrayList.add("yyy");
//arrayList.add(10); int类型就无法加入集合
//arrayList.add(20);
for (String s : arrayList) { //使用arrayList.for+Enter自动生成时,类型自动变为String
System.out.println(s);
}
ArrayList<Student2> arrayList1 = new ArrayList<Student2>(); //Student2是之前写好的一个类
Student2 s1 = new Student2("刘德华",20);
Student2 s2 = new Student2("郭富城",22);
Student2 s3 = new Student2("梁朝伟",18);
arrayList1.add(s1);
arrayList1.add(s2);
arrayList1.add(s3);
Iterator<Student2> it = arrayList1.iterator();
while(it.hasNext()){
Student2 s = it.next(); //使用泛型集合在这里就少一步强制转换
System.out.println(s);
}
}
}
结果:
xxx
yyy
Student{name='刘德华', age=20}
Student{name='郭富城', age=22}
Student{name='梁朝伟', age=18}
Set集合
set子接口
- 特点:无序/添加顺序和遍历顺序不一样,无下标,元素不可重复(和List正好相反)
- 方法:全部继承Collection中的方法
set接口的使用
Set实现类
- HashSet 【重点】
- 基于HashCode/哈希表实现元素不重复
- equals进行确认
- TreeSet
- 基于二叉树实现
- 基于排列顺序实现元素不重复
set接口使用过举例
package com.qf.chapter12_3;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
public class Demo01 {
public static void main(String[] args) {
//创建集合 创建一个Set的哈希表子集
Set<String> set = new HashSet<>();
//①添加数据
set.add("苹果");
set.add("华为");
set.add("小米");
set.add("华为"); //重复的不添加
System.out.println("数据个数:"+set.size()); //当小米在最前面的时候,打印结果相同→无序
System.out.println(set);
//②删除数据
set.remove("小米");
System.out.println(set);
//③遍历 【重点】
//使用增强for
System.out.println("------使用增强for进行遍历------");
for (String s : set) {
System.out.println(s);
}
//使用迭代器
System.out.println("------使用增迭代器进行遍历------");
Iterator<String> it = set.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
//④判断
System.out.println(set.contains("华为"));
System.out.println(set.isEmpty());
}
}
结果:
数据个数:3
[苹果, 华为, 小米]
[苹果, 华为]
------使用增强for进行遍历------
苹果
华为
------使用增迭代器进行遍历------
苹果
华为
true
false
HashSet使用 【重点】
- 基于HashCode计算元素存放的位置
- 当存入元素的哈希码相同时,会调用equals进行确认,如果结果为true,则拒绝后者存入
- 存储结构:哈希表(数组+链表+红黑树)
哈希表实现过程如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-awUrB1zO-1661860251240)(C:\Users\86156\AppData\Roaming\Typora\typora-user-images\image-20220516211201196.png)]](https://img-blog.csdnimg.cn/b504b46570aa4b2d83f534d28528223a.png)
HashSet使用案例1:
package com.qf.chapter12_3;
import java.util.HashSet;
import java.util.Iterator;
public class Demo02 {
public static void main(String[] args) {
//新建集合 存放字符串的哈希集合
HashSet<String> hashSet = new HashSet<>();
//①添加元素
hashSet.add("刘德华");
hashSet.add("梁朝伟");
hashSet.add("林志玲");
hashSet.add("周润发");
hashSet.add("刘德华");
System.out.println("元素个数为:"+hashSet.size());
System.out.println(hashSet); //因为set接口无序所以HashSet也是无序的
//②删除数据
hashSet.remove("刘德华");
System.out.println("删除之后的元素个数:"+hashSet.size());
System.out.println(hashSet);
//③遍历
//使用增强for
System.out.println("------使用增强for遍历------");
for (String s : hashSet) {
System.out.println(s);
}
//使用迭代器
System.out.println("------使用迭代器遍历------");
Iterator<String> it = hashSet.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
//④判断
System.out.println(hashSet.contains("郭富城"));
System.out.println(hashSet.isEmpty());
}
}
元素个数为:4
[林志玲, 梁朝伟, 周润发, 刘德华]
删除之后的元素个数:3
[林志玲, 梁朝伟, 周润发]
