



2025年春节,DeepSeek-R1的爆发式进化引发全球AI界震动——这一次,人工智能技术话语权的坐标系上终于刻下了中国创新者的印记。开源和强化学习,将会推动各家大模型更快迭代。随着AI完成工作的质量逐步逼近甚至超越人类水平,人类社会将出现深刻的变革和转型。
那么我们当前走到哪里了呢?我萌生了一个实验性的构想:借助AI工具在24小时内,仅凭个人开发能力,从零开始构建并上线一款“视频翻译应用”。
这个想法用DeepSeek体表述就是“我们是否能在晨昏线闭合前,让思维的星火蜕变为可触摸的文明解码器?这场与时间赛跑的创造狂欢,终将证明人类与智能体协同进化的可能性,正如普罗米修斯的火种终将照亮巴别塔的废墟。 ”
本次实验最终生成的结果,已经以Apache-2.0 开源协议在yuch/babelecho发布。
开发者背景
个人开发者,技术背景C/C++,已超过10年没有写用于生产环境的代码。
生成过程说明
本次实验的重点不在于各大模型之间的能力对比,而是遵循实用主义的原则,哪个合适用哪个,或同时使用多家模型。此外,鉴于我对当前流行的AI编程辅助平台(各种Copilot和灵码)不熟悉,因此未使用这些工具,所有的开发任务均通过手动操作在大模型交互式对话窗口完成。
这个过程,DeepSeek帮我诗化拔高了。
没有Copilot的智能补全,没有低代码平台的快捷键,
我在‘通义千问’的对话窗口复刻了旧世纪程序员的手工质感——
输入框是熔炉,自然语言是燃料,敲下回车键的瞬间,
十家AI模型的力量在字符间奔涌,
而我是那个掌控能量流向的结界师。
为什么选择视频翻译应用?
选择AI视频翻译作为切入点,不仅因为其融合了多模态内容处理和大模型翻译理解等AI技术栈,具备高度的可玩性和技术挑战性,更因为当前可以借助阿里视频云提供的卓越视频翻译能力快速上线。阿里视频翻译涵盖了从字幕翻译到声音翻译的全方位解决方案,包括:
- 字幕翻译:提供精准的语言转换,并支持视频字幕的提取、擦除和合成。这一过程确保了字幕的准确性和一致性,同时提升了用户的观看体验。
- 声音翻译:通过分离人声与背景音,识别并区分不同角色的声音,保留原有音色,并将角色的情感以新语种完美呈现。细致入微的处理方式使得翻译后的音频依然能够准确传递原始的情感和意图。
特别值得一提的是,阿里视频翻译还支持目标语言的口型对齐功能,可以根据目标语言的发音驱动人物口型的变化,从而实现更加自然和真实的视听体验。
跳转《阿里视频翻译技术详解》详细了解阿里视频翻译的实际效果体验。相关使用说明详见:介绍视频翻译的使用场景和使用流程_智能媒体服务(IMS)-阿里云帮助中心。
任务启动
