









最近优化了两个sql查询耗时导致页面查询time out的问题,简单记录下
1.索引不当导致查询超时
前端查询页面优化,日期查询框默认选中三个月的时间范围(之前页面时间查询框没有默认值,之所以让页面这样处理是为了让SQL走优化后的索引),发布之后,查询仍然报超时错误,
查看APM接口调用链:
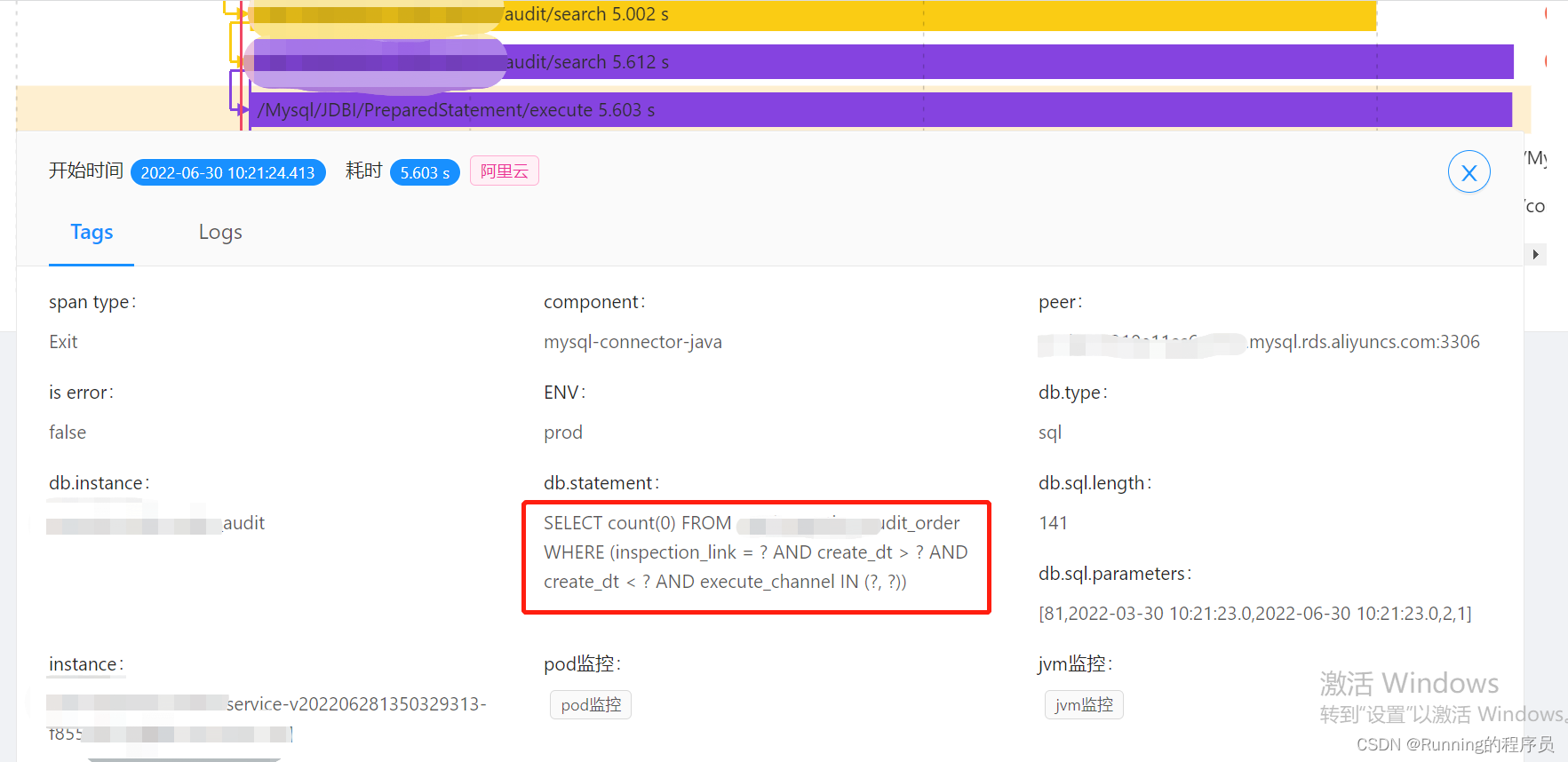
复制上图中的SQL,explain执行计划,发现没有走指定的索引(idx_create_dt_link_status on xxx_audit_order(`create_dt`, `inspection_link`, `inspection_audit_status`);),控制台执行sql耗时依然是6秒左右。本地数据库中插入生产上表的同量级数据(400万,大批量插入表数据详见另一篇文章)
索引结构和生产一致,执行查询,耗时基本一致(问题其实已经很明确:执行器没有按照我们创建的索引去执行,因为生产中我们禁用force index(index_name)这种命令,所以本地验证安全之后,才会申请发布生产)。删掉冗余不用的索引:
drop index idx_link_status on xxx_audit_order;
再次查看sql的explain,执行器已经选择我们设定的索引执行,控制台执行sql,耗时1秒,页面查询已经正常
另外针对页面的状态查询框,查询也是超时的,也是历史的索引在大数据量下暴露了问题,同样的思路,创建新的良好的索引即可,这里针对状态查询创建了如下的联合索引:
CREATE INDEX `idx_status_create_dt` on xxx_audit_order (`inspection_audit_status`, `create_dt`);
因为状态字段在这张表中对数据的区分度非常好,所以状态字段作为联合索引的前导字段,时间字段作为范围查询放到了联合索引的后面,这样查询效果得到了极大提升
2.大数据量下join关联3张表查询,导致超时
线上有这样一个SQL(mybatis动态sql在满足业务给定的条件拼接之后的形式),如下:
select distinct(o.order_no), o.* from xxx_sale_order o
left join xxx_order_product p on o.order_no = p.order_no
left join xxx_product_item item on o.order_no = item.after_sale_order_no
where o.execute_channel = 1
and (p.product_no = 'foo' or item.product_no = 'bar' )
order by o.id desc;
线上数据有300万,可以想象这条sql执行的会有多慢,控制台执行耗时7秒多,导致页面根本无法使用。大家都知道,join在表数据量大的时候查询效率会很差,那么怎么优化呢?一般来说,对join链接查询我们都会在业务层代码中进行转换,比如把需要关联的某张表先查询出该表的结果集,将join该表转换为where条件中的in(...)。这里业务层先查询表xxx_order_product 和 xxx_product_item ,比如:
public List<String> getXXXListByProductNo(final String productNo) {
if (StringUtils.isBlank(productNo)) {