------使用增强for遍历------
林志玲
梁朝伟
周润发
------使用迭代器遍历------
林志玲
梁朝伟
周润发
false
false
HashSet使用案例2:
添加类数据,新建一个Person类
package com.qf.chapter12_3;
public class Person {
private String name;
private int age;
//添加无参构造
public Person() {
}
//添加带参构造
public Person(String name, int age) {
this.name = name;
this.age = age;
}
//添加getter and setter
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
//为了好打印数据,重写一个toString方法 Alt+Ins→toString()
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
然后进行集合操作:
package com.qf.chapter12_3;
import java.util.HashSet;
public class Demo03 {
public static void main(String[] args) {
//创建集合
HashSet<Person> persons = new HashSet<>();
//①添加数据
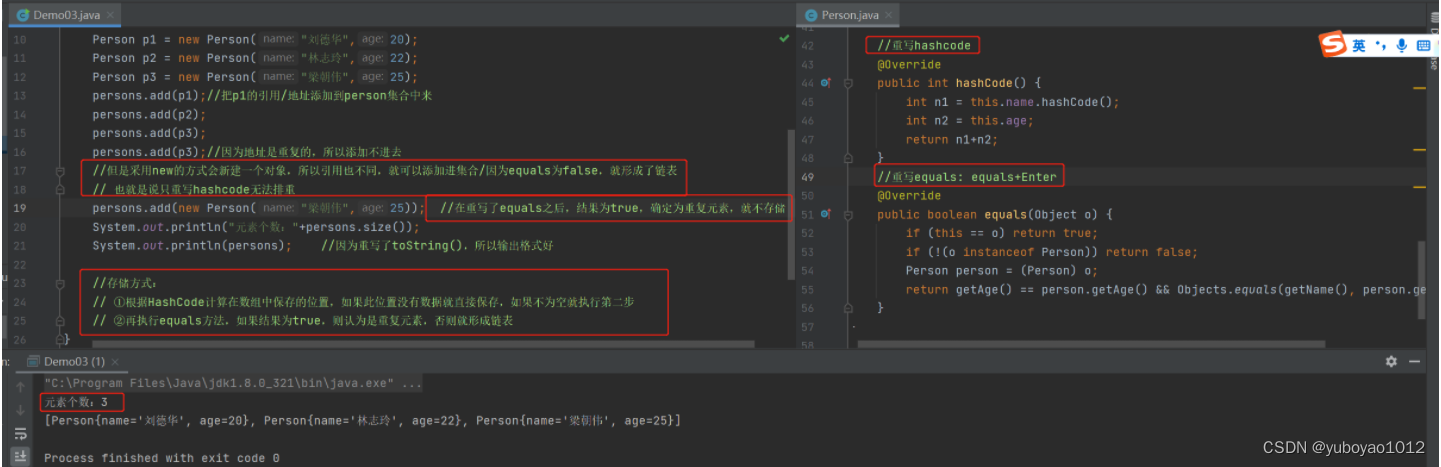
Person p1 = new Person("刘德华",20);
Person p2 = new Person("林志玲",22);
Person p3 = new Person("梁朝伟",25);
persons.add(p1);//把p1的引用/地址添加到person集合中来
persons.add(p2);
persons.add(p3);
persons.add(p3);//因为地址是重复的,所以添加不进去
//但是采用new的方式会新建一个对象,所以引用也不同,就可以添加进集合
persons.add(new Person("梁朝伟",25));
System.out.println("元素个数:"+persons.size());
System.out.println(persons); //因为重写了toString(),所以输出格式好
//②删除操作
persons.remove(p1);
//因为重写了hashcod和equals,所以下一行代码的删除方式也是可以的
//persons.remove(new Person("刘德华",20));
System.out.println("删除之后:"+persons.size());
//③遍历
//增强for
System.out.println("------使用增强for遍历------");
for (Person person : persons) {
System.out.println(person);
}
//迭代器
System.out.println("------使用迭代器遍历------");
Iterator<Person> it = persons.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
//④判断
System.out.println(persons.contains(p2));
//同理,因为重写了hashcod和equals,所以下一行代码的判断方式也是可以的
//System.out.println(persons.contains(new Person("林志玲",22)));
System.out.println(persons.isEmpty());
}
}
结果:
元素个数:4
[Person{name='刘德华', age=20}, Person{name='梁朝伟', age=25}, Person{name='梁朝伟', age=25}, Person{name='林志玲', age=22}]
删除之后:2
------使用增强for遍历------
Person{name='林志玲', age=22}
Person{name='梁朝伟', age=25}
------使用迭代器遍历------
Person{name='林志玲', age=22}
Person{name='梁朝伟', age=25}
true
false
HashSet存储方式/重复依据
生成hashCode和equals的快捷键方法
通过Alt+Ins选择"equals() and hashCode()"即可,如下图所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JGztRkx6-1661860251242)(C:\Users\86156\AppData\Roaming\Typora\typora-user-images\image-20220518202223927.png)]](https://img-blog.csdnimg.cn/222e1742e47a458f99997980fc2c2bac.png)
补充:
用上述方法自动生成的hashCode会用到“31”,如下图所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dBQlc2iR-1661860251243)(C:\Users\86156\AppData\Roaming\Typora\typora-user-images\image-20220518202719268.png)]](https://img-blog.csdnimg.cn/f6fcbb8c76ab46cc8d8a04f85e1a74a2.png)
因为
- 31是一个质数/素数,可以尽量减少散列冲突/让根据hashCode计算出来的元素所处位置尽量不一样
- 使用31可以提高执行效率(将乘法运算转换成位运算):31*i=(i<<5)-i 。
TreeSet概述
- 存储结构:红黑树/红黑树就是二叉查找树。所以元素不重复
- 基于排序顺序来实现的,所以元素不重复
- 实现了SortedSet接口,对集合元素自动排序
- 元素对象的类型必须实现Comparable接口,制定排序规则
- 通过CompareTo方法确定是否为重复元素
TreeSet的Comparable接口的使用
package com.qf.chapter12_3;
import java.util.Iterator;
import java.util.TreeSet;
public class Demo04 {
public static void main(String[] args) {
//创建集合
TreeSet<String> treeSet = new TreeSet<>();
