







一、参考《机器学习与实践》
KNN算法是一个易于掌握且非常有效的算法,KNN是懒惰学习(lazy learning)算法中的一种,所以不需要训练,但是需要样本数据。算法总共分为三步:
1.使用欧氏距离公式
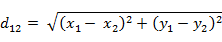
计算当前点与样本数据中所有点的距离
2.选出距离最近的K个点
3.在距离最近的K个点中选出频率最高的类别
python实现算法:
from numpy import * import operator Data=[[2.0,3.1],[3.0,2.9],[1.0,1.2],[1.2,1.3]] Labels=['A','A','B','B'] def Calua(DataSource,k,Data,labels,): DataSize=len(Data) #样本长度 ReduceData=tile(DataSource,(DataSize,1))-Data #使用tile函数生成样本数据长度的数据集并和样本数据集相减 SquareData=ReduceData**2 #对相减后的距离进行平方 SquareDistances=SquareData.sum(axis=1) #对平方后的数据进行相加 distance=SquareDistances**0.5 #然后再开方 sortedIndex=distance.argsort() #获取从小到大进行排序的索引 Dit={} for i in range(k): label=Labels[sortedIndex[i]] #按照距离由近到远获取标签 Dit[label]=Dit.get(label,0)+1 #计算出现的频率 soredClassCount=sorted(Dit.items(),key=operator.itemgetter(1),reverse=True)#按照出现的频率由大到小进行排序 return soredClassCount[0][0] #返回最大值
#当执行 print(Calua([1.0,1.1],3,Data,Labels))
会返回 B
关于k的取值有很多种,最简单的方法就是使用交叉验证取出最有效的值















 2468
2468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