我计划开发一个简洁的网页应用,允许用户上传本地视频文件。在上传过程中,页面会实时显示上传进度以及后续的处理过程。视频上传至服务器后,系统将自动进行翻译处理(如声音字幕或其他形式的视频翻译)。处理完成后,用户会收到一个下载链接,通过该链接可以下载已翻译的视频文件。
取名
首先请大模型给这个应用取名,大模型没多想就给了一堆建议,但都不是很满意,于是提示:巴别塔是一个典故,能用这个典故,针对这个场景起一个英文名吗?这次他回答:
当然可以!巴别塔(Tower of Babel) 是一个非常有深意的典故,象征着人类语言的多样性和沟通的障碍。将这个典故融入视频翻译应用的英文名,可以突出应用的核心功能——打破语言障碍,实现无缝沟通。最终我选用了BabelEcho。
寓意:巴别塔的回声,象征语言传递的无障碍和共鸣。
框架和技术栈
作为一个老C/C++程序员,什么前端后端,用哪些技术栈,我并不是太有概念。于是这个问题就交给大模型了,也没特别构思提示词:”写一个前端页面和后端程序,前端提交视频,后端调用视频翻译接口,翻译后,可下载“。 通义千问中规中矩给出建议:
为了实现一个前端页面和后端程序,允许用户提交视频文件、调用视频翻译接口进行翻译,并在翻译完成后提供下载链接,我们可以使用以下技术栈: 前端:HTML + JavaScript(或React、Vue等现代前端框架) 后端:Python Flask 或 FastAPI
通义千问的代码生成能力极强,洋洋洒洒的给出了整个代码和搭建步骤。得益于现代语言强大的包管理能力,基本不需要太多配置工作,代码也没怎么修改就可以直接运行。
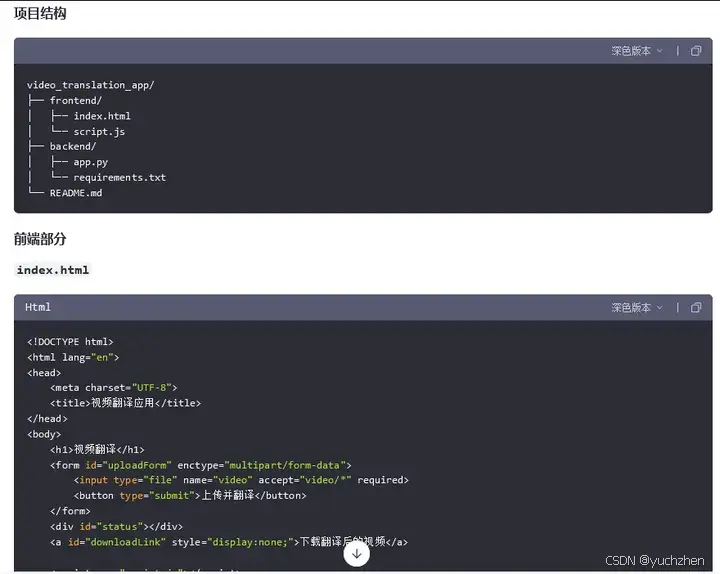
通义千问生成的应用框架
前端界面开发
默认生成的界面不美观,我们让大模型改:“前端用vue框架改写一下”。通义很快给出前端采用VUE.js的代码。
为了使用Vue.js框架改写前端部分,我们将创建一个Vue应用来处理视频上传、调用后端API进行翻译,并在完成后提供下载链接。以下是详细的实现步骤和代码示例。吧啦吧啦......
还贴心的告诉我怎么安装和配置Vue和其它环境。
再让他整合Element Plus,也是基于现有代码直接给出答案,基本直接拷贝过来就能用。我的大部分时间都花在处理文件选择、上传进度显示、结果返回解析、状态查询与更新等调试工作上,尤其是根据不同状态控制界面元素的显示与隐藏及禁用状态,合理显示进度条和提示信息。这部分逻辑需要根据具体的程序流程进行细致的处理,基本上都需要自己来完成。
在调试过程中,遇到问题也都可以直接提问,比如因跨域问题调用不过,是DeepSeek给出问题的分析和解决方法。
项目进行了一会,我突然想起这个应用也许小红书的老外们用得着,于是让大模型翻译成英文。简单几句话,整个代码,包括注释和提示信息,都自动变成了英文,NB。