//①添加元素
treeSet.add("xyz");
treeSet.add("abc");
treeSet.add("hello");
treeSet.add("xyz"); //红黑树无法添加重复元素
System.out.println("元素个数:"+treeSet.size());
System.out.println(treeSet);
//②删除元素
//treeSet.remove("xyz");
//System.out.println("删除之后的元素个数:"+treeSet.size());
//③遍历
//使用增强for
System.out.println("------使用增强for遍历------");
for (String s : treeSet) {
System.out.println(s);
}
//使用迭代器
System.out.println("------使用迭代器遍历------");
Iterator<String> it = treeSet.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
//④判断
System.out.println(treeSet.contains("abc"));
}
}
结果:
元素个数:3
[abc, hello, xyz]
------使用增强for遍历------
abc
hello
xyz
------使用迭代器遍历------
abc
hello
xyz
添加其余类元素,会出现下列问题:
出现了类型转换错误:Person类型不能转换成Comparable类型,为了将p1-p3添加到Treeset当中,要求:Person元素必须实现Comparable接口
于是打开Person类:
Comparable接口中只有一个方法,在Person类中进行重写:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DsOFJAGR-1661860251245)(C:\Users\86156\AppData\Roaming\Typora\typora-user-images\image-20220519110833156.png)]](https://img-blog.csdnimg.cn/5a83aa68e2bb42fb960cc8591610a9a7.png)
然后就可以进行添加和其他操作:
package com.qf.chapter12_3;
import java.util.TreeSet;
public class Demo05 {
public static void main(String[] args) {
//创建集合
TreeSet<Person> persons = new TreeSet<>();
//①添加元素
//**也就是说,实现Comparable接口之后,返回值是0就说明元素重复,不能添加。**
Person p1 = new Person("刘德华",20);
Person p2 = new Person("林志玲",22);
Person p3 = new Person("梁朝伟",25);
Person p4 = new Person("刘德华",30);
persons.add(p1);
persons.add(p2);
persons.add(p3);
persons.add(p4); //实现接口之后,先比较姓名然后比较年龄,年龄大的排在后面
System.out.println("元素个数:"+persons.size());
System.out.println(persons);
//②删除元素
persons.remove(p1);
System.out.println(persons.size());
//System.out.println(new Person("刘德华",20)); 也是可以删除的,因为Comparable接口现在比较的是姓名+年龄
//③遍历
//使用增强for
System.out.println("------使用增强for遍历------");
for (Person person : persons) {
System.out.println(person);
}
//使用迭代器
System.out.println("------使用迭代器遍历------");
Iterator<Person> it = persons.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
//④判断
System.out.println(persons.contains(p1));
// System.out.println(persons.contains(new Person("刘德华",20)); 同理,也是因为Comparable接口的原因,返回值是true
}
}
结果:
元素个数:4
[Person{name='刘德华', age=20}, Person{name='刘德华', age=30}, Person{name='林志玲', age=22}, Person{name='梁朝伟', age=25}]
3
------使用增强for遍历------
Person{name='刘德华', age=30}
Person{name='林志玲', age=22}
Person{name='梁朝伟', age=25}
------使用迭代器遍历------
Person{name='刘德华', age=30}
Person{name='林志玲', age=22}
Person{name='梁朝伟', age=25}
TreeSet的Comparator接口的使用
用来实现定制比较(比较器)
package com.qf.chapter12_3;
import java.util.Comparator;
import java.util.TreeSet;
public class Demo06 {
public static <p1, p3> void main(String[] args) {
//创建集合,并指定比较规则
//创建集合的时候把比较规则告诉他/制定比较规则,这样Person类中的元素就不必要实现Comparator这个接口了
TreeSet<Person> persons = new TreeSet<>(new Comparator<Person>() {//不能new接口,所以使用匿名内部类
//在Comparator接口中只需要实现一个方法就行了——compare
@Override
public int compare(Person o1, Person o2) {
int n1 = o1.getAge()-o2.getAge();
int n2 = o1.getName().compareTo(o2.getName());