return Collections.emptyList();
}
List<String> asoNoList = mapper.selectByProductNo(productNo);
List<String> xxxOrderNos = productService.getAsoNoListByProductNo(productNo);
if (CollectionUtils.isNotEmpty(xxxOrderNos)) {
asoNoList.addAll(xxxOrderNos);
}
if (CollectionUtils.isEmpty(asoNoList)) {
return Collections.emptyList();
}
return asoNoList.stream().distinct().limit(100).collect(Collectors.toList());
}
这样一来,原来三表关联,最后就转换为单表的where条件查询,sql如下:
select o.* from xxx_order o
where o.execute_channel = 1
and o.order_no in('foo','bar'...)
order by o.id desc;
查询时间大幅提升,问题解决
PS:
- join关联查询
join关联查询时,关联键一定要用驱动表进行全链关联,否则即使各表的关联字段都有索引,也不会走索引,原因很简单,因为此时会产生临时表,结果就是filesort,比如下面的sql,查询效率很差:
select o.* from xxx_sale_order o
left join xxx_order_product p on o.order_no = p.order_no
left join xxx_product_item item on p.id = item.product_ref_id
where o.execute_channel = 1 and ...
order by o.id desc;
- 联合索引
联合索引也就是复合索引,即一个索引是由多个字段组成的,如上文中的
idx_create_dt_link_status on xxx_audit_order(`create_dt`, `inspection_link`, `inspection_audit_status`);
大家都知道,联合索引mysql是按照最做匹配原则去匹配索引的,所以这里重点强调下:联合索引的前导字段一定要是区分度很大的字段(比如id啊或者编号啊等等),这样查询效率非常高;不要将标识范围的字段作为联合索引的前导字段(比如创建时间、修改时间),范围查询将会导致联合索引不再匹配后面的索引字段,比如上文中的这个联合索引:
idx_create_dt_link_status on xxx_audit_order(`create_dt`, `inspection_link`, `inspection_audit_status`);
这个索引在上文中提到的优化之所以有效果,其实是因为create_dt字段的范围查找过滤掉了大部分数据,后面的两个索引字段(inspection_link`, `inspection_audit_status并没有起作用)所以这个联合索引实际上是冗余的,直接改为单列索引即可,即:
idx_create_dt on xxx_audit_order(`create_dt`);


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









