









1.概述
我们在日常开发中经常会遇到需要进行定时批处理的需求,也就是所谓的跑批,本文记录下简单批处理任务的开发思路。
2.数据模型设计
批处理任务本质是指在指定的时间,由应用程序对源数据(需要处理的数据)进行业务处理,产生业务需要的目标数据的过程。所以数据模型(也就是表结构)的设计是至关重要的;不论什么业务场景,核心是数据模型可以记录批处理的一些简单结果,常见的源数据表结构中都会存在如下通用字段:
process_status: 处理状态(0:未处理, 1:处理成功, 2处理失败)
fail_msg: 失败原因
如:
CREATE TABLE `xxx_origin` (
`id` INT(11) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键',
`batch_no` VARCHAR(16) NOT NULL COMMENT '批次号',
`process_status` INT(11) NOT NULL COMMENT '处理状态, 0:未处理, 1:处理成功, 2:处理失败',
`fail_msg` VARCHAR(256) NOT NULL COMMENT '处理失败的原因',
`create_by` INT(11) NOT NULL DEFAULT '0' COMMENT '创建人',
`create_dt` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_by` INT(11) NOT NULL DEFAULT '0' COMMENT '更新人',
`update_dt` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`),
INDEX `idx_batch_no` (`batch_no`)
) ENGINE=InnoDB DEFAULT CHARACTER SET=utf8mb4 AUTO_INCREMENT=1 COLLATE='utf8mb4_general_ci' COMMENT='xxx表';
目标表各不相同,一般会有批次号字段batch_no
3.开发
进行coding时,核心就是你要仔细考虑跑批时处理的数据量级;如果数据量只是百级、千级很少的数据量,那么你实际并不需要考虑性能问题,跑批时直接加载需要处理的数据,一次性处理即可,简单快捷,也不会有性能问题;如果数据量上万、上百万、千万的量级,那么,此时,跑批时的处理策略就异常重要了。简单有效的策略是跑批时分页加载需要处理的数据当然,具体落实这个策略时,也有很多需要注意的点:
1.直接使用分页sql在大数据量时查询速度非常慢,如mysql的limit
2.事务的处理
既然是问题,当然就有解决的方法,跑批时相关处理代码如下:
@Transactional(rollbackFor = Exception.class)
public void run(String batchNo) {
//分页处理该批次未处理的数据
while (true) {
//获取该批次未处理的第一条数据id
Integer startIndex = originDataService.getFirstUnprocessedItemId(batchNo);
log.info("startIndex: {}", startIndex);
if (Objects.isNull(startIndex)) {
log.info("当前批次数据处理结束 batchNo: {}", batchNo);
break;
}
//获取未处理的数据
List<OriginDataPO> dataList = originDataService.getUnprocessedItemsByBatchNo(startIndex, BATCH_SIZE, batchNo);
try {
log.info("待处理dataList: {}", dataList);
originDataCollector.doCollect(batchNo, dataList);
} catch (Exception e) {
log.error("数据处理失败", e);
//更新数据明细处理状态为:处理失败
List<Integer> targetIds = logPOList.stream().map(m -> m.getId()).collect(Collectors.toList());
originDataService.updateOriginDataItemOnFail(targetIds, e.getMessage());
}
}
}
@Transactional(rollbackFor = Exception.class, propagation = Propagation.REQUIRES_NEW)
public void doCollect(final String batchNo, List<OriginDataPO> dataList) {
//事务处理:新开事务,保证每一页的数据处理结束后都提交事务保存相关数据,这样可以避免经典的最后一条失败了,之前处理的都要回滚
......
//业务逻辑处理
}
@Transactional(rollbackFor = Exception.class, propagation = Propagation.REQUIRES_NEW)
public void updateOriginDataItemOnFail(List<Integer> ids, String errMsg) {
//事务处理:新开事务
......
//记录失败明细
}
代码执行流程:
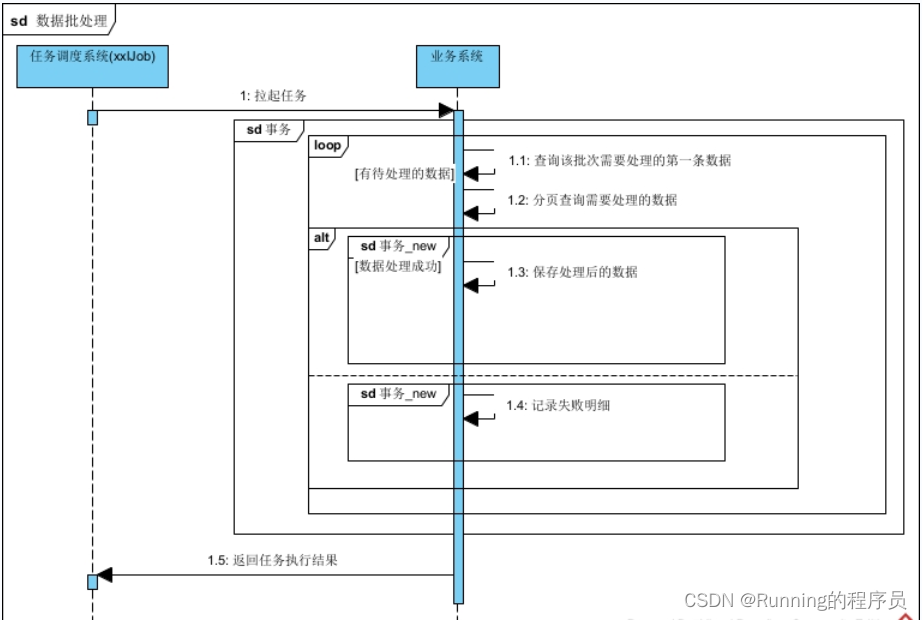
4.优化
上述代码中,针对传统的分页做了优化,核心就是使用覆盖索引替换limit,这样可以大大提高大数据量的查询速度,详细如下:
上述代码中originDataService.getFirstUnprocessedItemId(batchNo)对应的SQL语句为:
@Options(flushCache = Options.FlushCachePolicy.TRUE)
@Select("SELECT id FROM xxx_origin_data WHERE batch_no = #{batchNo} AND process_status = 0 ORDER BY id ASC LIMIT 1;")
Integer selectFirstUnprocessedItem(@Param("batchNo") String batchNo);
上述代码中originDataService.getUnprocessedItemsByBatchNo(startIndex, BATCH_SIZE, batchNo)对应的SQL语句为:
@Select("SELECT id AS id, merchant_no AS merchantNo, batch_no AS batchNo, channel AS channel, product_id AS productId, " +
"property_id AS propertyId, process_status AS processStatus, merchant_name AS merchantName " +
"FROM xxx_origin_data " +
"WHERE id >= #{start} AND batch_no = #{batchNo} AND process_status = 0 ORDER BY id ASC LIMIT #{offset};")
List<RiskMerchantLogPO> selectUnprocessedItems(@Param("start") Integer start, @Param("batchNo") String batchNo, @Param("offset") Integer offset);
5.结语
对于复杂的跑批任务,例如银行业中清分系统、计费系统、结算系统等等,我们可以使用专门的批处理框架,如SpringBatch,可以支撑更复杂、细粒度的控制。跑批任务的调度可以使用目前流行的xxlJob框架。















 726
726











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