return n1==0?n2:n1;
}
});
Person p1 = new Person("刘德华",20);
Person p2 = new Person("林志玲",22);
Person p3 = new Person("梁朝伟",25);
Person p4 = new Person("野原广志",25);
persons.add(p1);
persons.add(p2);
persons.add(p3);
persons.add(p4);
System.out.println(persons);
}
}
结果:
[Person{name='刘德华', age=20}, Person{name='林志玲', age=22}, Person{name='梁朝伟', age=25}, Person{name='野原广志', age=25}]
Tree案例:
package com.qf.chapter12_3;
import java.util.Comparator;
import java.util.TreeSet;
//使用TreeSet集合实现字符串按照长度进行排序 → 定制比较规则
public class Demo07 {
public static void main(String[] args) {
//创建集合,并指定比较规则
TreeSet<String> treeSet = new TreeSet<>(new Comparator<String>(){
@Override
public int compare(String o1, String o2) {
int n1 = o1.length()-o2.length();
int n2 = o1.compareTo(o2); //如果长度相同就按照之前的字符串比较规则来
return n1==0?n2:n1;
}
});
//添加数据
treeSet.add("helloworld");
treeSet.add("pingguo");
treeSet.add("lisi");
treeSet.add("zhangsan");
treeSet.add("beijing");
treeSet.add("cat");
treeSet.add("nanjing");
treeSet.add("xian");
System.out.println(treeSet);
}
}
结果:
[cat, lisi, xian, beijing, nanjing, pingguo, zhangsan, helloworld]
Map集合
Map集合概述
- 结构和特点:

- 方法
- V put(K key,V value) //将对象存入集合中,关联键值。key重复则覆盖原值
- Object get(Object key) //根据键获取对应的值
- Set //返回所有的key
- Collection values() //返回包含所有值的Collection集合
- Set<Map.Entry<K,V>> //键值匹配的Set集合
Map接口使用
Map遍历有两种方式:
- keySet:将Map中所有的键/key拿出来当做一个集合,然后使用增强for遍历,再通过get()方法用key获取值/value
- Map.Entry(效率高一点):把key和value封装成Entry/键值对,再用增强for遍历,用getkey()和getvalue()分别的到键和值
- 过程如图所示:

使用范例:
package com.qf.chapter12_4;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class Demo01 {
public static void main(String[] args) {
//创建Map集合
Map<String,String> map = new HashMap<>();
//①添加元素
map.put("cn","中国");
map.put("uk","英国");
map.put("usa","美国");
map.put("cn","zhongguo"); //键一样无法添加,但是替换了value值
System.out.println(map.size());
System.out.println(map);
//②删除元素
map.remove("cn");
System.out.println("删除之后:"+map.size());
System.out.println(map);
//③遍历
//使用keySet 返回值是所有key的Set集合
System.out.println("------使用keySet遍历------");
Set<String> keyset = map.keySet();
//再使用增强for遍历Set集合里面的key
for (String s : keyset) {
System.out.println(s+"-------"+map.get(s)); //用key获取value的值
}
System.out.println("------使用Map.Entry遍历------");
//使用entryset方法 也是一个Set集合,集合里面的类型是Map.Entry,这是在Map接口里面写的一个内部接口(内部接口要加前缀),代表一个个的键值对,类型就是<String,String>
Set<Map.Entry<String,String>> entries = map.entrySet();
//再使用增强for遍历
for (Map.Entry<String, String> entry : entries) {
System.out.println(entry.getKey()+"------"+entry.getValue());
}
//④判断
System.out.println(map.containsKey("cn"));
System.out.println(map.containsValue("泰国"));
}
}
结果:
3
{usa=美国, uk=英国, cn=zhongguo}
删除之后:2
{usa=美国, uk=英国}
------使用keySet遍历------
usa-------美国
uk-------英国
------使用Map.Entry遍历------
usa------美国
uk------英国
HashMap使用
-
存储结构:数组+链表+红黑树
-
线程不安全/单线程情况下使用
-
运行效率快
-
允许用null作为key或value
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5bKqrTyY-1661860251246)(C:\Users\86156\AppData\Roaming\Typora\typora-user-images\image-20220520130533733.png)]](https://img-blog.csdnimg.cn/56817b96422144c1af08766e6482566b.png)