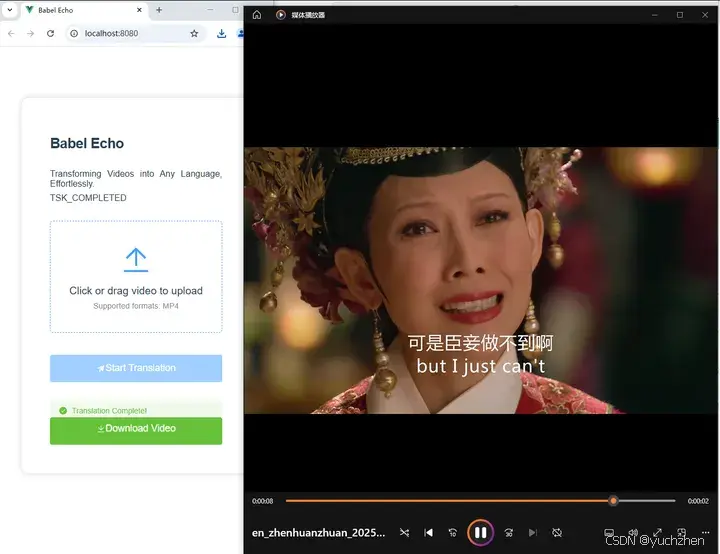
第一次全流程调试通过时的效果
后端开发
大模型生成的框架使用Flask构建简单的Web服务器,并且已把前后端的基础交互完成,经简单调试后就能工作。
- /translate 端点接收视频文件,保存到OSS后调用阿里云IMS API进行翻译;
- /task-status/<task_id> 任务状态检查接口检查任务的状态;
然而,自动生成的视频翻译API调用代码存在诸多问题,基本上无法直接使用。我尝试了多种方法和大模型,例如提供阿里云文档链接、提供请求样例等,试图借助大模型来生成调用代码,但生成的代码质量始终不能让人满意。最终,我还是通过结合人工调整才得以完成这项工作。
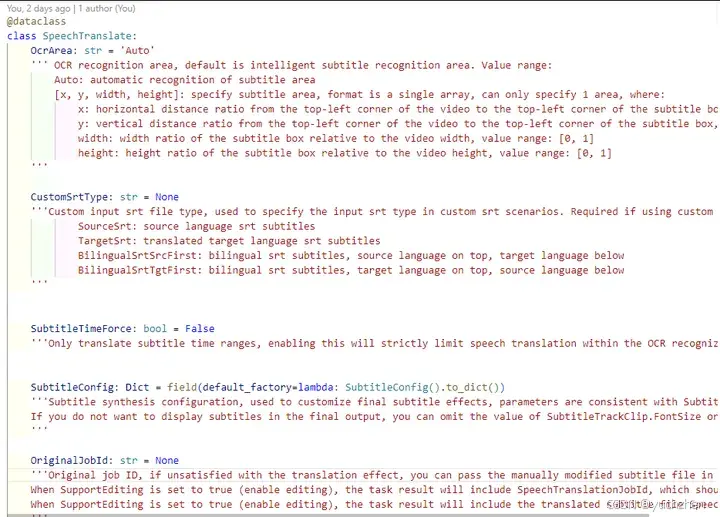
阿里云使视频翻译API的结构定义类
在后端代码调试过程中,最耗费时间的部分是解析返回的参数和处理各种错误。例如,在解析 GetSmartHandleJob(获取智能任务结果)接口的返回数据时,我需要同时尝试实际返回的结果,并将返回的字符串提供给大模型,以帮助生成相应的处理函数。这一过程涉及反复试验和调整,以确保能够正确解析各种可能的返回情况并进行适当的错误处理。
@staticmethod
def get_nested_value_from_jsonstr(jsonstr, keys):
"""
Retrieve the value at a specified path from a nested json str.
:param jsonstr: jsonstr contains A list of key paths
:param keys: A list of key paths
:return: Returns the found value, or None if the path does not exist
"""
try:
value = json.loads(jsonstr)
for key in keys:
value = value[key]
return value
except (KeyError, TypeError):
return None
#######
edit_config = api_respond.get_nested_value(["body","SmartJobInfo","EditingConfig"])
mediaURL= ApiResponse.get_nested_value_from_jsonstr(edit_config,["outputConfig","mediaURL"])
...
