









开发中我们看那些散发着浓烈的bad smell的代码,总有一种要修理它的冲动!这当然是好事,说明我们有能力识别不好的东西以及维持系统健康运行的意愿。但是,但是总是无处不在,我们好心有时候会办出坏事来。下面这个真实的案例就是某同学觉得表的字符集设计的不合理,在一次需求开发中就把他改了,然而不幸的是由此导致了一个不小的线上事故,下面分享给大家
1.事故的导火线
你敢想?导致线上事故的是一个简单的DDL 语句:
ALTER TABLE table_t CONVERT TO CHARACTER SET utf8mb4;
2.事故现场
由于业务系统响应极慢,使用方反馈(早期系统没有完善的告警机制),开发排查日志发现是sql查询速度很慢,然后查询慢日志监控,看到了如下的壮观场景:
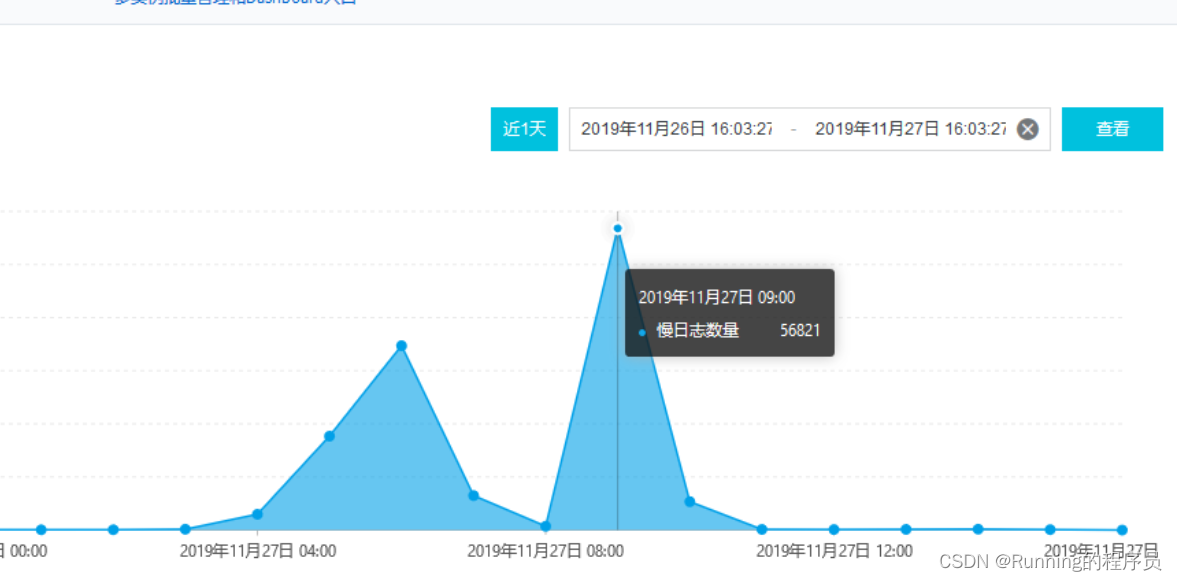
3.事故原因分析
为什么会有这么多慢查询呢??因为查询语句的关联字段的字符集不同,导致索引失效,sql执行变成了全表扫描,进而导致数据库实例所在机器的CPU 长时间100%,影响业务访问。
4.事故线下重现
我们使用连接查询时,两个表的关联字段都建有索引,但是如果两个表的关联字段的字符集不同,就会导致索引失效,不会走索引。执行下面的建表语句:
CREATE TABLE `t1` (
`id` bigint NOT NULL AUTO_INCREMENT,
`name` VARCHAR(64) DEFAULT '',
`code` VARCHAR(16) DEFAULT '',
PRIMARY KEY (`id`),
KEY `idx_code` (`code`),
KEY `idx_name` (`name`)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=UTF8;
CREATE TABLE `t2` (
`id` bigint NOT NULL AUTO_INCREMENT,
`name` VARCHAR(64) DEFAULT '',
`code` VARCHAR(16) DEFAULT '',
PRIMARY KEY (`id`),
KEY `idx_code` (`code`),
KEY `idx_name` (`name`)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=UTF8MB4;
然后插入一些数据:
INSERT INTO `t1` (`id`, `name`, `code`) VALUES (6, 'aa', '');
INSERT INTO `t1` (`id`, `name`, `code`) VALUES (7, 'bb', '');
INSERT INTO `t1` (`id`, `name`, `code`) VALUES (8, '0', '');
INSERT INTO `t1` (`id`, `name`, `code`) VALUES (9, '1', '');
INSERT INTO `t1` (`id`, `name`, `code`) VALUES (10, '2', '');
INSERT INTO `t1` (`id`, `name`, `code`) VALUES (11, '3', '');
INSERT INTO `t1` (`id`, `name`, `code`) VALUES (12, '4', '');
INSERT INTO `t1` (`id`, `name`, `code`) VALUES (13, '5', '');