加载因子:当存储数量到达总的存储量的75%时进行扩容
使用范例:
先创建Student类:
package com.qf.chapter12_4;
import java.util.Objects;
public class Student {
private String name;
private int stuNo;
//添加无参构造
public Student() {
}
//添加带参构造
public Student(String name, int stuNo) {
this.name = name;
this.stuNo = stuNo;
}
//添加getter and setter方法
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getStuNo() {
return stuNo;
}
public void setStuNo(int stuNo) {
this.stuNo = stuNo;
}
//为了好打印,重写toString方法
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", stuNo=" + stuNo +
'}';
}
//重写HashCode和equals
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Student)) return false;
Student student = (Student) o;
return getStuNo() == student.getStuNo() && Objects.equals(getName(), student.getName());
}
@Override
public int hashCode() {
return Objects.hash(getName(), getStuNo());
}
}
然后进行操作:
package com.qf.chapter12_4;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class Demo02 {
public static void main(String[] args) {
//创建集合
HashMap<Student,String> students = new HashMap<>();
//①添加元素
Student s1 = new Student("孙悟空",100);
Student s2 = new Student("猪八戒",101);
Student s3 = new Student("沙和尚",102);
students.put(s1,"北京");
students.put(s2,"上海");
students.put(s3,"杭州");
students.put(s3,"南京"); //上海/北京/杭州这和些value是可以重复的,虽然没有加进来,但是s3的value值变了
students.put(new Student("孙悟空",100),"杭州"); //除了value其余都一样,是可以加进来的,因为new的地址和之前的”沙和尚102“不同,所以可以存储在HashMap中
//去重需要在Student类中重写equals和HashCode
System.out.println(students.size());
System.out.println(students);
//②删除
students.remove(s1); //删除的是"s1"所指的元素,不是删除第一个输出的元素
System.out.println("删除之后:"+students.size());
//③遍历
//使用keySet
System.out.println("------使用keySet遍历------");
Set<Student> keyset = students.keySet();
for (Student student : keyset) {
System.out.println(student+"======"+students.get(student));
}
//如果把创建Set写进增强for里面,就会变成下面的写法
//for(Student key:students.keySet()){
// System.out.println(key+"======"+students.get(key));
//}
//使用Entry
//使用entry
System.out.println("------使用Map.Entry遍历------");
Set<HashMap.Entry<Student,String>> entries = students.entrySet();
for (Map.Entry<Student, String> entry : entries) {
System.out.println(entry.getKey()+"======"+entry.getValue());
}
//如果把创建Entry写进增强for里面,就会变成下面的写法
//for(Map.Entry<Student,String> entry:students.entrySet()){
// System.out.println(entry.getKey()+"======"+entry.getValue());
//}
//④判断
System.out.println(students.containsKey(s1));
System.out.println(students.containsKey(new Student("猪八戒",101))); //因为重写了equals()和hashcode(),判断依据发生了变化,所以是true
System.out.println(students.containsValue("杭州"));
System.out.println(students);
}
}
结果:
3
{Student{name='猪八戒', stuNo=101}=上海, Student{name='沙和尚', stuNo=102}=南京, Student{name='孙悟空', stuNo=100}=杭州}
删除之后:2
------使用keySet遍历------
Student{name='猪八戒', stuNo=101}======上海
Student{name='沙和尚', stuNo=102}======南京
------使用Map.Entry遍历------
Student{name='猪八戒', stuNo=101}======上海
Student{name='沙和尚', stuNo=102}======南京