vtstatus_response.media_file_url = oss_config.generate_presigned_url(object_name)
vtstatus_response.state= api_respond.get_nested_value(["body","State"])
ai_result_str = api_respond.get_nested_value(["body","JobResult","AiResult"])
vtstatus_response.media_id = ApiResponse.get_nested_value_from_jsonstr(ai_result_str,["MediaId"])美术设计
鉴于应用交互非常简单,所有界面效果均采用了Element Plus提供的组件来实现。默认情况下,各类显示效果由大模型生成,而对于一些不满意的细节,我会向大模型询问调整建议。例如,当按钮与提示文字之间的间距过大时,大模型会建议我调整特定的CSS参数以优化布局。
尽管如此,一个专业的应用程序图标仍然是不可或缺的。为了获取合适的图标,我首先尝试了一个AI图标生成网站,并根据我的需求生成了图标。生成的图标如下所示:

其审美实在不敢恭维。或者我们干脆直接让LLM来生成图标试试,于是把如下指令给了DeepSeek:我需要生成一个“视频翻译”应用的图标,这是一个网页应用,可以把视频从一种语言翻译为其他各国语言,你能帮我生成这个图标吗?用svg返回结果。
DeepSeek倒是不怯场,自言自语半天给出了他的设计。
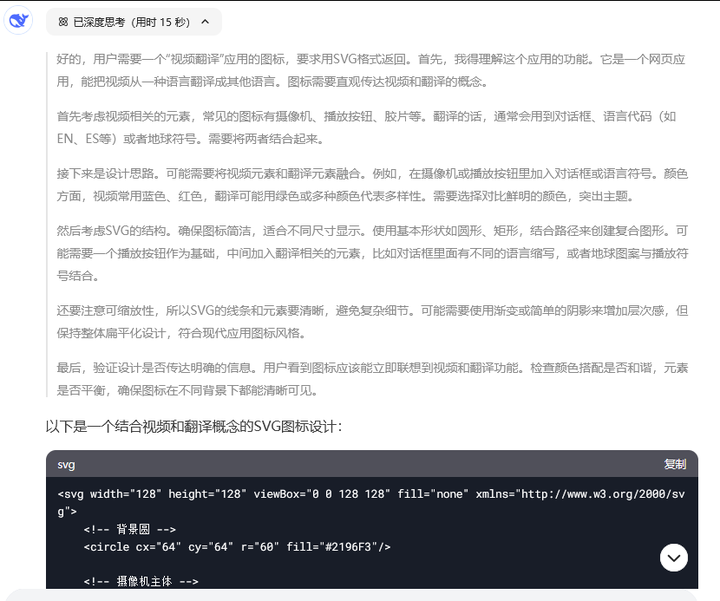
DeepSeek思考过程
实际长这样:

也不好看。我只好PUA他,让他再改改:下面的文字都突出边界了,不太行啊,而且这个图标比较传统,你有没有设计sense,我调用你接口要网费电费的,你再做不好,我就去找隔壁家的通义千问了。他倒是老实,吭哧吭哧改了几版,包括我也让通义用这个方式去生成了,效果都不行。最后还是自己手工改一下DeepSeek的第一版吧,修改后效果如下:

对应SVG代码:
<svg width="128" height="128" viewBox="0 0 128 128" fill="none" xmlns="http://www.w3.org/2000/svg">
<!-- 背景圆 -->
<circle cx="64" cy="64" r="60" fill="#2196F3"/>
<!-- 摄像机主体 -->
<path d="M44 44H84C90.6274 44 96 49.3726 96 56V72C96 78.6274 90.6274 84 84 84H44C37.3726 84 32 78.6274 32 72V56C32 49.3726 37.3726 44 44 44Z" fill="white"/>
<!-- 镜头 -->
<circle cx="64" cy="64" r="16" fill="#2196F3"/>
<!-- 多语言文本气泡 -->
<path d="M55 94C55 94 60 90 64 90C68 90 73 94 73 94" stroke="white" stroke-width="4"/>
<!-- 播放按钮 -->
<path d="M60 58L76 66L60 74V58Z" fill="white"/>
</svg>应用发布
在处理需要查询资料来回答问题的任务时,我更倾向于依赖Kimi。他相对更少自作主张地随意作答,而是基于实际的搜索结果回复。我的提问很简单:现在我要把开发好的flask 和 vue.js 应用部署的Ubuntu的环境中,应该怎么做?Kimi迅速提供了详细的步骤:包括使用Gunicorn和Nginx来部署后端,部署前端的静态文件,配置域名和SSL证书,并给出了确保安全性和性能的最佳实践建议。整个过程清晰明了,堪称一份保姆级教程。
后续在解决域名、安全性和翻译费用问题后,或许我会把这次试验的成果以一个应用服务方式发布出来,真正的和AI一起迭代这个小应用。
写在最后
甄嬛传名场面翻译
在春节假期断断续续的24小时里,最终还是完成了这个实验。在面对复杂处理逻辑和多样的错误类型时,因为缺乏足够的上下文信息以及AI未和实际环境联动,人工干预仍然是确保代码质量和功能实现的关键步骤。
最终结果与测试视频《甄嬛传》中的名场面相反:but I just can :)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