INSERT INTO `t1` (`id`, `name`, `code`) VALUES (14, '6', '');
INSERT INTO `t1` (`id`, `name`, `code`) VALUES (15, '7', '');
INSERT INTO `t1` (`id`, `name`, `code`) VALUES (16, '8', '');
INSERT INTO `t1` (`id`, `name`, `code`) VALUES (17, '9', '');
INSERT INTO `t2` (`id`, `name`, `code`) VALUES (6, 'ff', '');
INSERT INTO `t2` (`id`, `name`, `code`) VALUES (7, 'hh', '');
INSERT INTO `t2` (`id`, `name`, `code`) VALUES (8, 'gg', '');
线上的sql形式如下:
select * from t2 left join t1 on t1.code = t2.code where t2.name = 'ff';
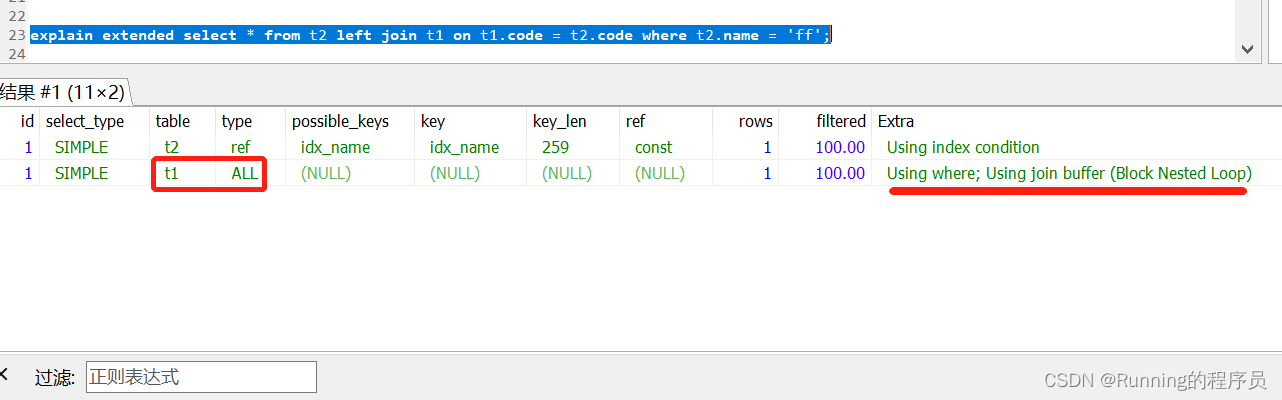
我们查看执行计划:
explain extended select * from t2 left join t1 on t1.code = t2.code where t2.name = 'ff';
从下图的执行计划可以看到,查询条件t2.name = 'ff’使用了索引,而条件t1.code = t2.code并没有使用表t1的索引:
为什么两个字段的字符集不一样就不走索引了呢?这个命令SHOW WARNINGS; 会给你详细的说明分析,这个命令和执行计划配合使用,简直不能再香了。你一定要去使用!如下:
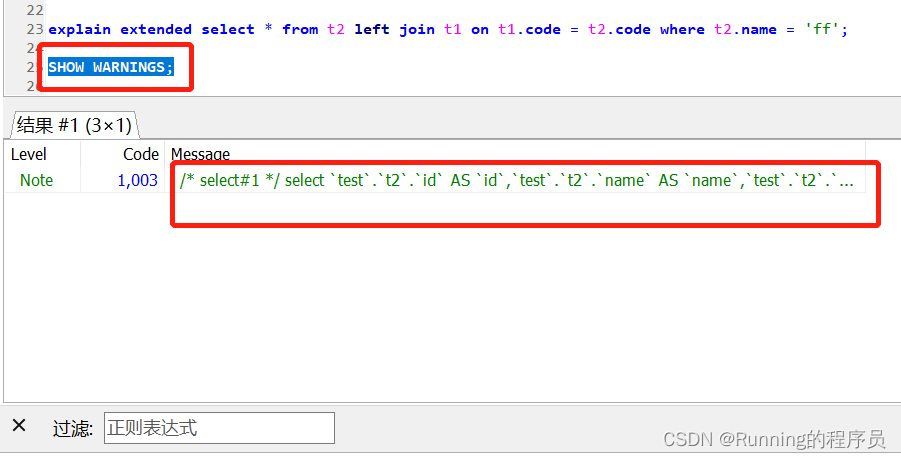
message全量内容如下:
/* select#1 */ select `test`.`t2`.`id` AS `id`,`test`.`t2`.`name` AS `name`,`test`.`t2`.`code` AS `code`,`test`.`t1`.`id` AS `id`,`test`.`t1`.`name` AS `name`,`test`.`t1`.`code` AS `code` from `test`.`t2` left join `test`.`t1` on((convert(`test`.`t1`.`code` using utf8mb4) = `test`.`t2`.`code`)) where (`test`.`t2`.`name` = 'ff')
这时候已经非常清楚了,MySQL在关联字段上进行了convert转化,索引当然就失效喽!
5.事故解决
问题的解决也是简单粗暴,DBA直接改回了原来的字符集:
ALTER TABLE t_test CONVERT TO CHARACTER SET utf8;
6.事故复盘
平时让我们说索引失效的场景你可能会咔咔咔的说出不少,但是实际使用的时候却时常会犯错,实际上还是意识不强烈。不管怎么说,都要认真对待自己写下的每行代码,包括任何要上线的资源,如初始化的数据,脚本等。就拿这次事故来说,开发同学本意是觉得utf8字符集不严谨,应该使用utf8mb4,但实际上表中的code字段存储的只是数字和字母组成的字符串,早期历史原因被设计成utf8也无可厚非了。但是,我们作为后来接手着,任何改动就要小心了,避免跳坑里了。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