false
true
false
{Student{name='猪八戒', stuNo=101}=上海, Student{name='沙和尚', stuNo=102}=南京}
HashMap源码分析
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OA2OJoCC-1661860251246)(C:\Users\86156\AppData\Roaming\Typora\typora-user-images\image-20220520144907456.png)]](https://img-blog.csdnimg.cn/be653984d4054eb1bef5cf9480b461dd.png)
假设键值/key相同,会进入equals()算法,如果为true就表明键值相同,不会存放,但会替换掉value值;如果为false就会接在相同键值的链表里。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Fwi7QqpE-1661860251247)(C:\Users\86156\AppData\Roaming\Typora\typora-user-images\image-20220520145148470.png)]](https://img-blog.csdnimg.cn/82051820da844ab2906f4ba06dc94137.png)
如上图所示,注意"8"的含义。
部分源码:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-06DocUDS-1661860251247)(C:\Users\86156\AppData\Roaming\Typora\typora-user-images\image-20220520145500390.png)]](https://img-blog.csdnimg.cn/705f4c9088d64d08ac79c6a4fb2470f5.png)
键值对Entery就是一个个节点,如下图所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8ifRTn0q-1661860251248)(C:\Users\86156\AppData\Roaming\Typora\typora-user-images\image-20220520145640274.png)]](https://img-blog.csdnimg.cn/e293f9d34aee442abf5afcf804bb430d.png)
总结:
- 当HashMap刚创建时,table是null,为了节省空间,当添加第一个元素时,table容量调整为16。
- 当元素个数大于阈值(16*0.75=12)时,会进行扩容,扩容后大小为原来的2倍。目的是为了调整元素的个数。
- jdl1.8当每个链表长度>8,并且元素个数≥64时,会将链表调整为红黑树,目的是方便查找,提高执行效率。
- jdl1.8当链表长度<6时,就会调整为链表
- jdl1.8以前,链表是头插入,jdl1.8以后是尾插入。
HashSet和HashMap
HashSet源码里面用的就是HashMap
Hashtable/了解
线程安全,运行慢;不允许用null作为key或value
Properties
是Hashtable的子类,要求key和value都是String。通常用于配置文件的读取。和"流"相似。
TreeMap使用
- 存储接口是红黑树,可以进行排序。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NBitcnyt-1661860251248)(C:\Users\86156\AppData\Roaming\Typora\typora-user-images\image-20220520153552660.png)]](https://img-blog.csdnimg.cn/399365e41b574e55b4ce4c7624b78ac7.png)
如上图所示:因为存储结构是红黑树,需要进行比较,而s1、s2、s3是Student结构,该类只重写equals()和hashCode()是不足以进行比较的,所以报错。
需要在其类中重写Comparable接口,如下图所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NKUgLZDR-1661860251248)(C:\Users\86156\AppData\Roaming\Typora\typora-user-images\image-20220521100338073.png)]](https://img-blog.csdnimg.cn/89699958d0cd472185bfdb402d52e4d4.png)
使用范例:
package com.qf.chapter12_4;
import java.util.Map;
import java.util.TreeMap;
public class Demo03 {
public static void main(String[] args) {
//创建集合
TreeMap<Student,String> treeMap = new TreeMap<>();
//①添加元素 实现Comparable接口 也可以在创建TreeMap的时候传入比较器Comparator:TreeMap<Student,String> treeMap = new TreeMap<>(new Comparator<Student>); 然后在其相应的函数compare里面写比较方法即可
Student s1 = new Student("孙悟空",100);
Student s2 = new Student("猪八戒",101);
Student s3 = new Student("沙和尚",102);
treeMap.put(s1,"北京");
treeMap.put(s2,"上海");
treeMap.put(s3,"深圳");
treeMap.put(new Student("沙和尚",102),"南京"); //比较依据是重写的Comparable(),而学号一样就无法添加。但是value被替代了
System.out.println(treeMap.size());
System.out.println(treeMap);
//②删除
//treeMap.remove(s3);
//System.out.println("删除之后:"+treeMap.size());
//treeMap.remove(new Student("猪八戒",101)); //是可以删除的,因为也用了comparable接口,学号一样就可以删除
//③遍历
System.out.println("------使用keySet遍历------");
for (Student key: treeMap.keySet()) {
System.out.println(key+"======"+treeMap.get(key));
}
System.out.println("------使用entrySet遍历------");
for(Map.Entry<Student,String> entry: treeMap.entrySet()){
System.out.println(entry.getKey()+"======"+entry.getValue());
}
//④判断
System.out.println(treeMap.containsKey( new Student("孙悟空",100)));
}
}
结果:
3
{Student{name='孙悟空', stuNo=100}=北京, Student{name='猪八戒', stuNo=101}=上海, Student{name='沙和尚', stuNo=102}=南京}
------使用keySet遍历------
Student{name='孙悟空', stuNo=100}======北京
Student{name='猪八戒', stuNo=101}======上海
Student{name='沙和尚', stuNo=102}======南京
------使用entrySet遍历------
Student{name='孙悟空', stuNo=100}======北京
Student{name='猪八戒', stuNo=101}======上海
Student{name='沙和尚', stuNo=102}======南京
true
Collections工具类
定义了除存取以外的集合重用方法:
- public static void reverse(List<?> list) //翻转集合中元素的顺序
- public static void shuffle(List<?> list) //随机重置集合里的元素顺序
- public static void sort (List list) //升序排序(必须实现Comparable接口)
使用范例:
package com.qf.chapter12_4;
import java.util.*;
public class Demo04 {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(20);
list.add(5);
list.add(12);
list.add(30);
list.add(6);
//sort排序
System.out.println("排序之前:"+list);
Collections.sort(list);
System.out.println("排序之后:"+list);
//binarySearch 二分查找
System.out.println(Collections.binarySearch(list,12));
System.out.println(Collections.binarySearch(list,1112)); //负数就是不存在
//copy 要求目的集合dest和源集合src的大小相同,而刚创建的集合其大小默认是0
List<Integer> dest = new ArrayList<>();
for(int i=0;i<list.size();i++){
dest.add(0); //通过添加零元素来占位子,是两个集合大小相同
}
Collections.copy(dest,list);
System.out.println(dest);
//reverse
Collections.reverse(list);
System.out.println("反转之后:"+list);
//shuffle 打乱
Collections.shuffle(list);
System.out.println("打乱之后:"+list);
System.out.println("======集合list转成数组======");
Integer[] arr = list.toArray(new Integer[5]);
Integer[] arr2 = list.toArray(new Integer[10]);
System.out.println(arr.length);
System.out.println(Arrays.toString(arr)); //便于查看结果,把arrays变成字符串输出出来
System.out.println(Arrays.toString(arr2));
System.out.println("======数组转成集合list======");
String[] names = {"张三","李四","王五"};
List<String> nammelist = Arrays.asList(names);
//转换成的集合是受限集合,不能添加或删除
//nammelist.add("111"); 会出错
System.out.println(nammelist);
//int[] nums = {100,200,300,400,500};
//这里不能写List<Integer>,改成下图写法之后,numslist集合中的元素就不是数字/Integer了,变成数组/int[]了
//List<int[]> numslist = Arrays.asList(nums);
//所以要更改创建数组的方法: 基本类型数组转换成集合时,需要修改为包装类型
Integer[] nums = {100,200,300,400,500};
List<Integer> numslist = Arrays.asList(nums);
System.out.println(numslist);
}
}
结果:
排序之前:[20, 5, 12, 30, 6]
排序之后:[5, 6, 12, 20, 30]
2
-6
[5, 6, 12, 20, 30]
反转之后:[30, 20, 12, 6, 5]
打乱之后:[6, 12, 5, 20, 30]
======集合list转成数组======
5
[6, 12, 5, 20, 30]
[6, 12, 5, 20, 30, null, null, null, null, null]
======数组转成集合list======
[张三, 李四, 王五]
[100, 200, 300, 400, 500]
总结
集合和数组类似,是存储多个对象的容器。但是集合大小可以更改,只能存储引用类型数据。同时定义了对多个对象进行操作的方法。















 1756
1756











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









